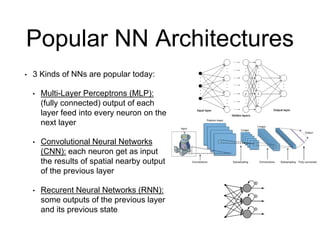
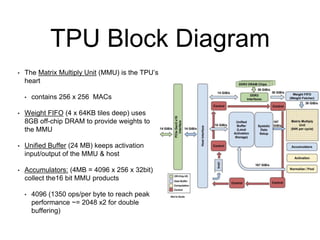
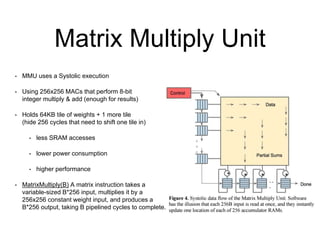
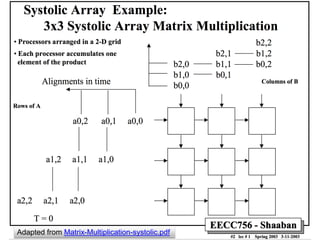
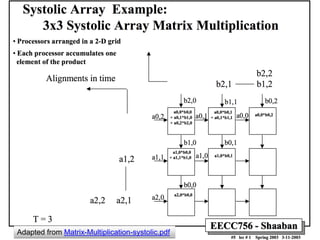
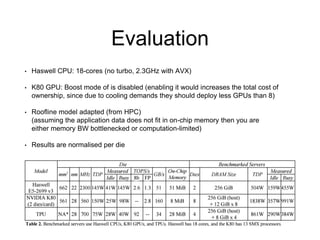
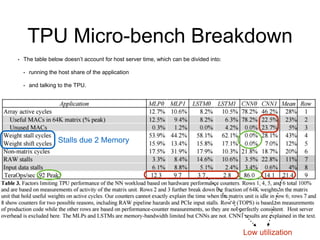
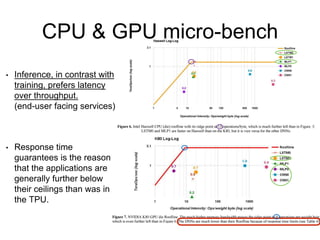
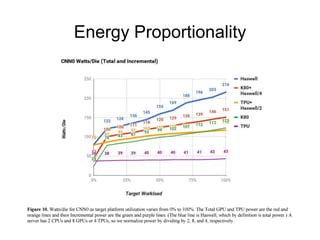
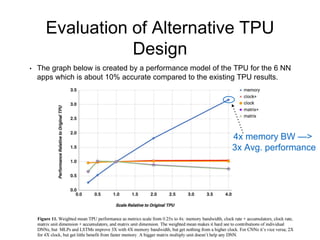
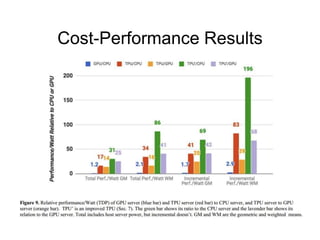
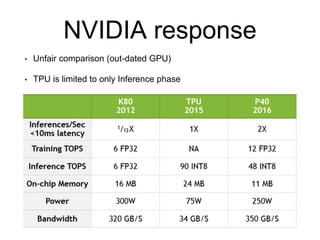
The document analyzes the performance of Google's Tensor Processing Unit (TPU) compared to CPUs and GPUs for neural network inference workloads. It finds that the TPU, an ASIC designed specifically for neural network operations, achieves a 25-30x speedup over CPUs and GPUs. This is due to the TPU having many more simple integer math cores and on-chip memory optimized for neural network computations. The document concludes the TPU is 30-80x more energy efficient than other hardware and its performance could increase further with higher memory bandwidth.


































































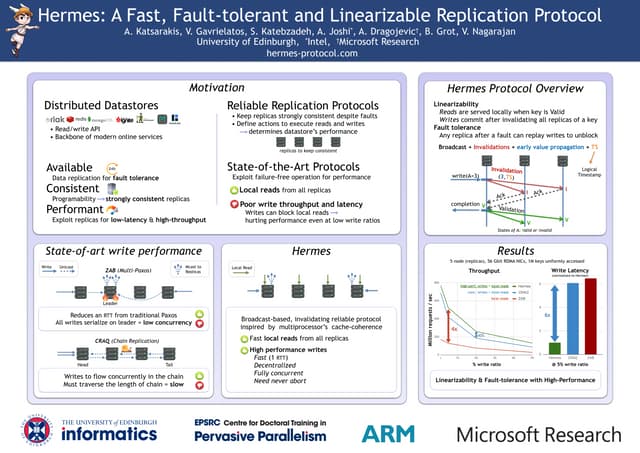
![[VLDB'25] The LAW Theorem: Local Reads and Linearizable Asynchronous Replication](https://cdn.slidesharecdn.com/ss_thumbnails/law-vldb25-latestv3-251019111018-53070a6a-thumbnail.jpg?width=640&height=640&fit=bounds)






![Zeus: Locality-aware Distributed Transactions [Eurosys '21 presentation]](https://cdn.slidesharecdn.com/ss_thumbnails/zeus-eurosys21-210419094422-thumbnail.jpg?width=640&height=640&fit=bounds)