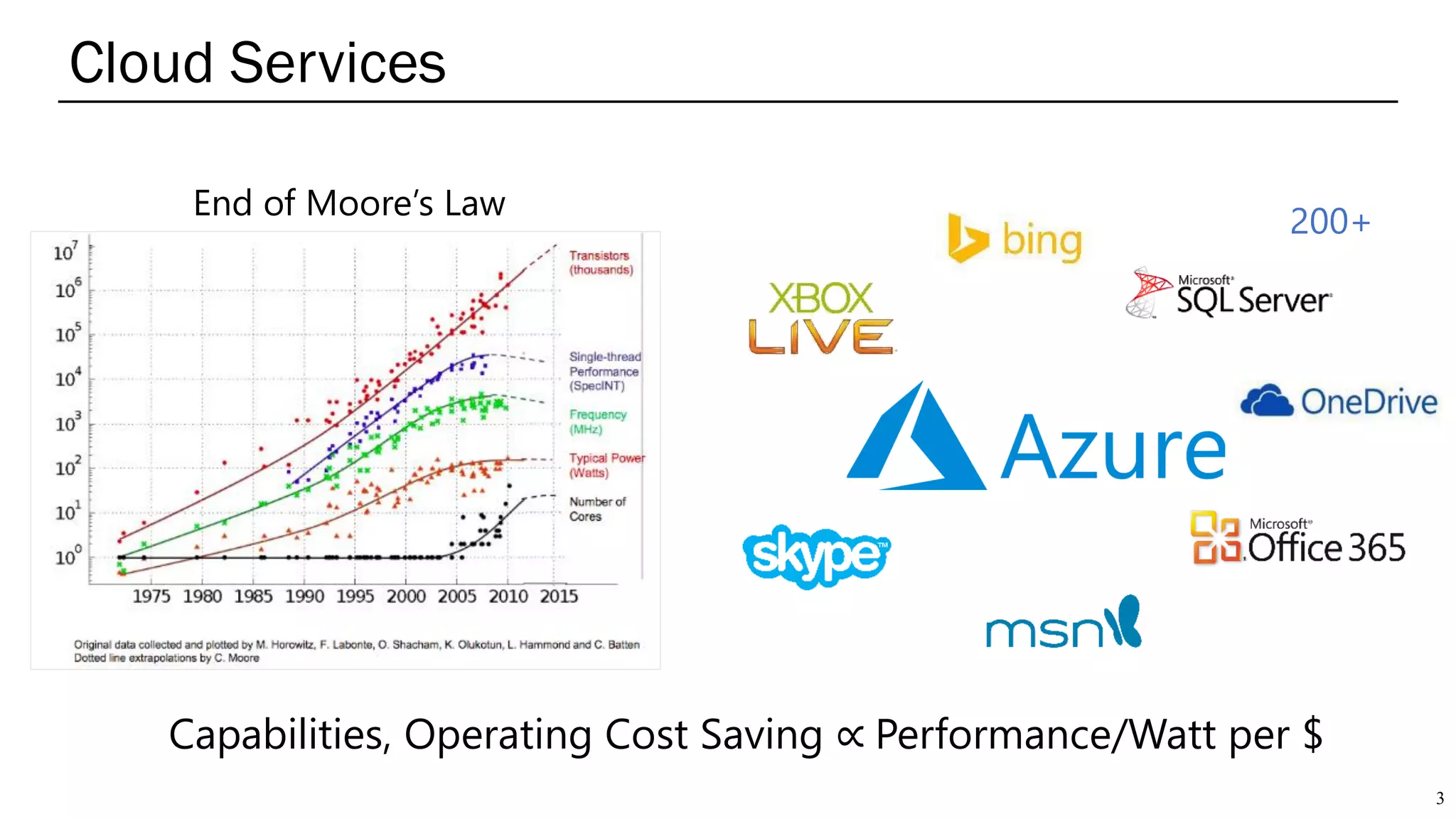
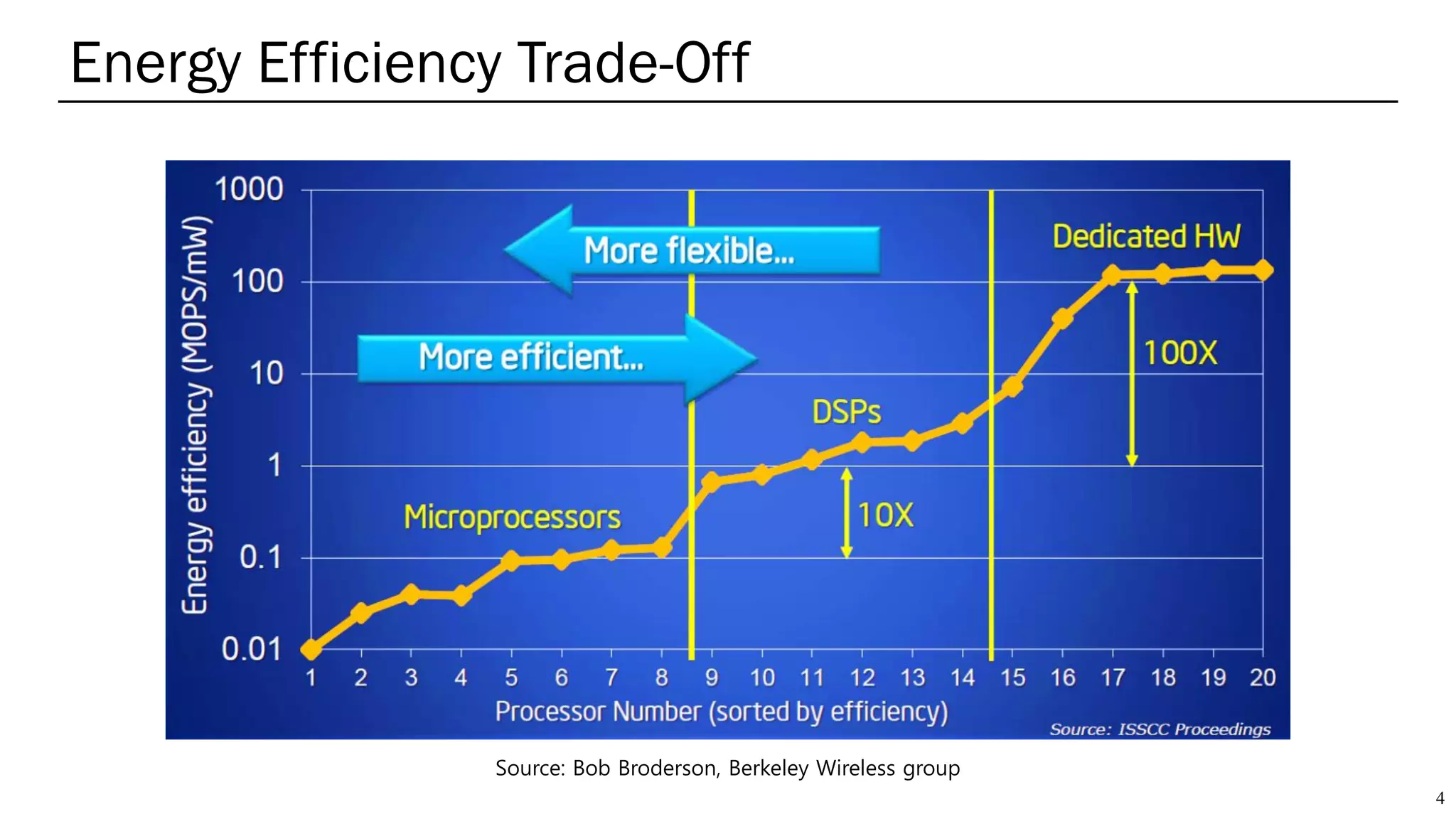
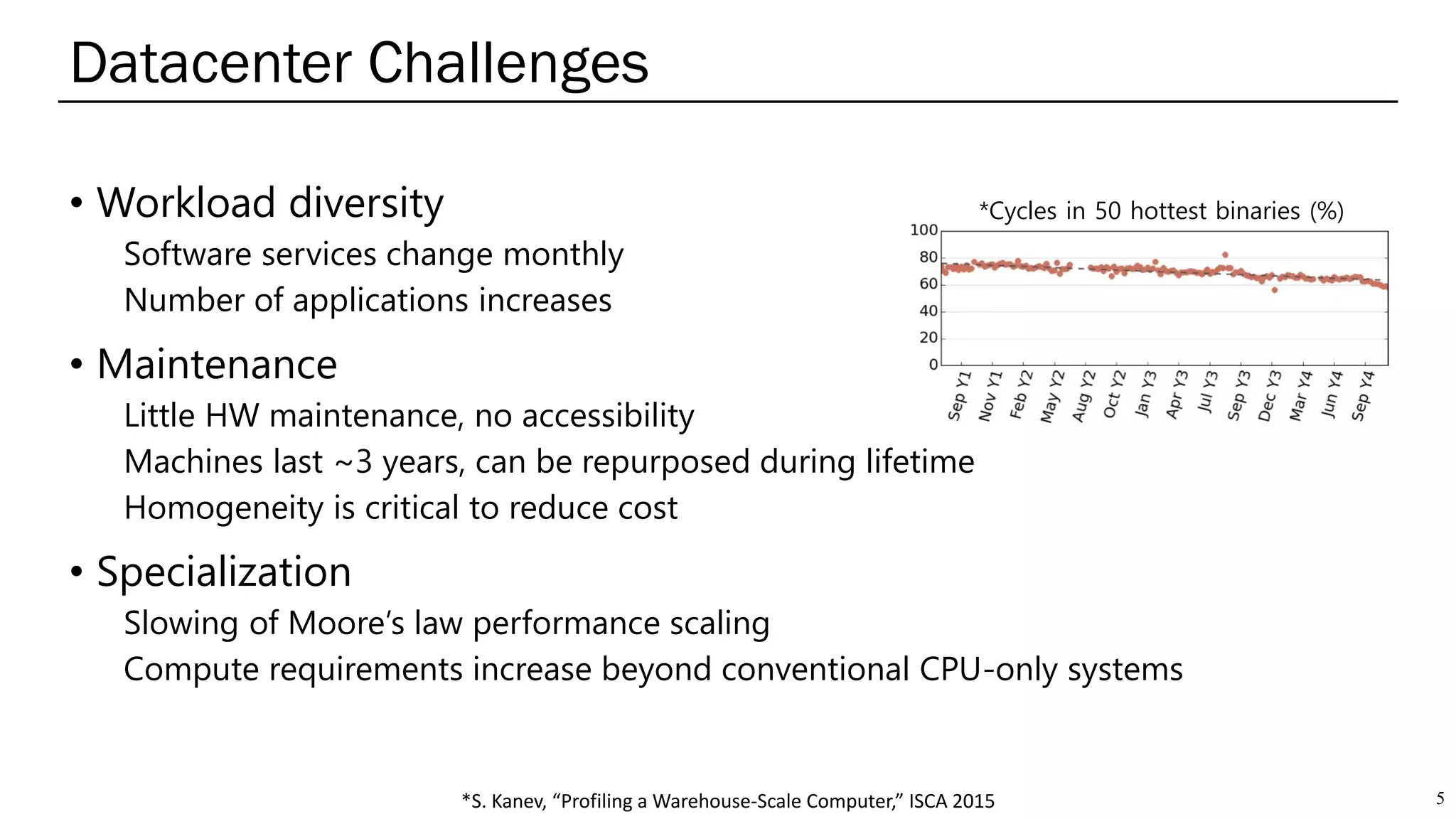
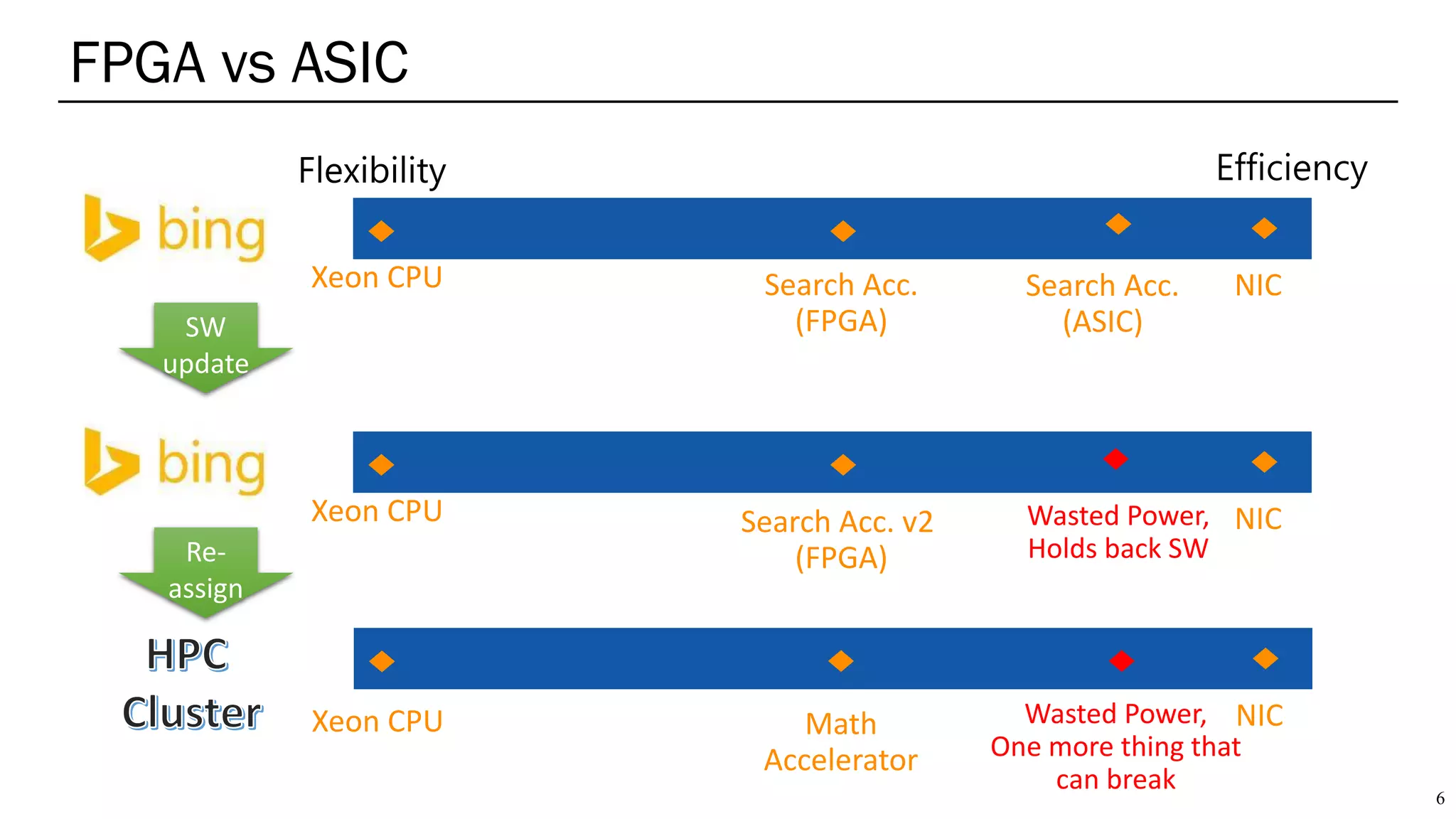
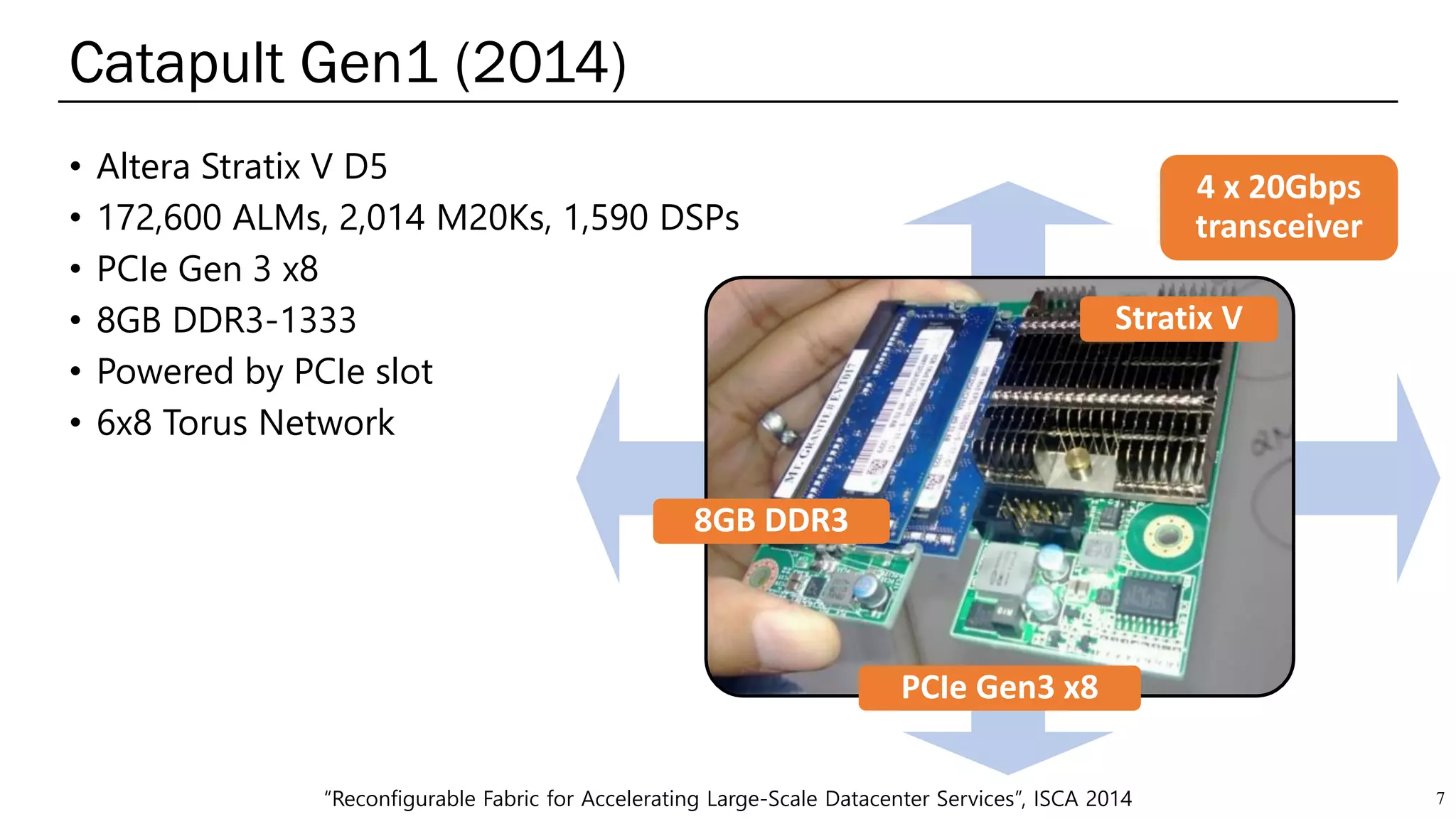
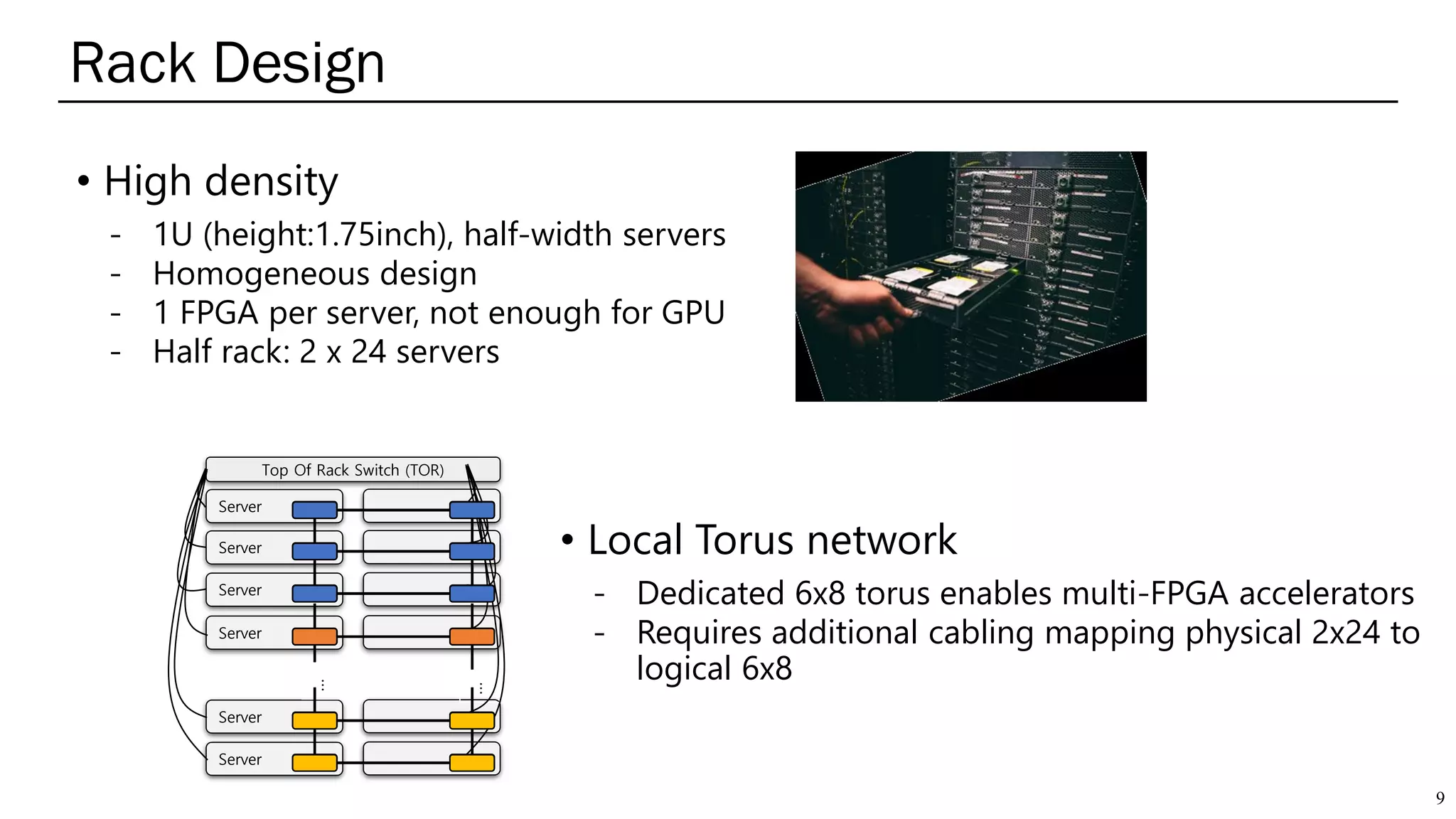
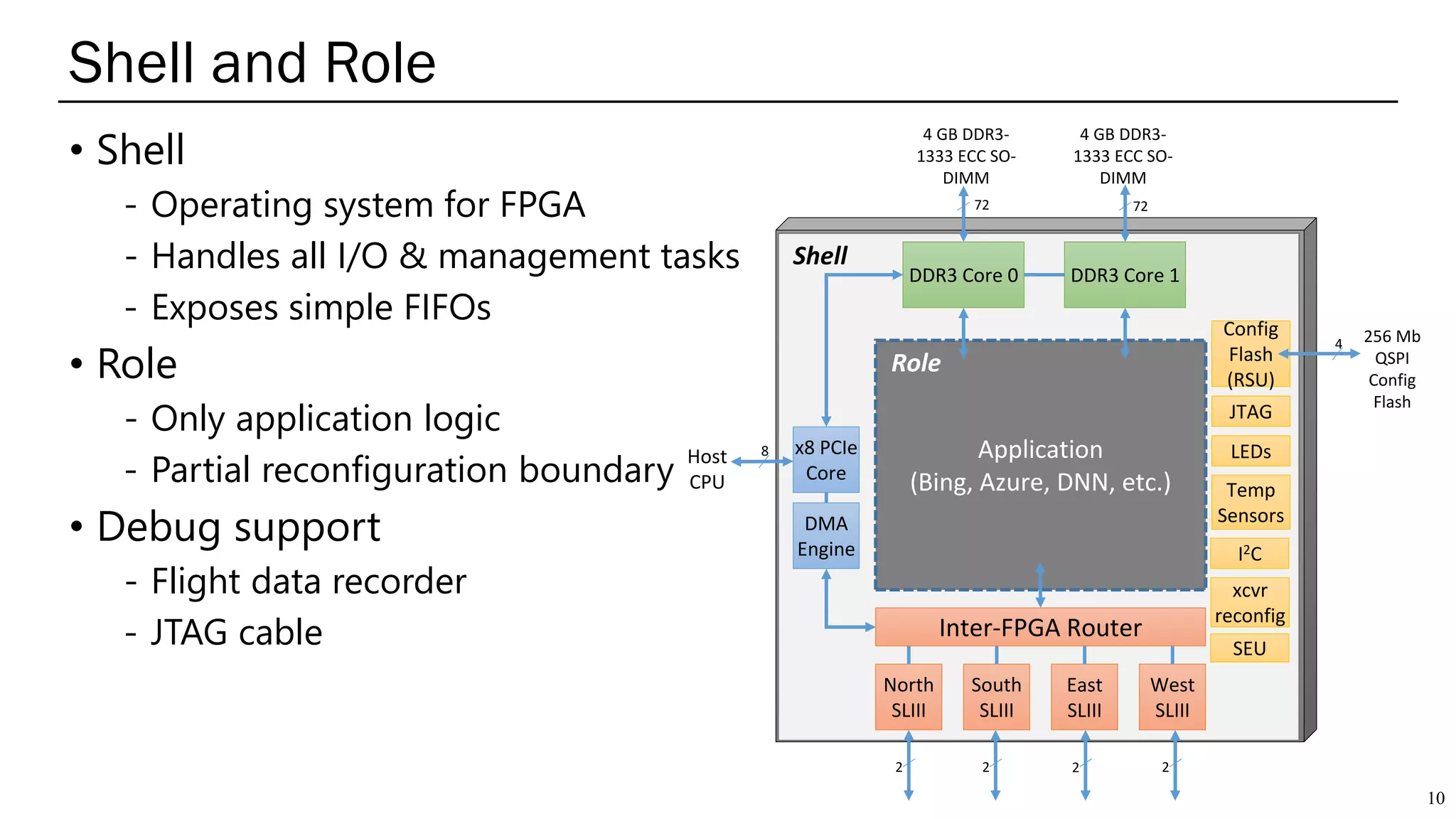
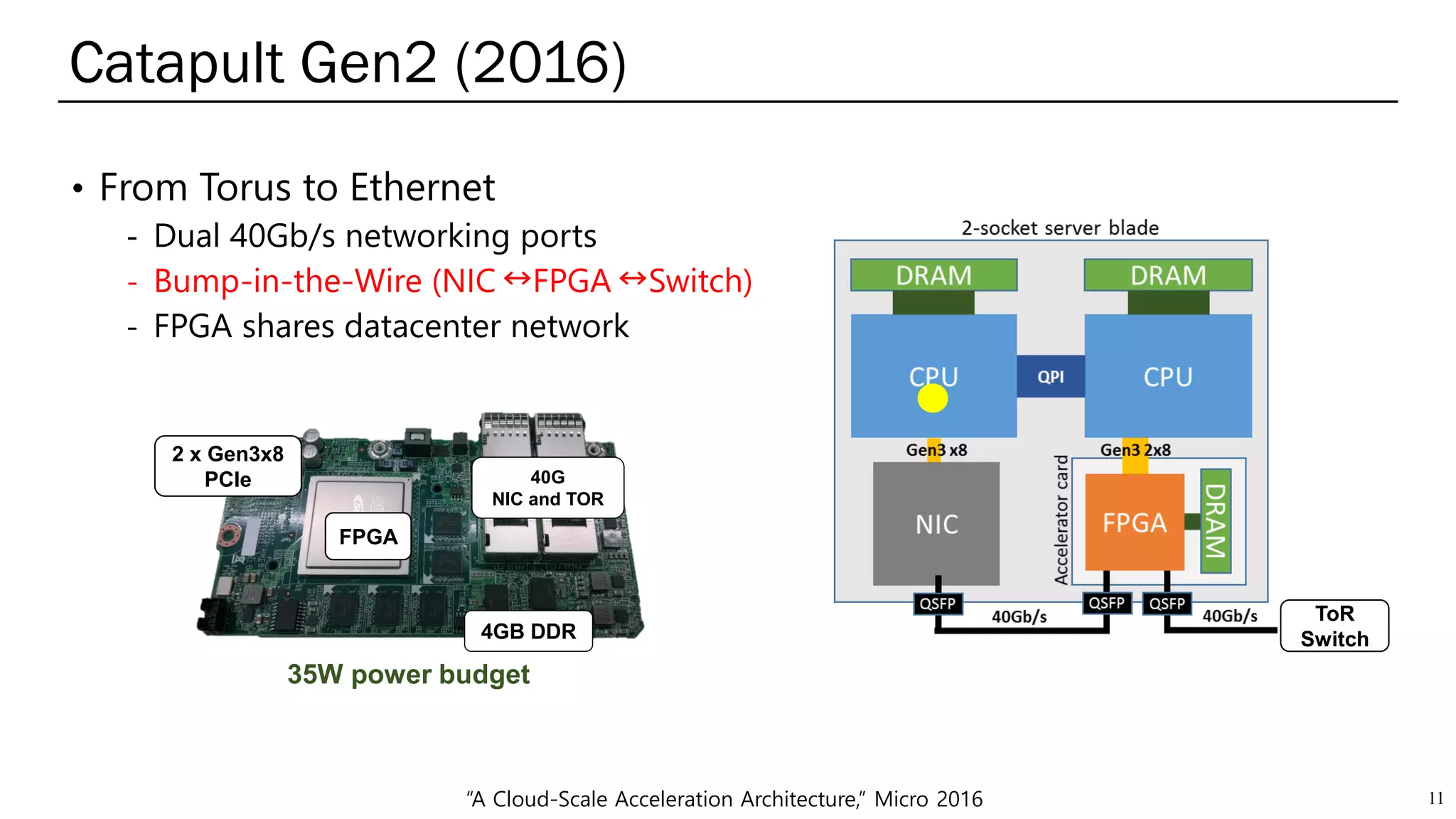
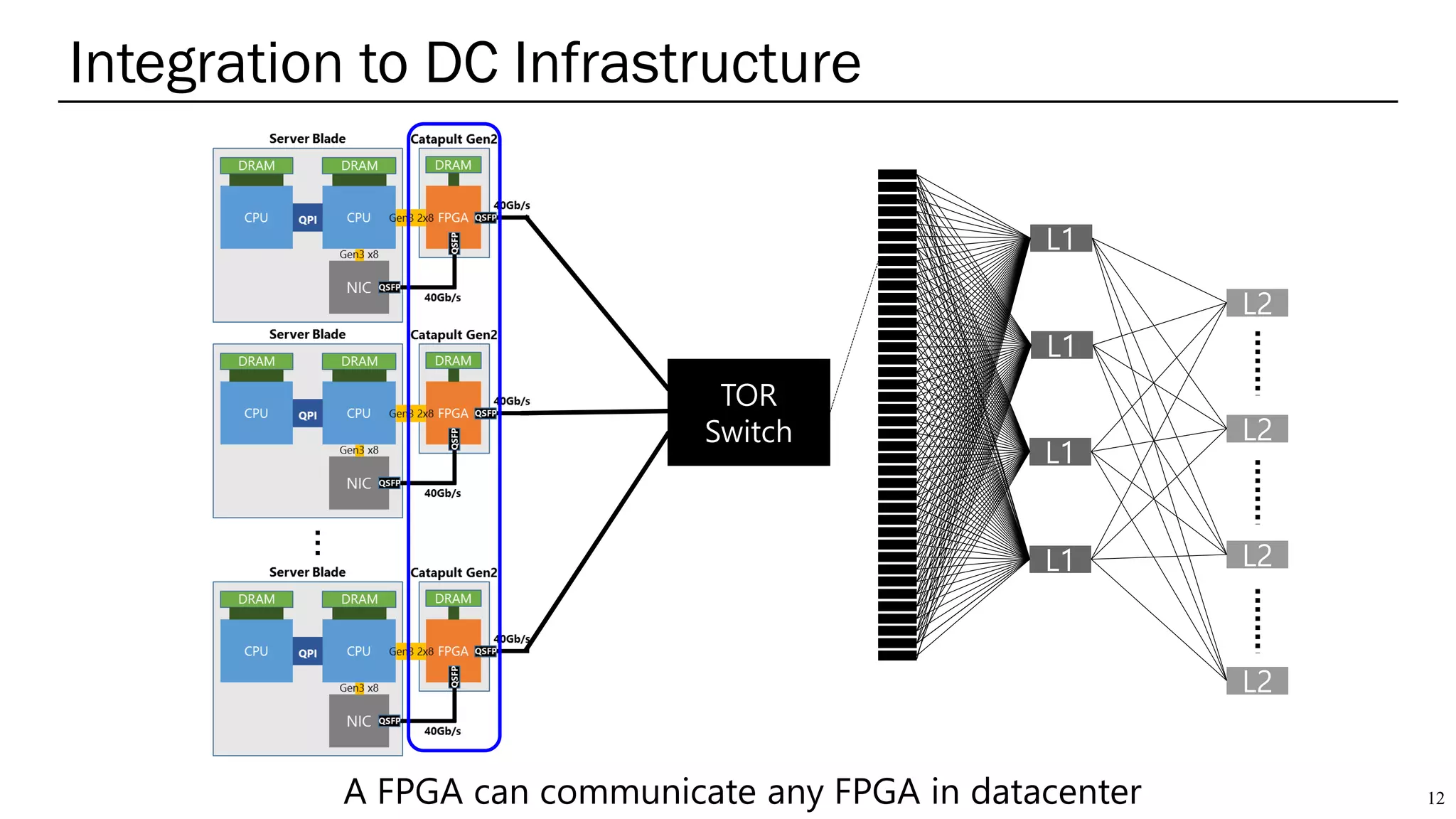
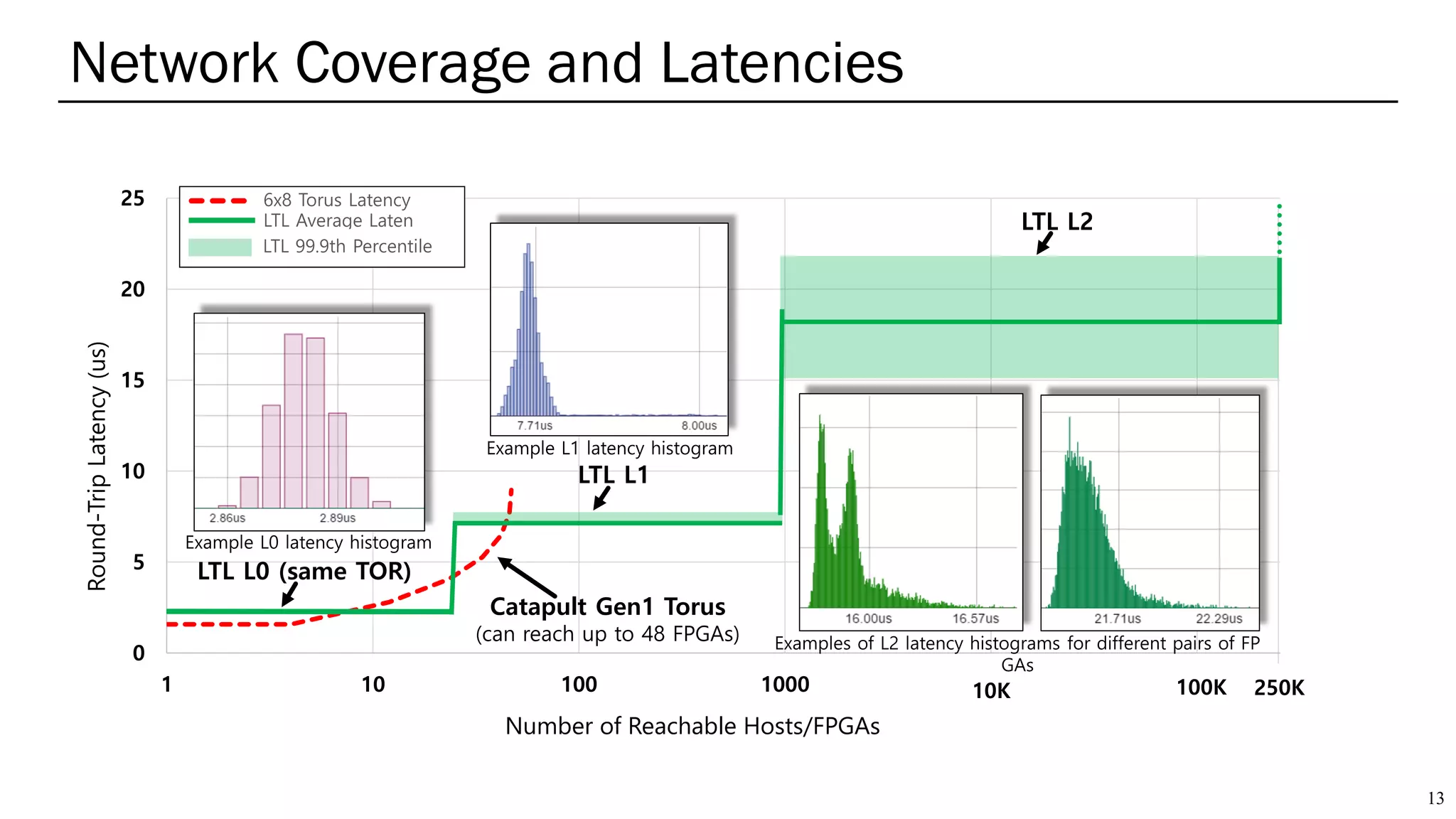
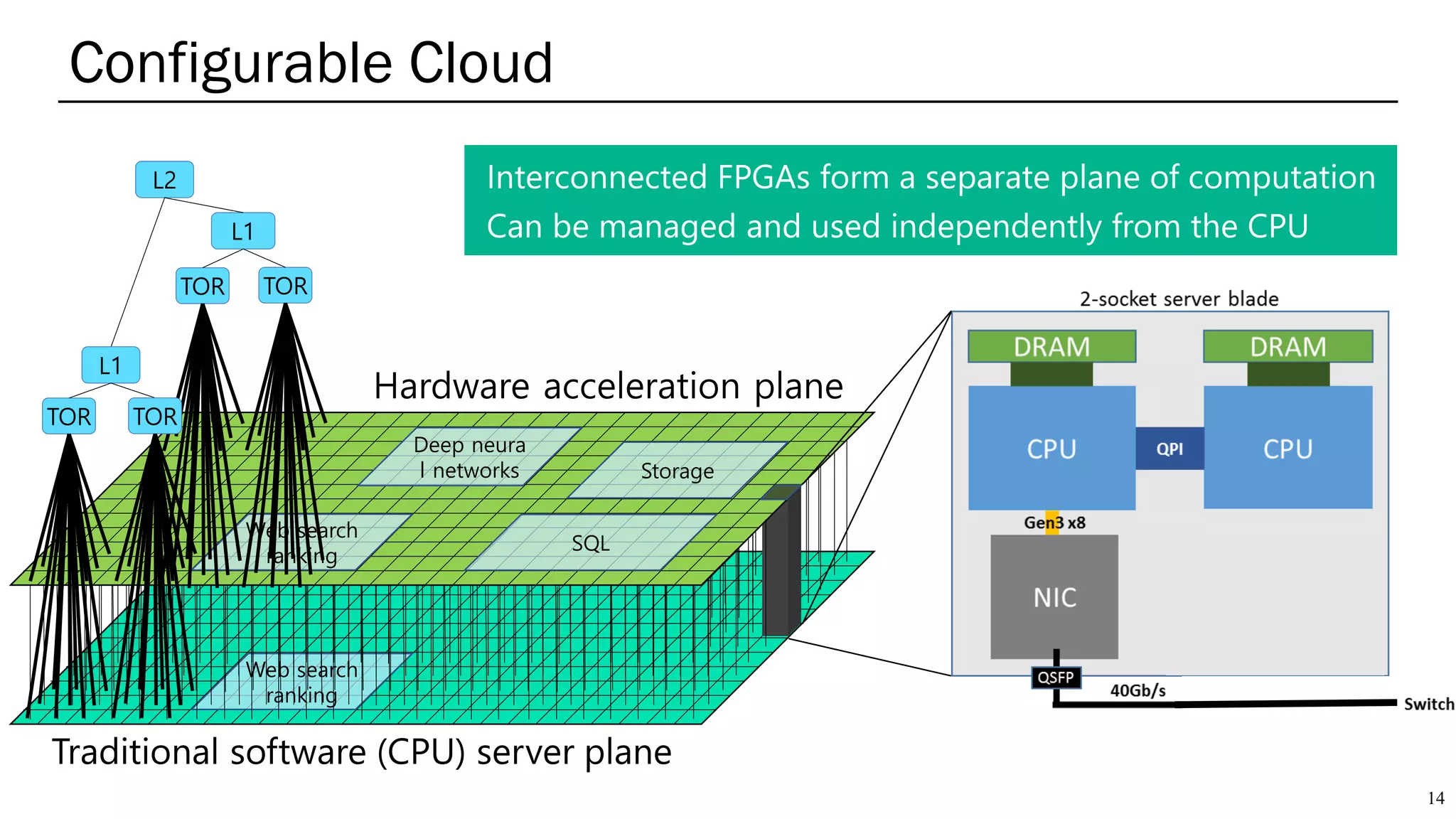
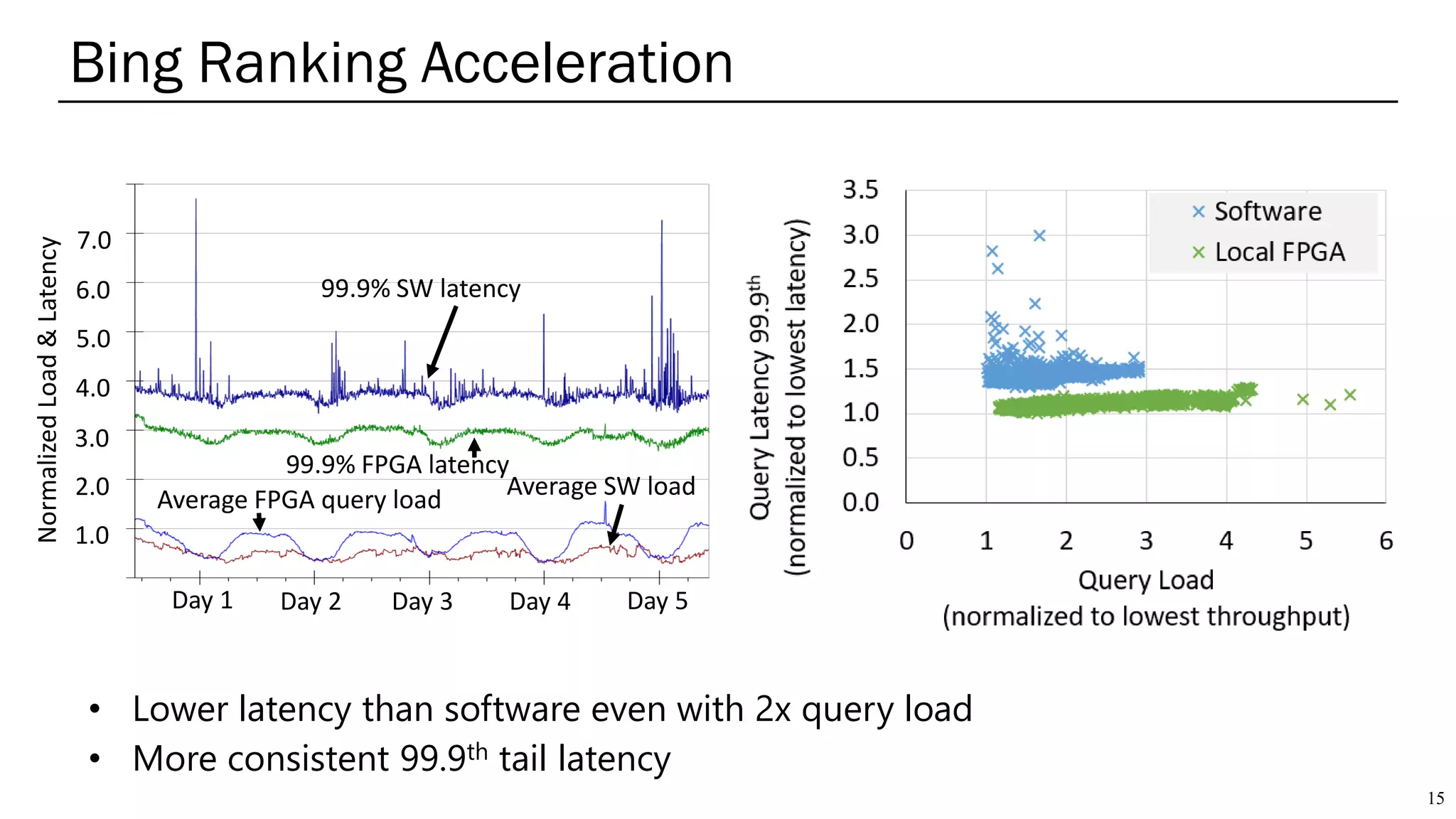
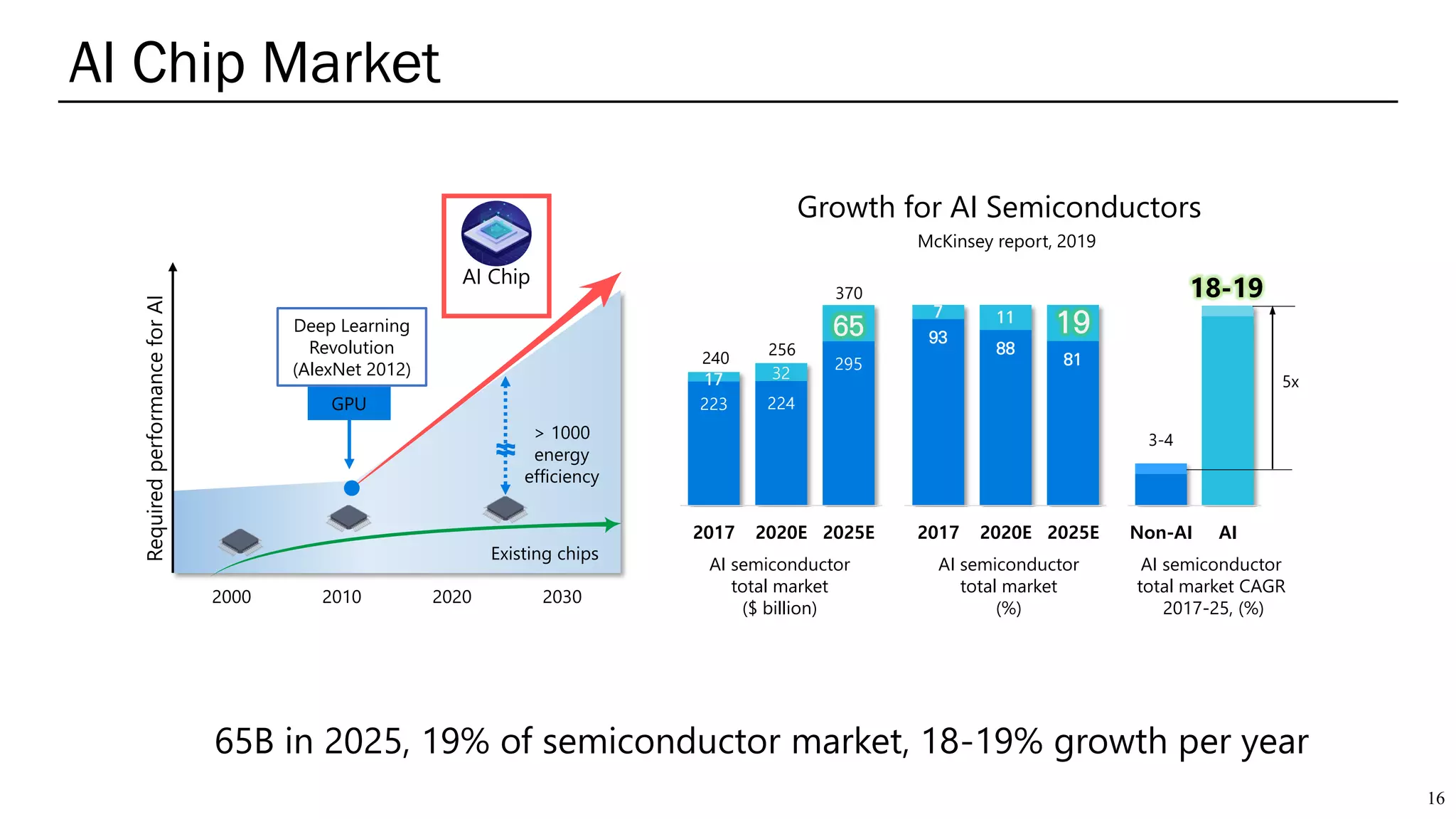
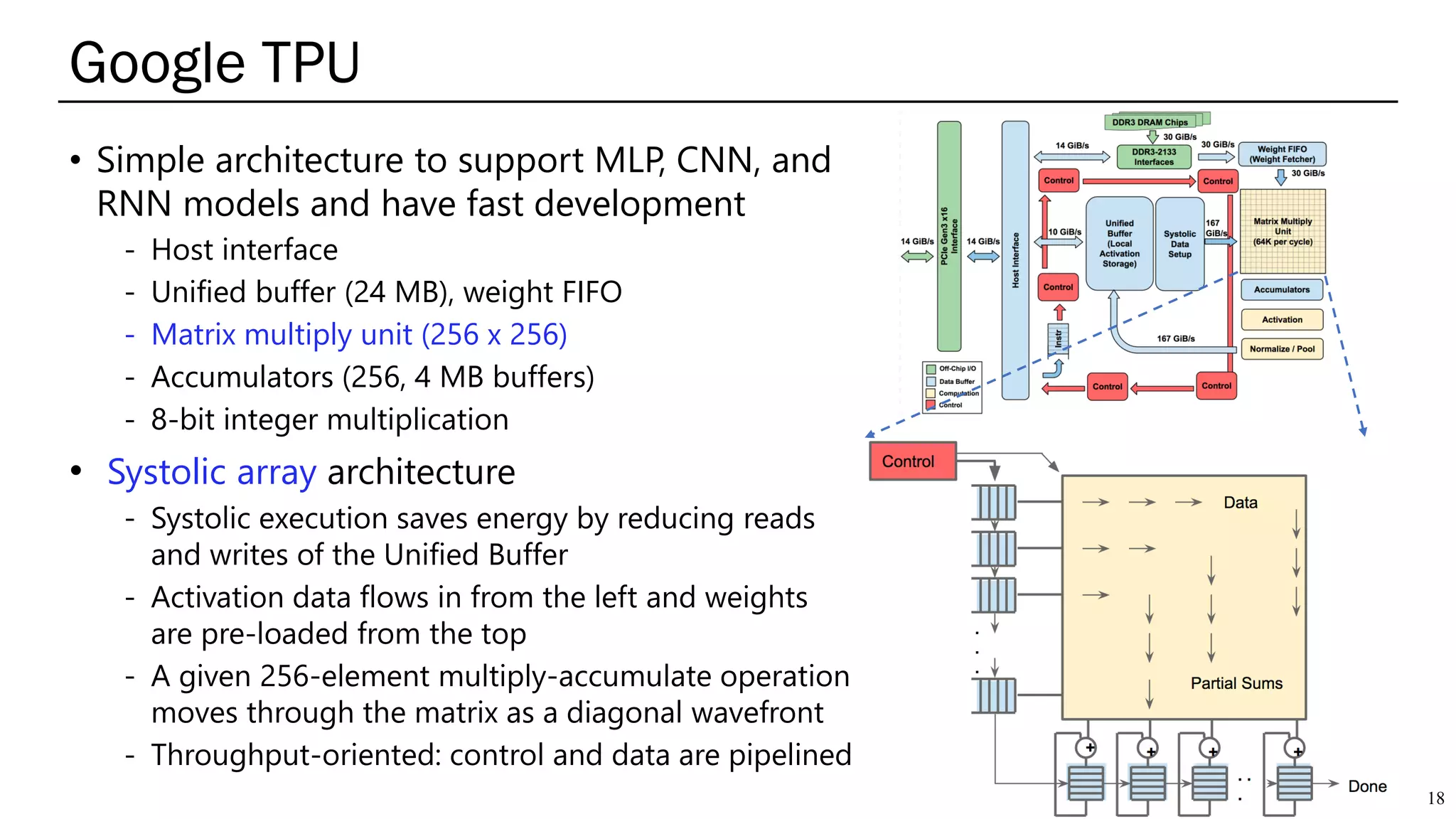
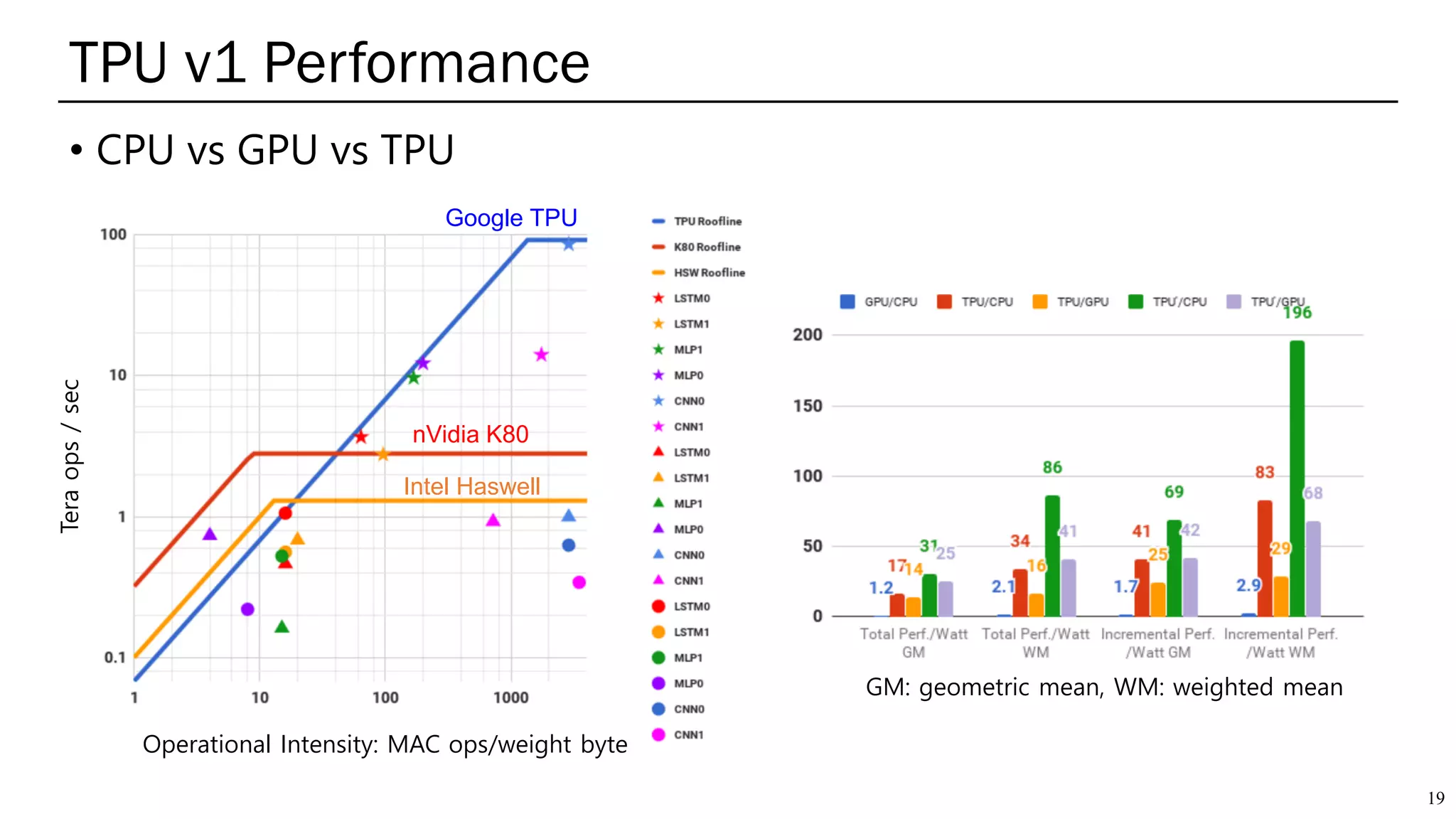
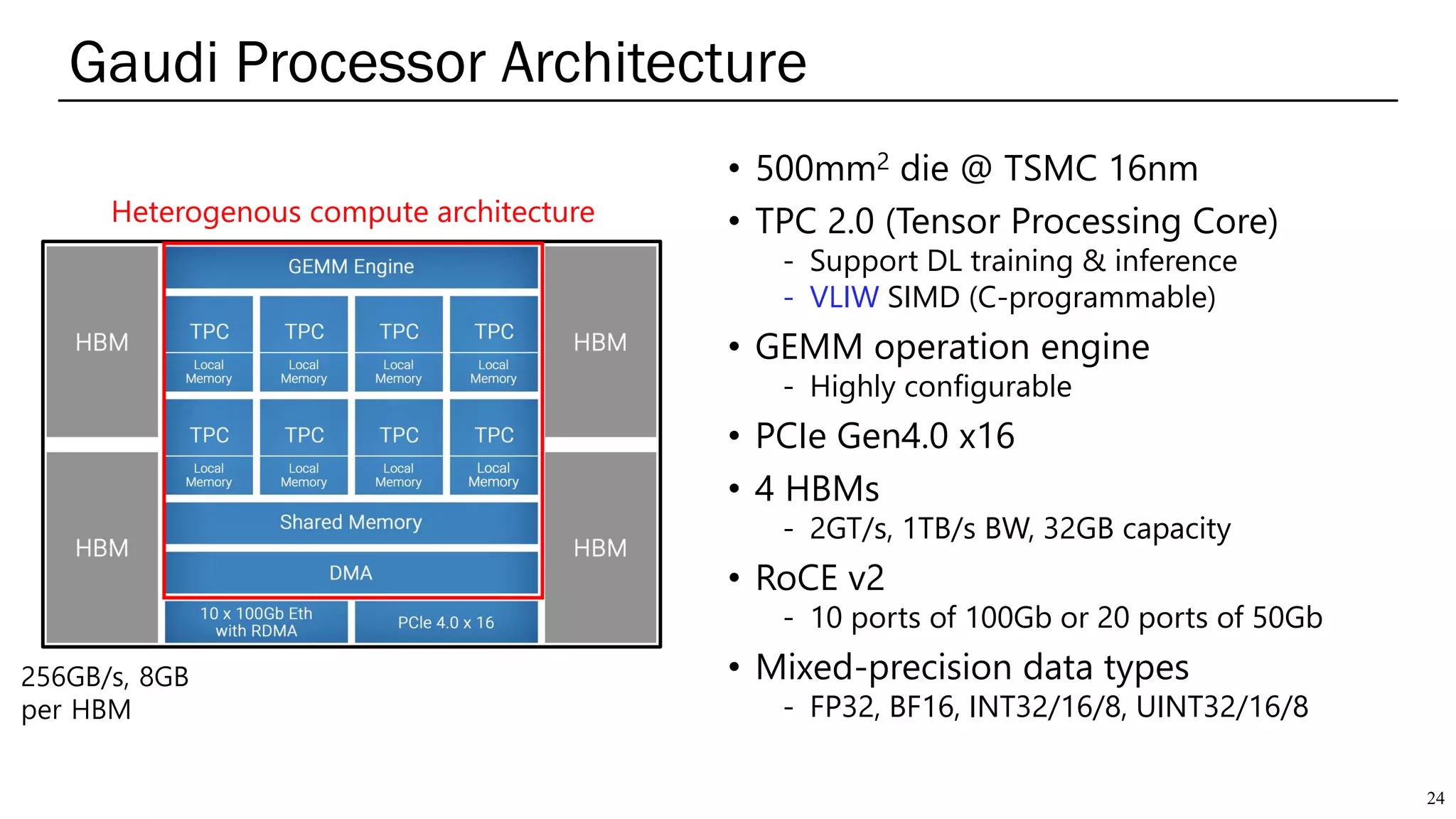
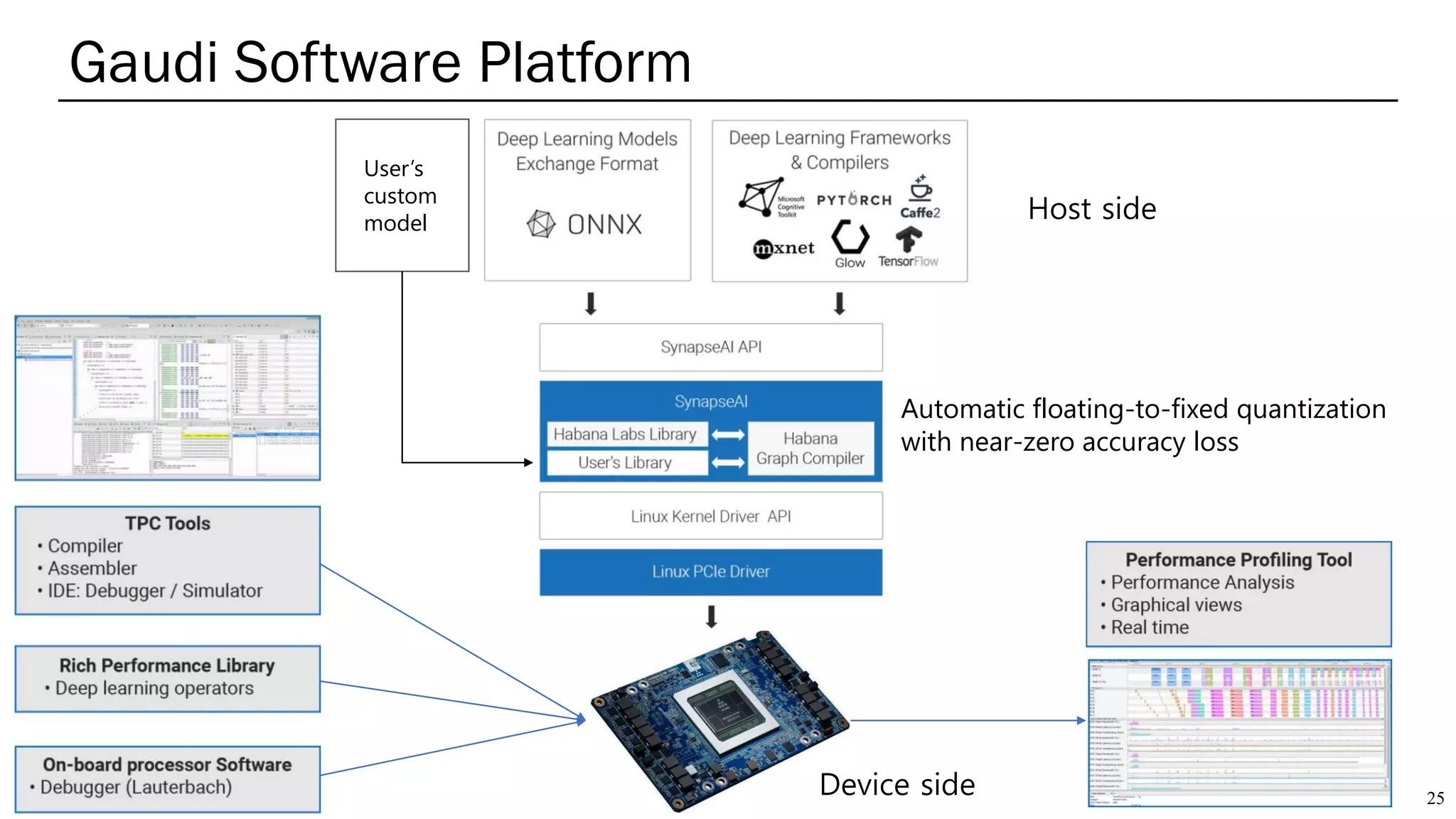
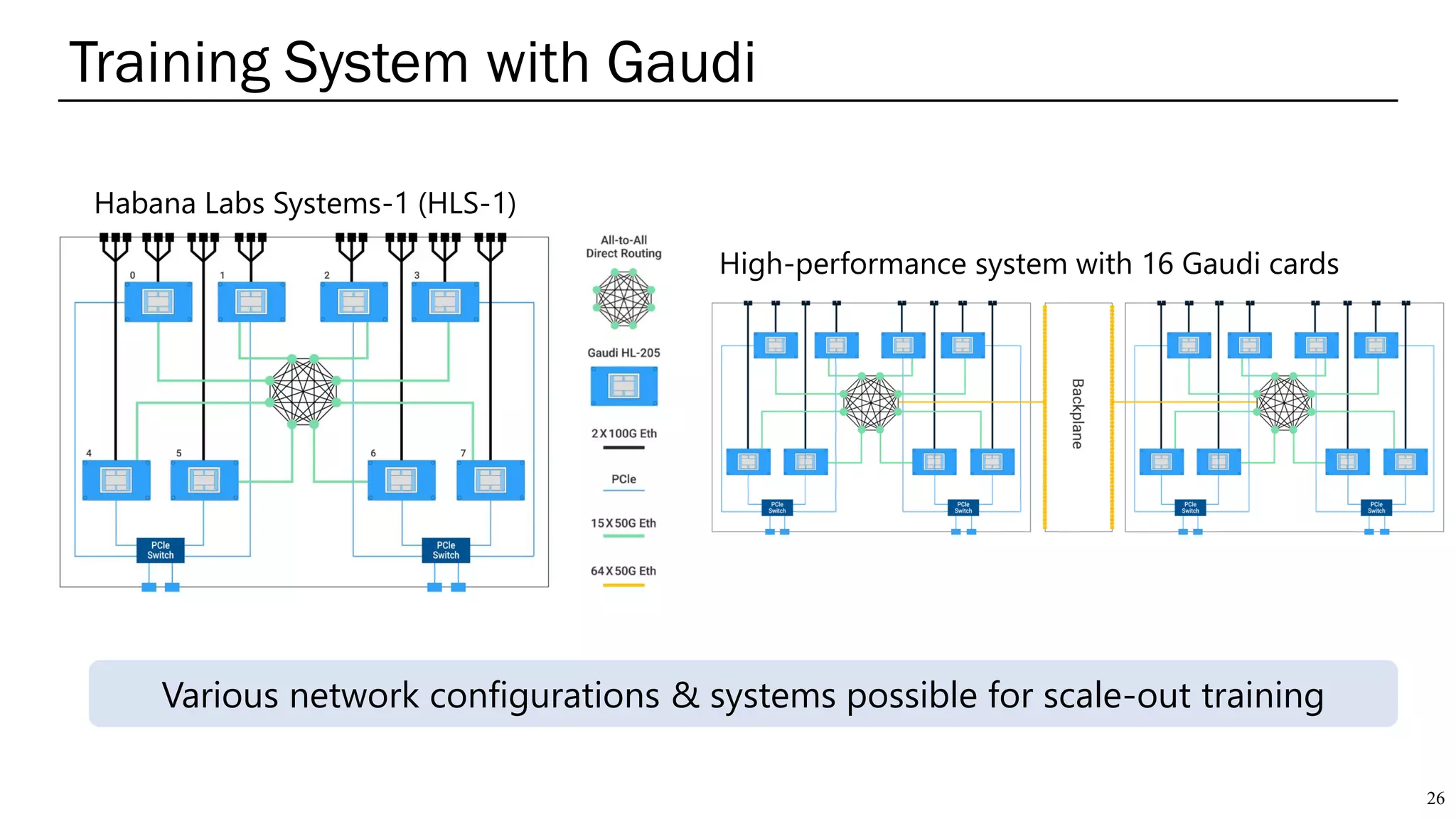
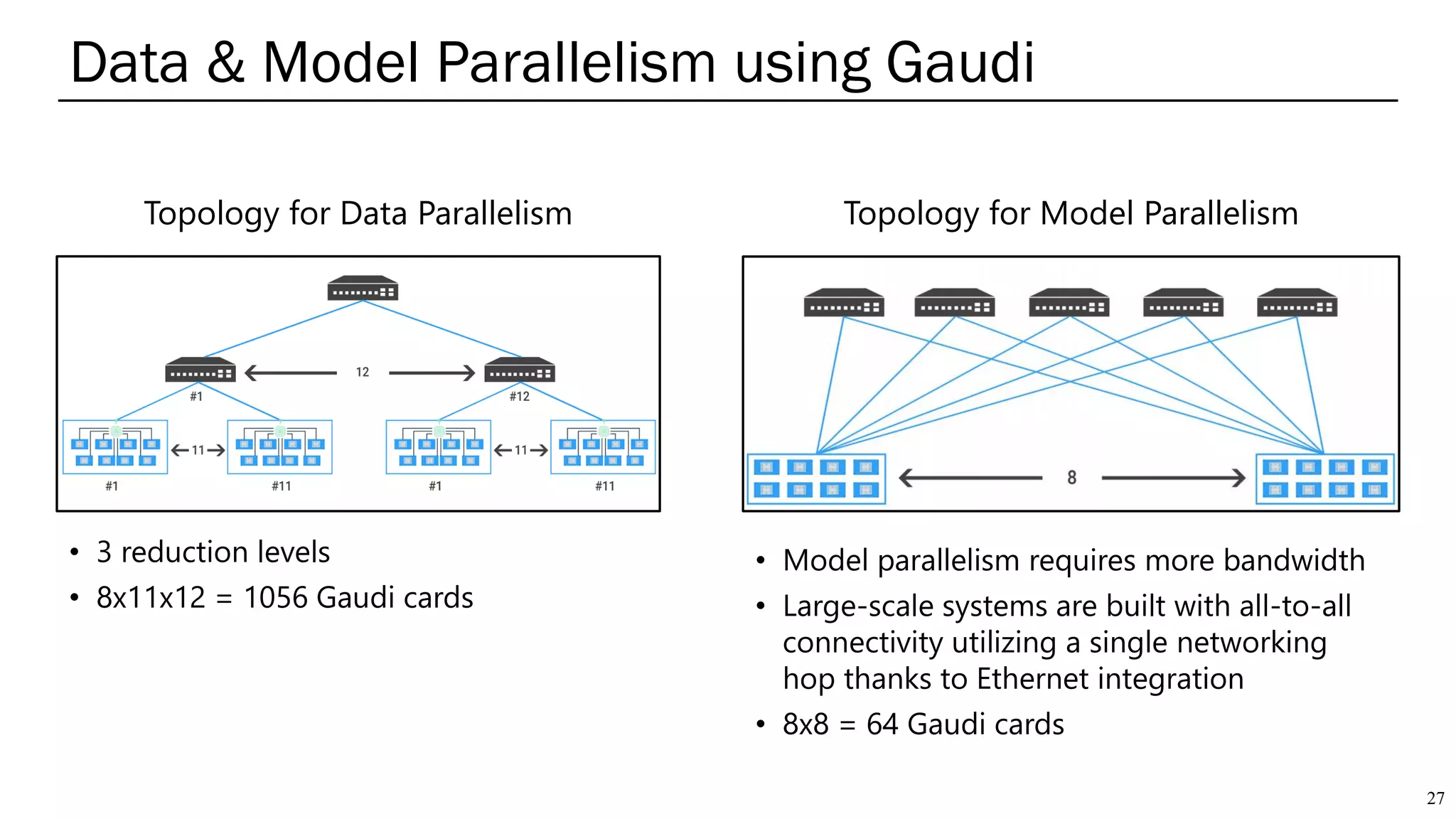
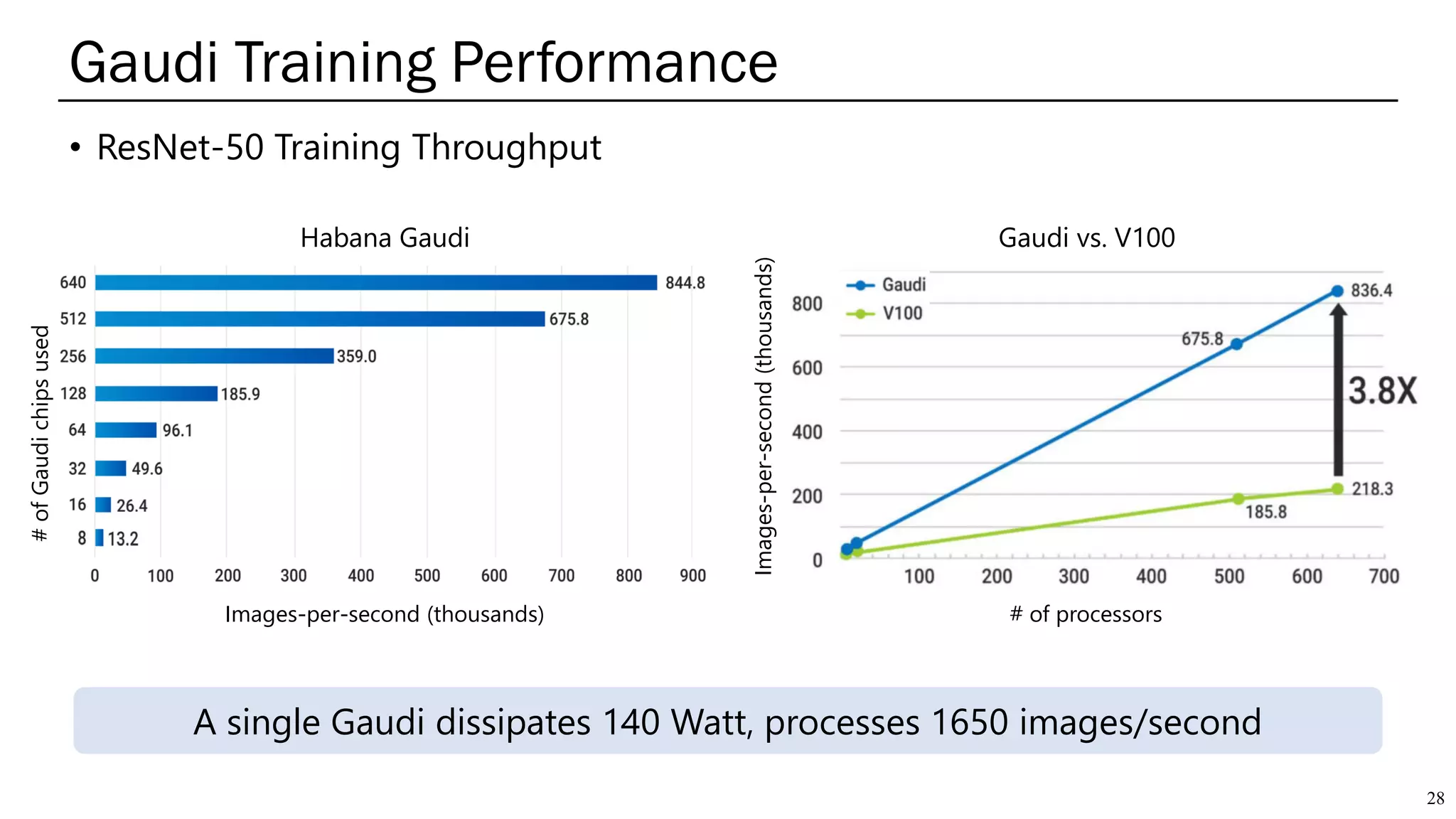
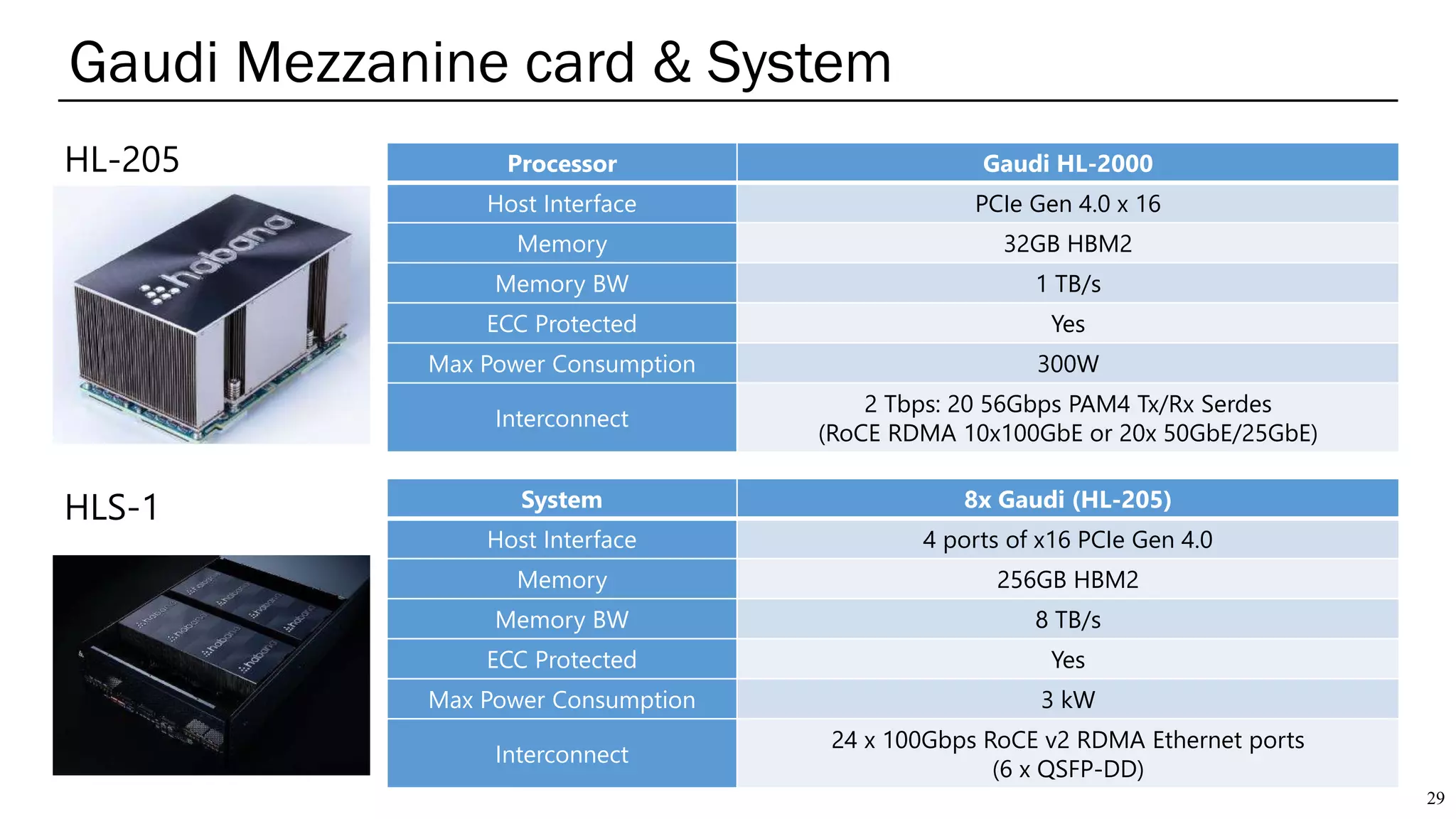
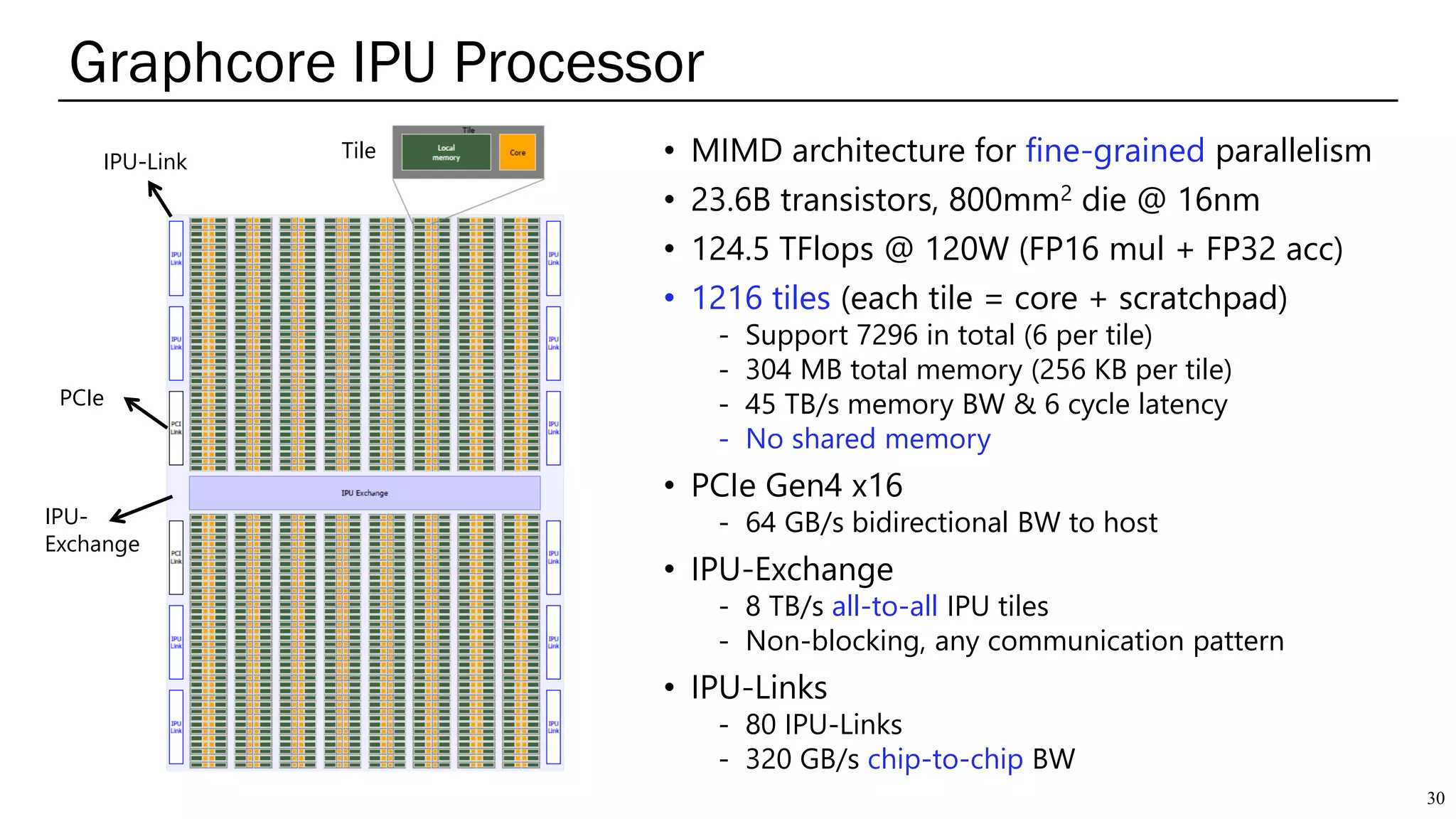
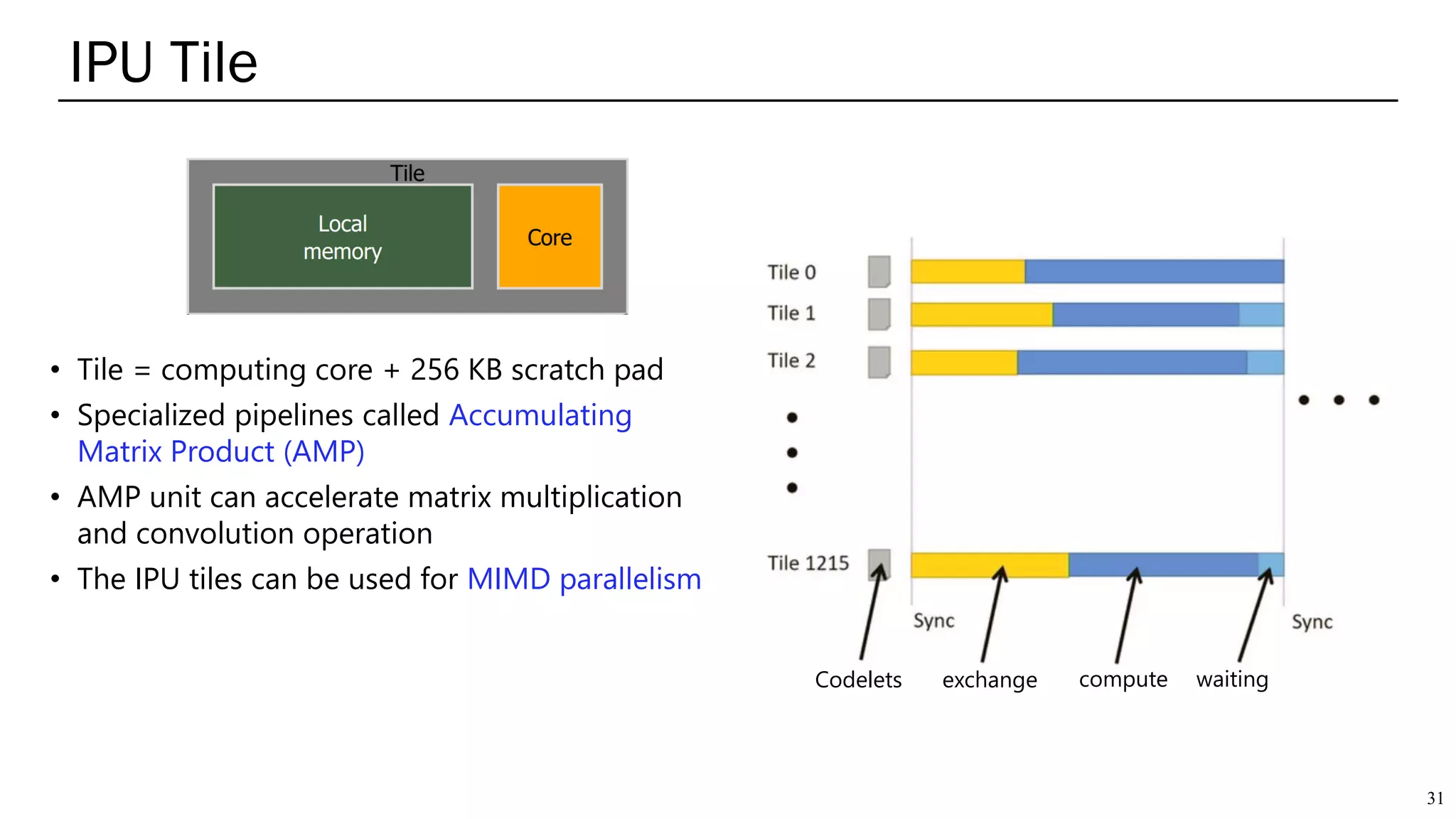
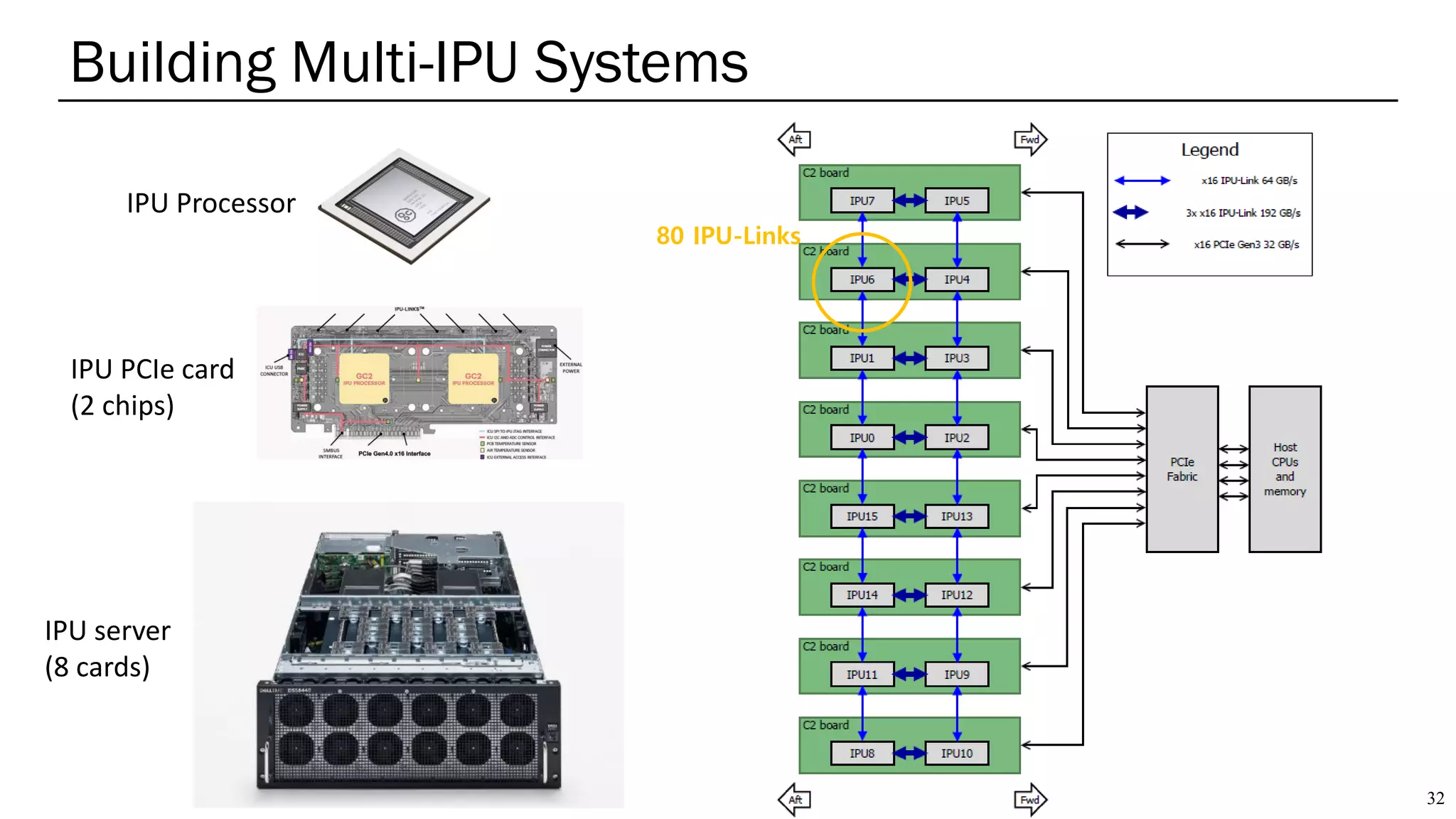
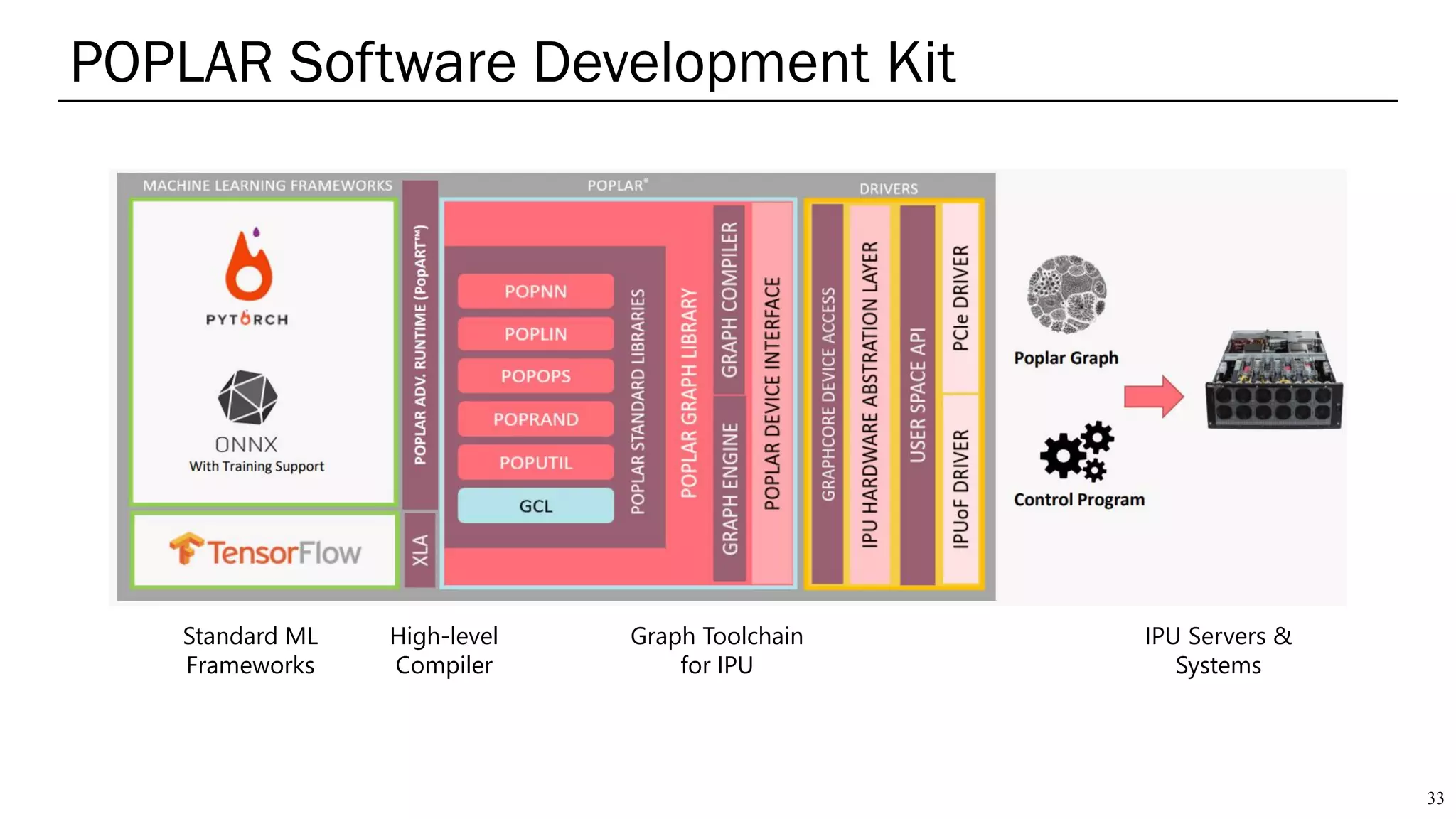
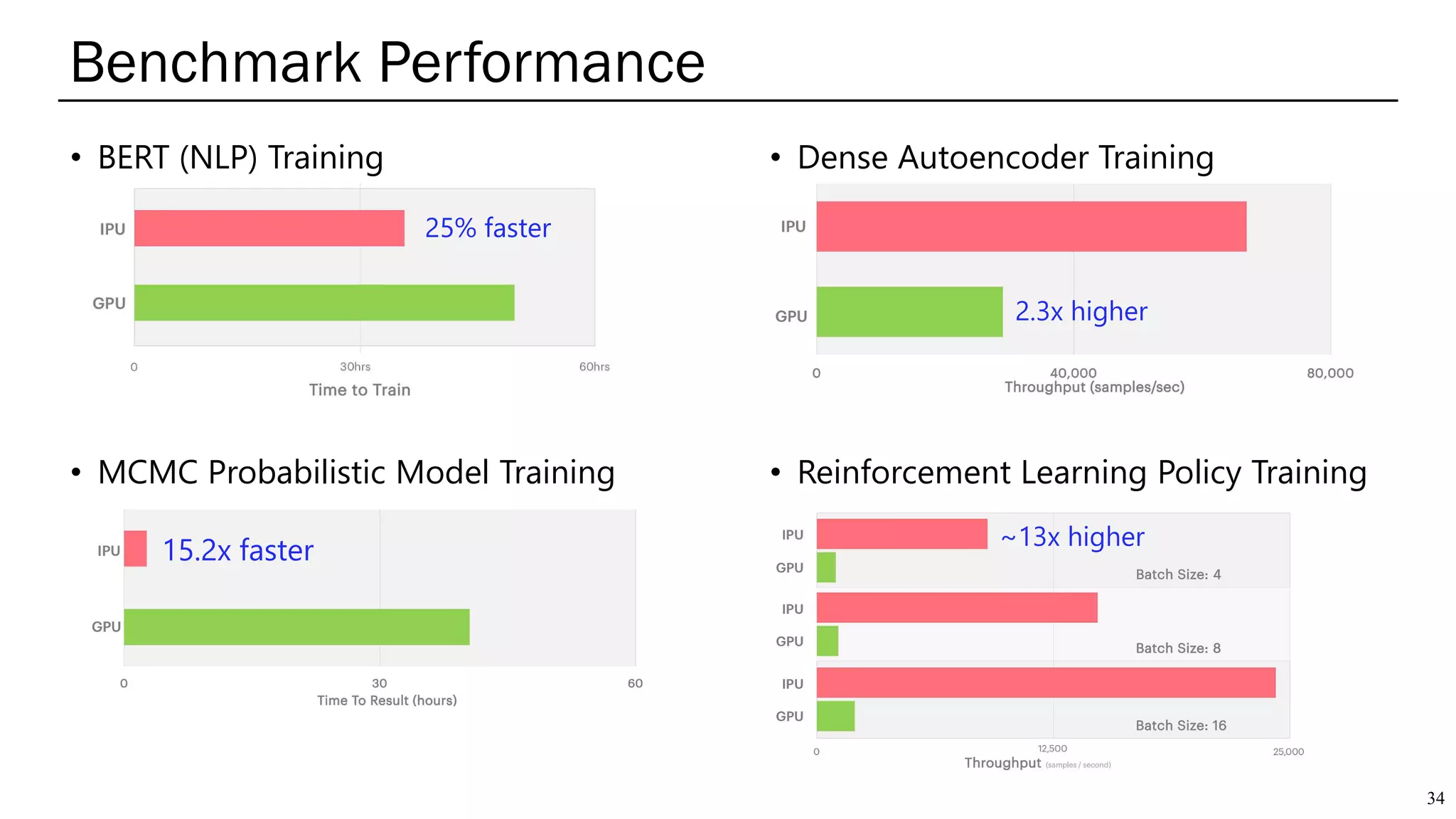
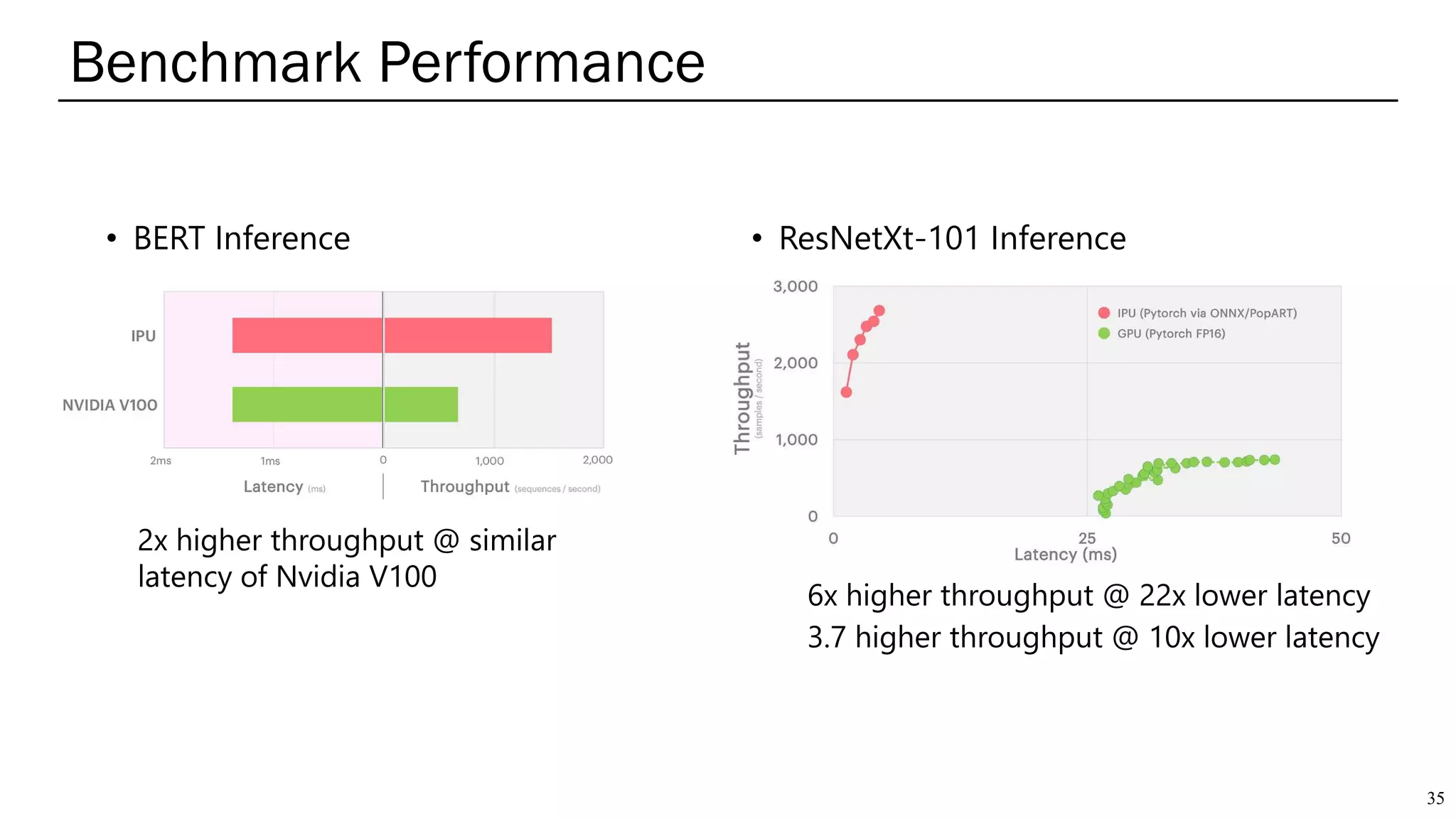
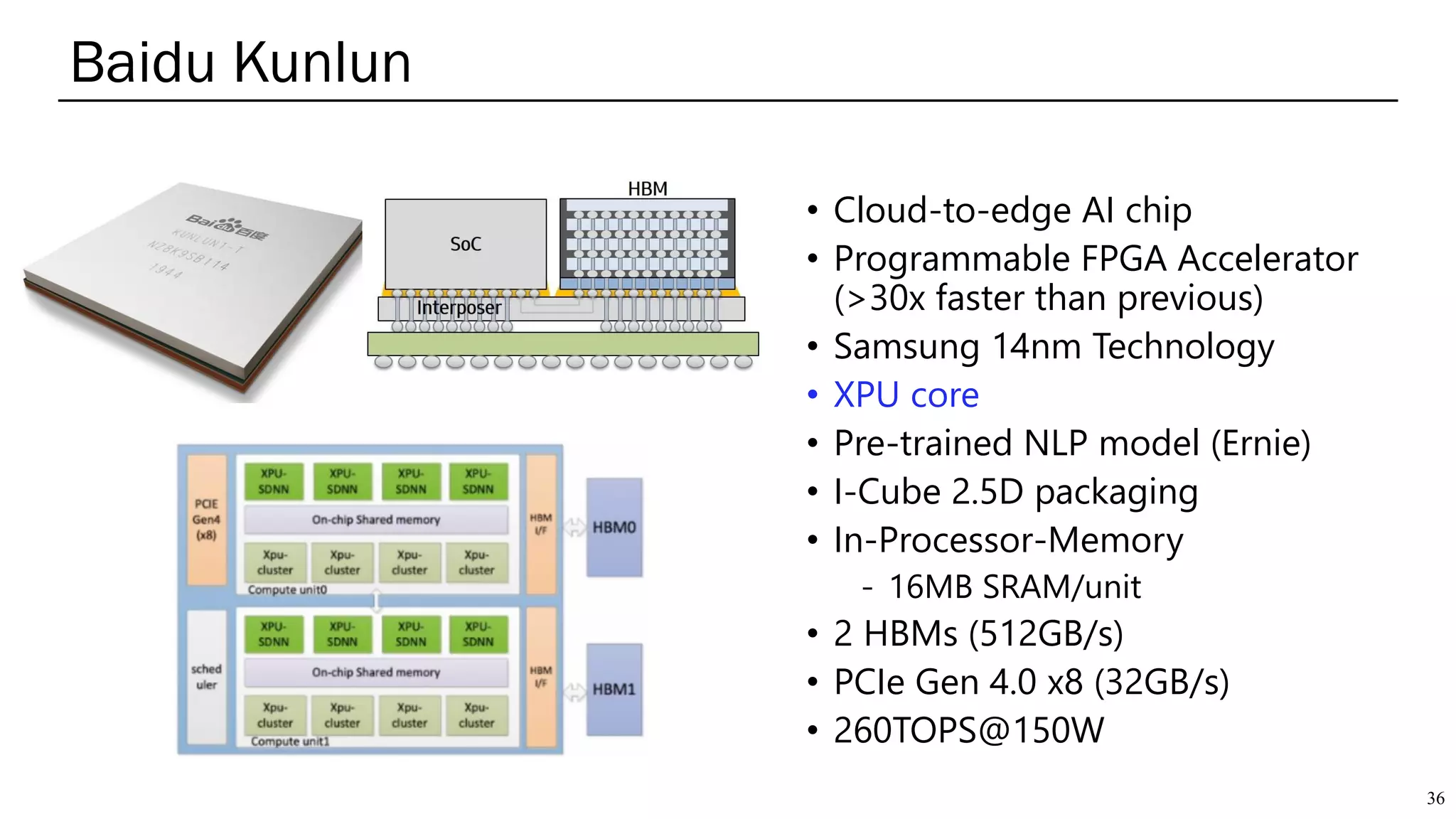
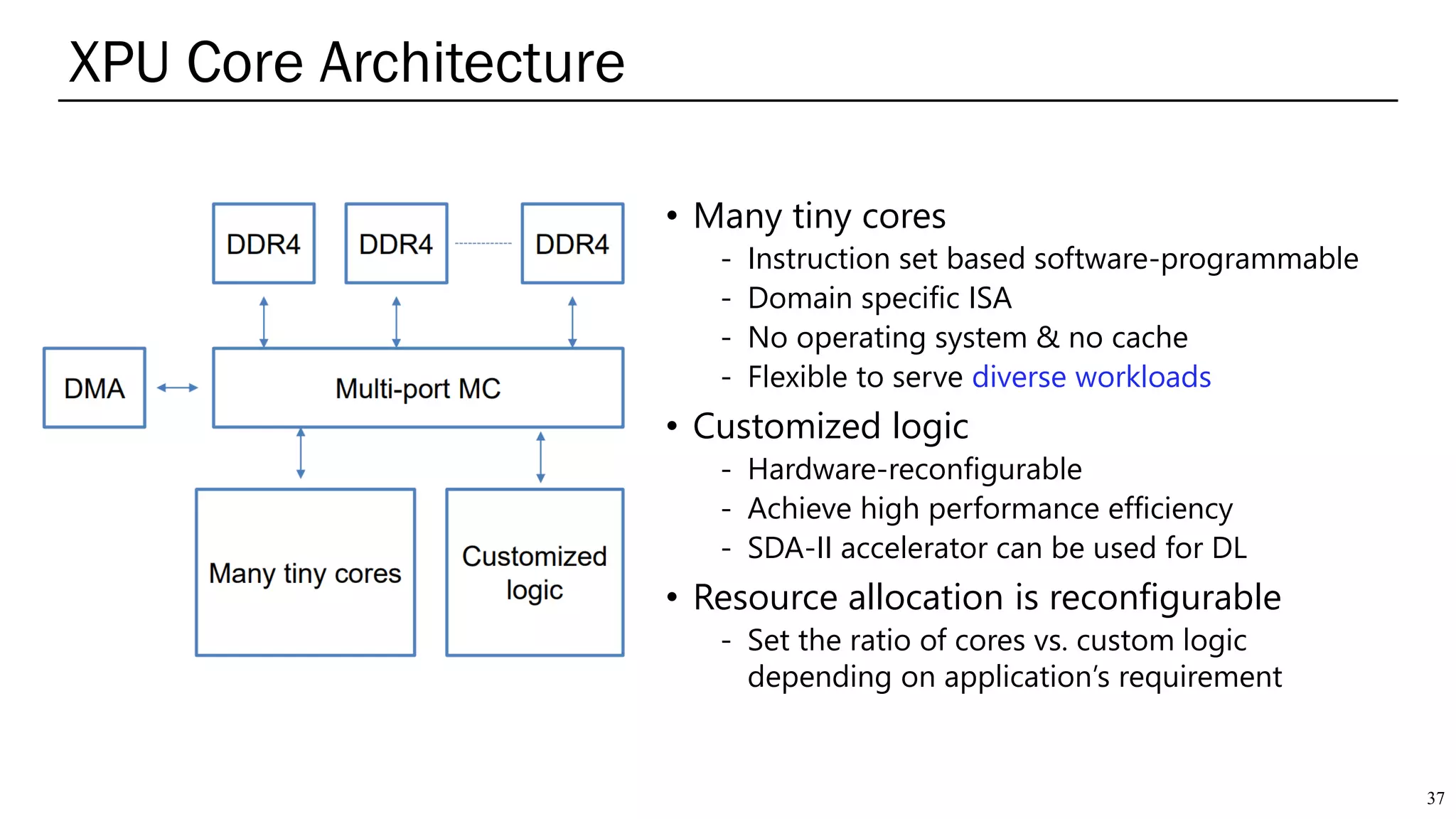
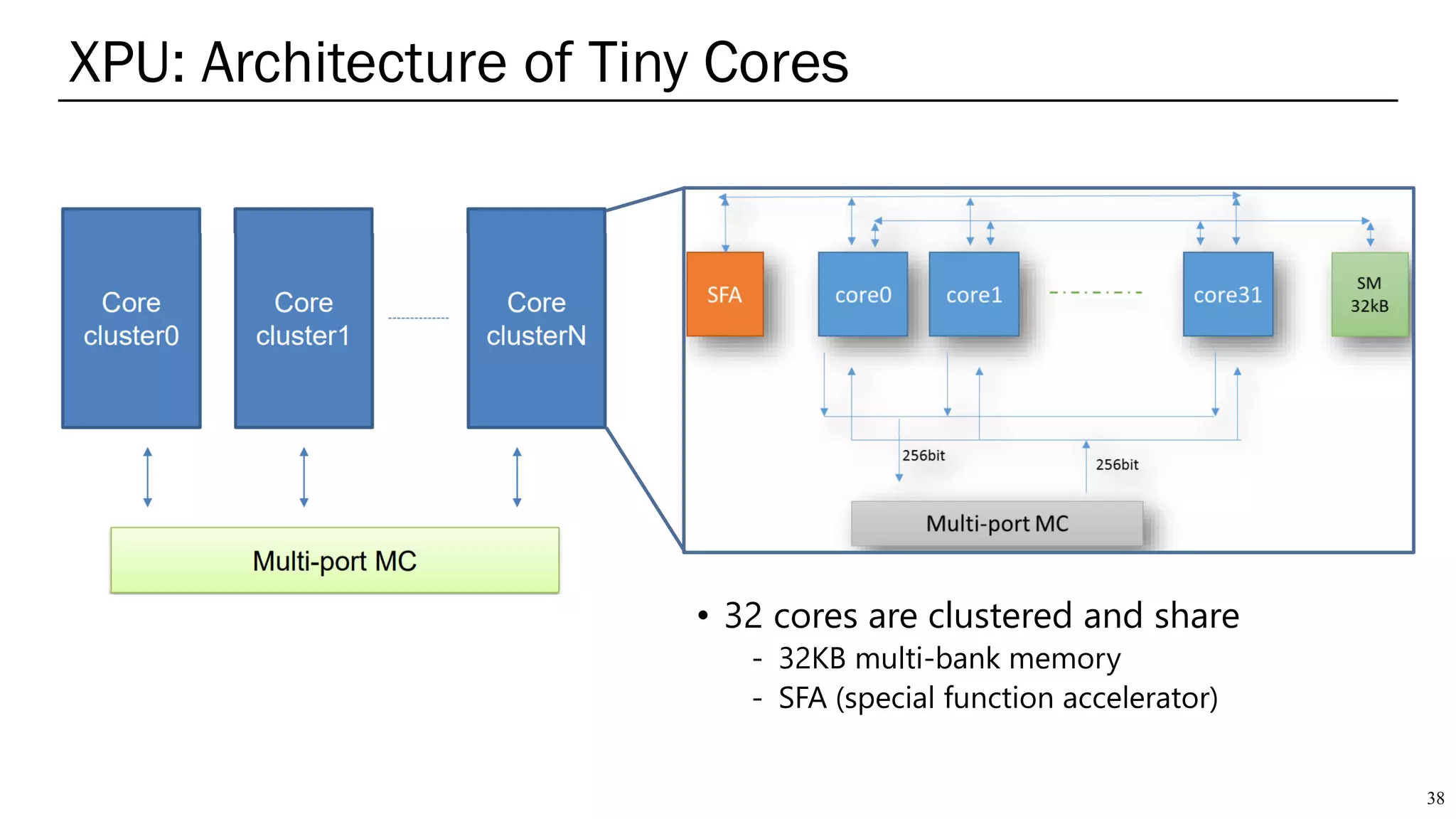
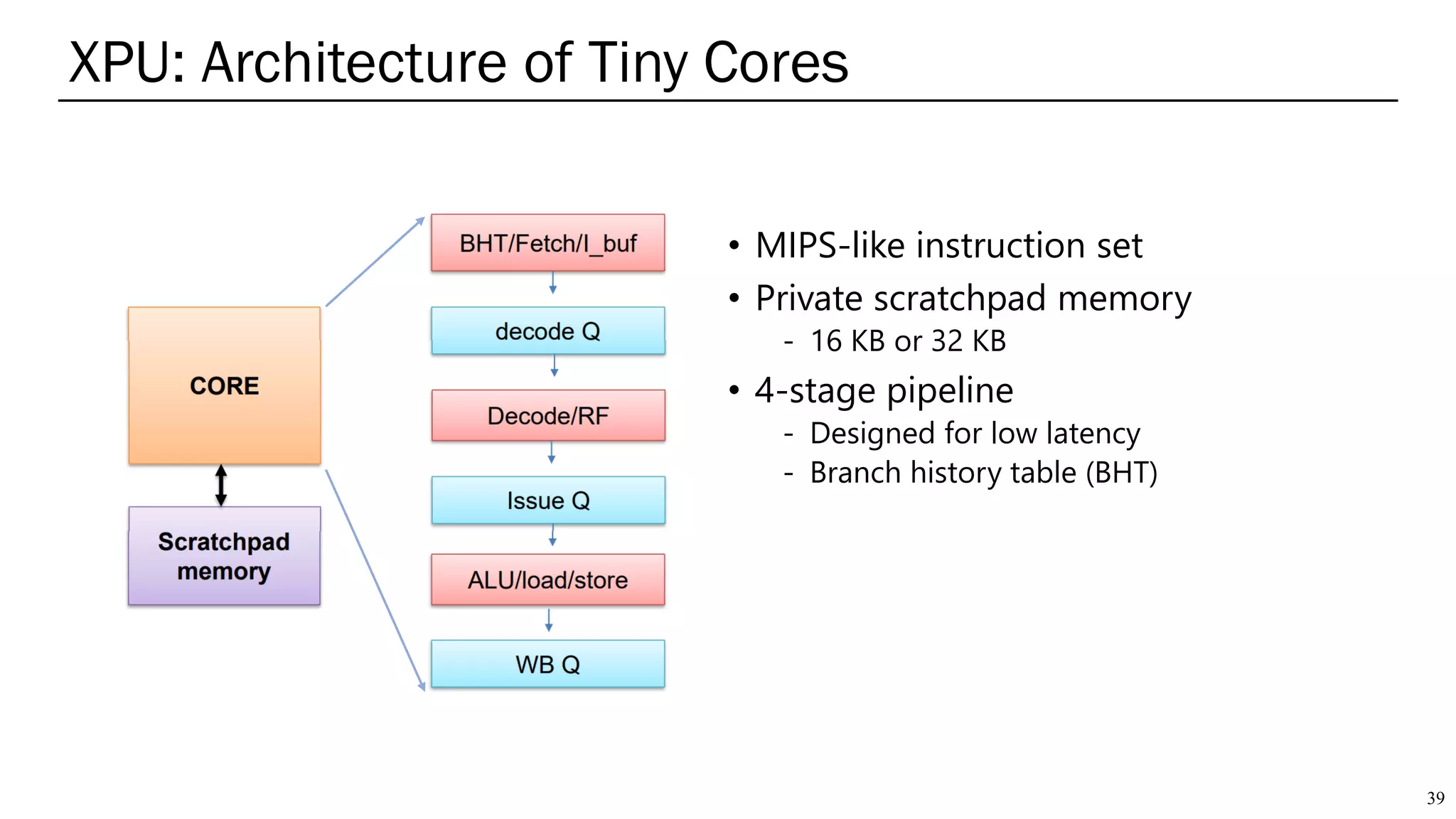
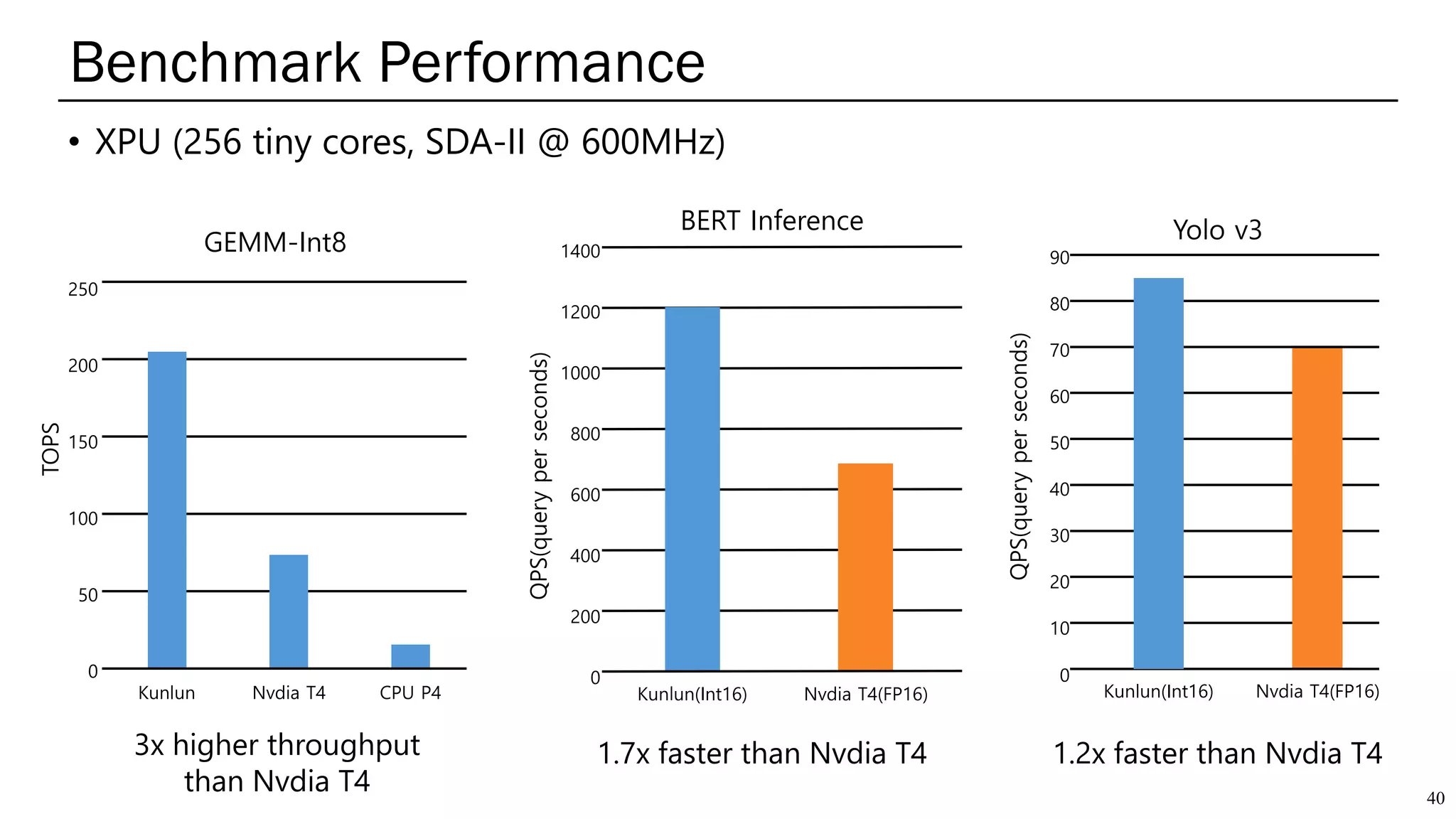
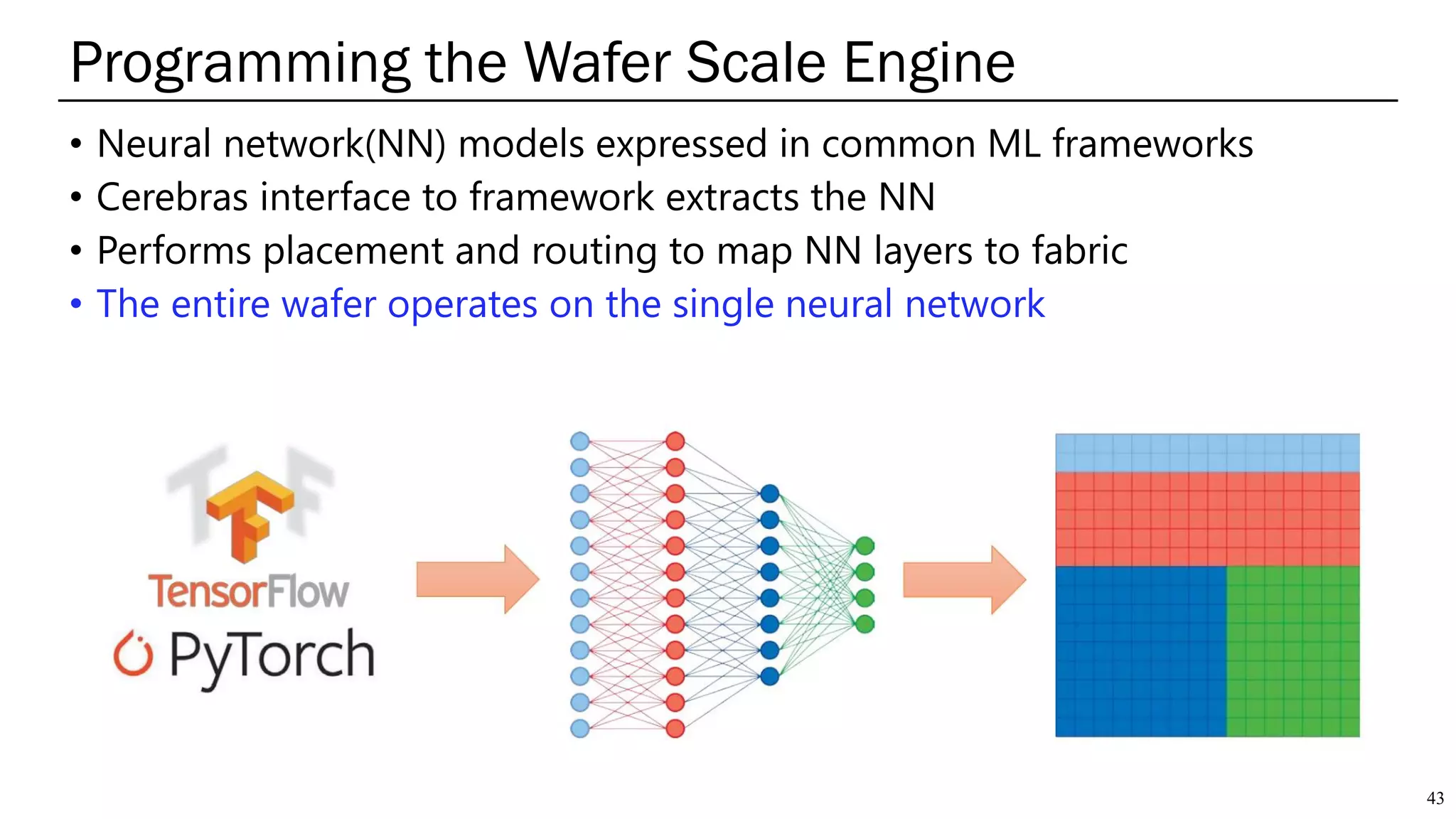
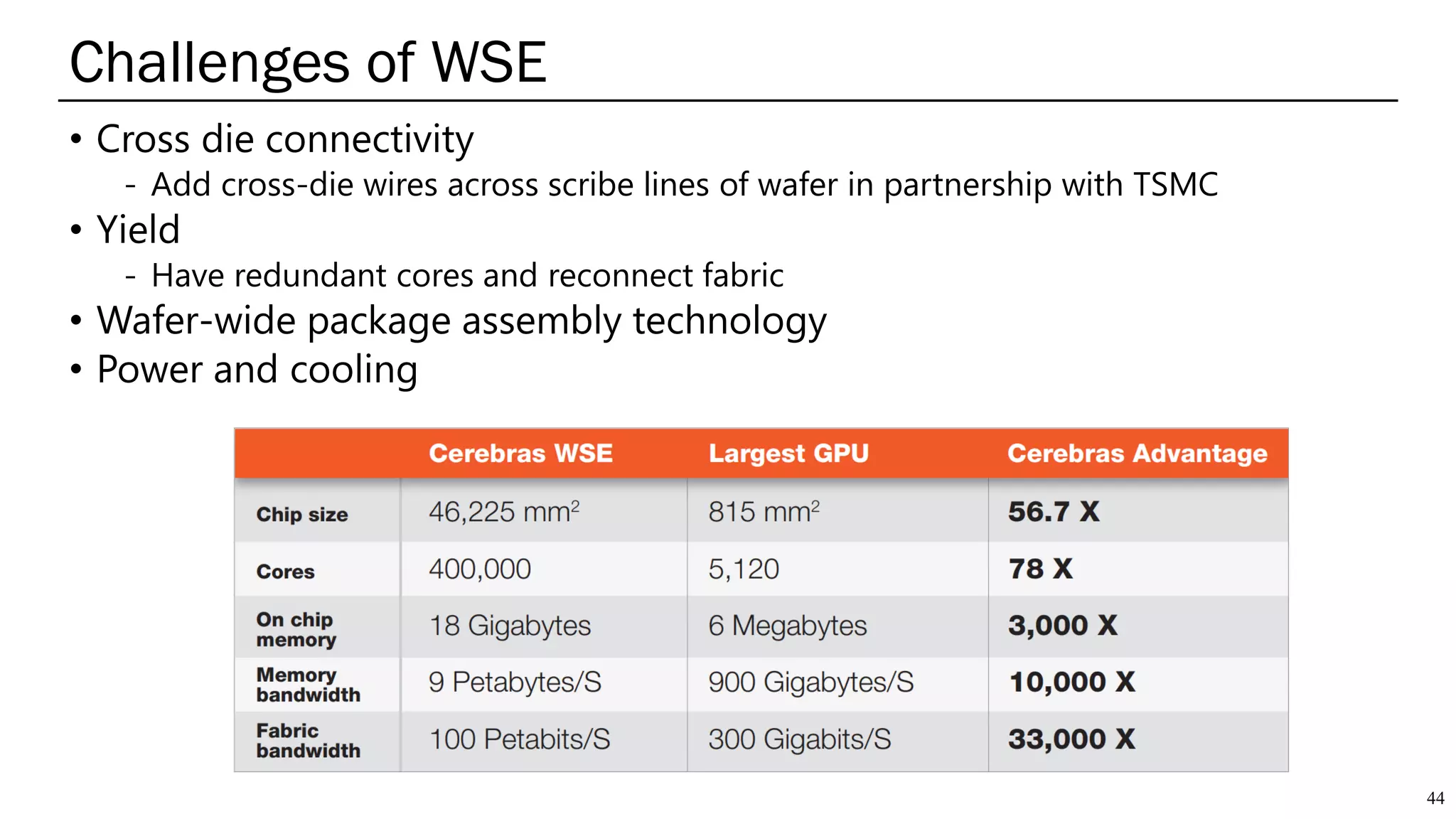
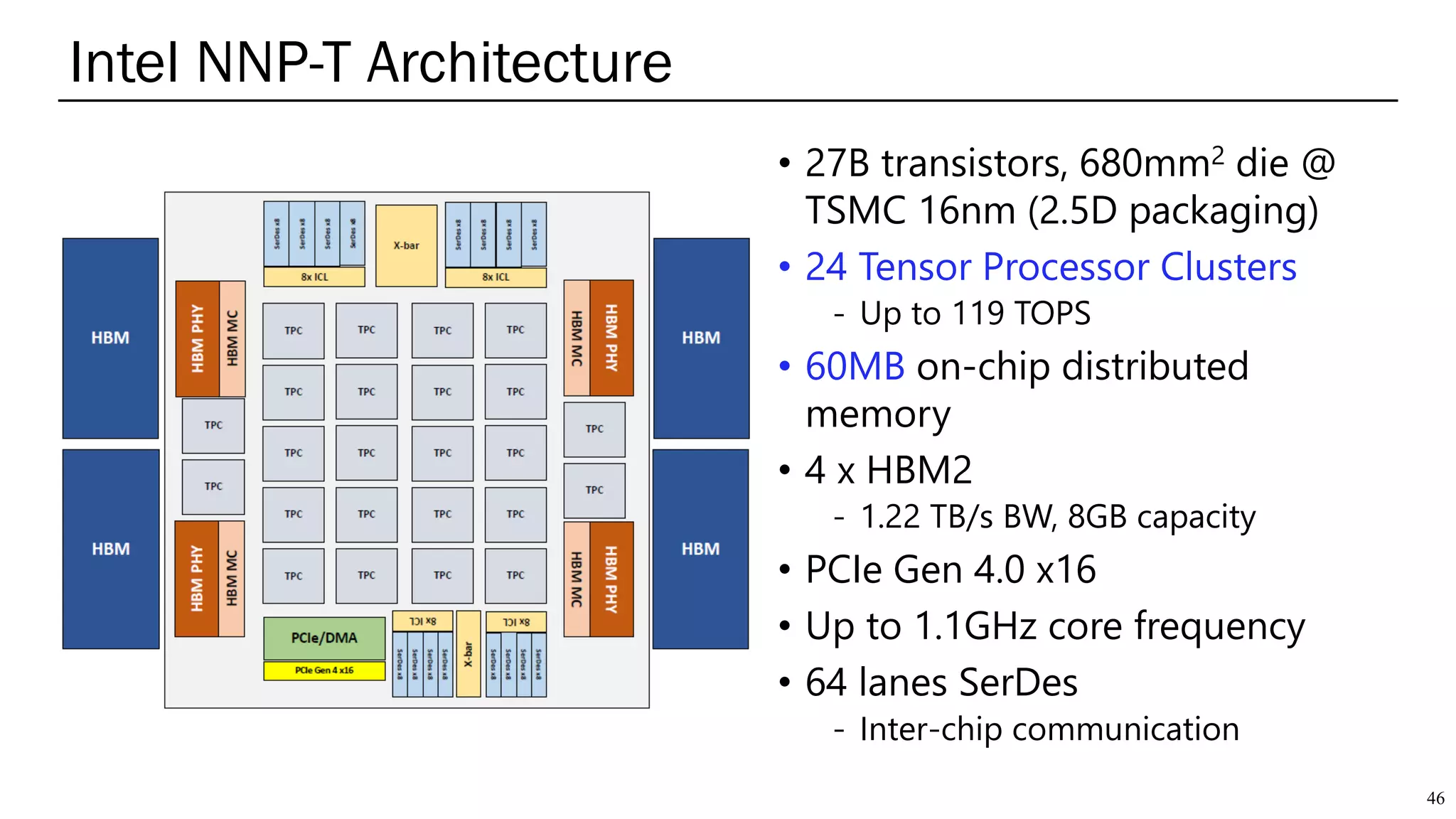
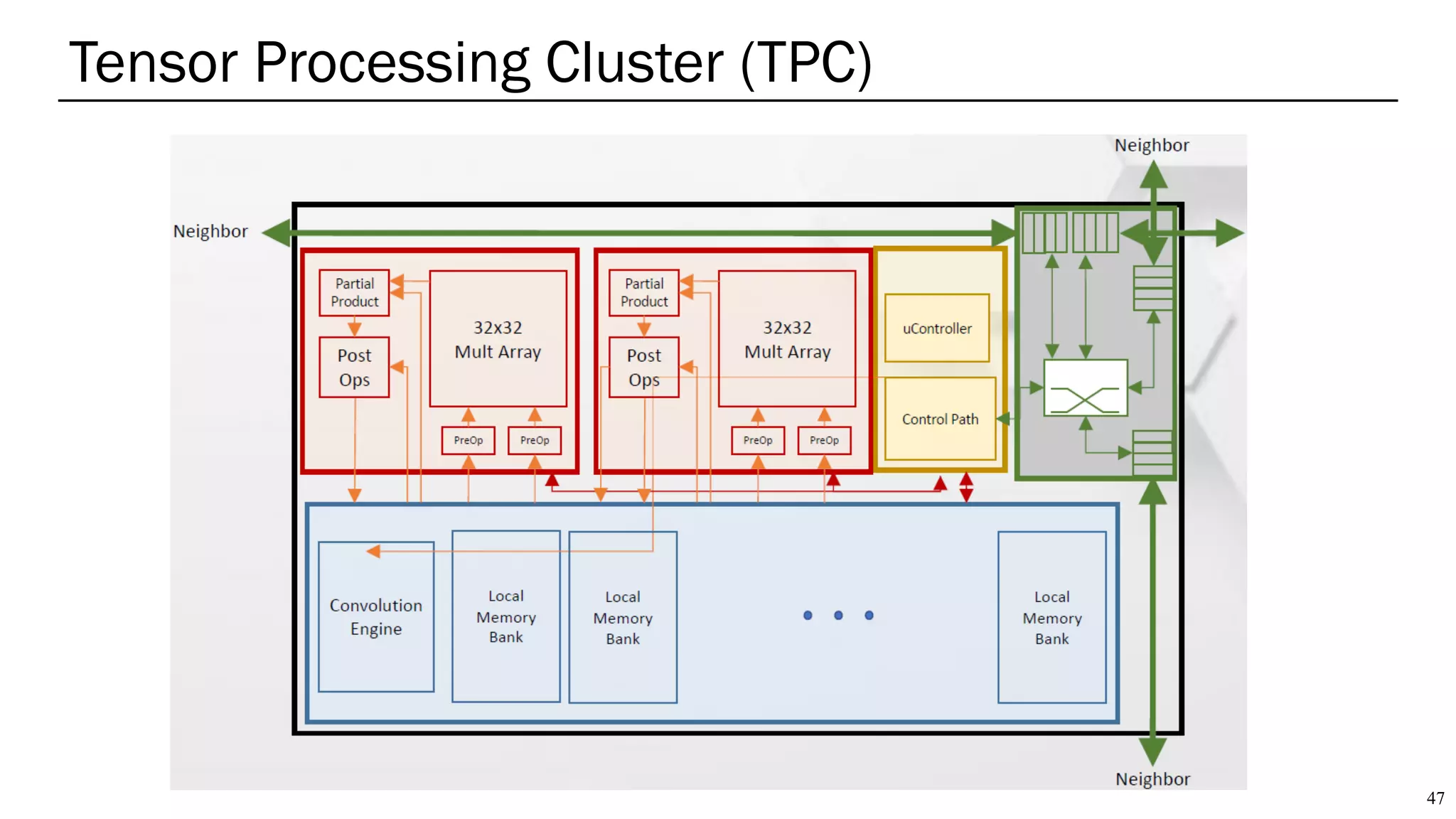
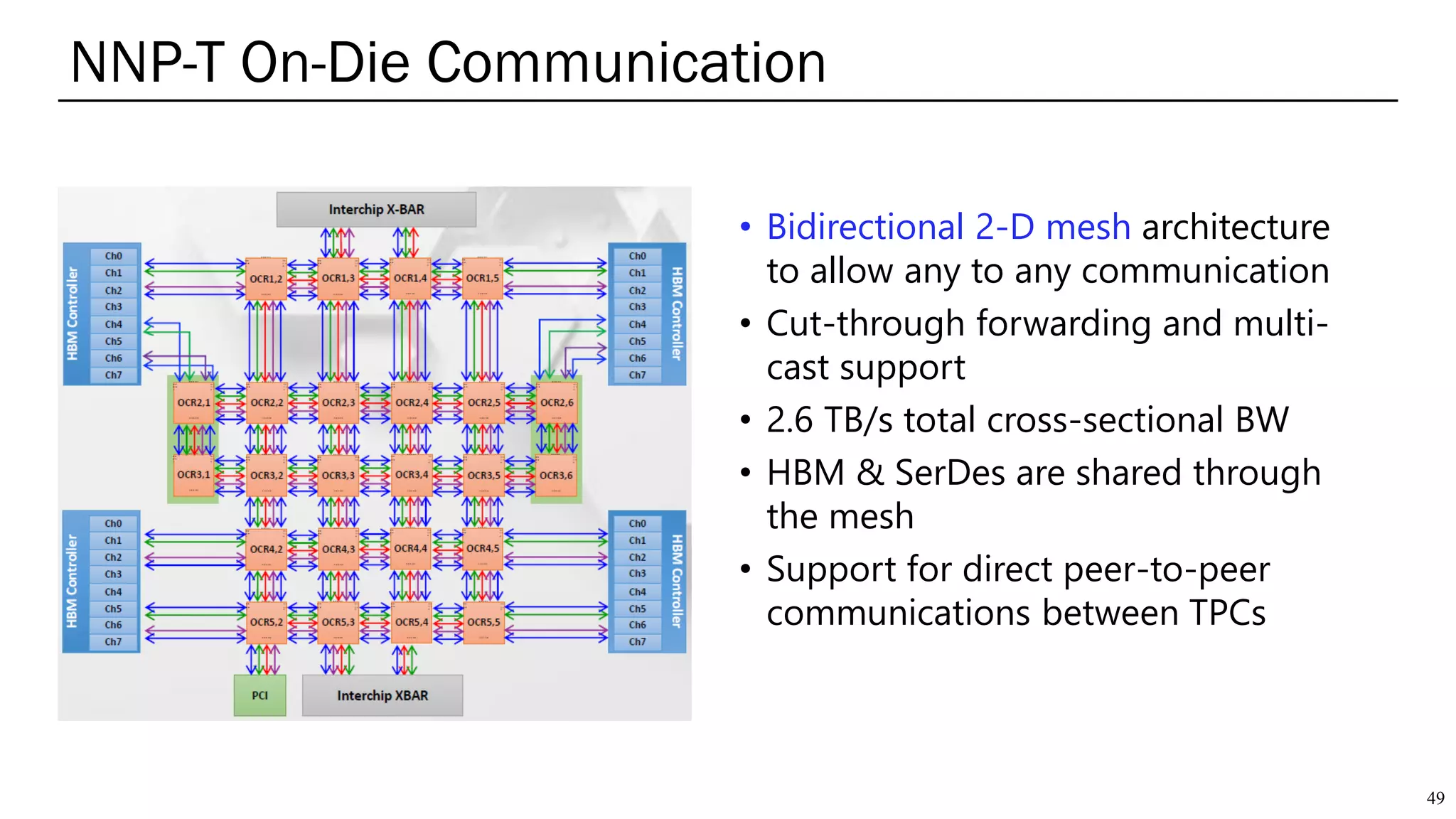
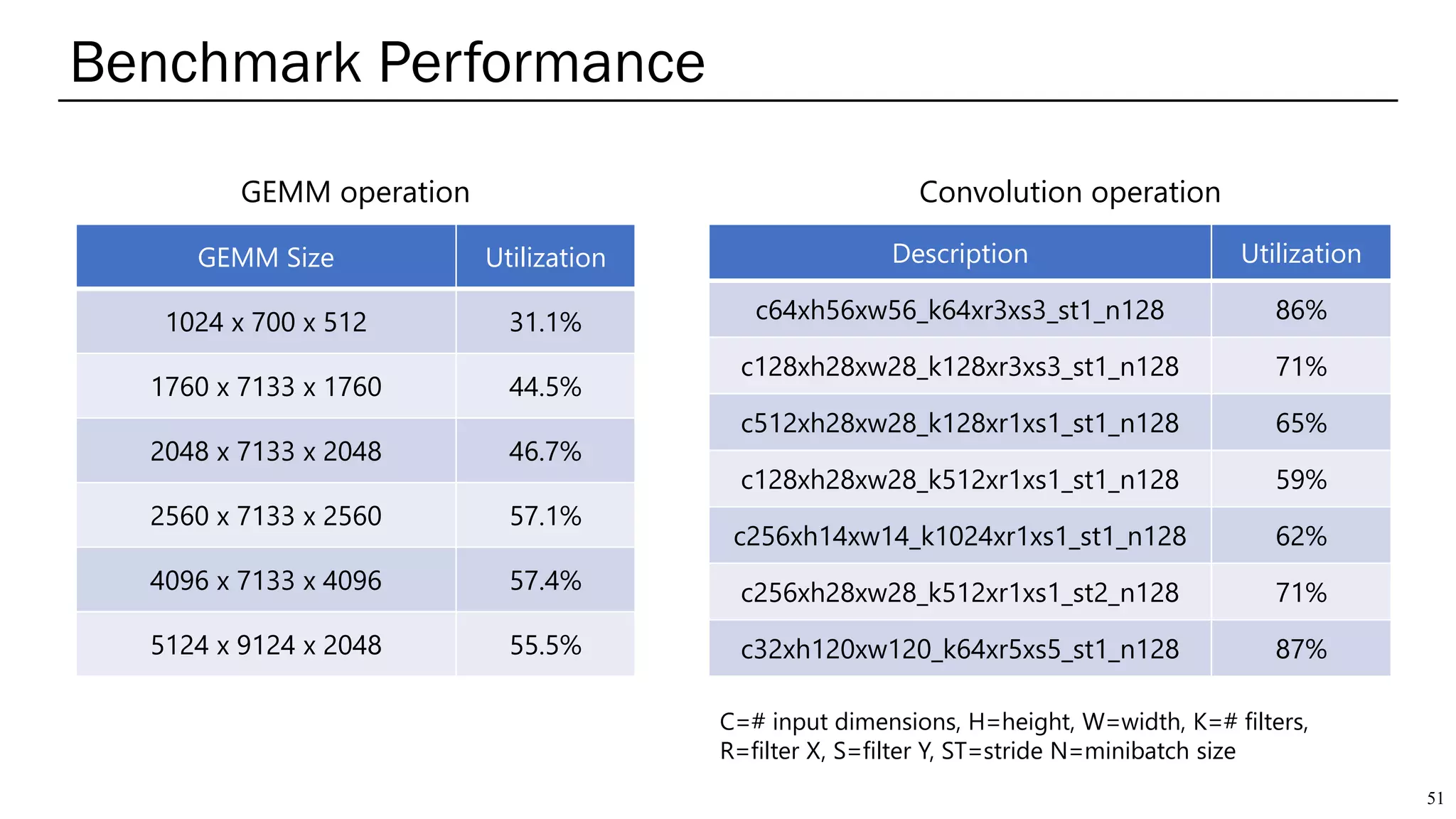
The document summarizes several AI accelerators for cloud datacenters including Google TPU, HabanaLabs Gaudi, Graphcore IPU, and Baidu Kunlun. It discusses their architectures, performance, and how they address challenges in datacenters like workload diversity and energy efficiency. The accelerators use specialized hardware like systolic arrays and FPGA/ASIC designs to achieve much higher performance and efficiency than CPUs and GPUs for AI tasks like training deep learning models.