Downloaded 772 times



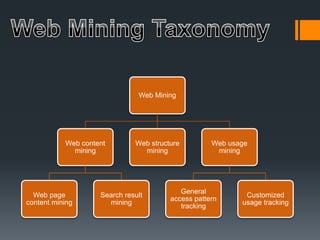






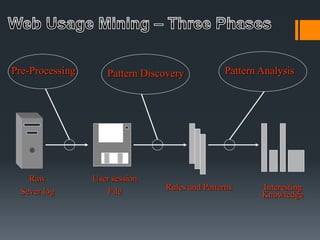










Web mining uses data mining techniques to extract information from web documents and services. It involves web content mining of page content and search results, web structure mining of hyperlink structures, and web usage mining of server logs to find user access patterns. Data mining techniques like classification, clustering, and association rule mining can be applied to web data to discover useful patterns and information.























































































