Downloaded 10 times



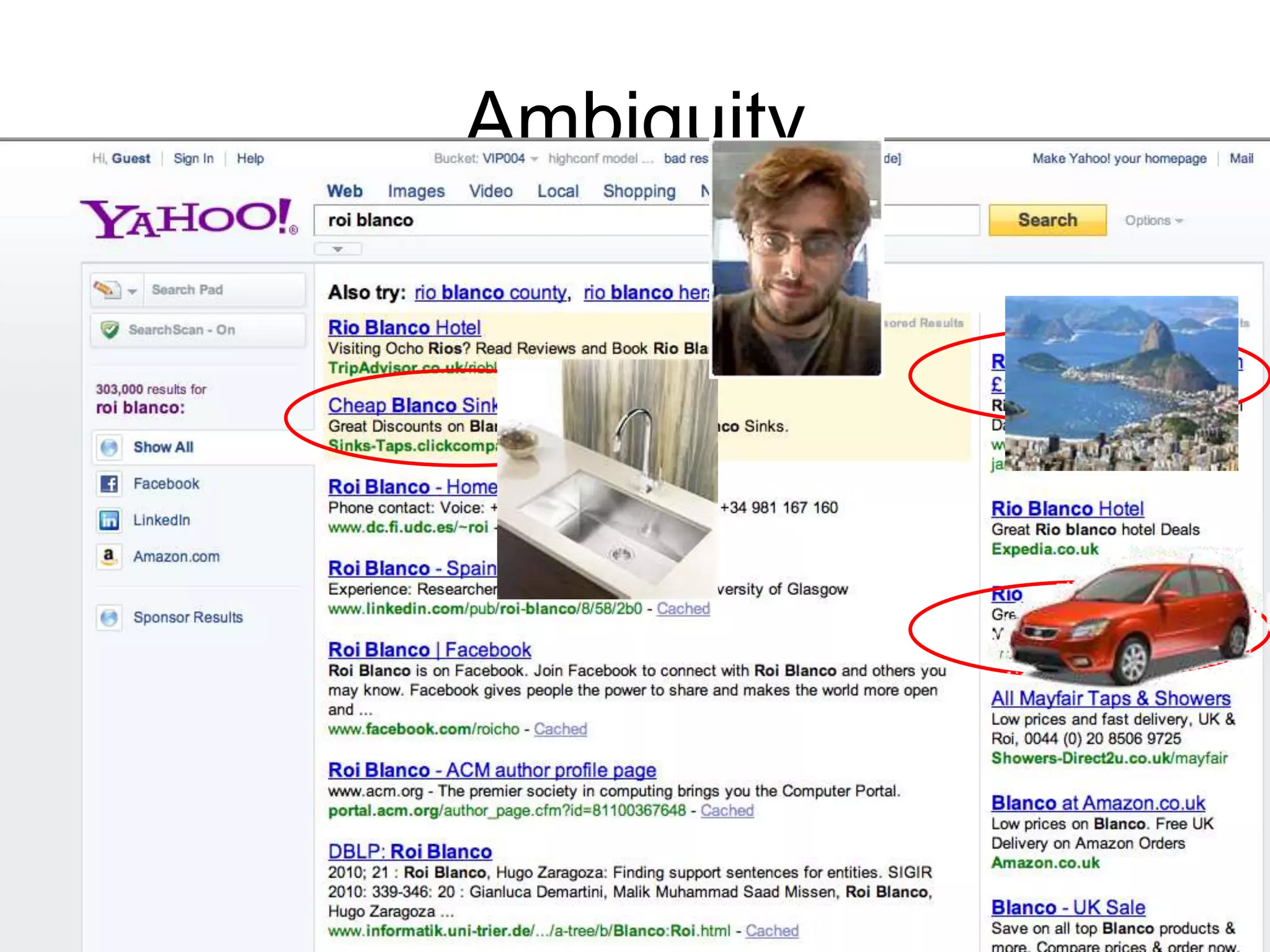
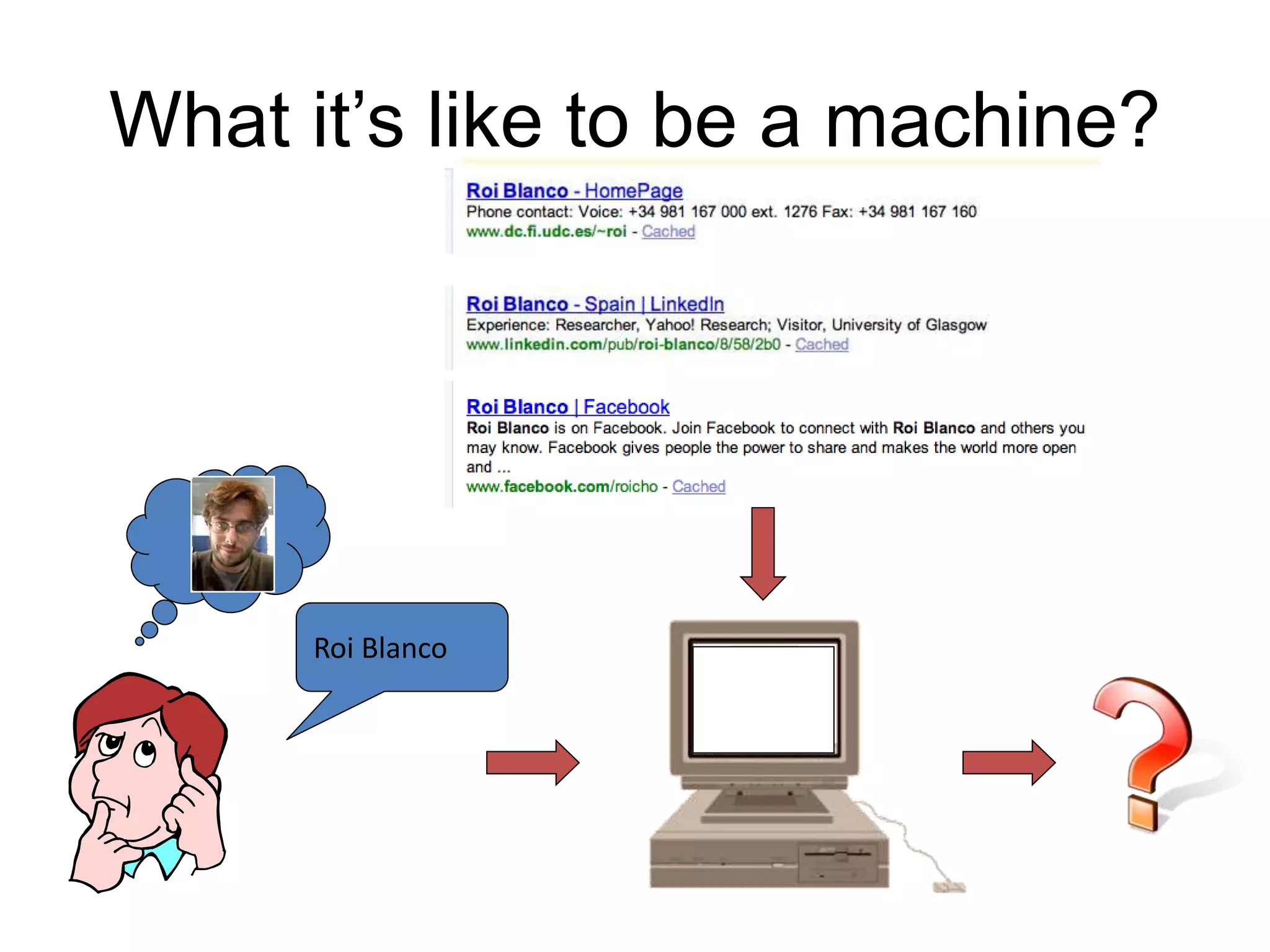
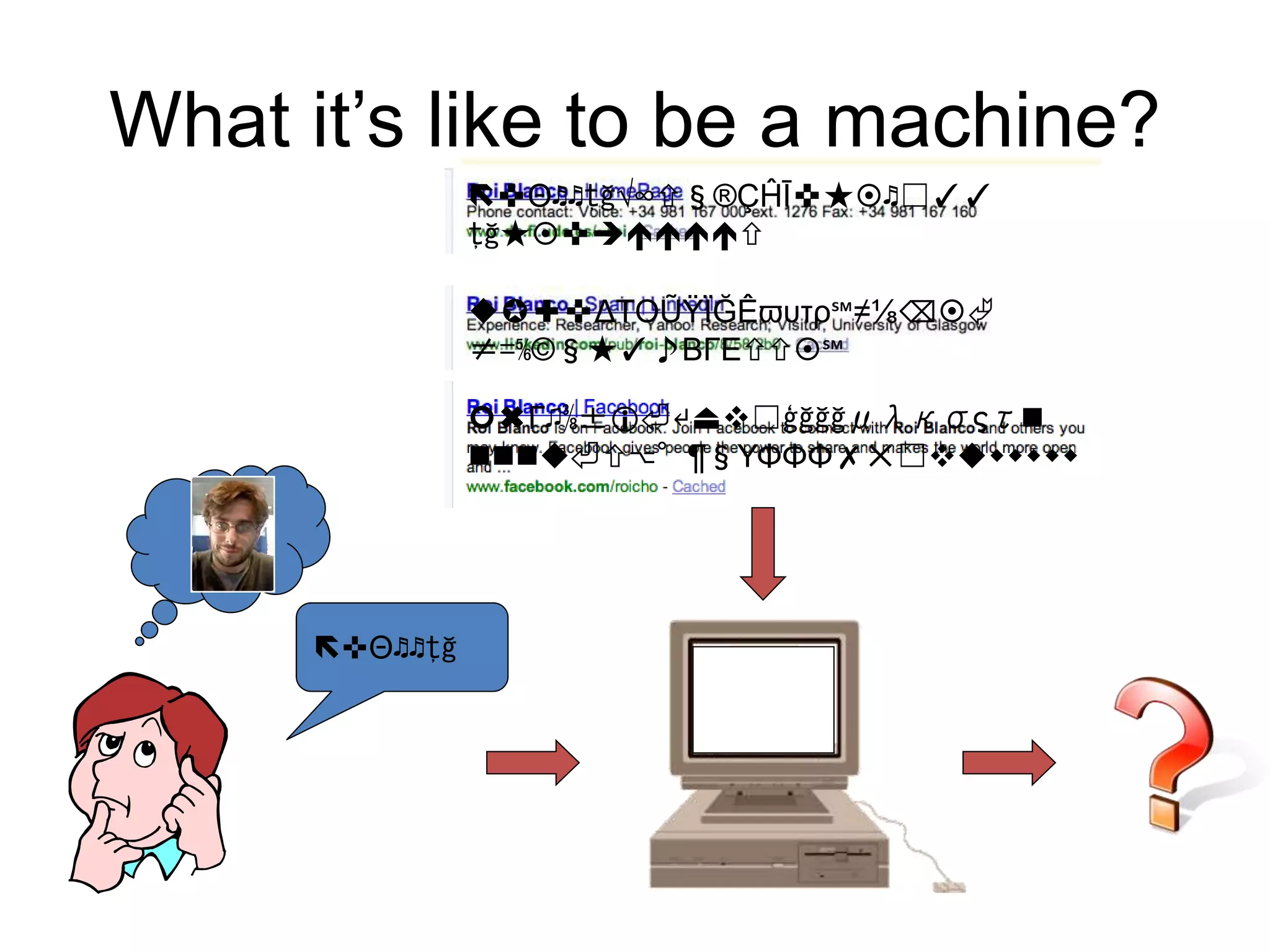

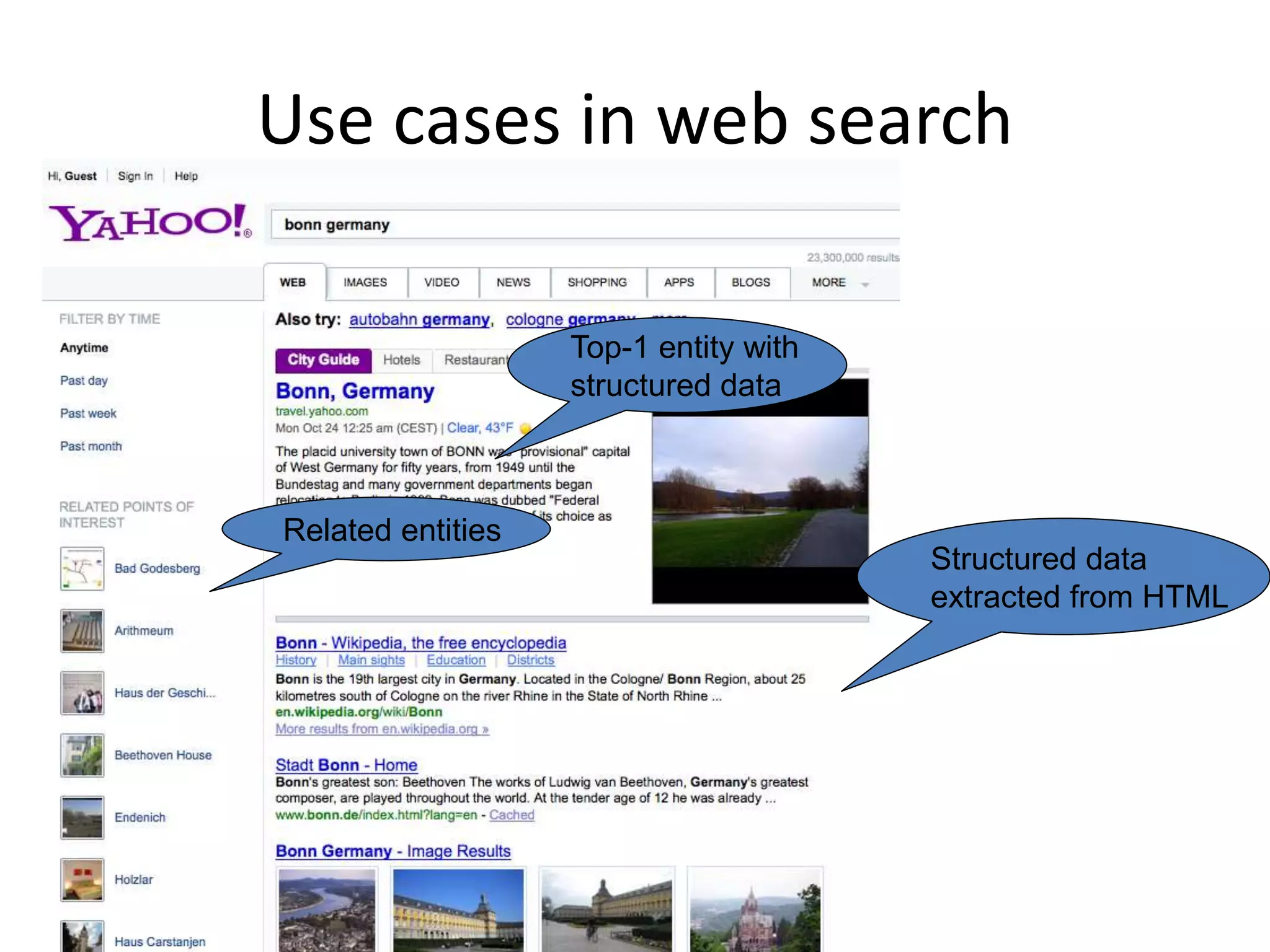
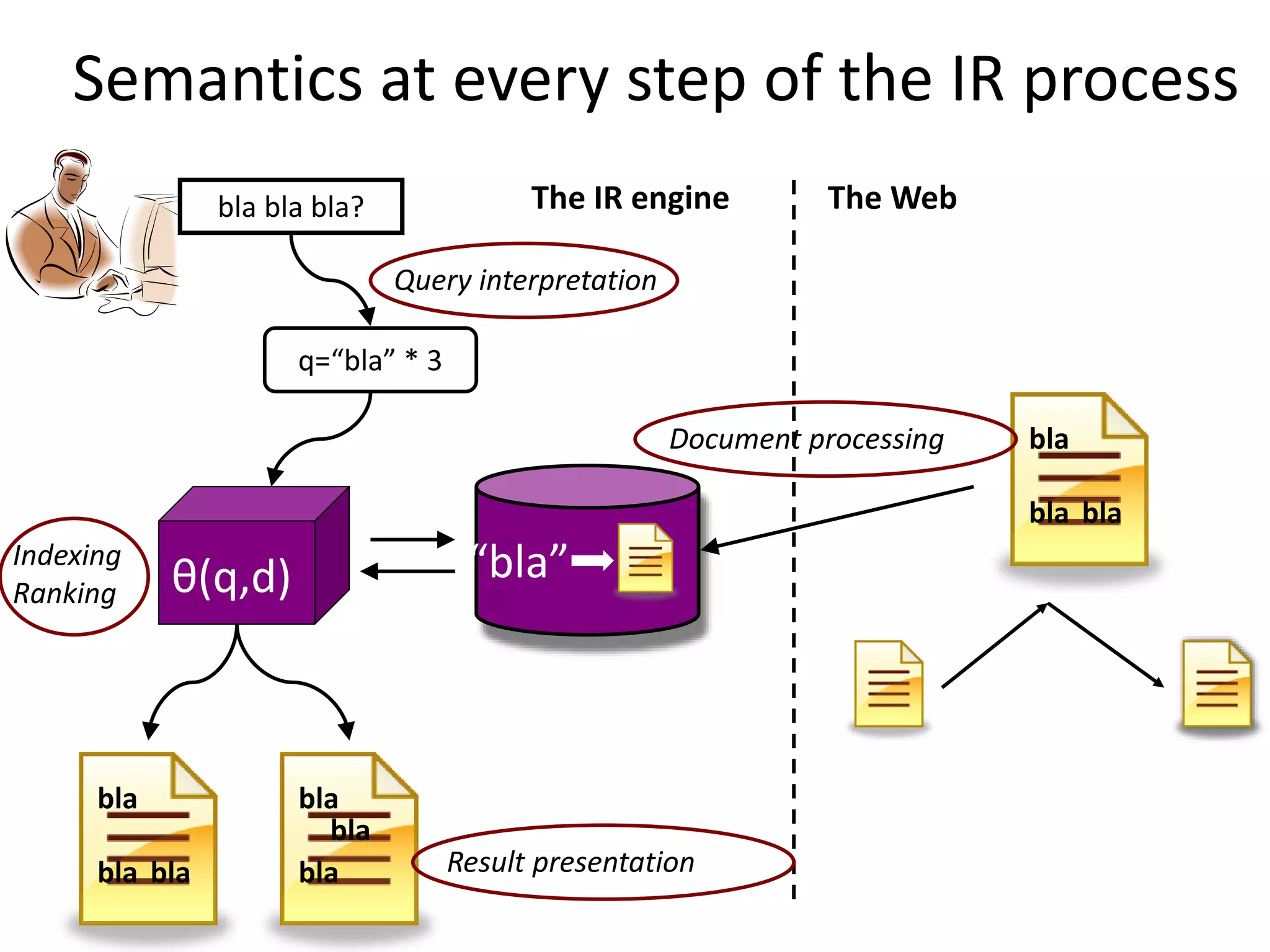

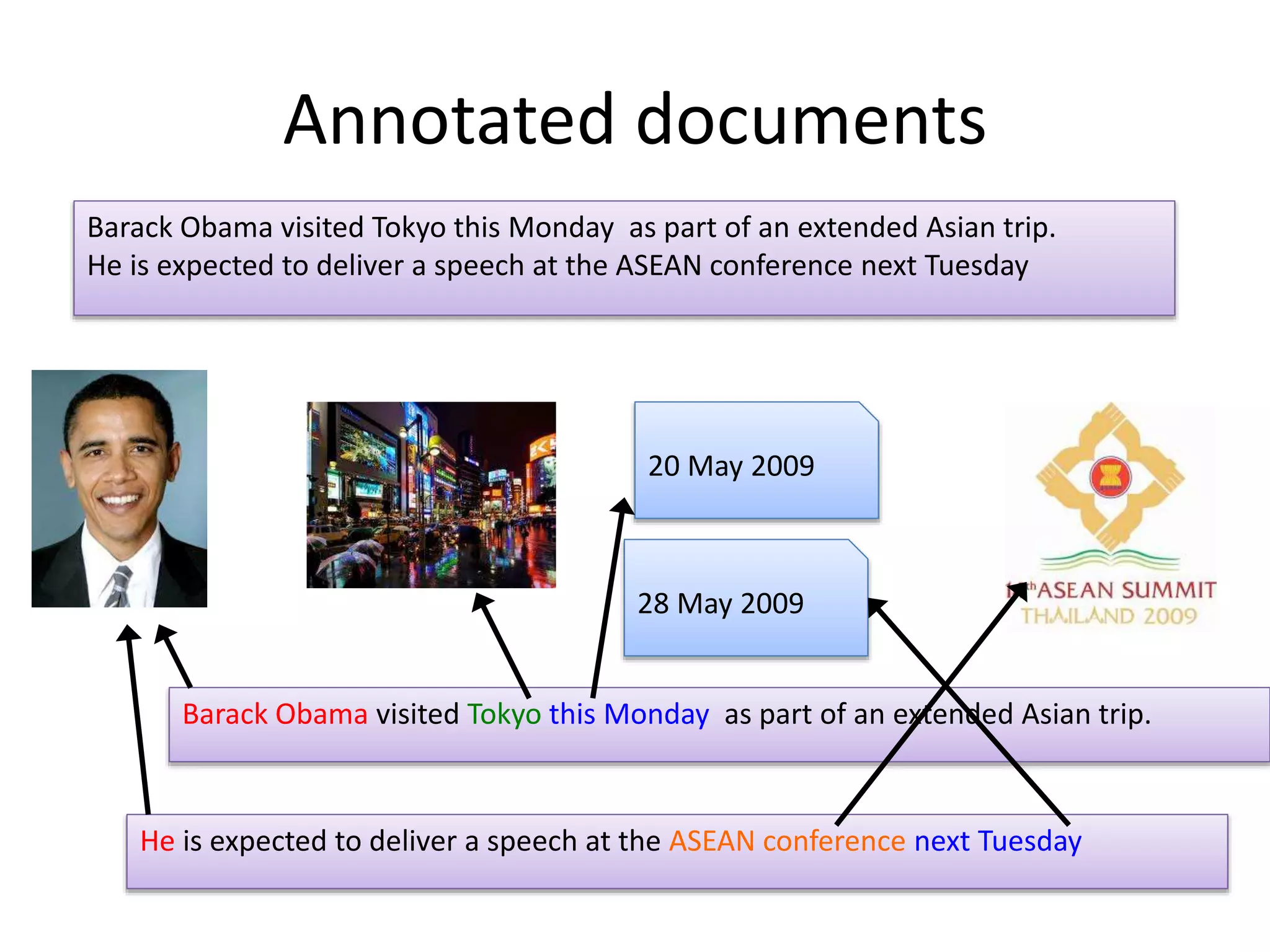

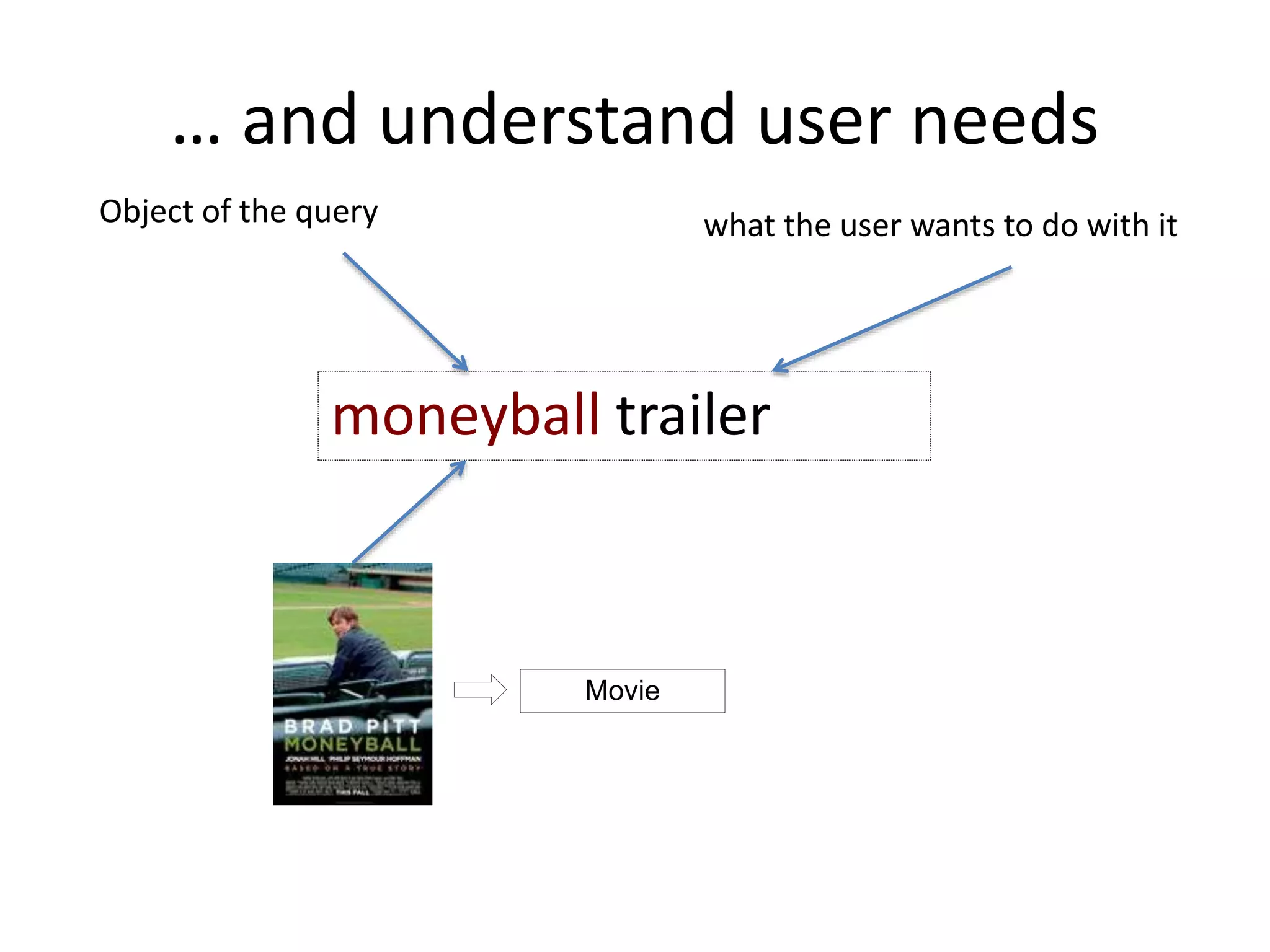



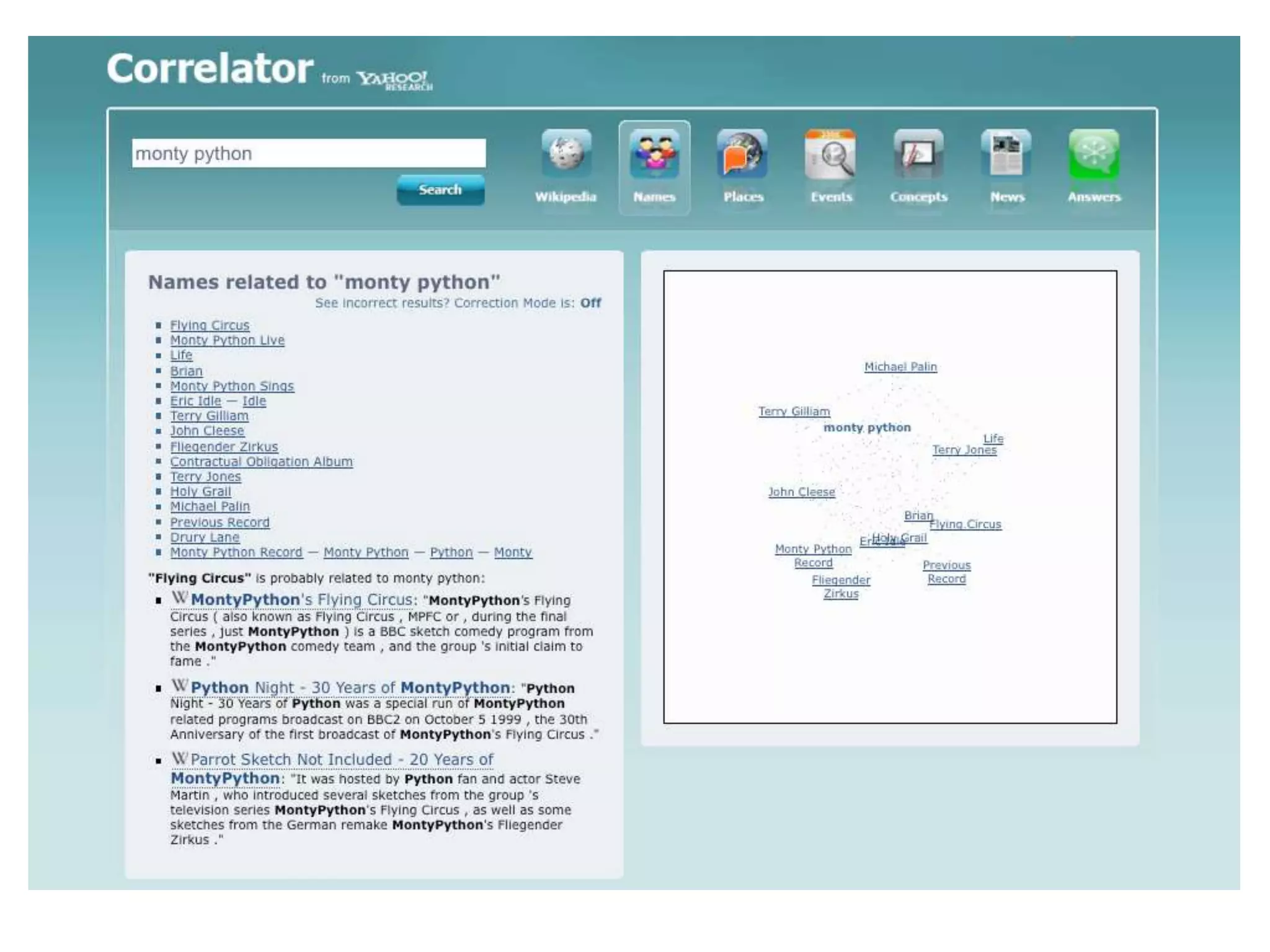
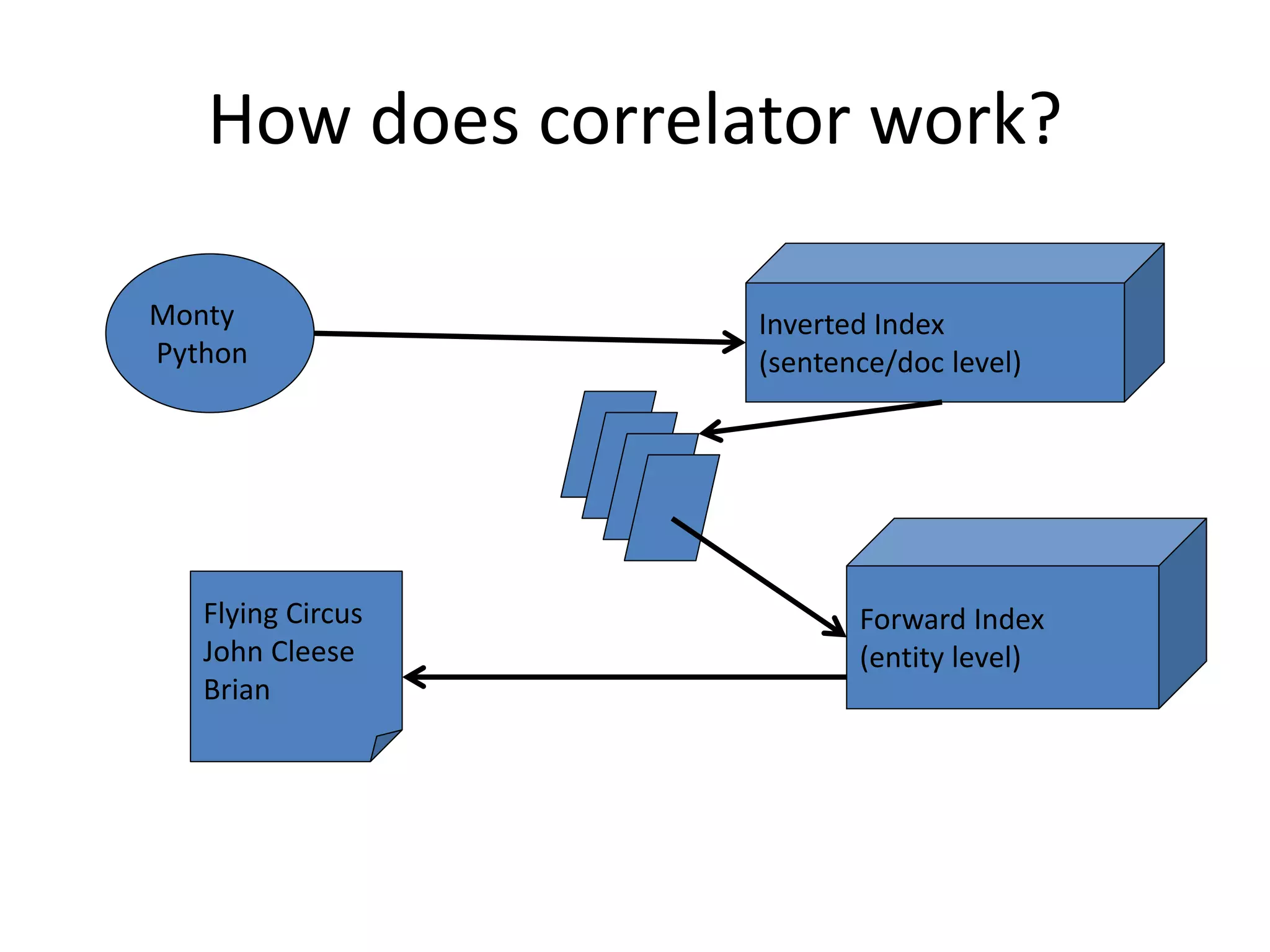


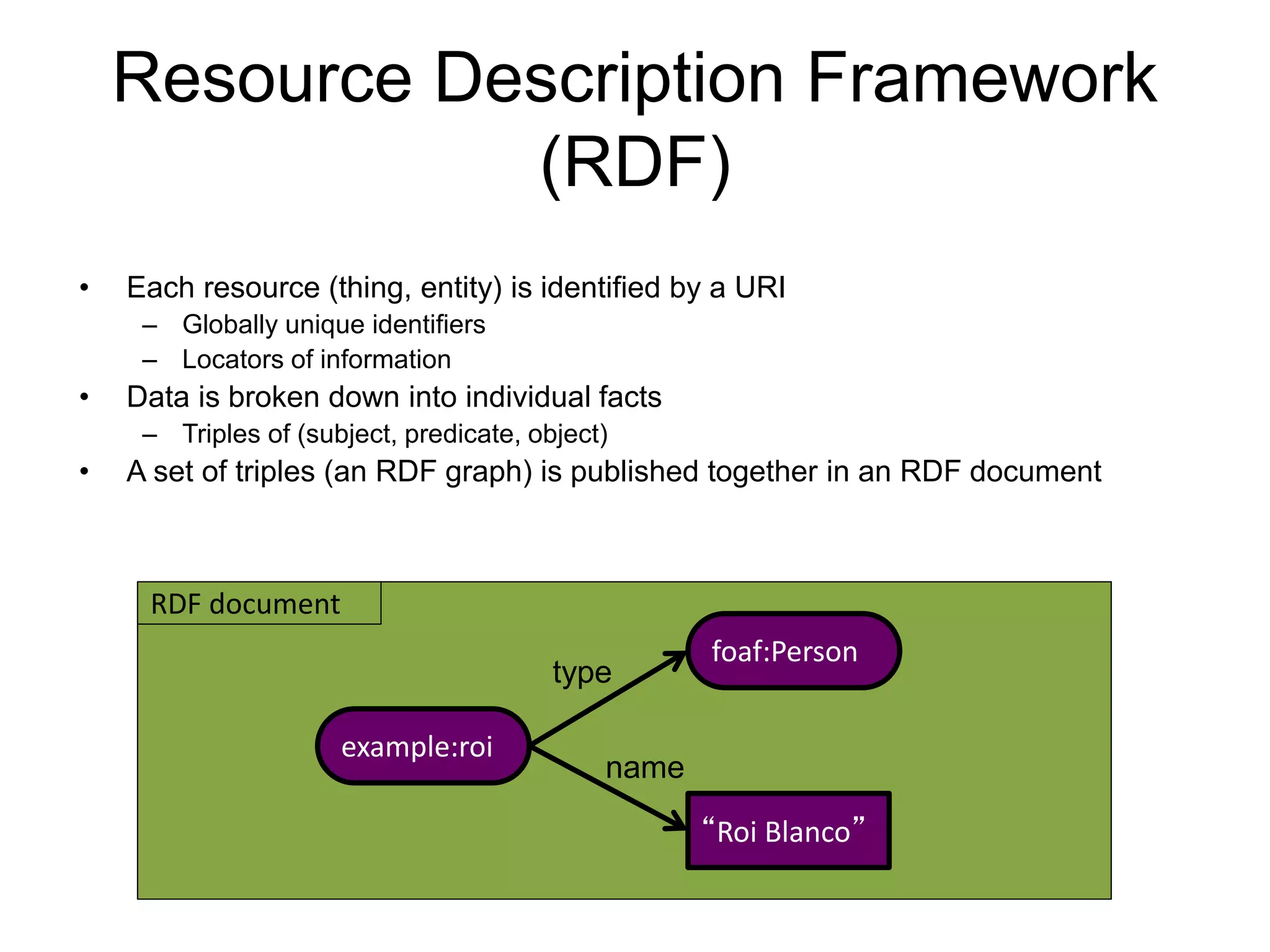
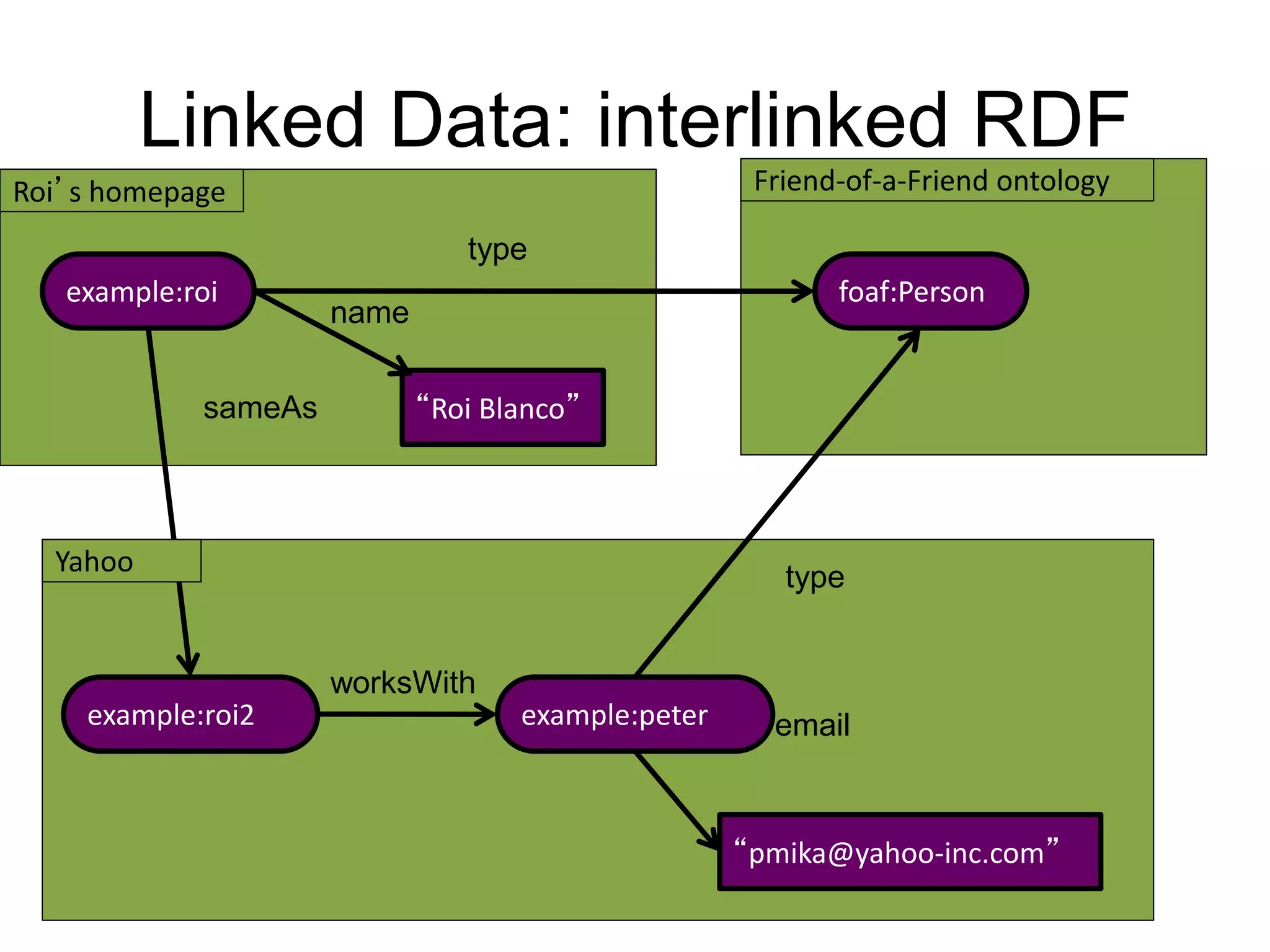



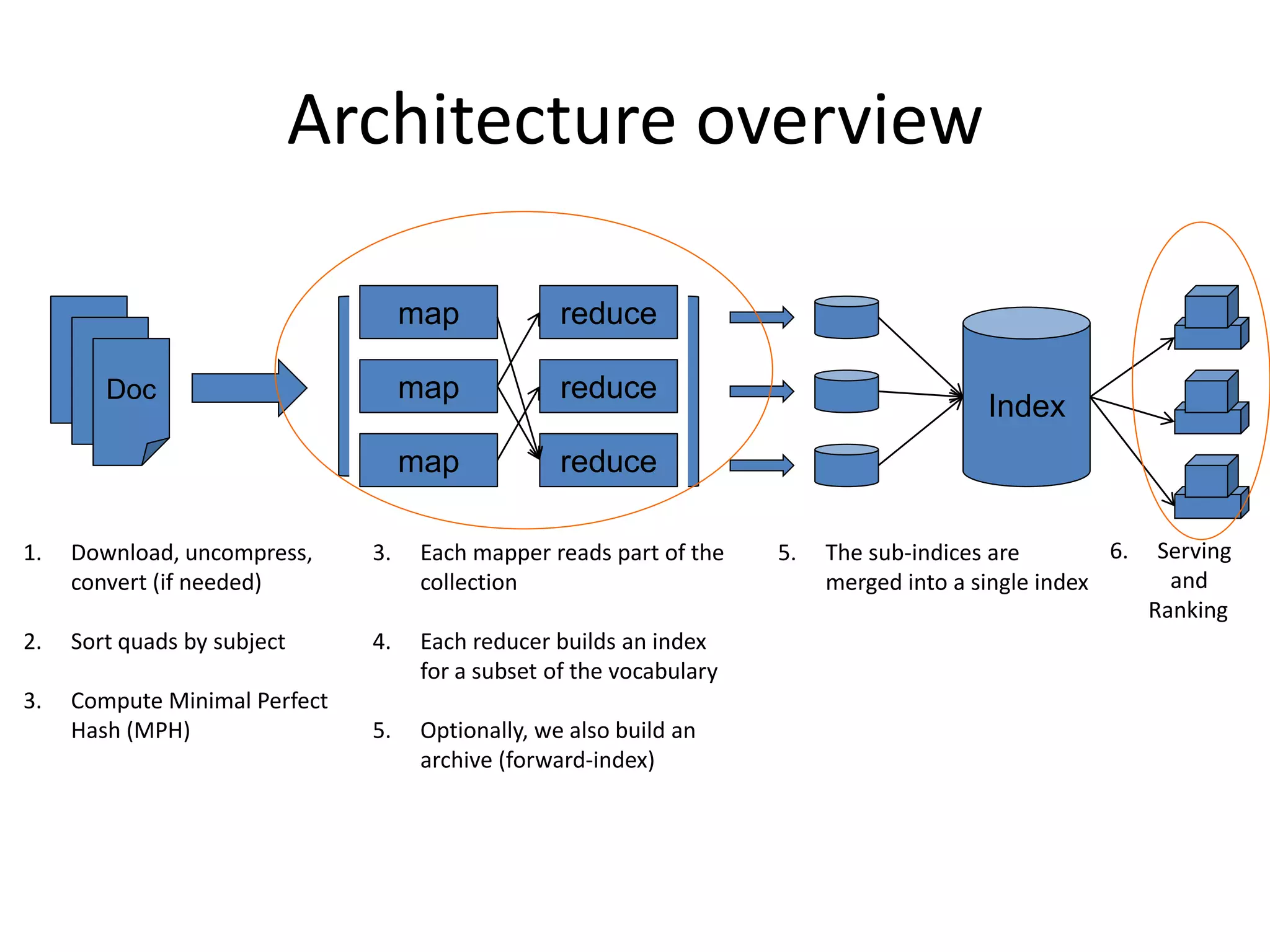






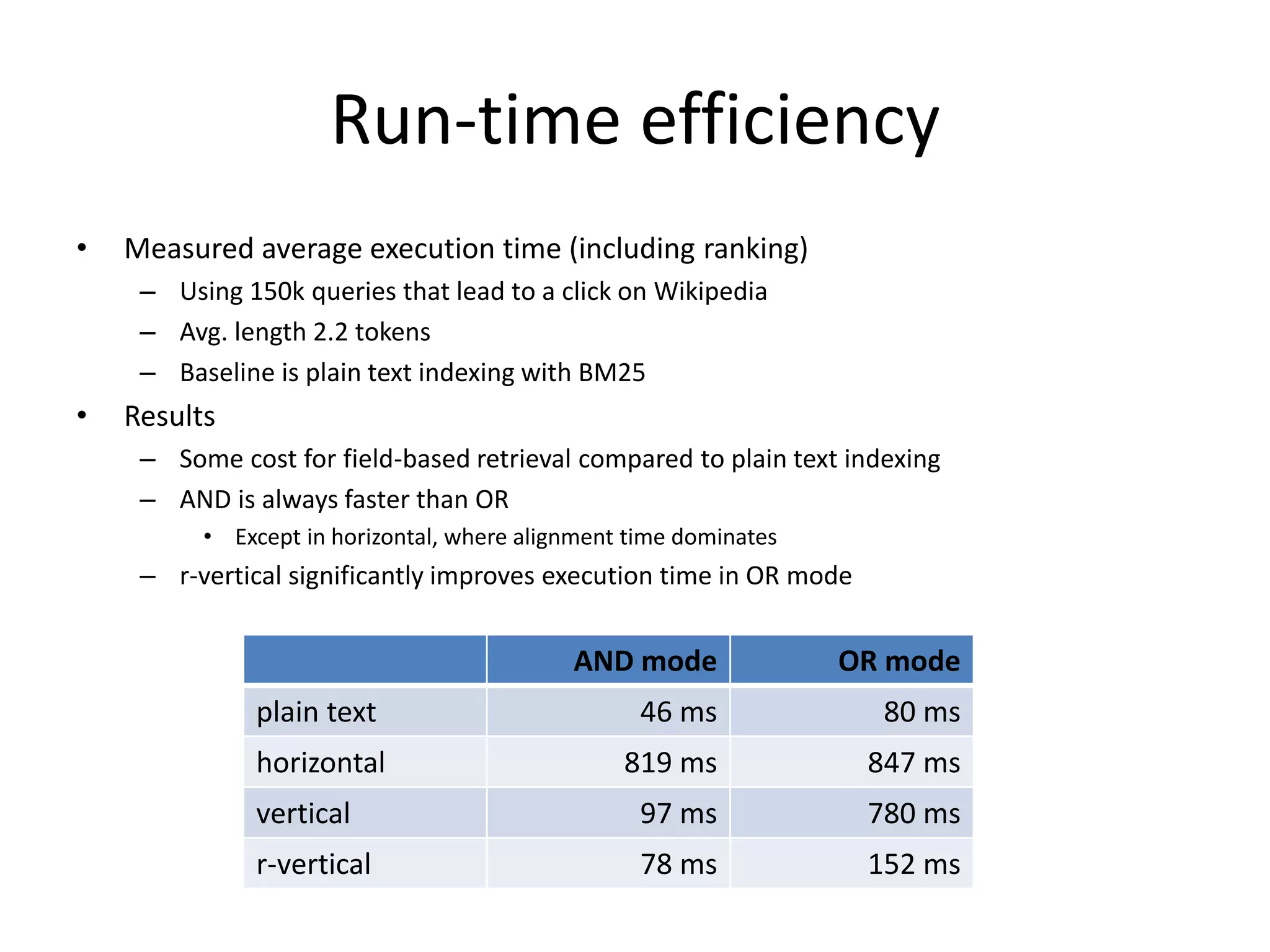



The document discusses large-scale semantic search and its importance in improving user queries and search results. It highlights the challenges in understanding user queries, the complexity of unstructured data, and the need for efficient indexing methods to support semantic analysis. Additionally, it covers various applications of semantic search, including enhanced search capabilities, recommender systems, and the integration of structured and unstructured data.













































































![Vibe Coding vs. Spec-Driven Development [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/vibecodingvsspecdrivendevelopment-251209105622-43f455e7-thumbnail.jpg?width=640&height=640&fit=bounds)














