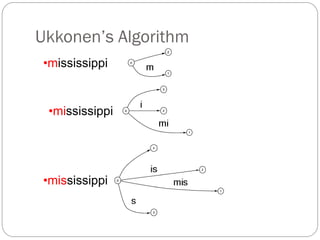
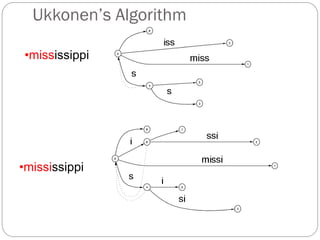
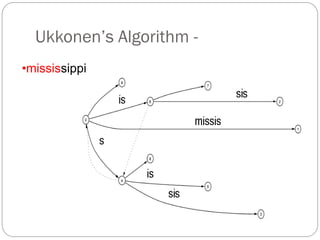
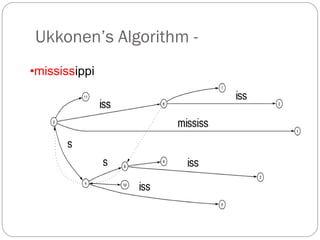
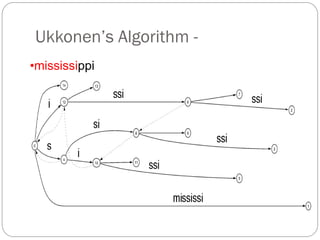
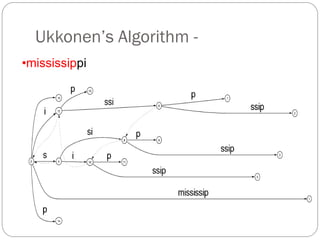
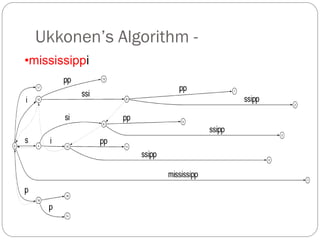
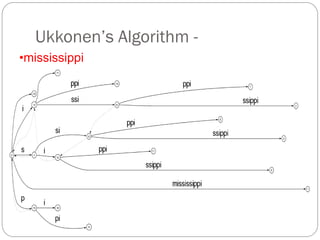
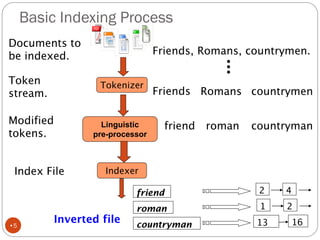
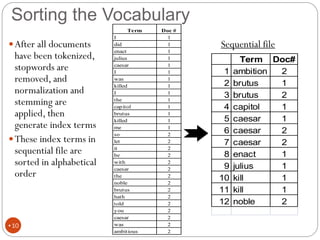
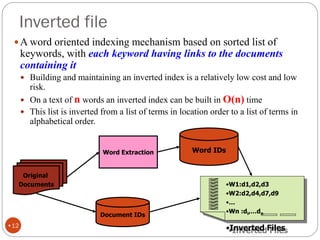
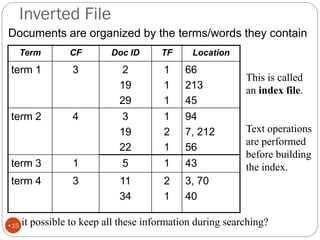
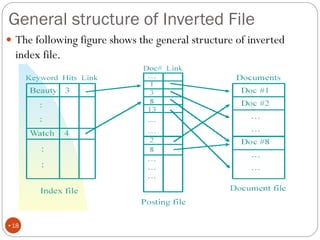
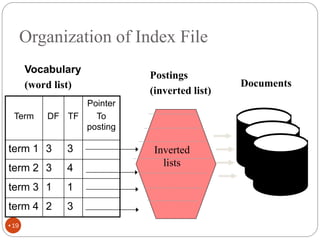
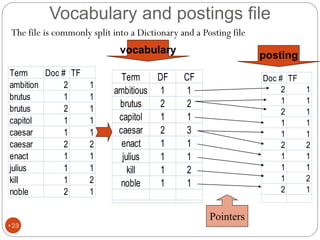
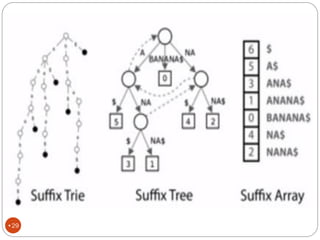
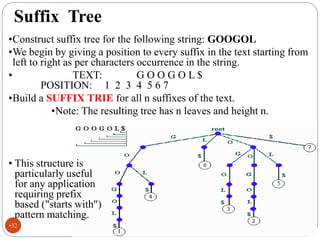
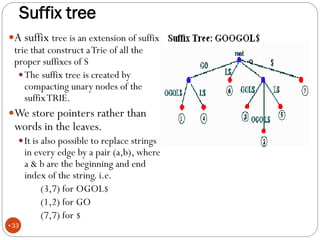
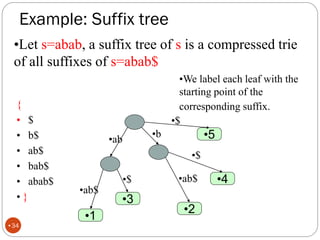
The document discusses different indexing structures for information retrieval, including sequential files, inverted files, and suffix trees. It provides examples of how each structure is constructed and organized. Sequential files arrange all terms and their associated documents sequentially without pointers. Inverted files divide the index into a vocabulary listing terms alphabetically and associated postings files containing term locations. Suffix trees index the entire text as a single string and support complex queries by compactly representing all suffixes.



























![Complexity Analysis
The suffix tree for a string has been built in O(n2) time.
Searching is very fast:The search time is linear in the length of
string S.
The number of leaves is n+1, where n is the number of input strings.
Furthermore, in the leaves, we may store either the strings themselves or
pointers to the strings (that is, integers).
Searching for a substring[1..m], in string[1..n], can be solved in
O(m) time.
Expensive memory-wise
Suffix trees consume a lot of space
How many bytes required to store MISSISSIPI ?
•38](https://image.slidesharecdn.com/chapter3indexingstructure-230506070016-d6ba681a/85/Chapter-3-Indexing-Structure-pdf-38-320.jpg)