Download as PDF, PPTX






![9 9
NUMA Application Level Tuning:
Shared Memory Threading Example: TRIAD
Parallelized time consuming hotspot “TRIAD” (e.g.
of STREAM benchmark) using OpenMP
main() {
…
#pragma omp parallel
{
//Parallelized TRIAD loop…
#pragma omp parallel for private(j)
for (j=0; j<N; j++)
a[j] = b[j]+scalar*c[j];
} //end omp parallel
…
} //end main
Parallelizing hotspots may not be sufficient for NUMA
Notes for Intel Software Conference – Brazil, May 2014](https://image.slidesharecdn.com/numaistep2014-140603143243-phpapp02/85/Notes-on-NUMA-architecture-9-320.jpg)
![10 10
NUMA Shared Memory Threading
Example ( Linux* )
KMP_AFFINITY=compact,0,verbose
main() {
…
#pragma omp parallel
{
#pragma omp for private(i)
for(i=0;i<N;i++)
{ a[i] = 10.0; b[i] = 10.0; c[i] = 10.0;}
…
//Parallelized TRIAD loop…
#pragma omp parallel for private(j)
for (j=0; j<N; j++)
a[j] = b[j]+scalar*c[j];
} //end omp parallel …
} //end main
Each thread initializes its data
pinning the pages to local memory
Environment variable
to pin affinity
Same thread that initialized
data uses data
Notes for Intel Software Conference – Brazil, May 2014](https://image.slidesharecdn.com/numaistep2014-140603143243-phpapp02/85/Notes-on-NUMA-architecture-10-320.jpg)



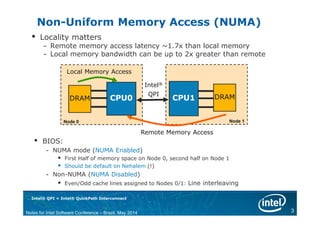
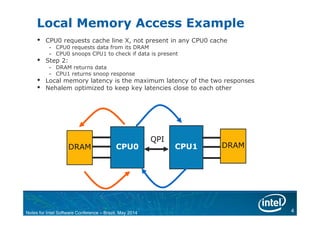
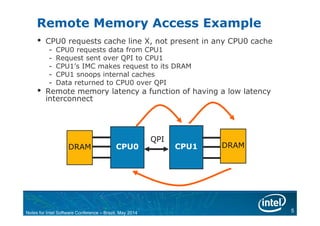
The document discusses NUMA (Non-Uniform Memory Access) architecture and optimization. With NUMA, memory is divided across multiple nodes and latency depends on memory location. Local memory has the lowest latency while remote memory has higher latency. The document provides examples of local and remote memory access and discusses how process-parallel and shared-memory threading applications are affected by NUMA. It also covers NUMA-aware operating system differences, techniques for process affinity, and NUMA optimization strategies like minimizing remote memory access.





















































































