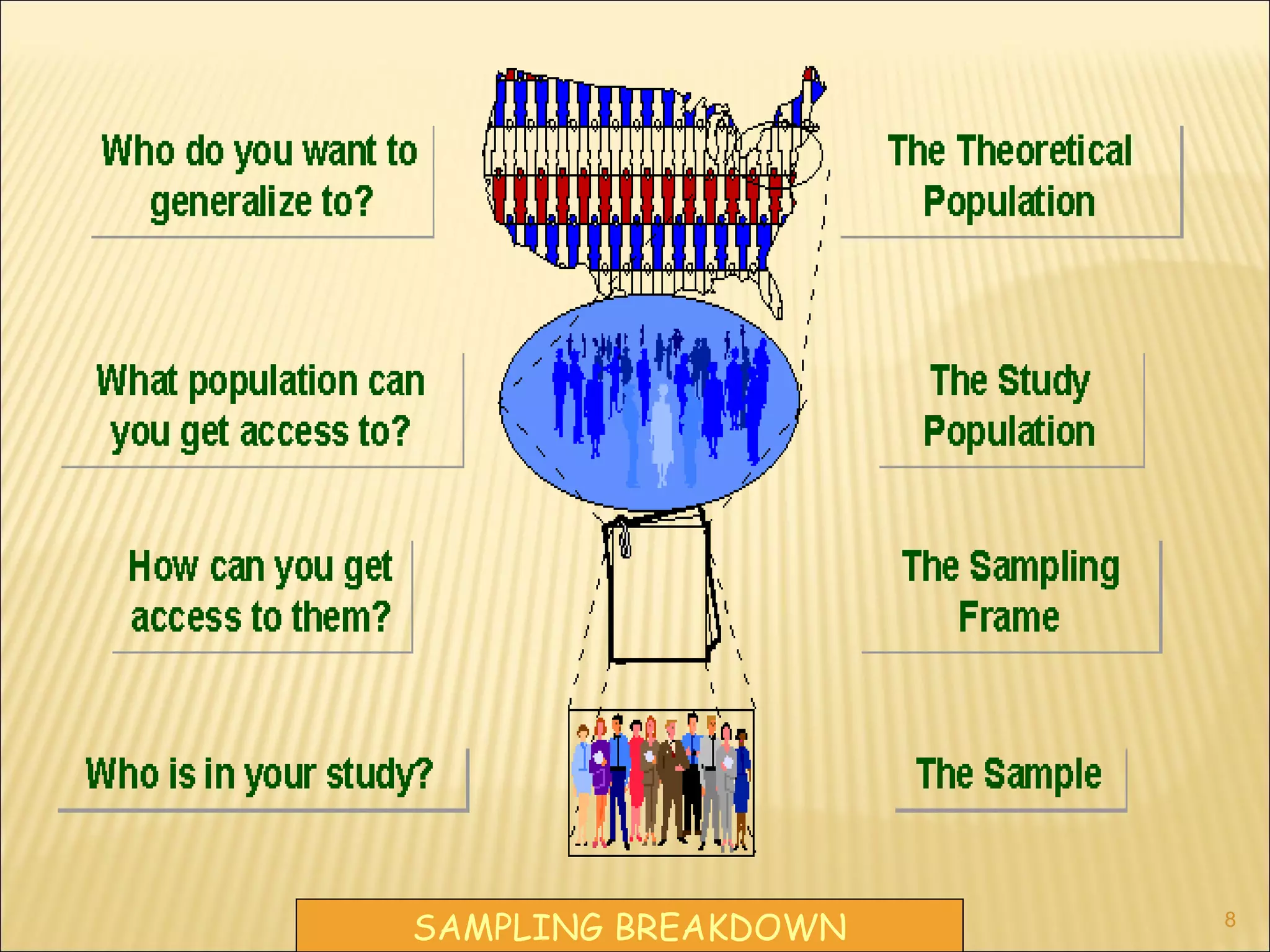
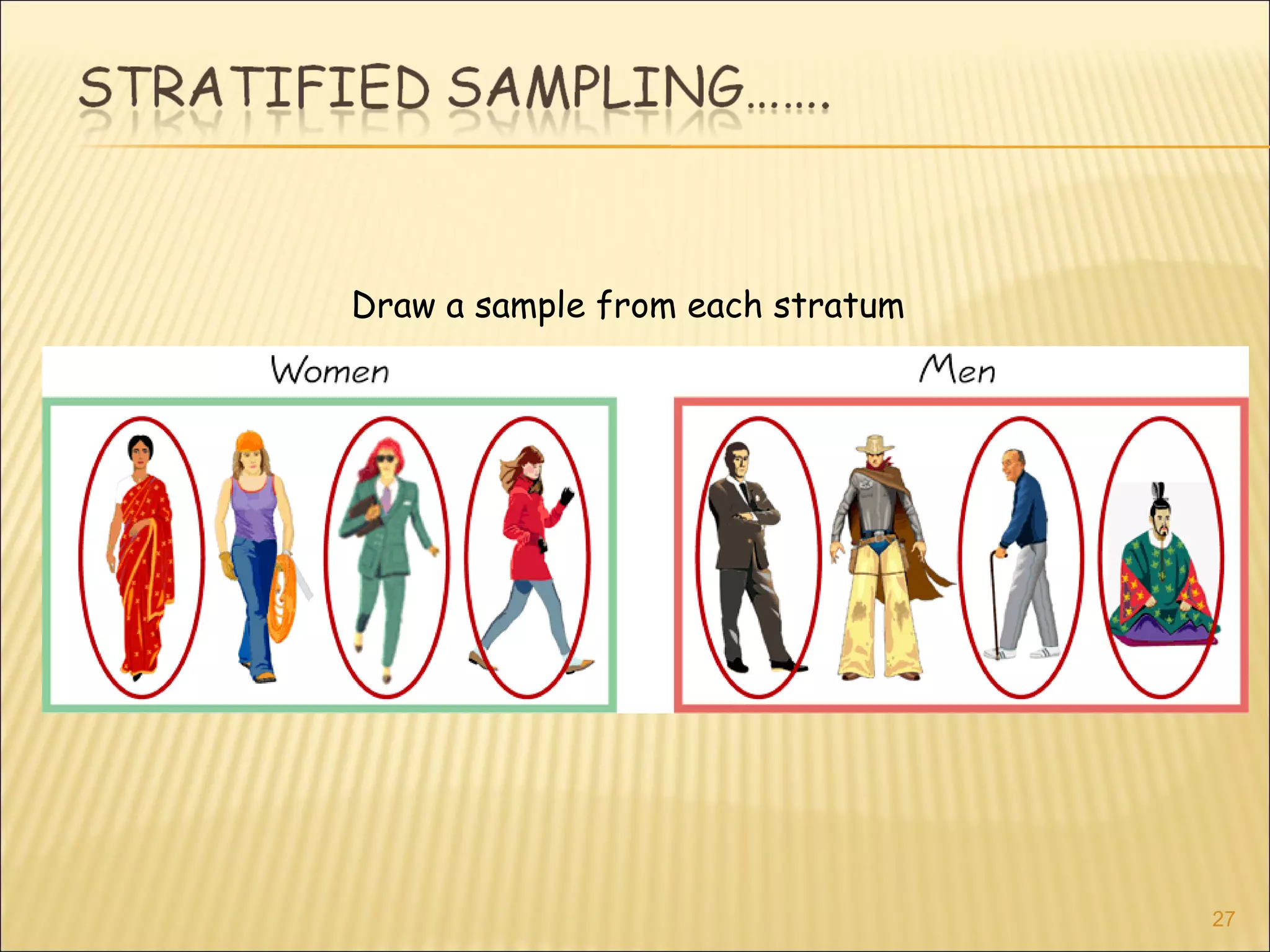
The document discusses various sampling methods and concepts in research methodology. It defines key terms like population, sample, sampling frame, probability sampling, and non-probability sampling. It then explains different probability sampling techniques like simple random sampling, systematic sampling, stratified sampling, cluster sampling, and multistage sampling. It also discusses non-probability sampling methods and compares the advantages and disadvantages of different approaches. The document emphasizes the importance of representative sampling.














































![ Event contingent – records data when certain events occur
Interval contingent – records data according to the passing of a
certain period of time
ESM has several disadvantages. One of the disadvantages of
ESM is it can sometimes be perceived as invasive and intrusive
by participants. ESM also leads to possible self-selection bias.
It may be that only certain types of individuals are willing to
participate in this type of study creating a non-random sample.
Another concern is related to participant cooperation.
Participants may not be actually fill out their diaries at the
specified times. Furthermore, ESM may substantively change
the phenomenon being studied. Reactivity or priming effects
may occur, such that repeated measurement may cause
changes in the participants' experiences. This method of
sampling data is also highly vulnerable to common method
variance.[6]
49](https://image.slidesharecdn.com/samplingtechniques-190501043139/75/Sampling-techniques-49-2048.jpg)












![Sampling1[1]](https://cdn.slidesharecdn.com/ss_thumbnails/sampling11-120509162836-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)








































































