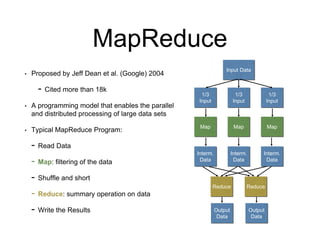
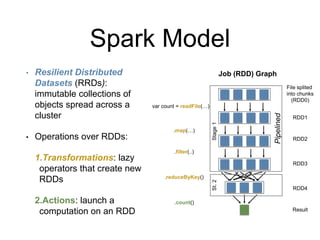
This document discusses distributed processing frameworks for big data. It introduces MapReduce as a programming model that enables parallel processing of large datasets across clusters. While MapReduce was novel, it was limited to batch processing and only supported map and reduce operations. Spark was then proposed as another framework to replace MapReduce, representing computations as directed acyclic graphs and caching datasets in memory for better performance. Both systems introduced challenges in measuring and improving performance at scale.
























































![[VLDB'25] The LAW Theorem: Local Reads and Linearizable Asynchronous Replication](https://cdn.slidesharecdn.com/ss_thumbnails/law-vldb25-latestv3-251019111018-53070a6a-thumbnail.jpg?width=640&height=640&fit=bounds)



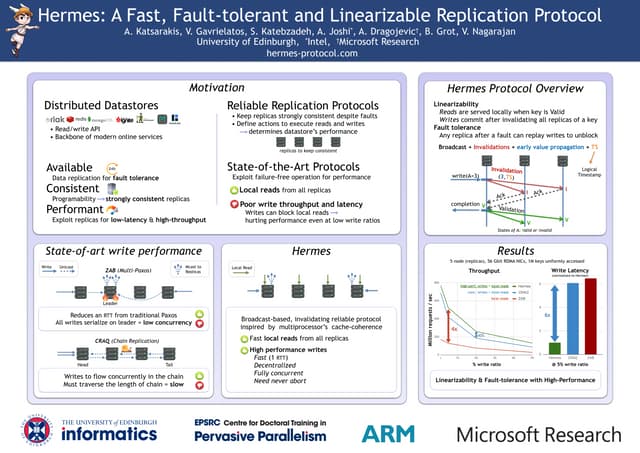



![Zeus: Locality-aware Distributed Transactions [Eurosys '21 presentation]](https://cdn.slidesharecdn.com/ss_thumbnails/zeus-eurosys21-210419094422-thumbnail.jpg?width=640&height=640&fit=bounds)



















