Download as PDF, PPTX





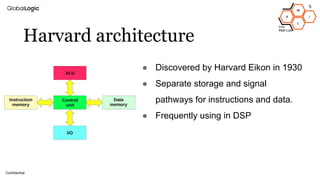

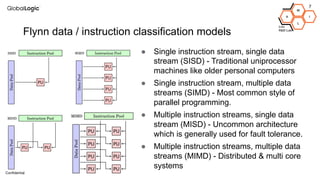

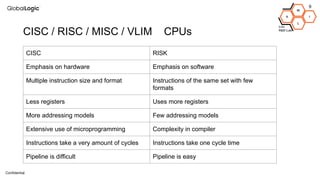
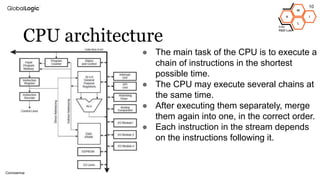
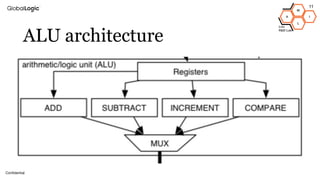




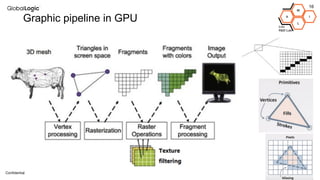
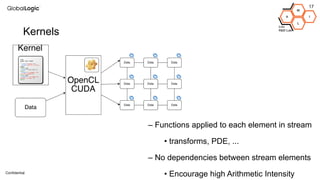
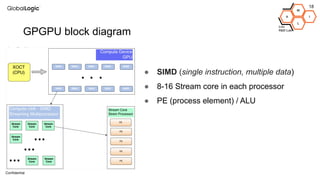
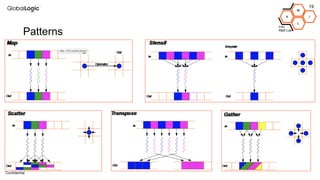
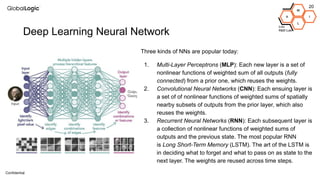
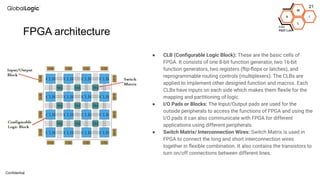

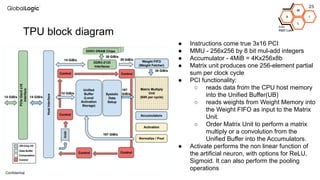
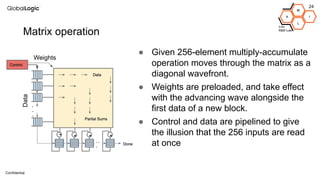
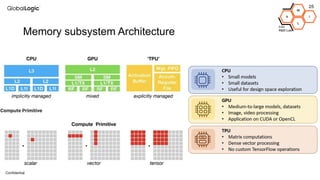

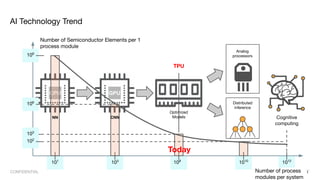
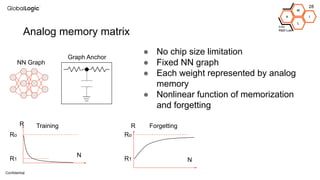



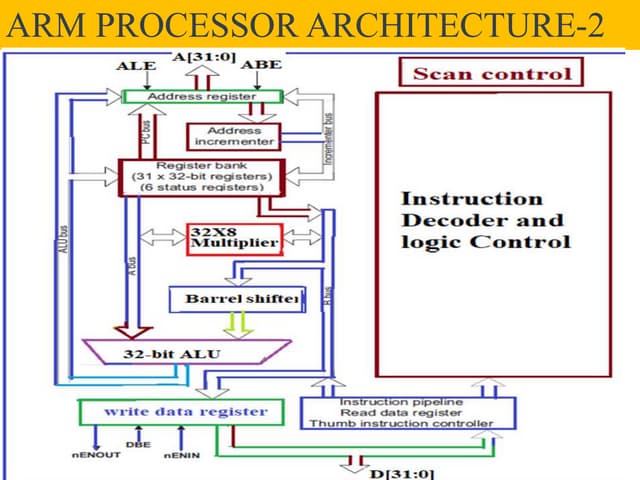
This document provides an overview of CPU, GPU, and TPU architectures for artificial intelligence. It discusses the historical context of the Harvard and von Neumann architectures. It describes key aspects of CPU architecture including CISC/RISC designs. GPU architecture is summarized as being well-suited for data parallelism. The document outlines the TPU architecture including its block diagram and use of matrix operations. Finally, it presents some next technological steps such as analog processors and distributed inference.