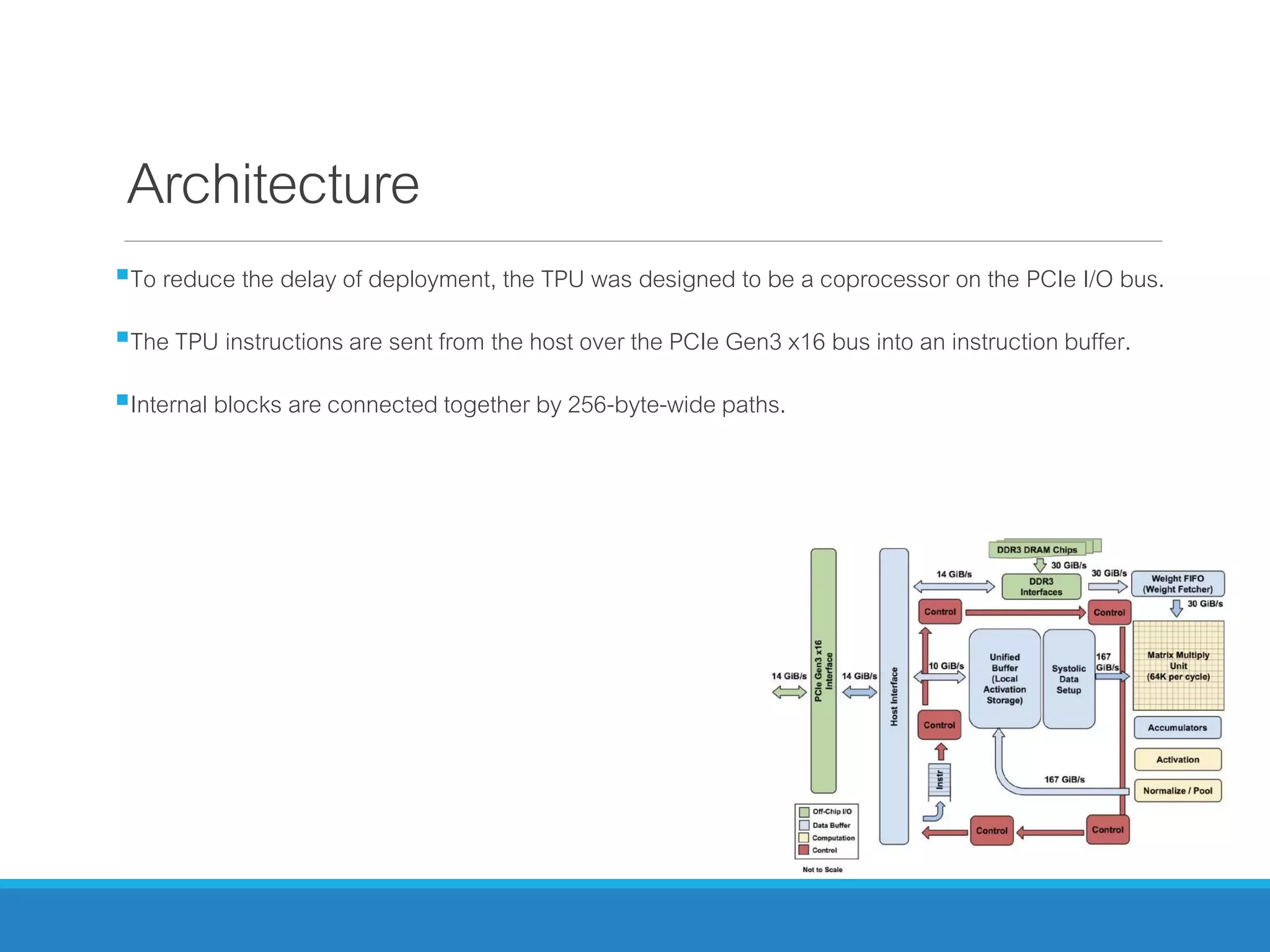
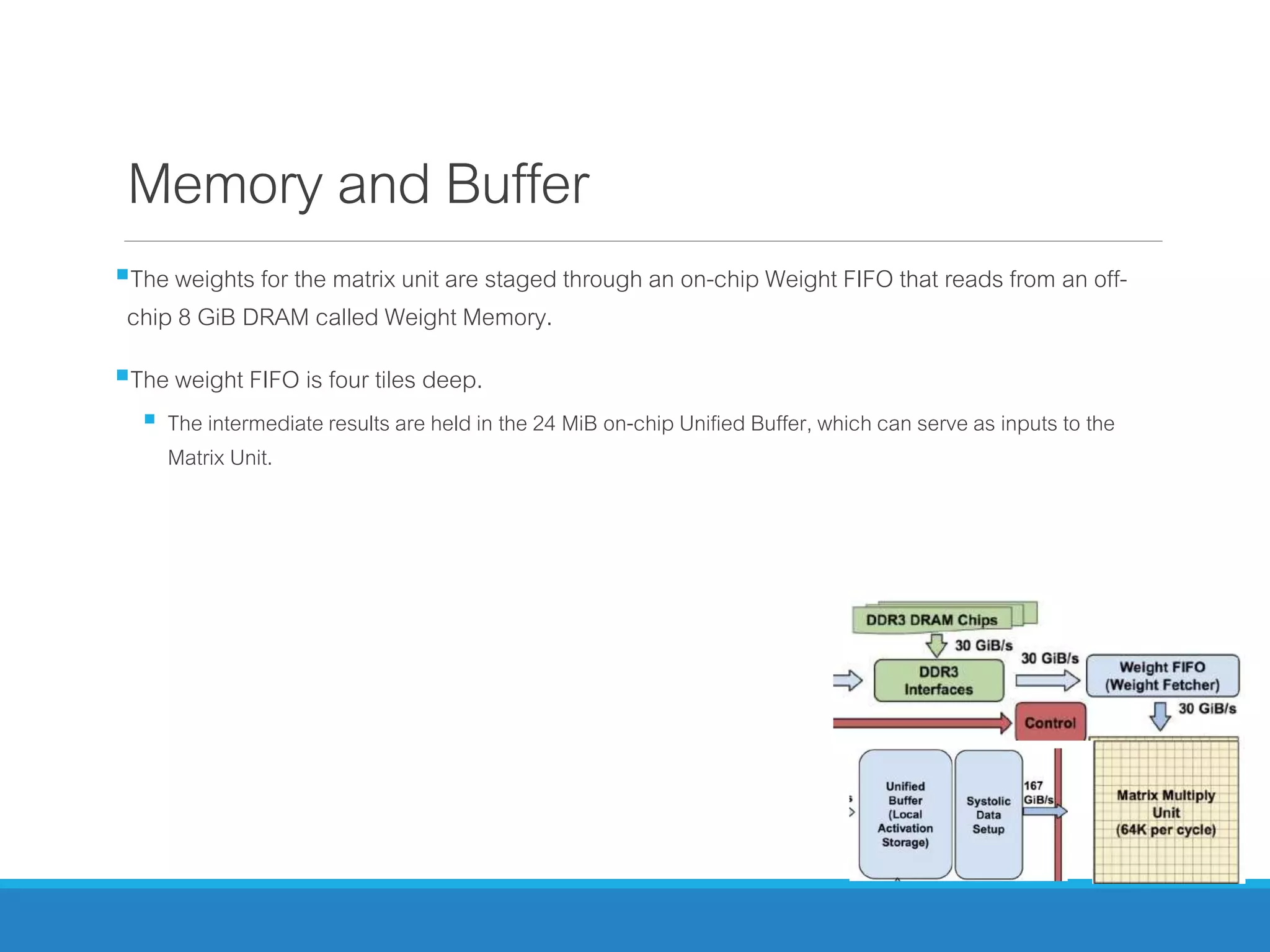
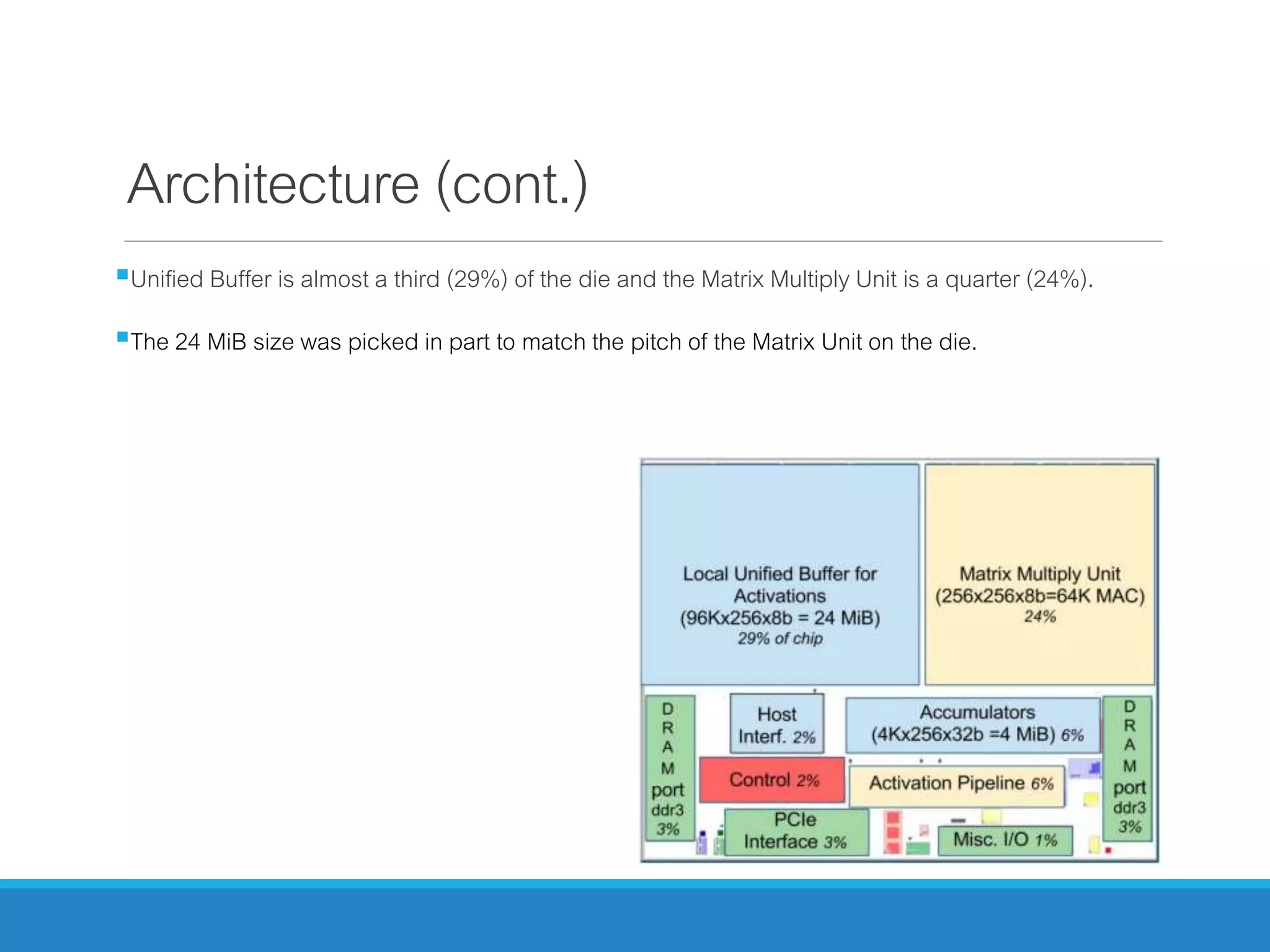
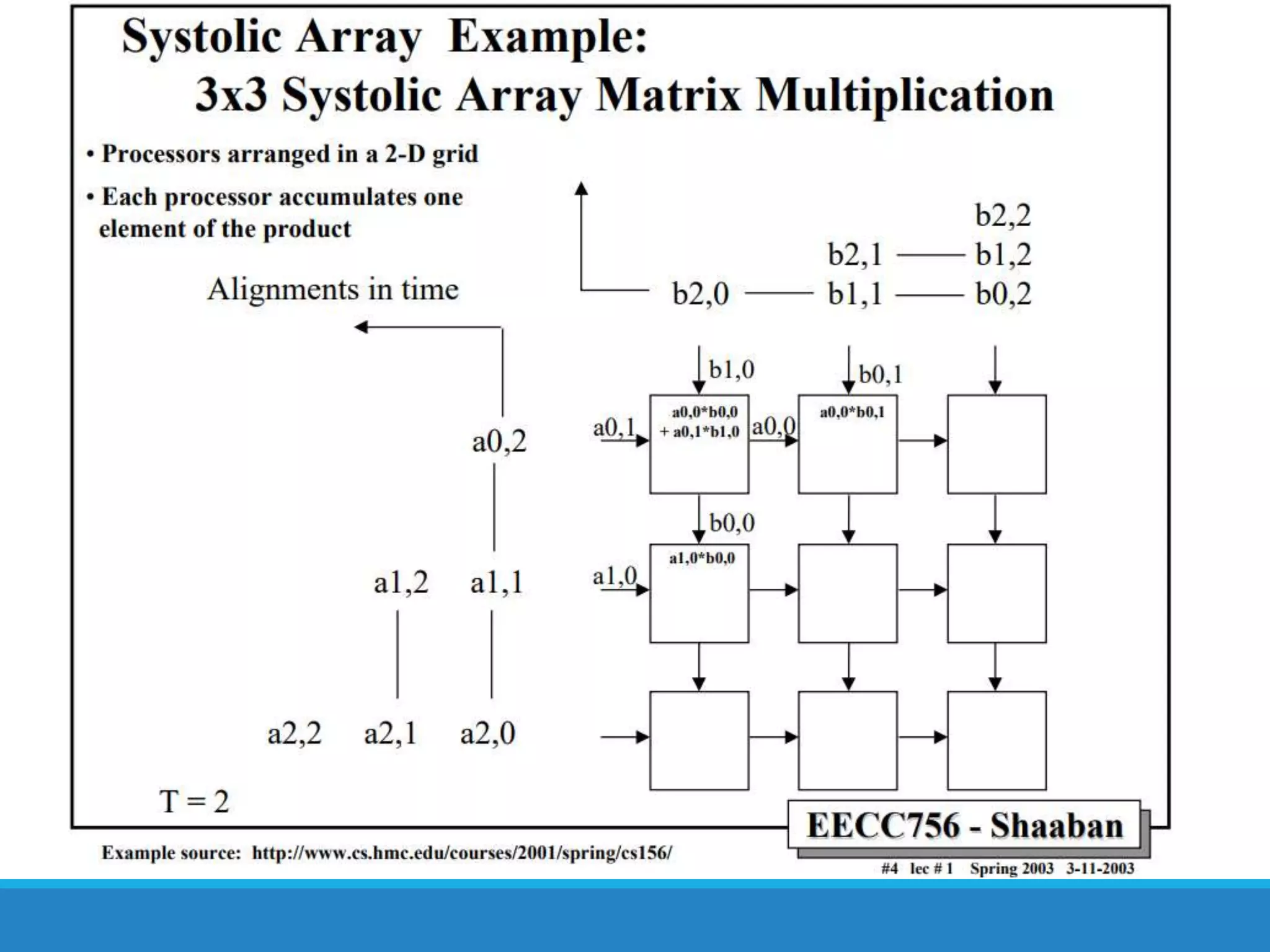
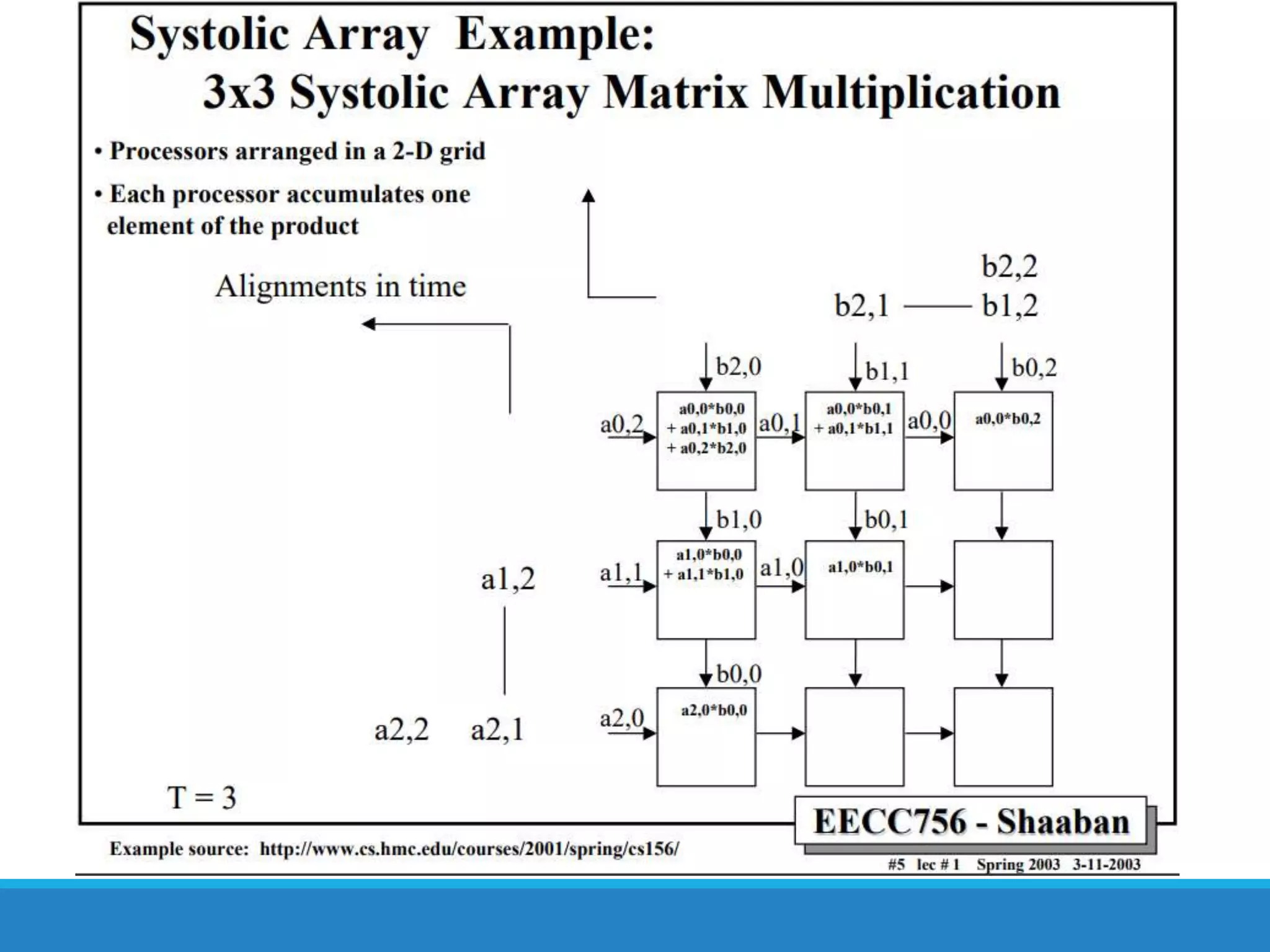
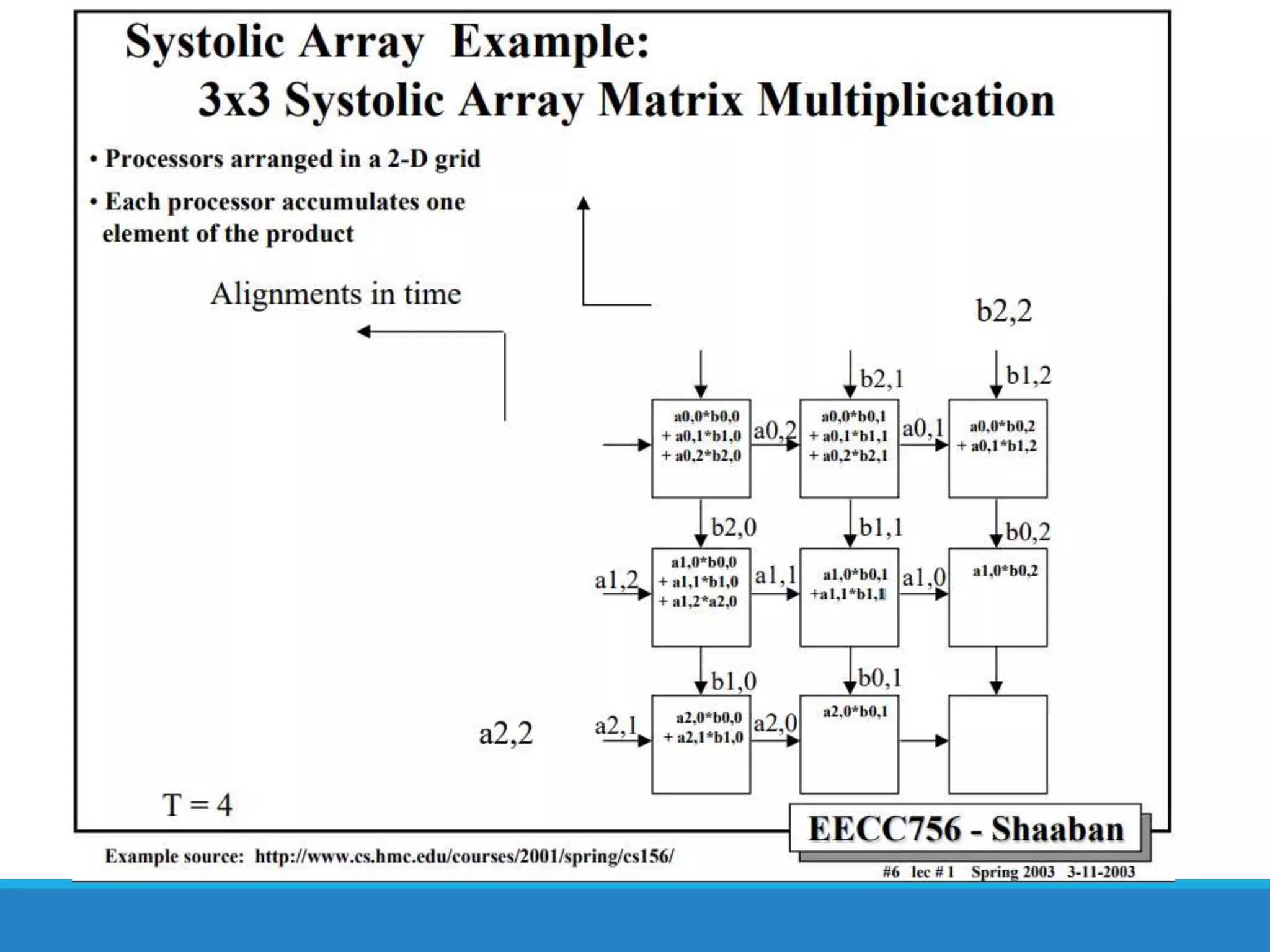
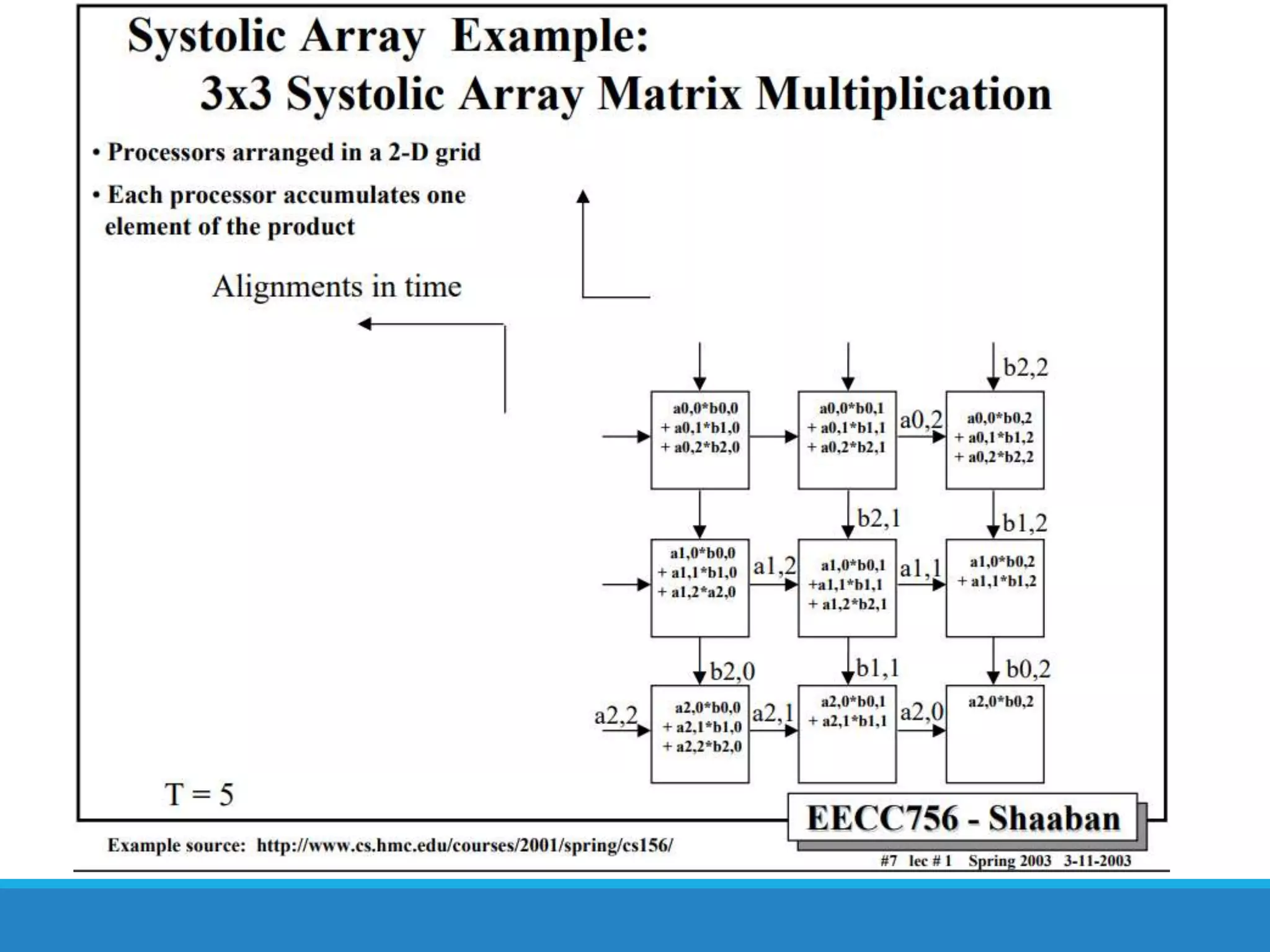
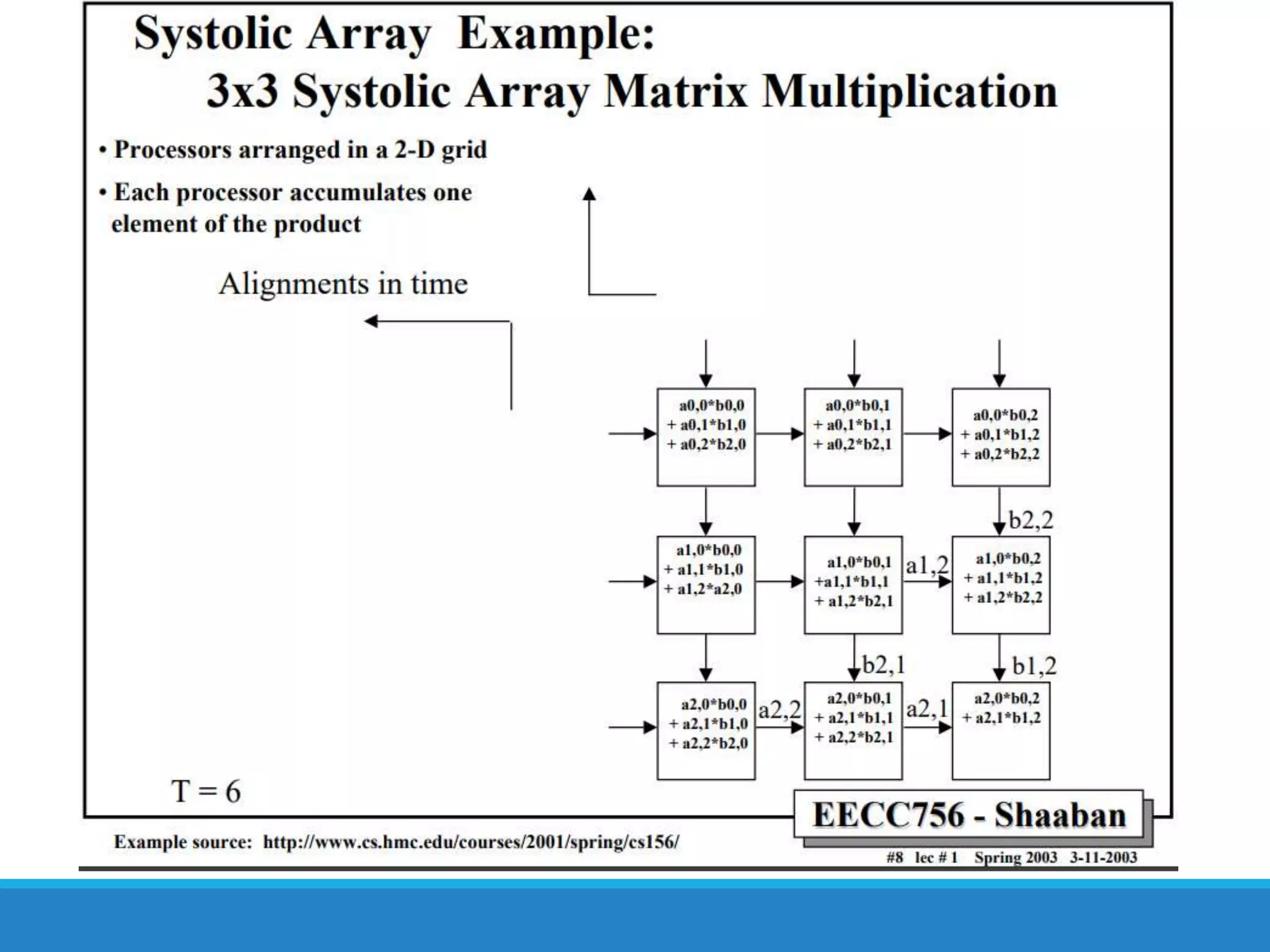
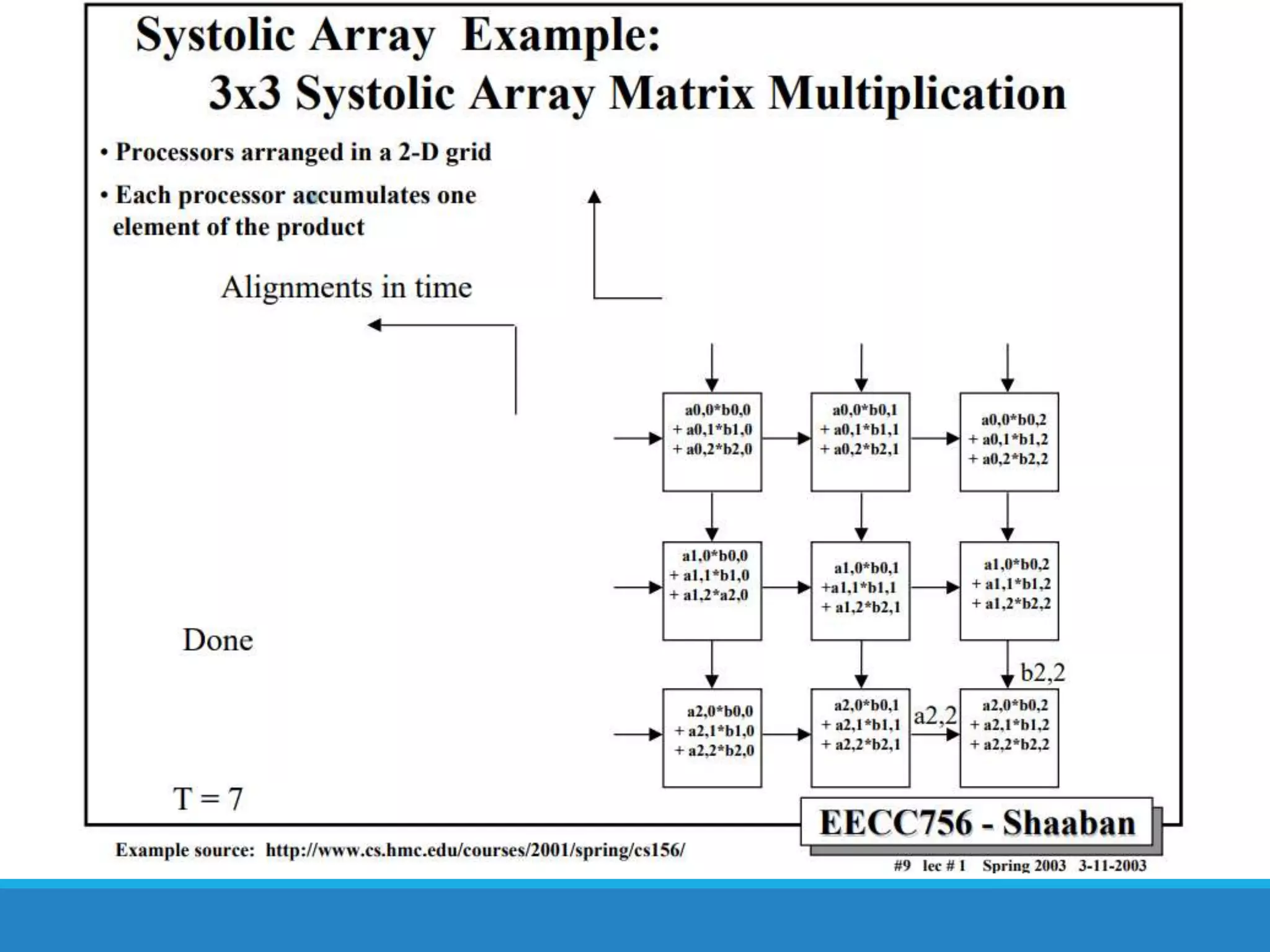
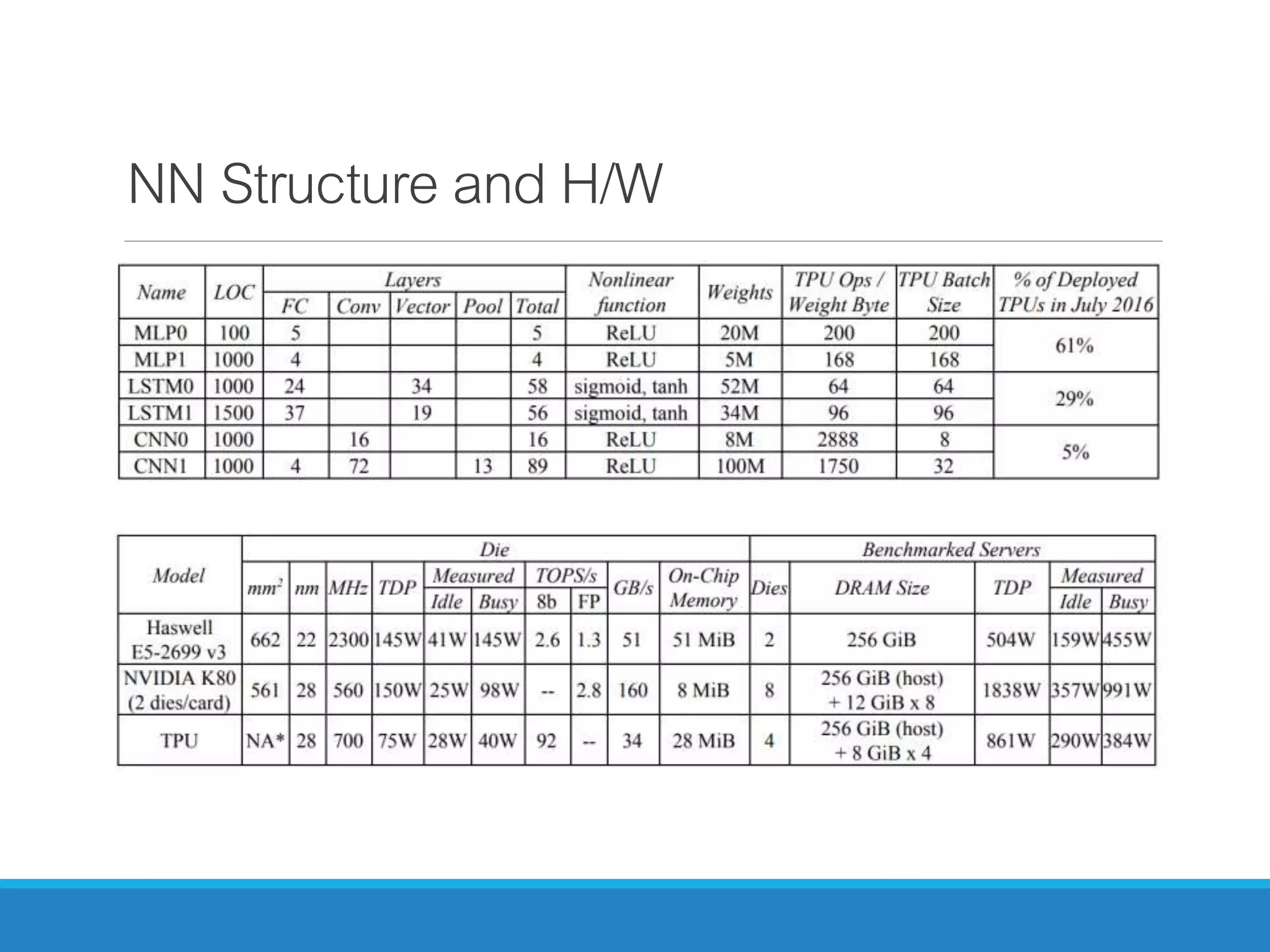
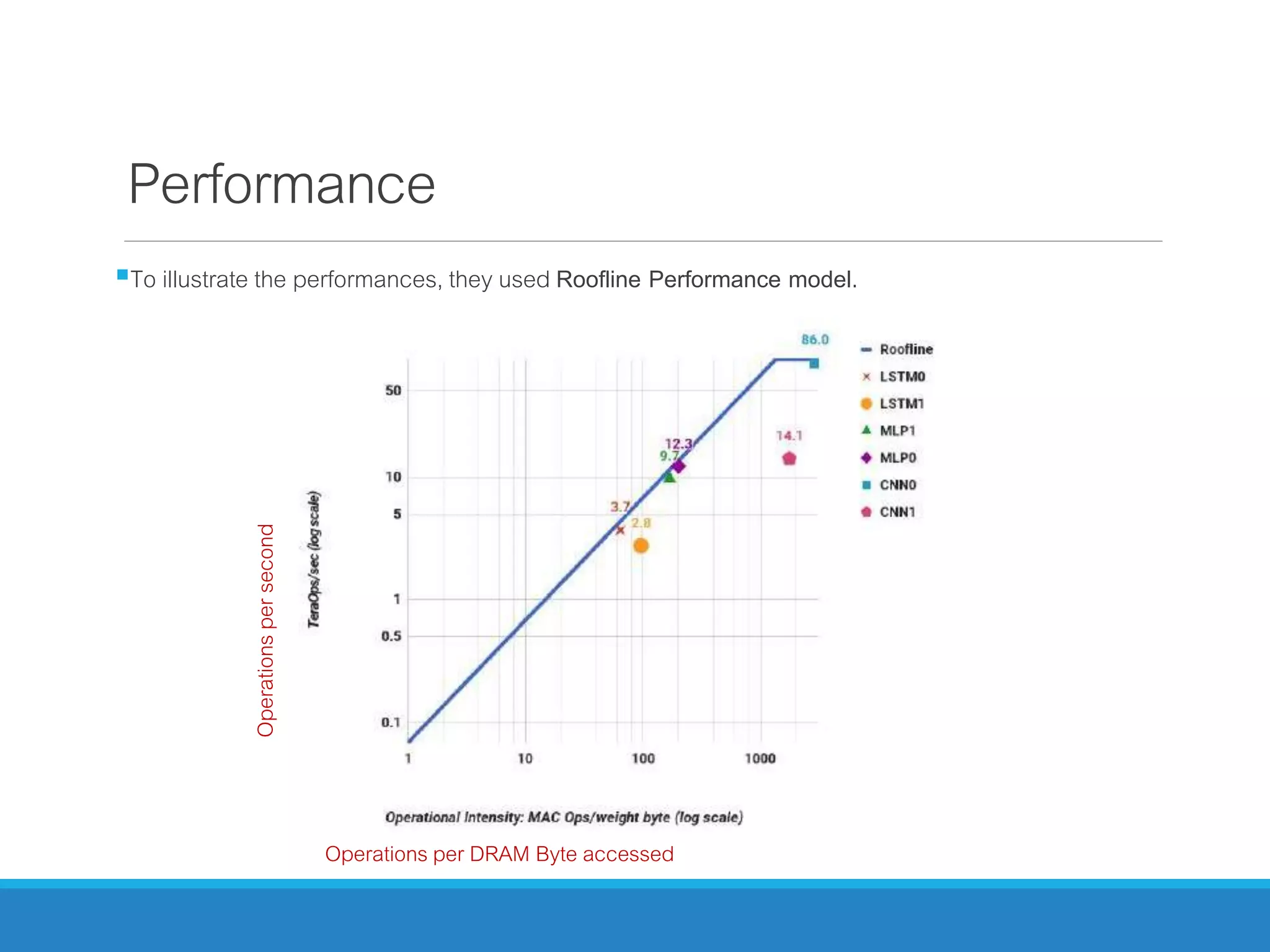
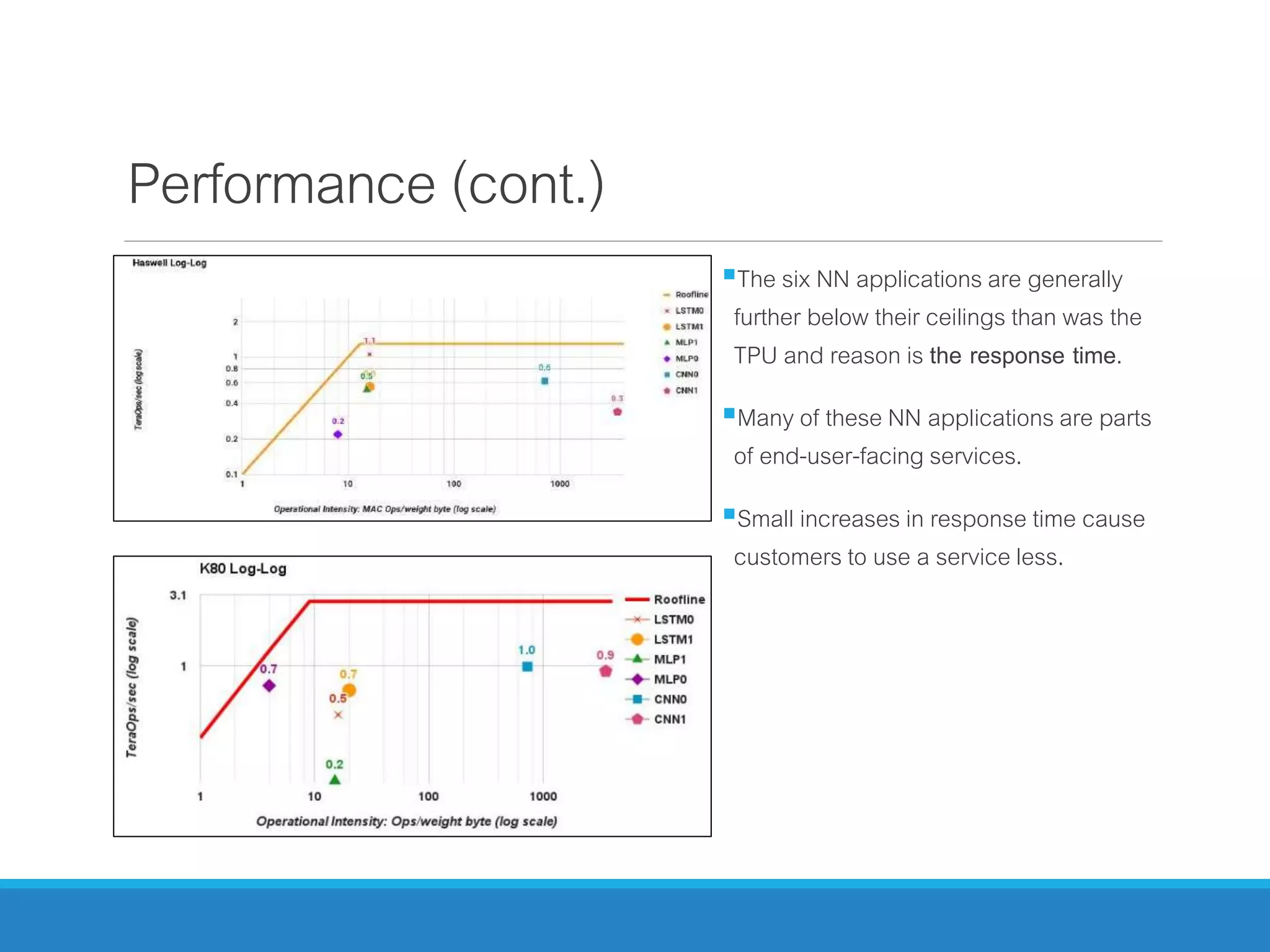
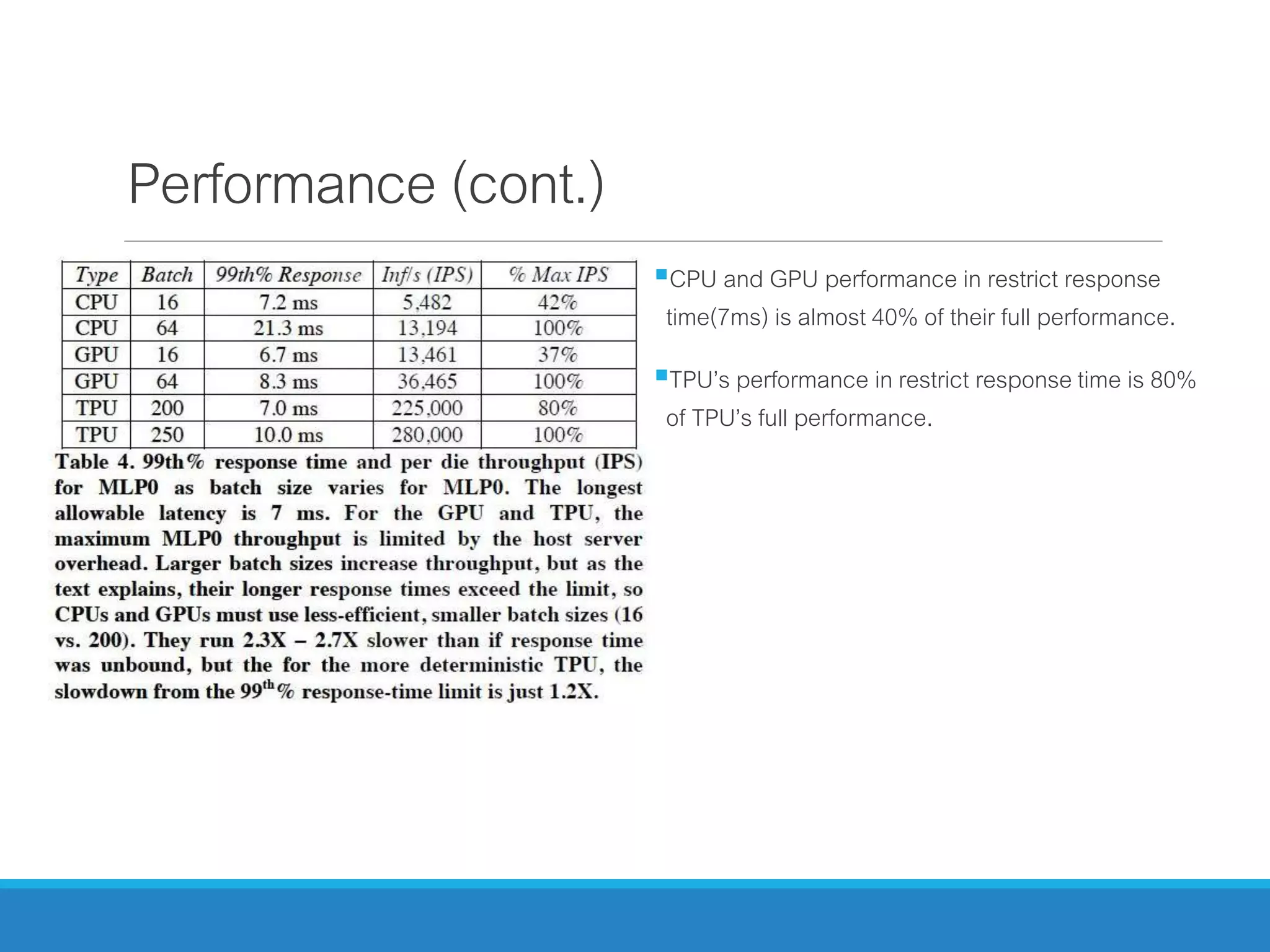
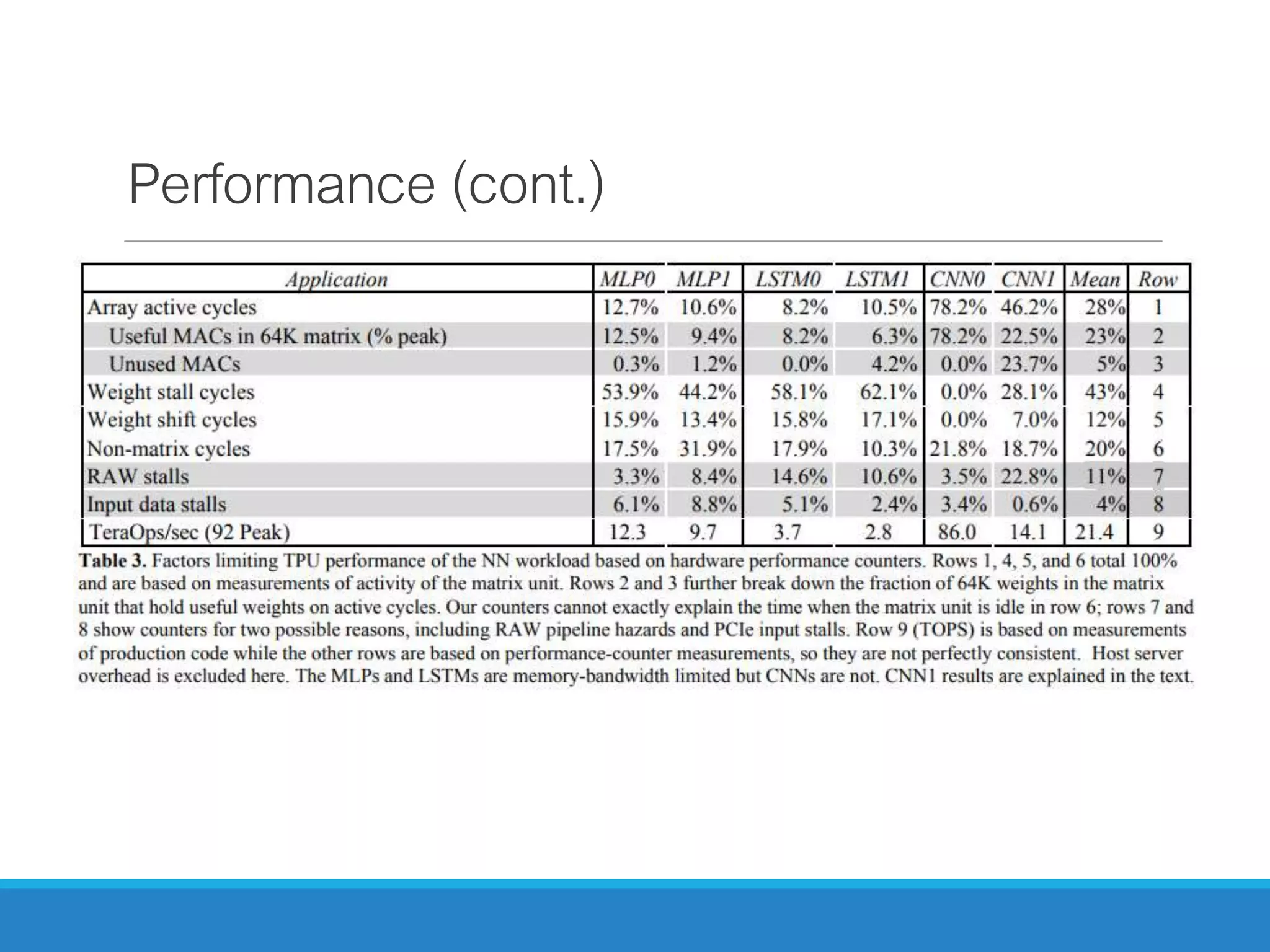
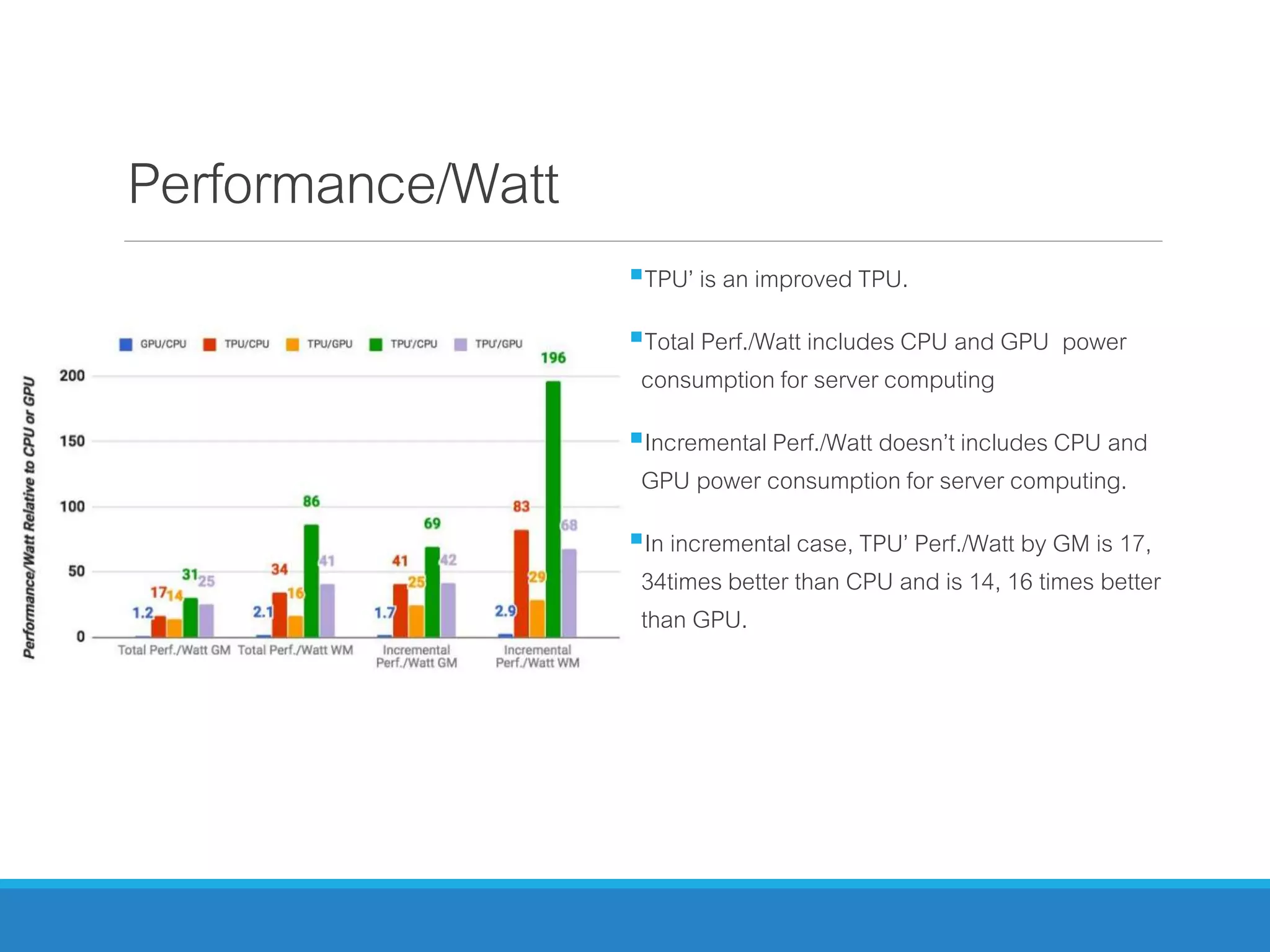
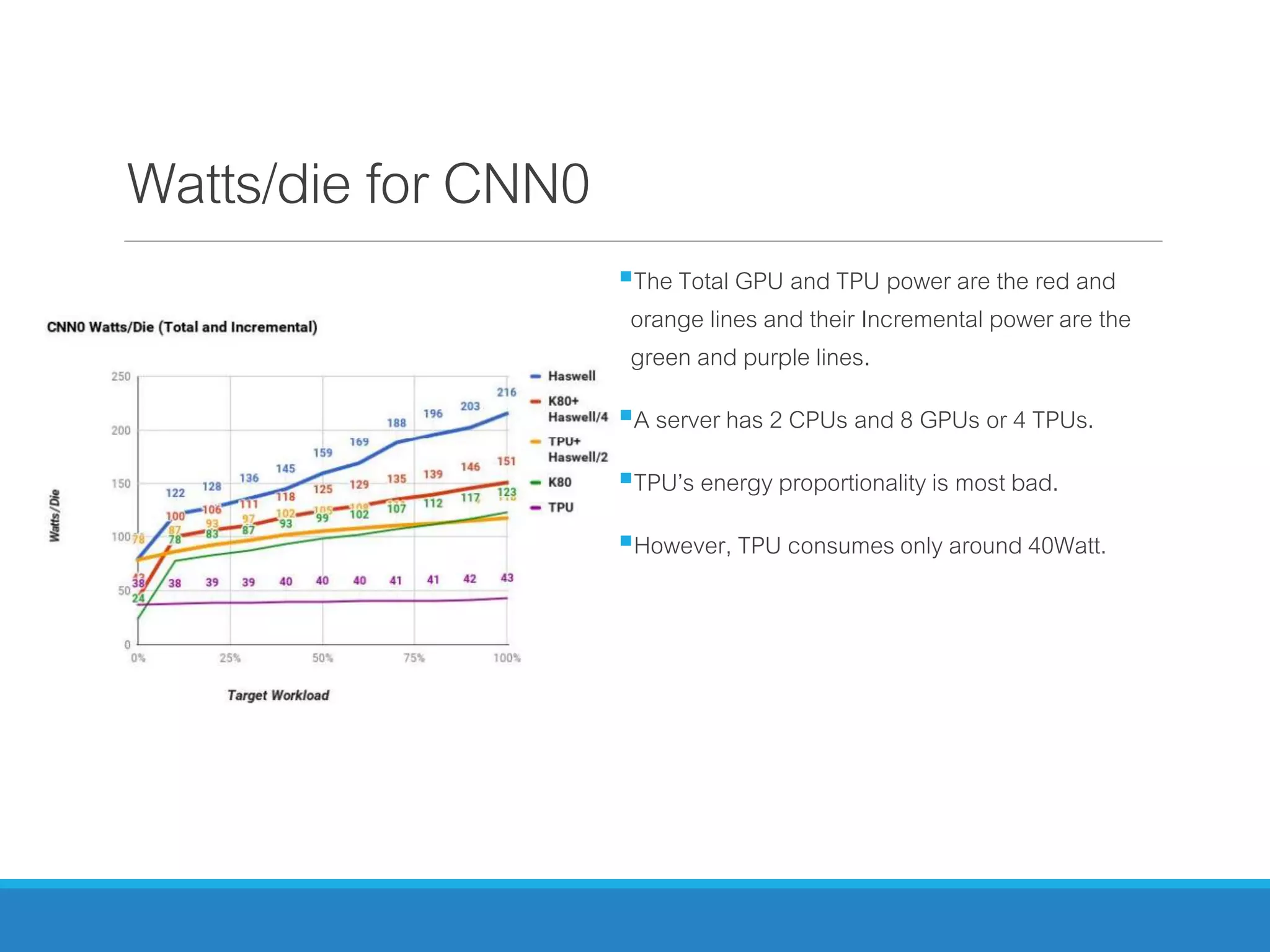
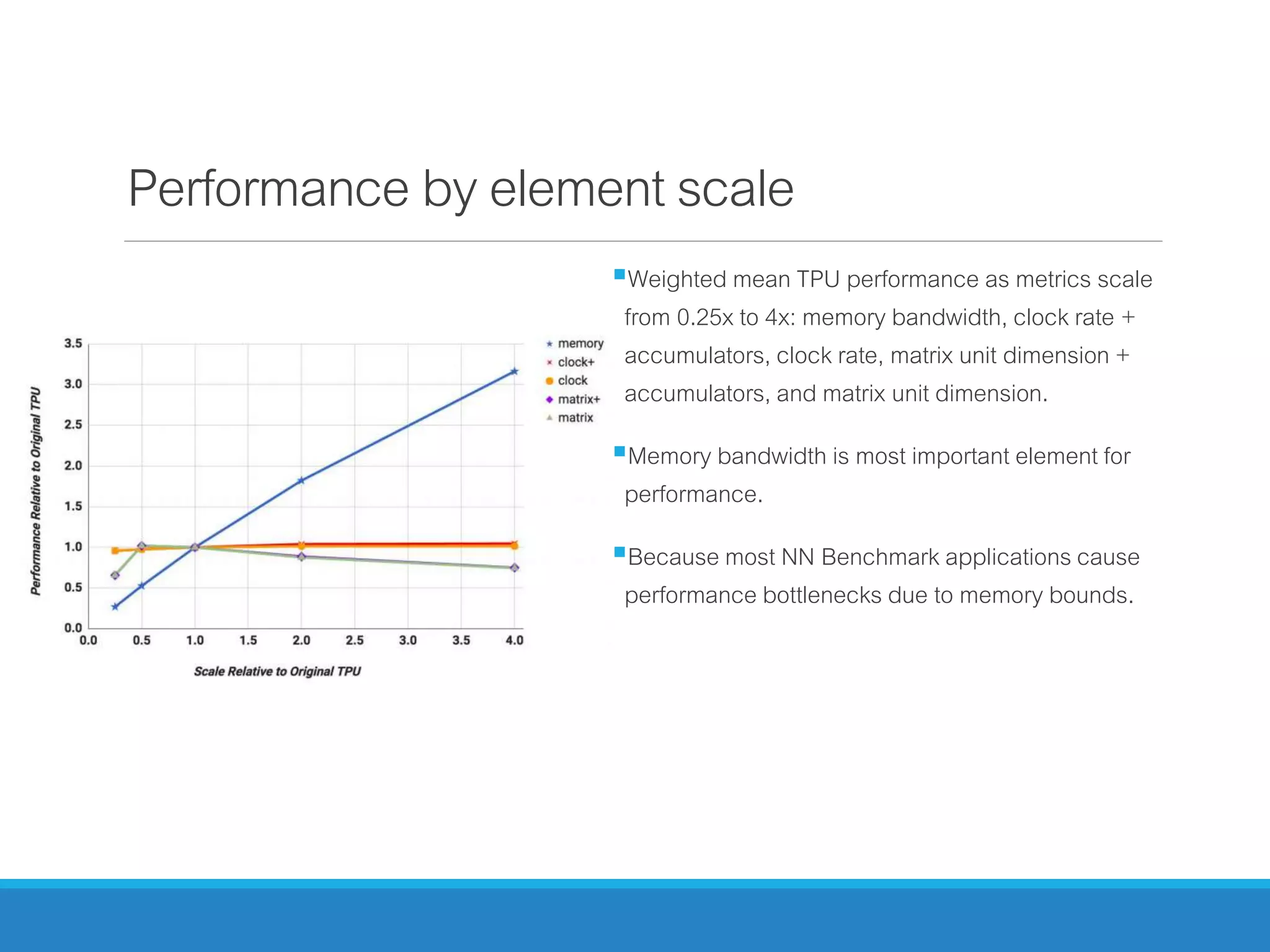
The document analyzes the performance of Tensor Processing Units (TPUs) in datacenters, highlighting their significant advantages over GPU and CPU architectures for machine learning inference tasks. It demonstrates that TPUs are drastically more efficient and faster, achieving performance improvements of up to 30x-200x, especially in response time-sensitive applications. Through technical innovations such as 8-bit integer processing and optimized memory utilization, TPUs efficiently handle neural network workloads, making them a strong preference for contemporary deep learning applications.