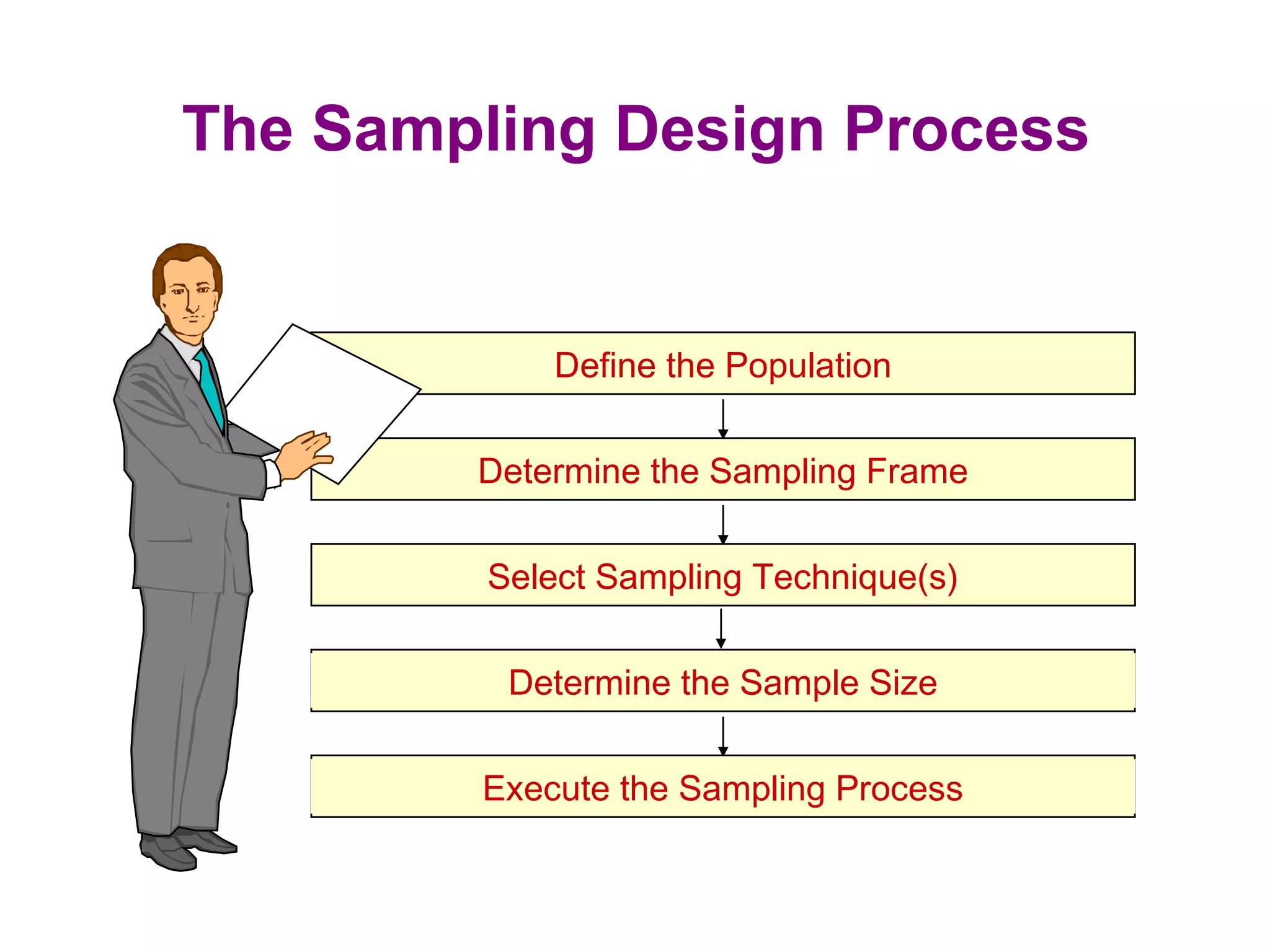
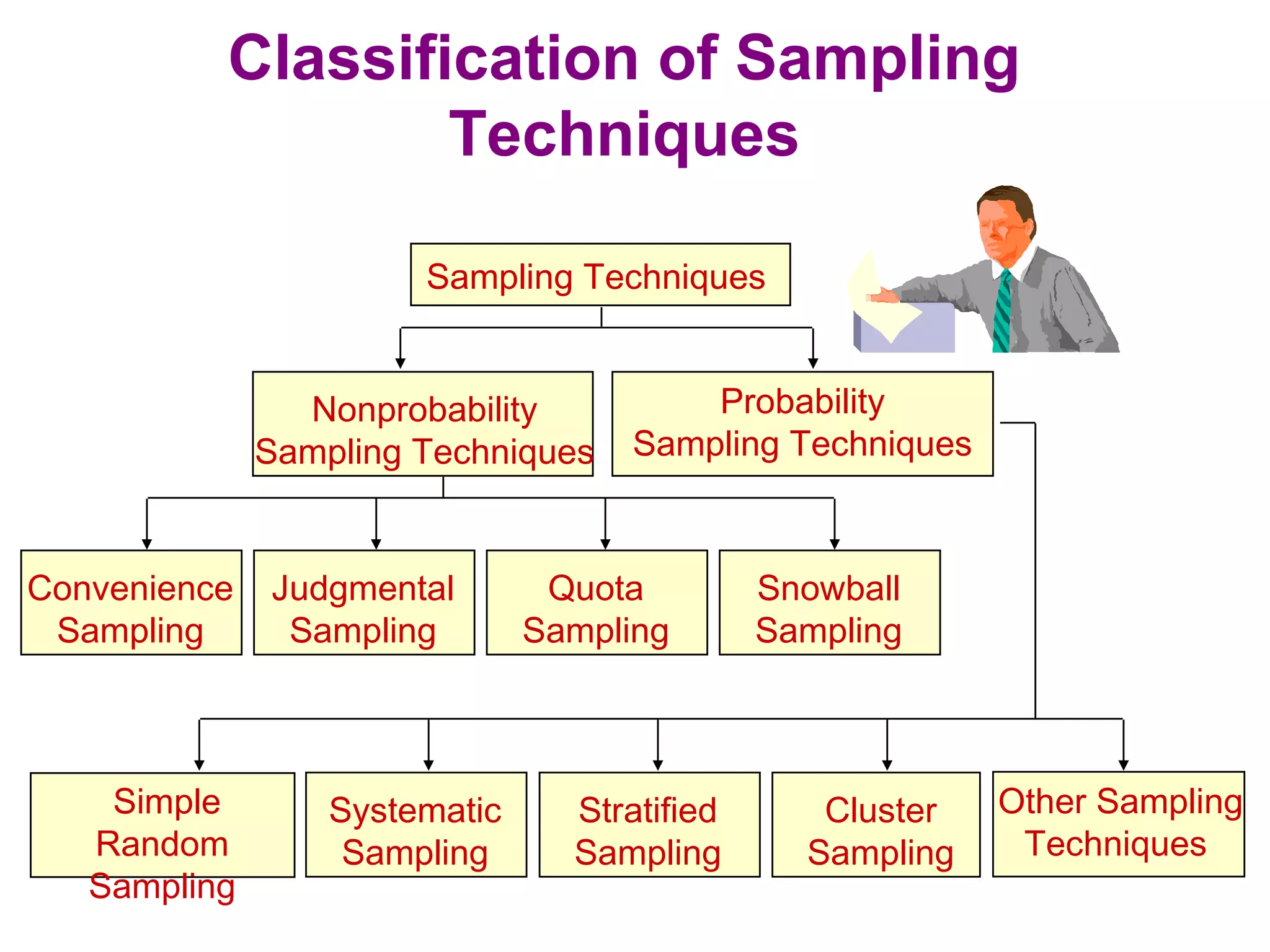
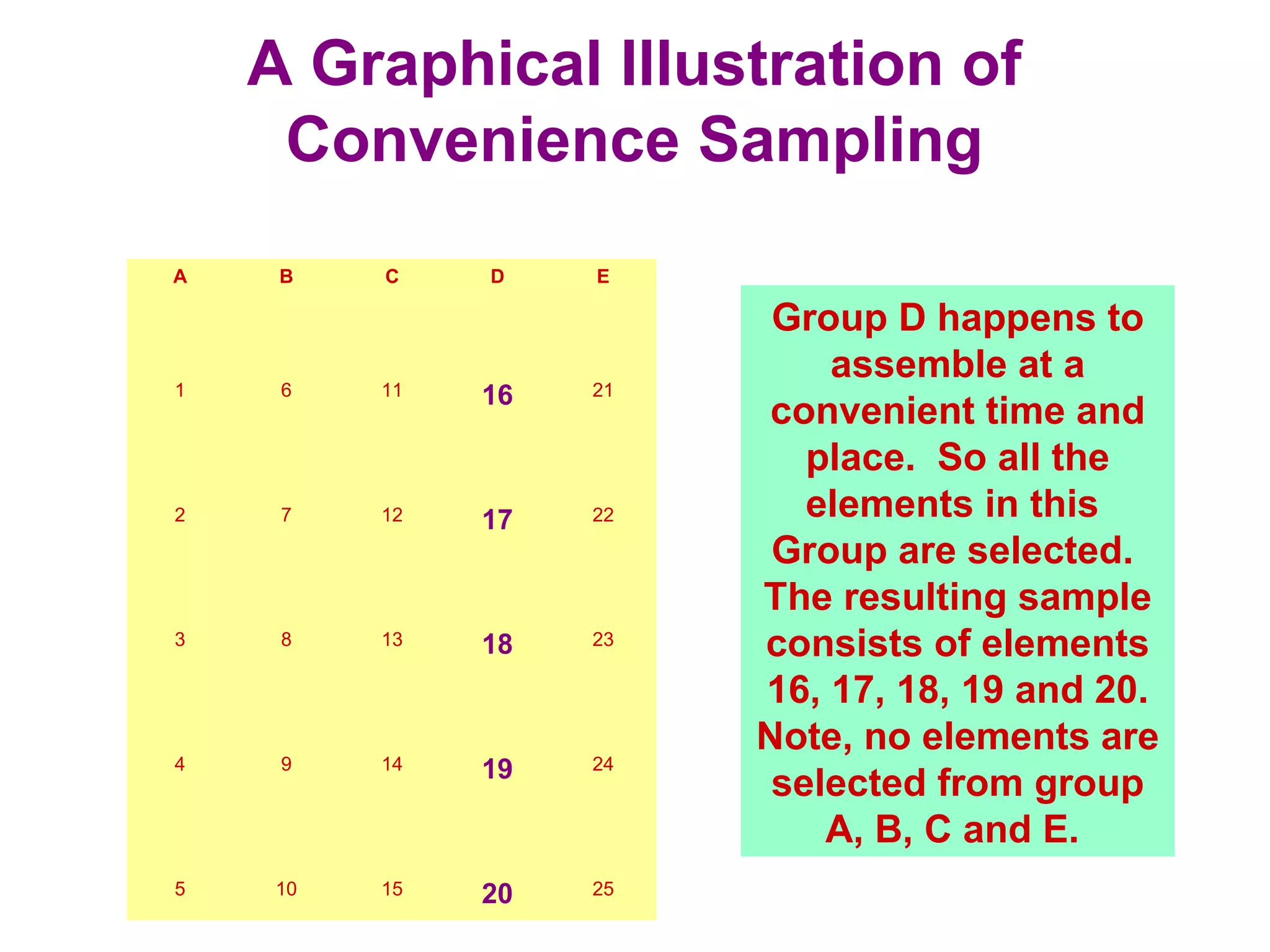
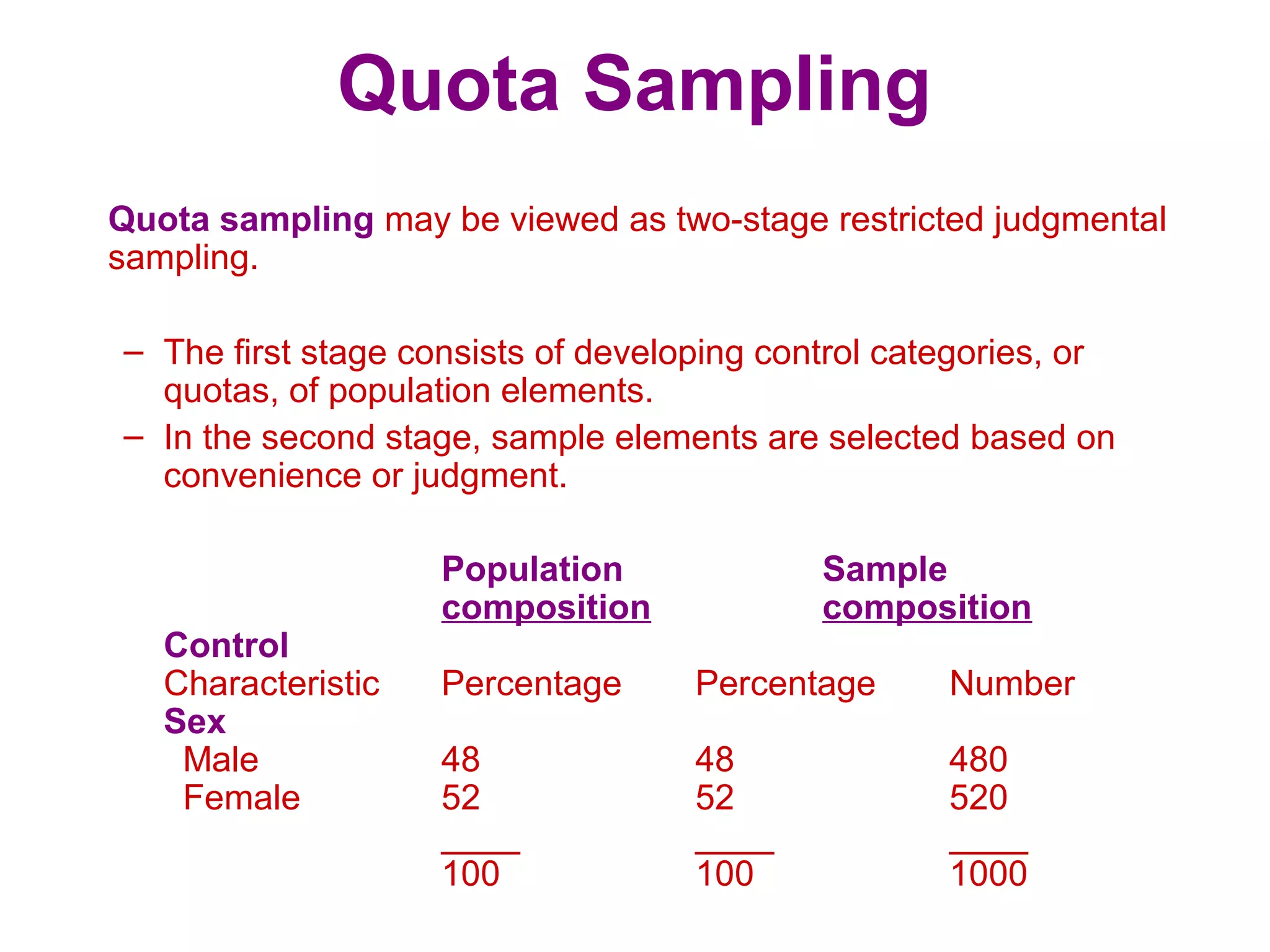
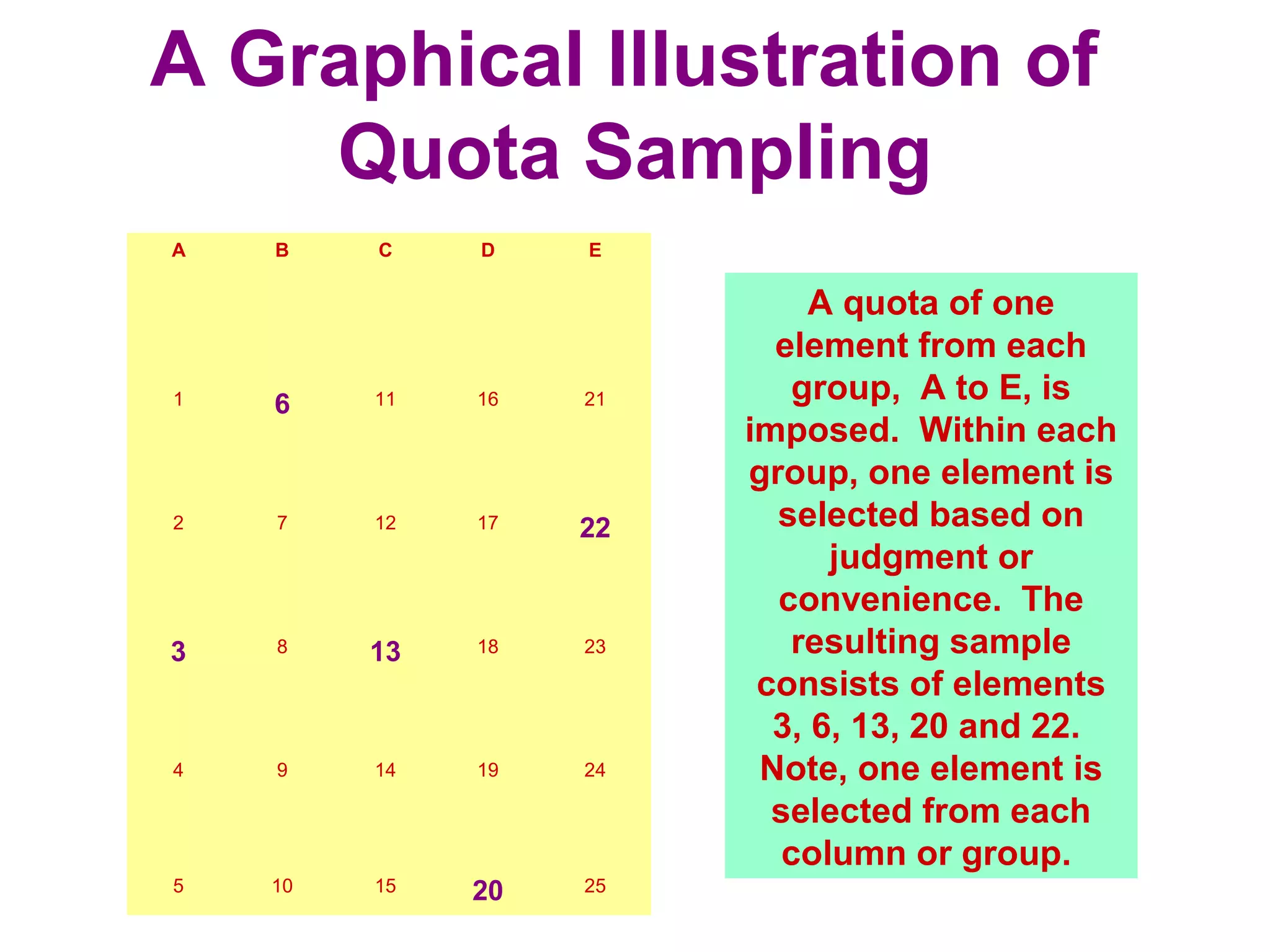
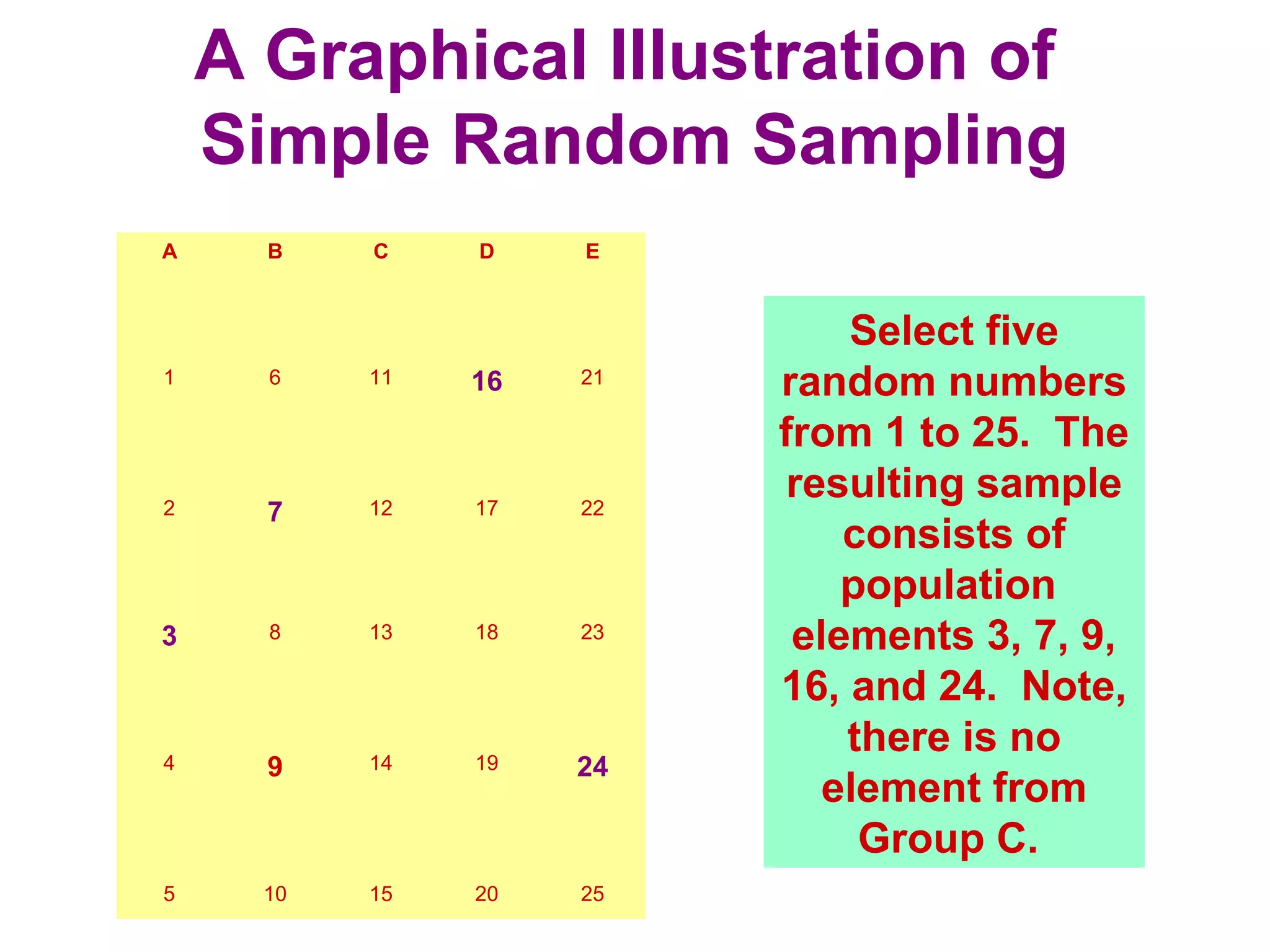
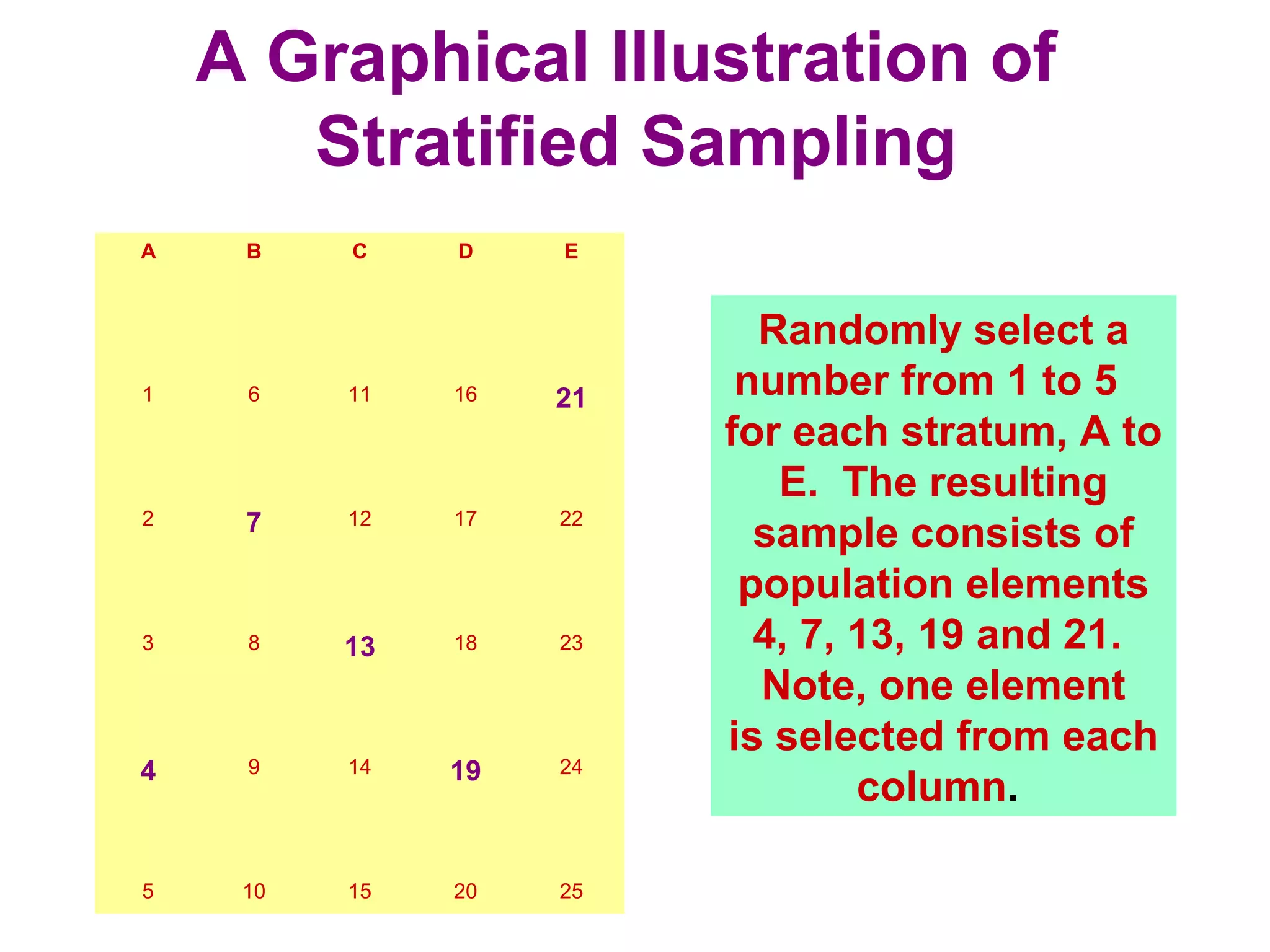
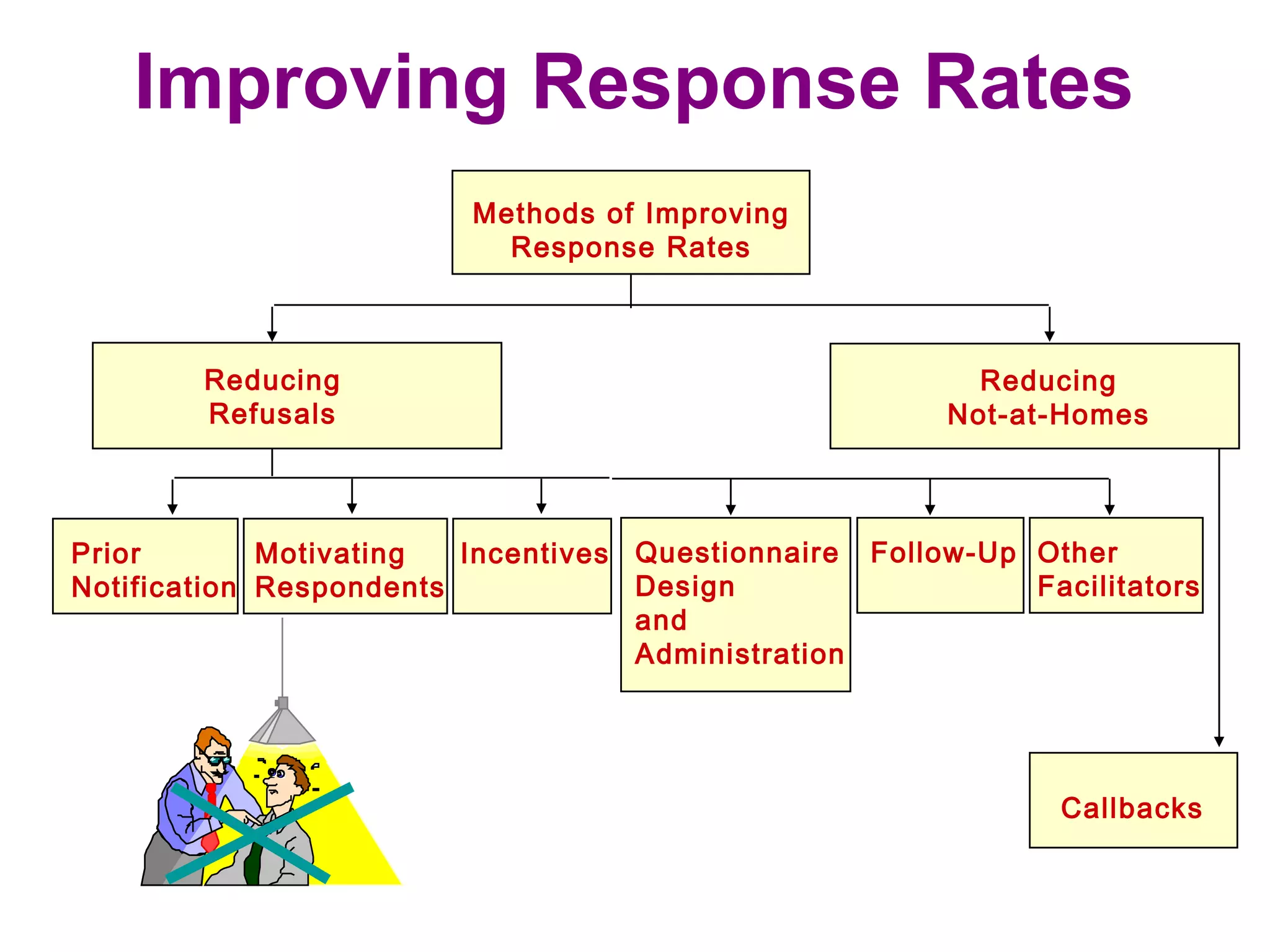
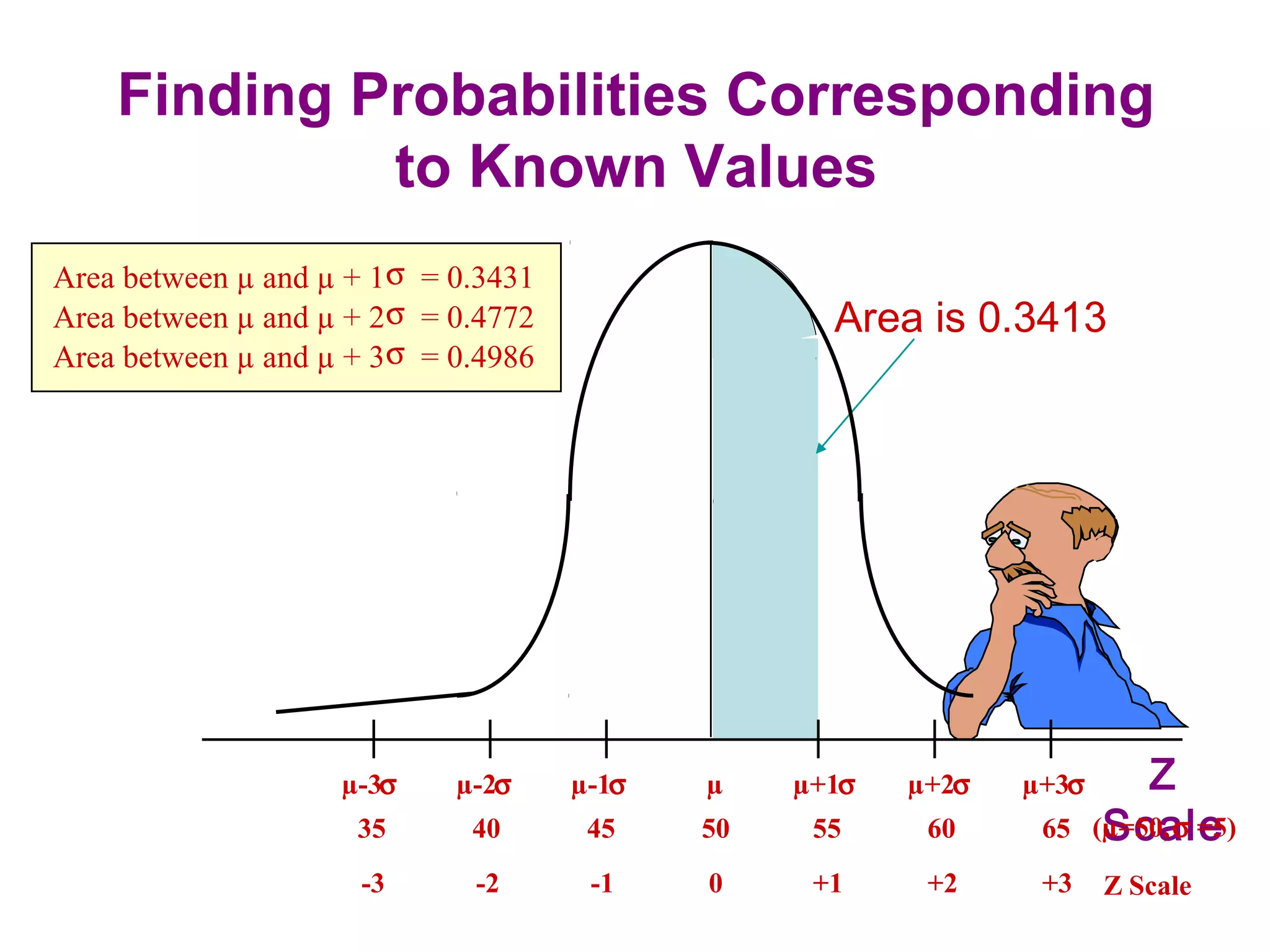
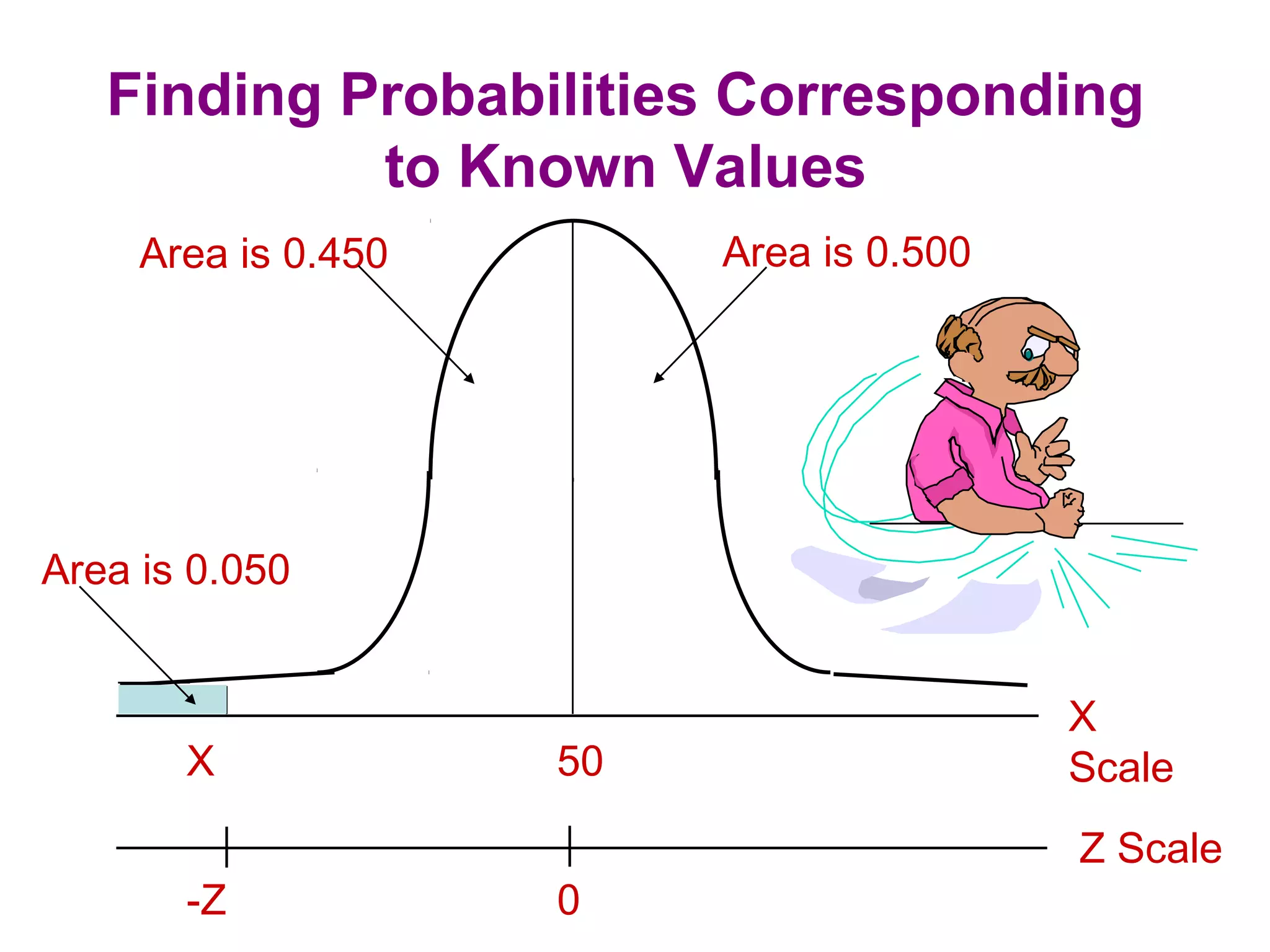
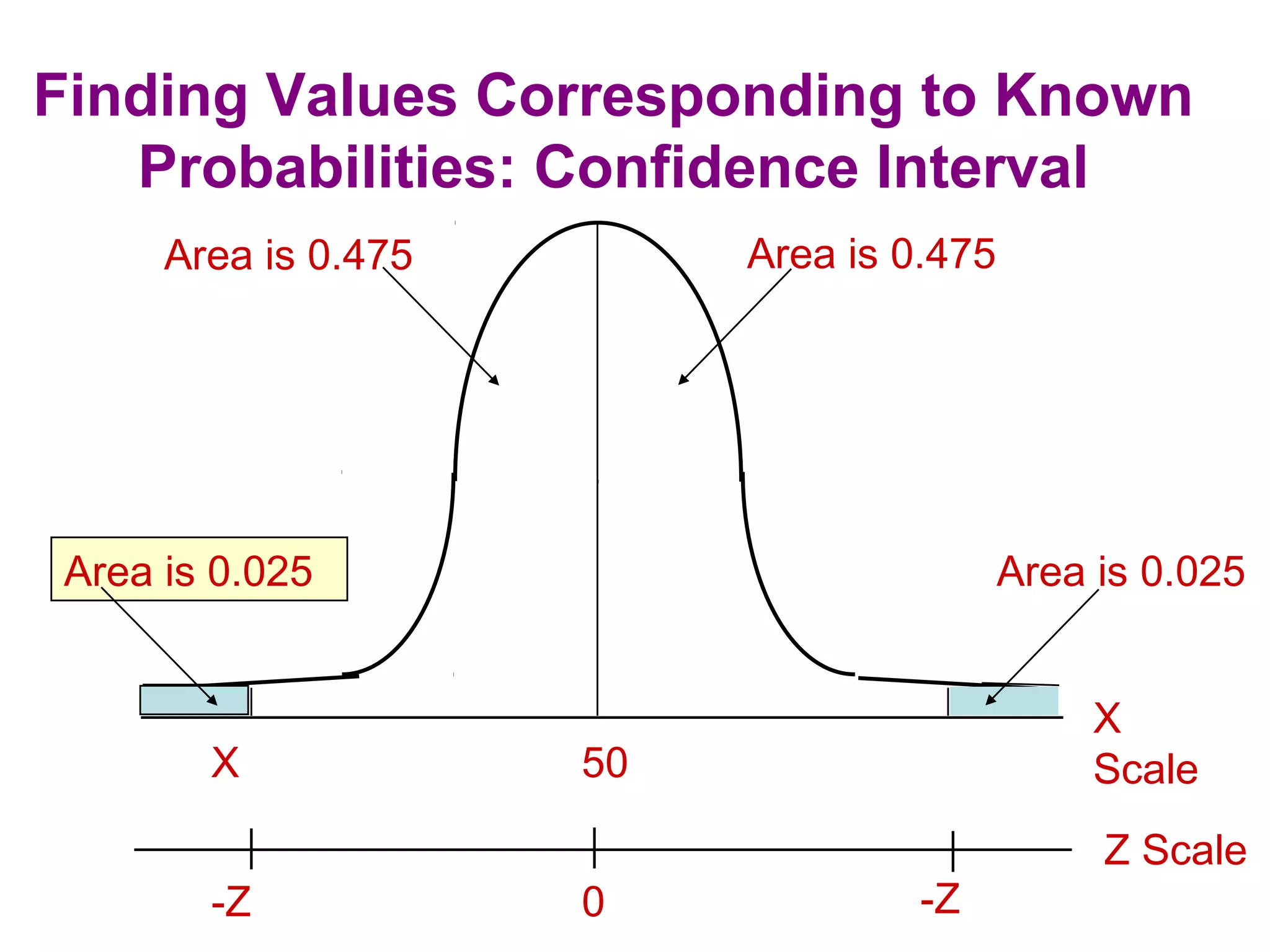
The sampling design process involves 6 steps: 1) define the target population, 2) determine the sampling frame, 3) select sampling techniques, 4) determine the sample size, 5) execute the sampling process, and 6) analyze results. Key factors in determining sample size include importance of decision, number of variables, analysis type, resource constraints, and completion rates. Common sampling techniques include probability methods like simple random sampling, stratified sampling, and cluster sampling as well as non-probability methods like convenience sampling and judgmental sampling. Each technique has strengths and weaknesses related to representativeness, bias, precision, and feasibility.