Download to read offline












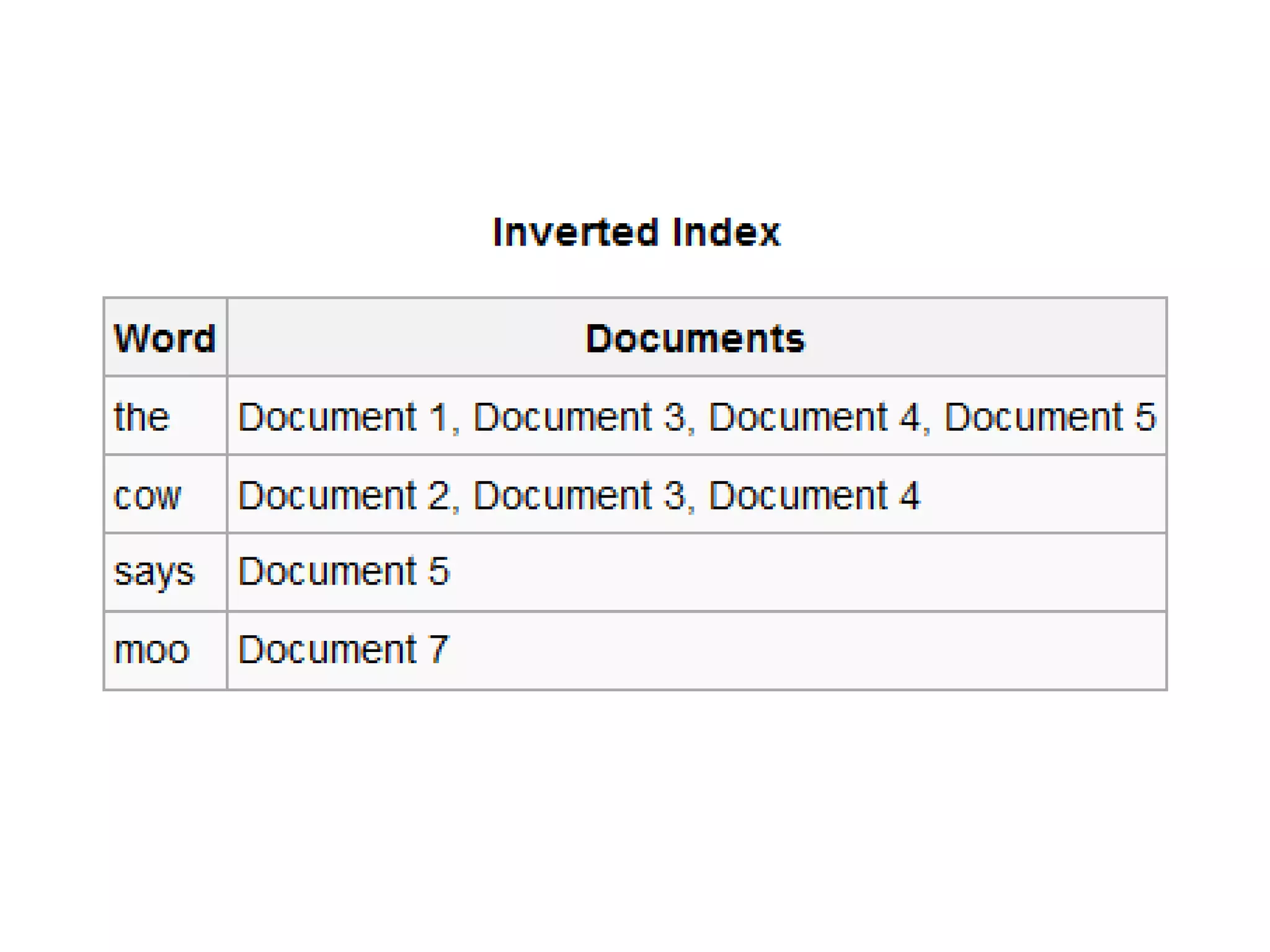
















Web indexing involves creating metadata to provide keywords for websites and intranets to improve searchability. It collects, parses, and stores data to facilitate fast information retrieval. The purpose is to optimize speed in finding relevant documents by indexing all content, though this requires significant computing resources. Index design incorporates concepts from various fields to balance factors like size, speed, and maintenance over time.



































































