Download as PDF, PPTX



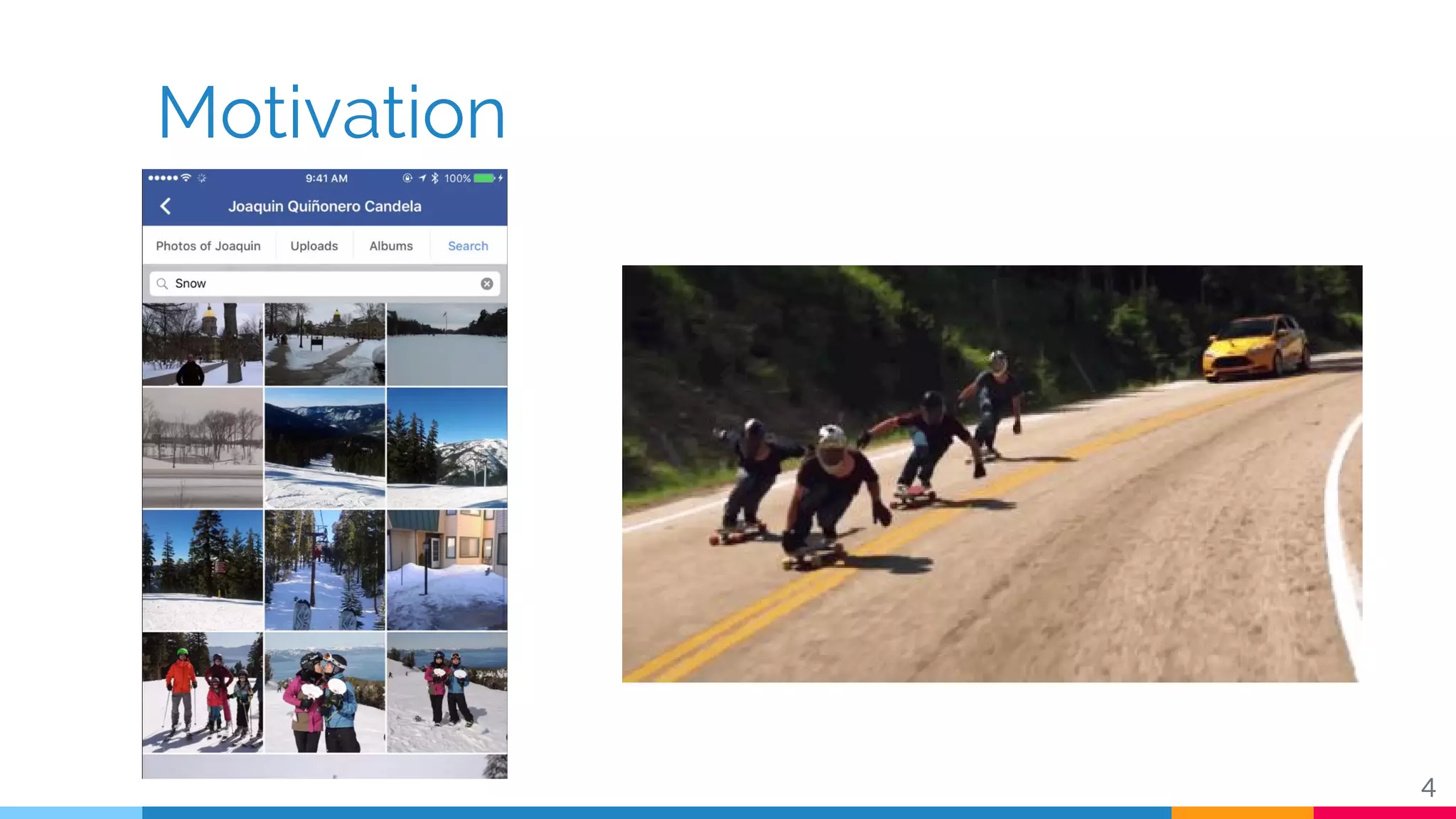




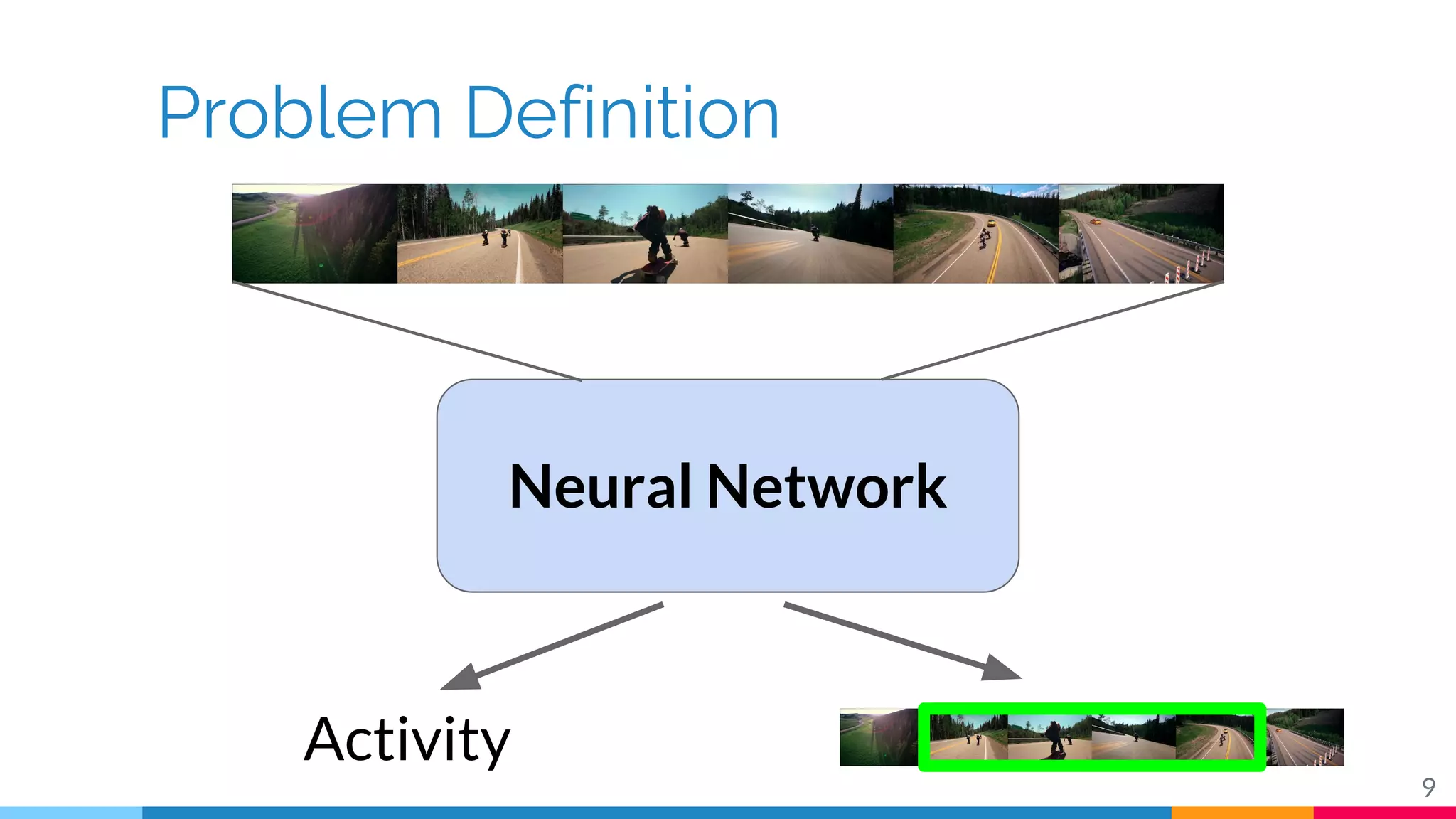
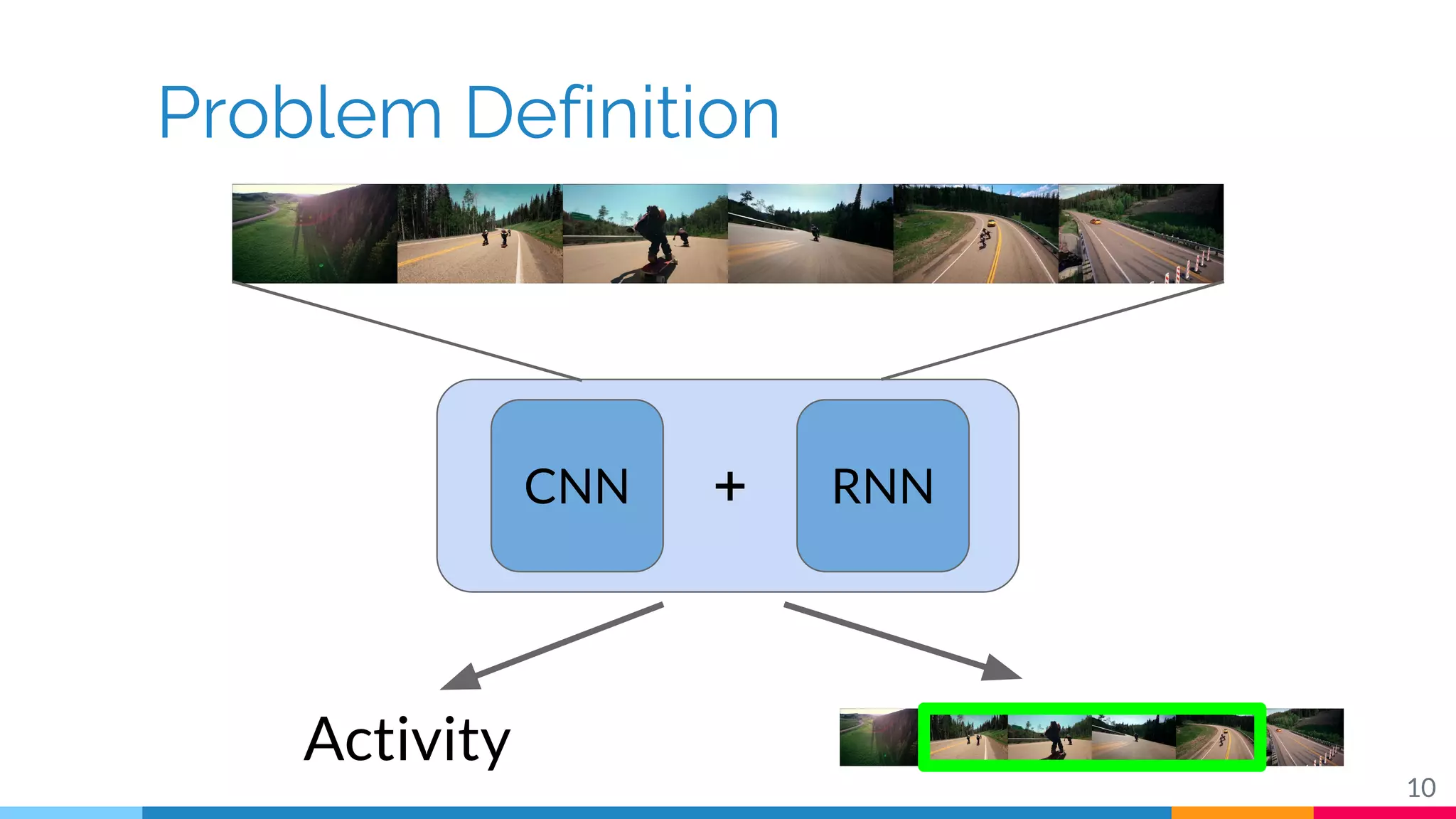



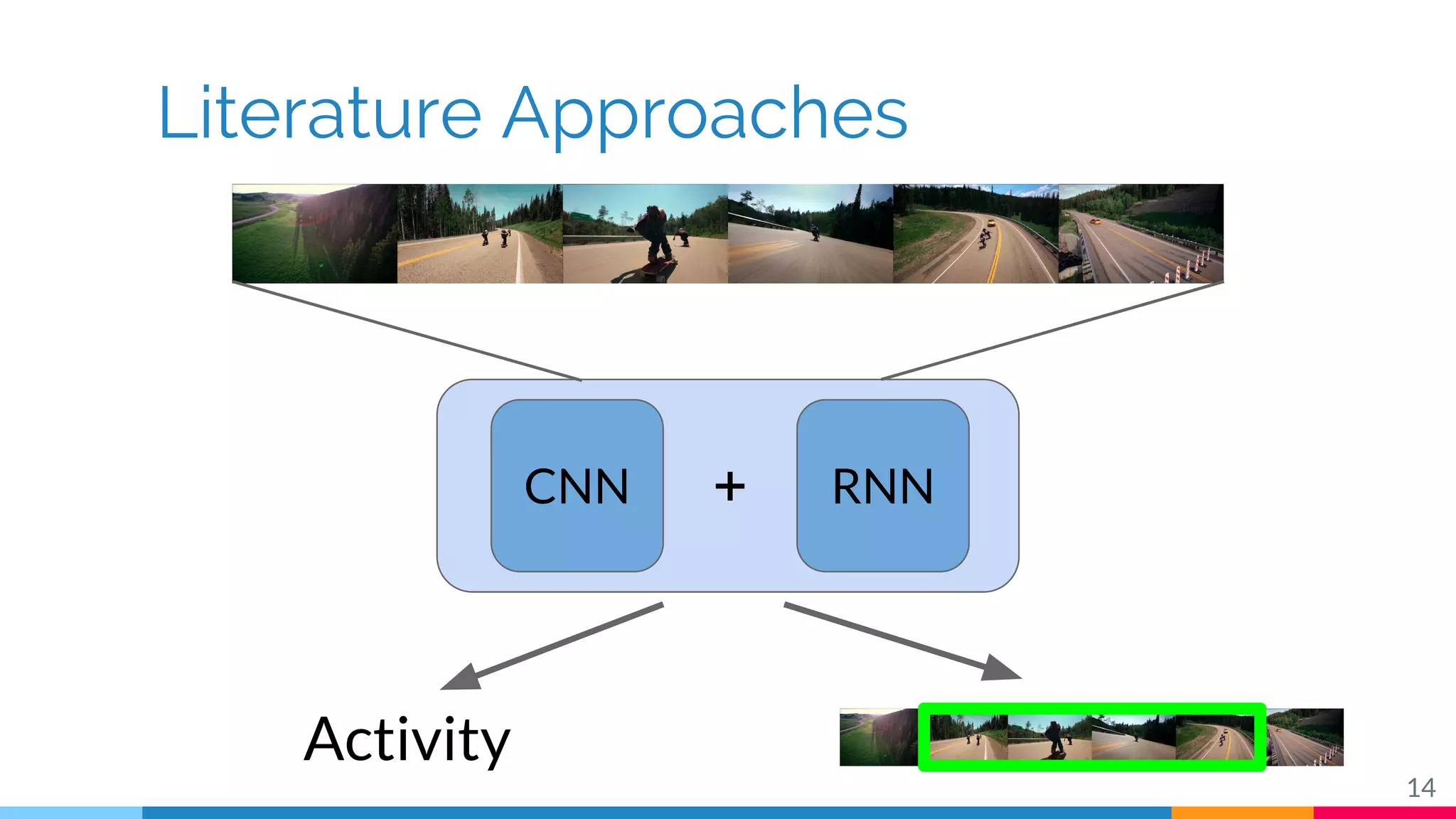
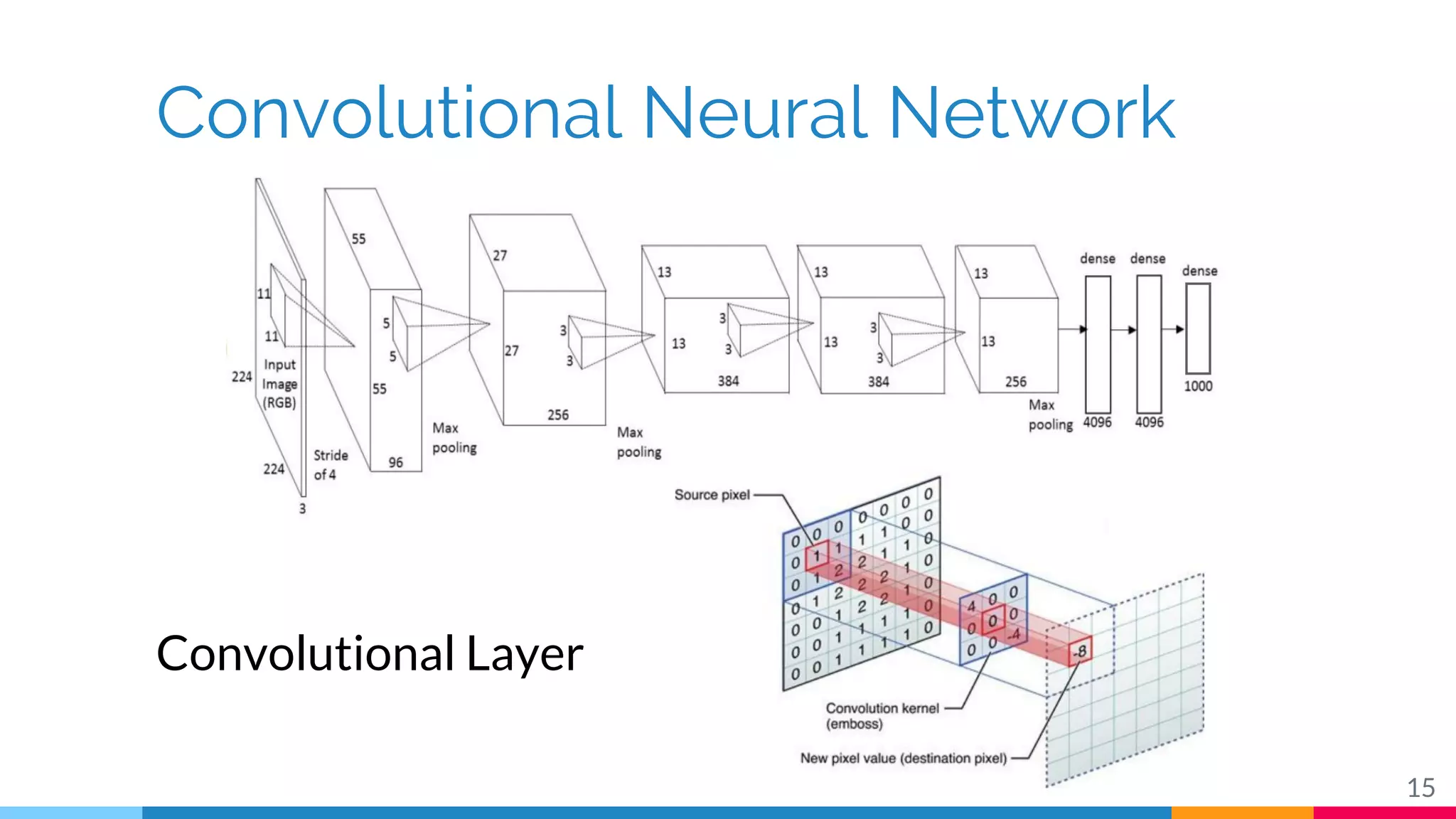
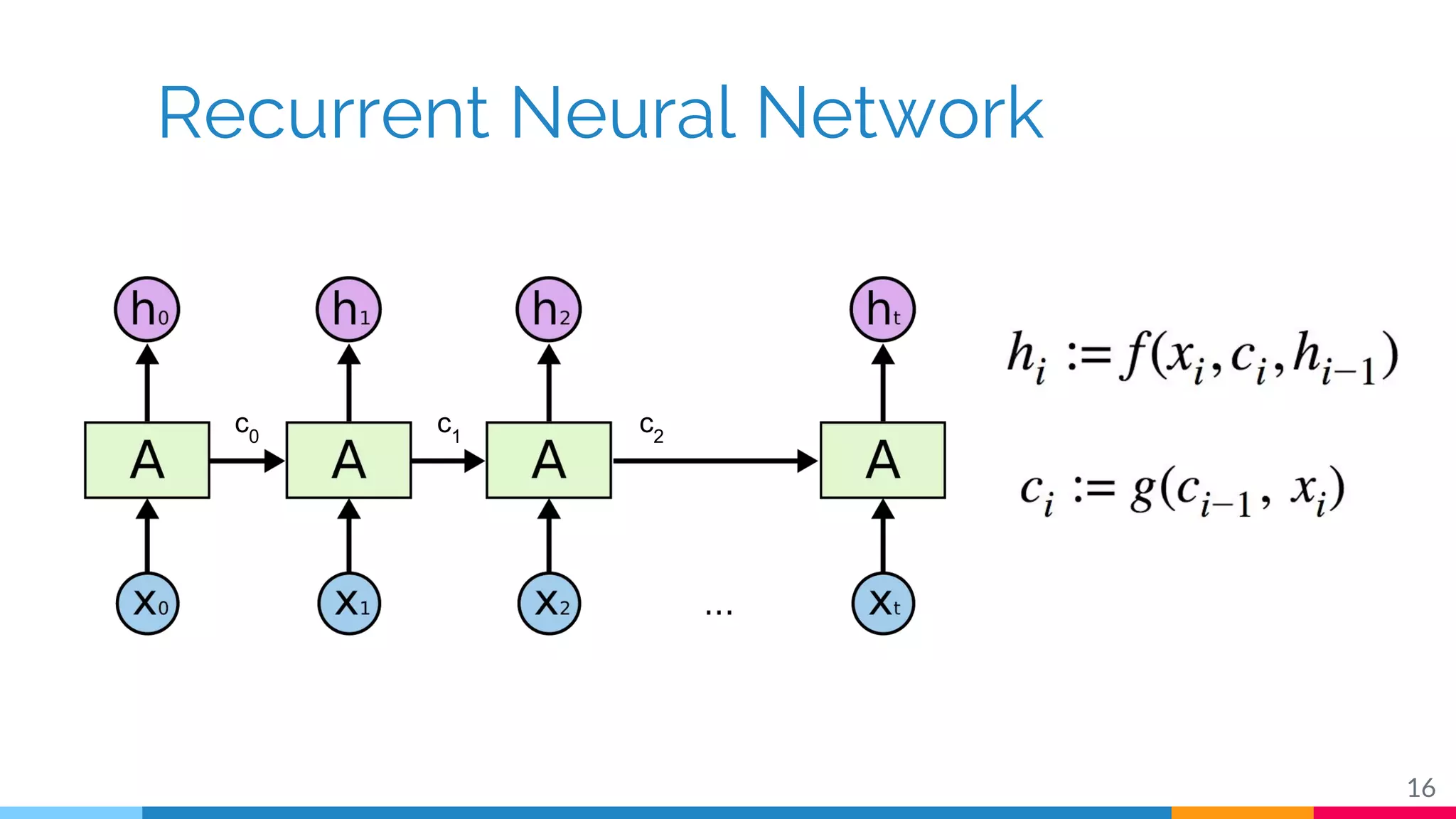
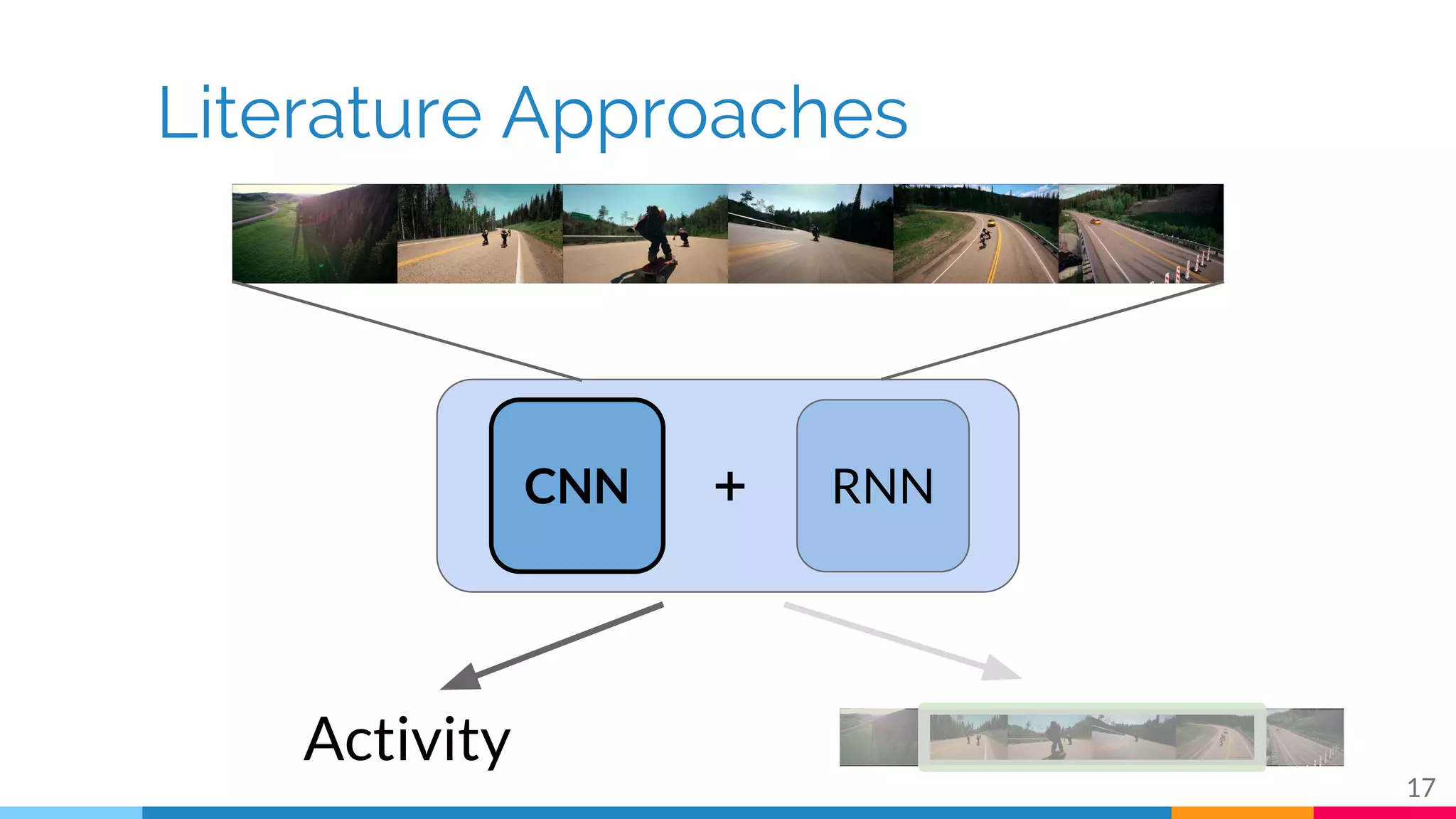
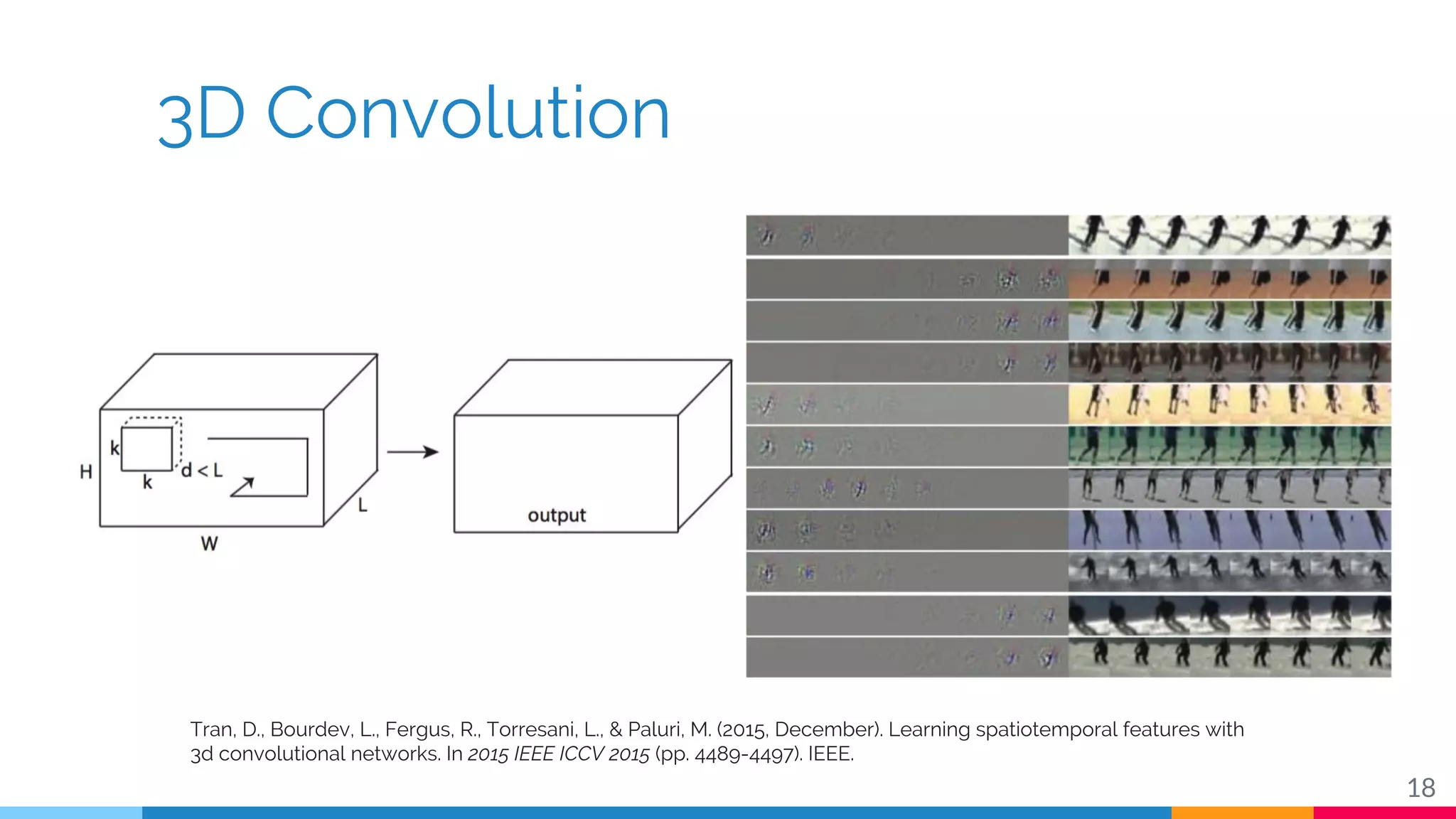

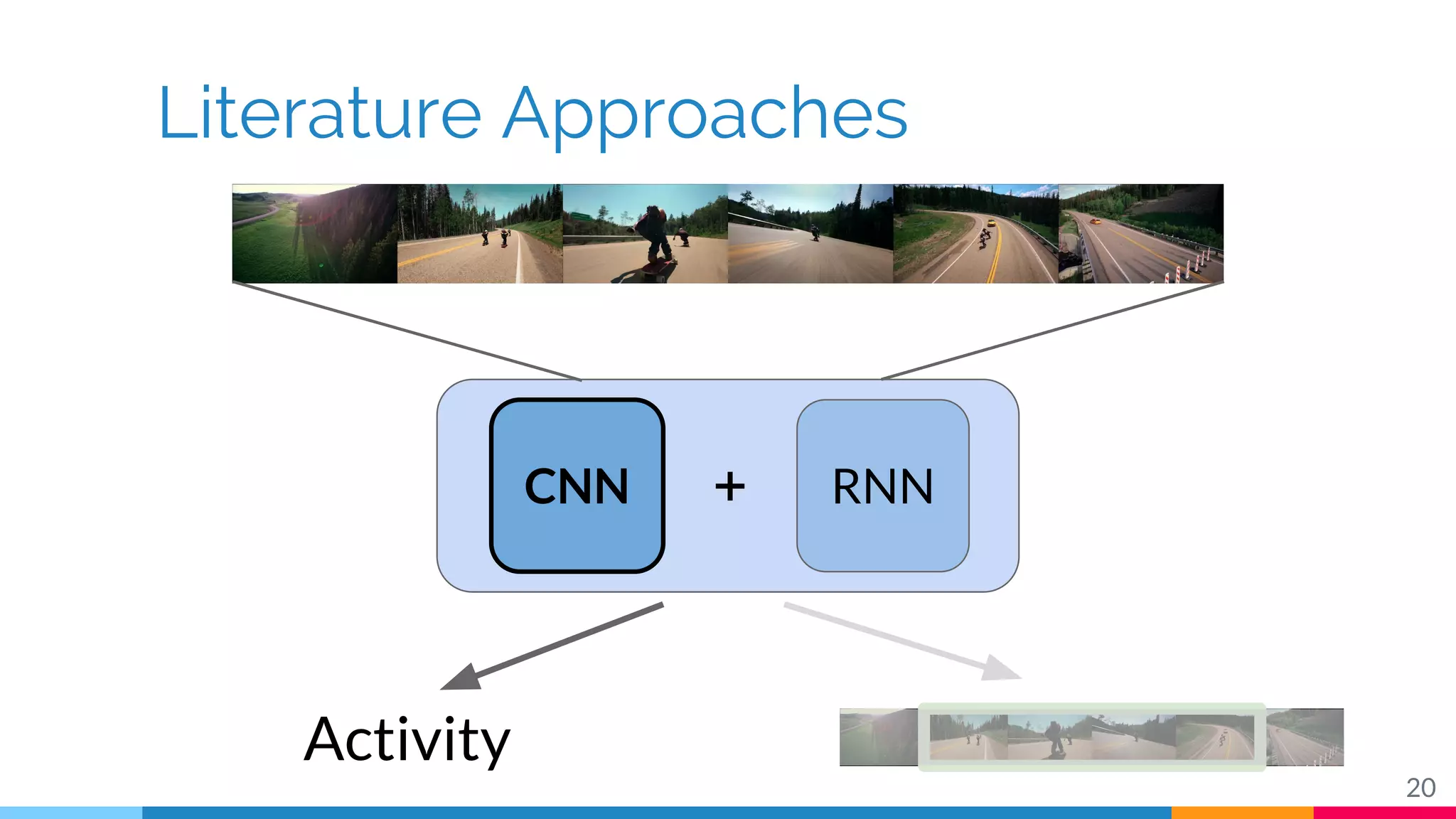
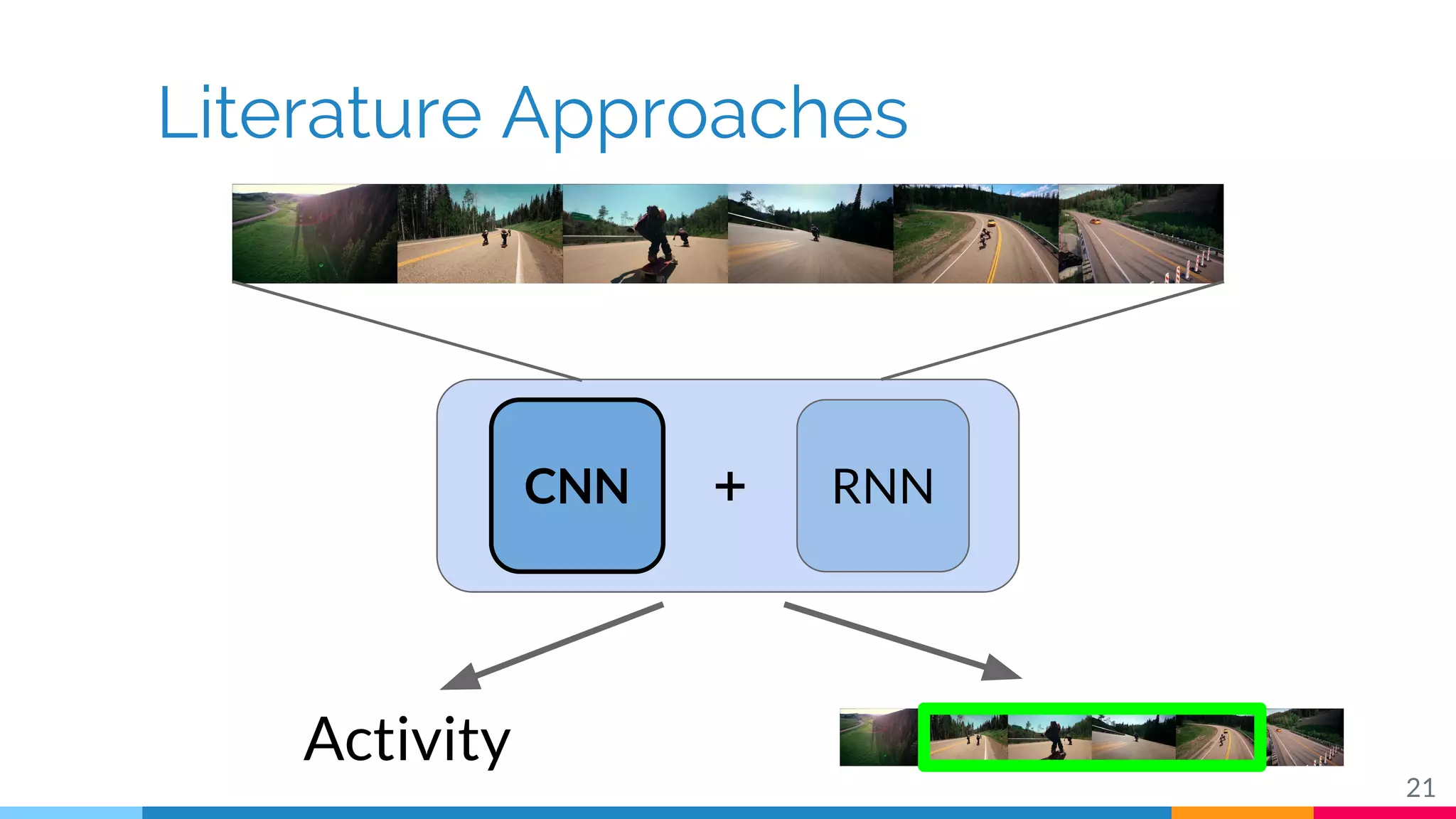
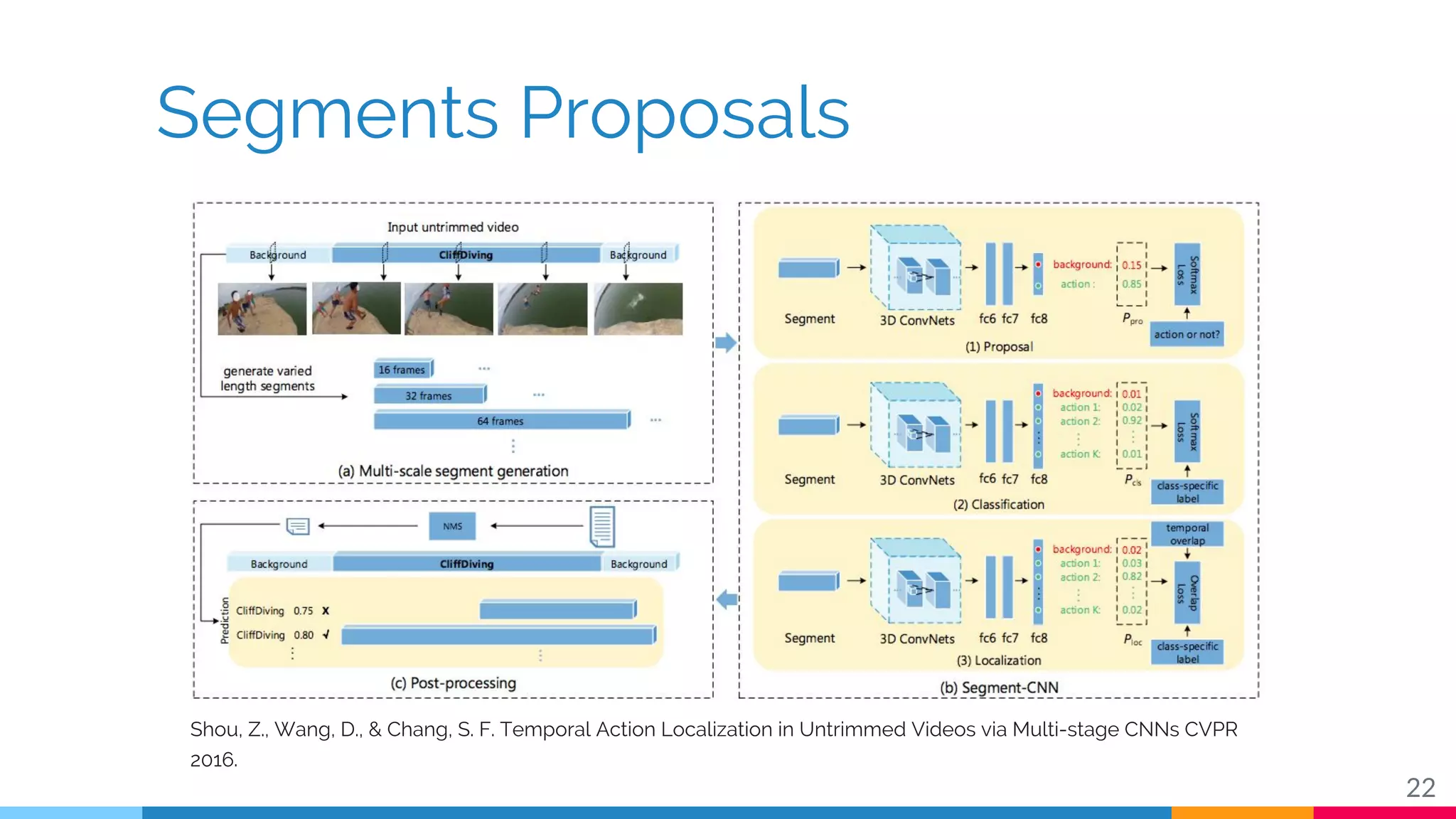
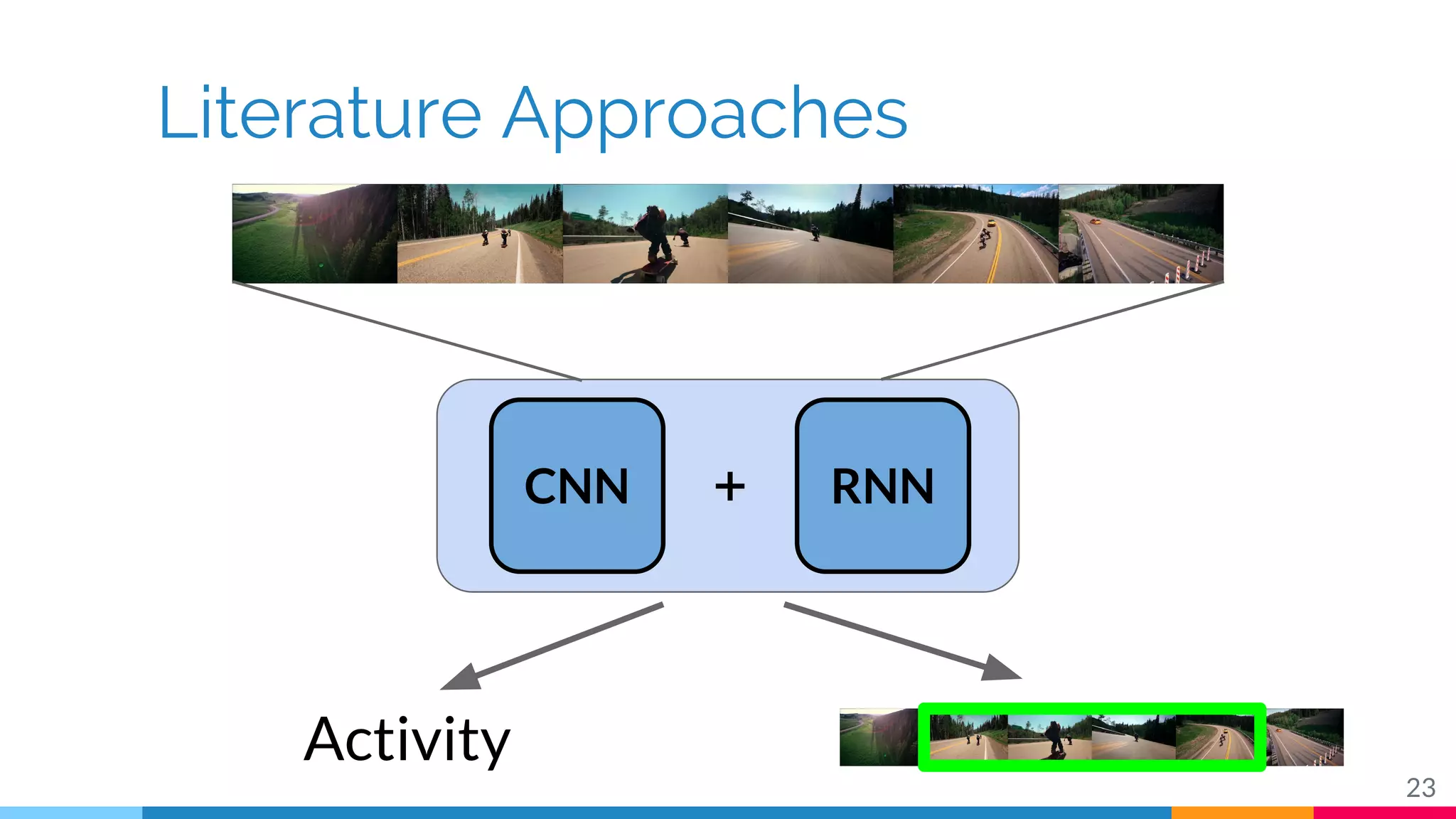
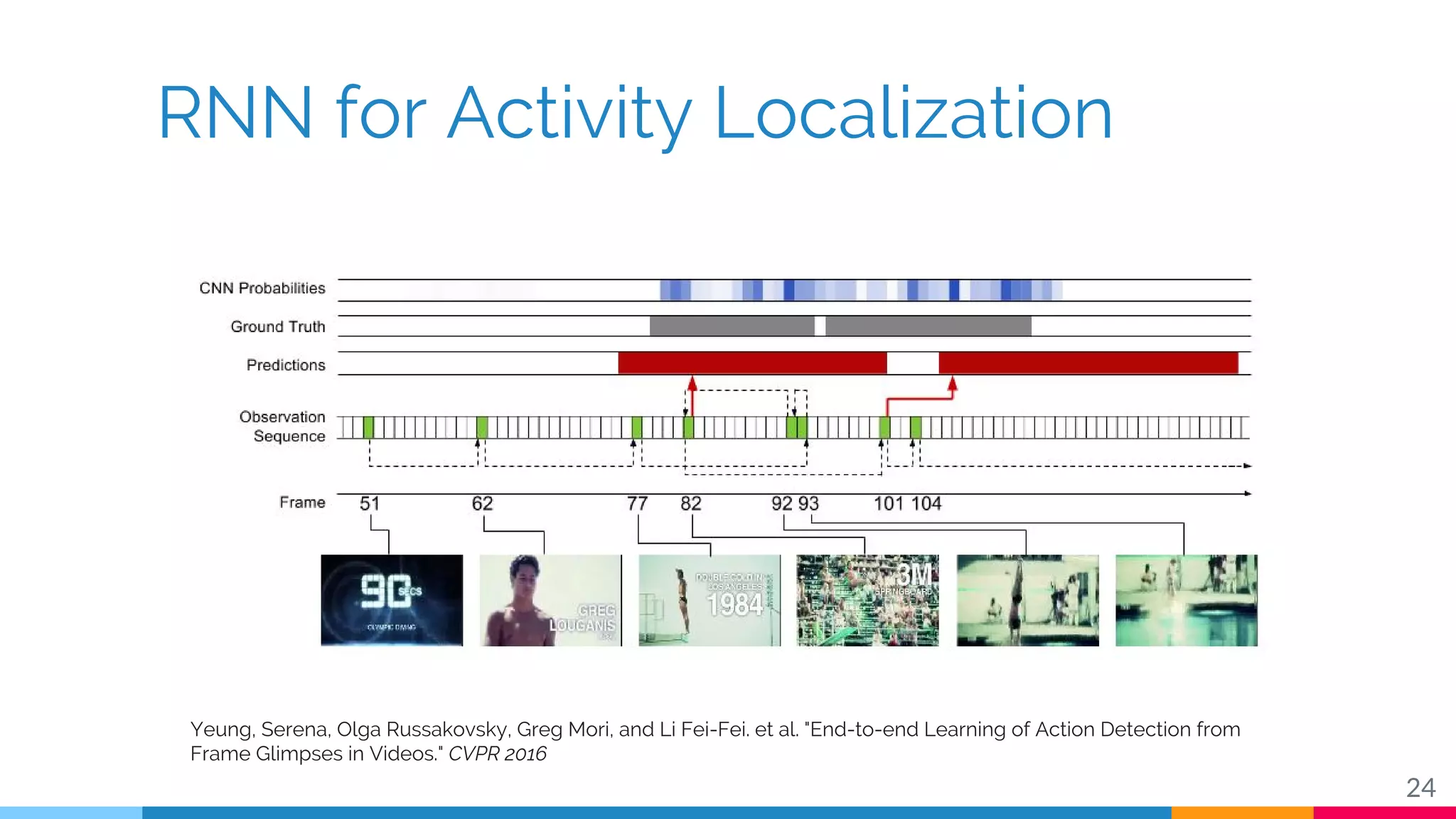




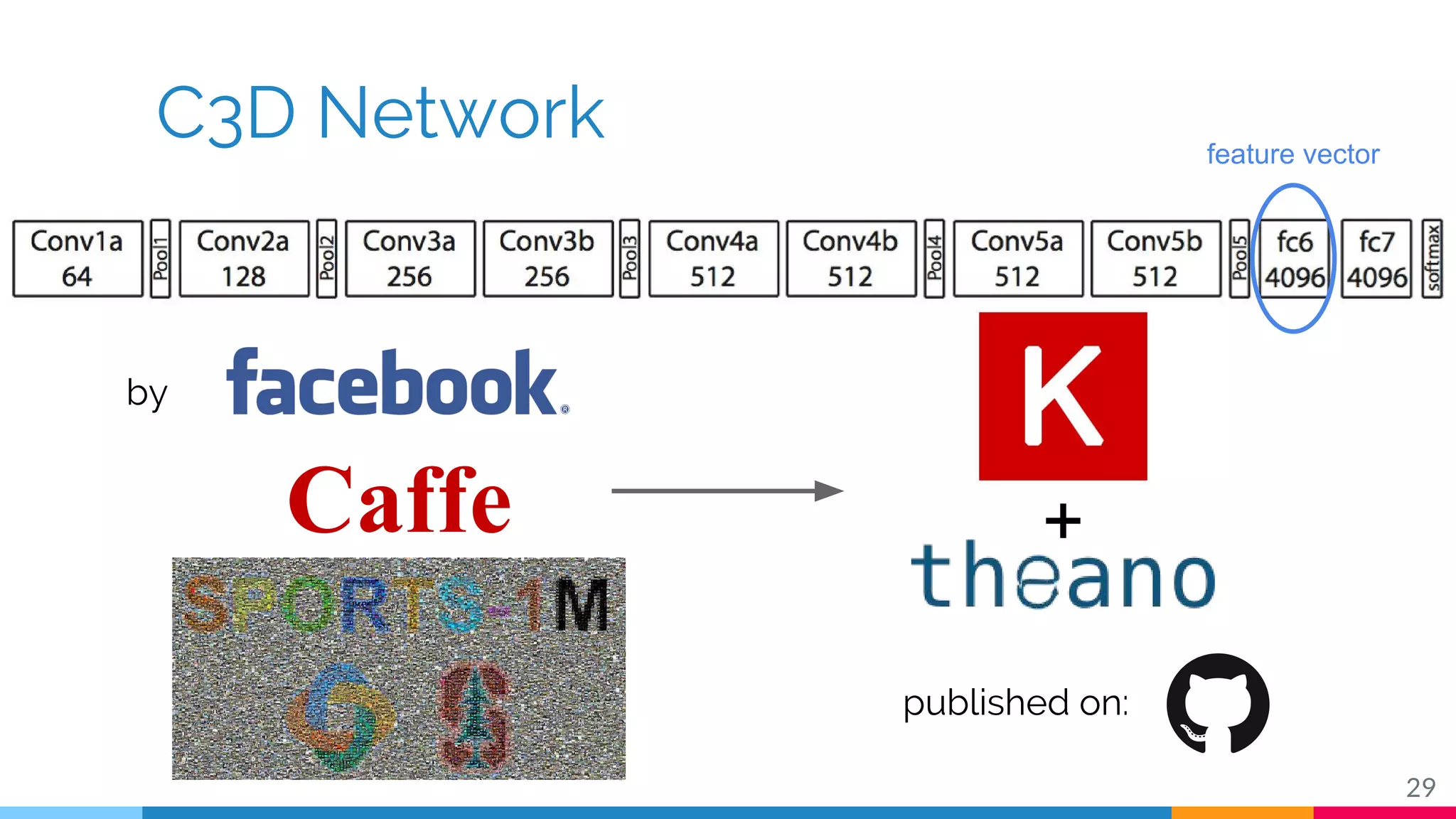
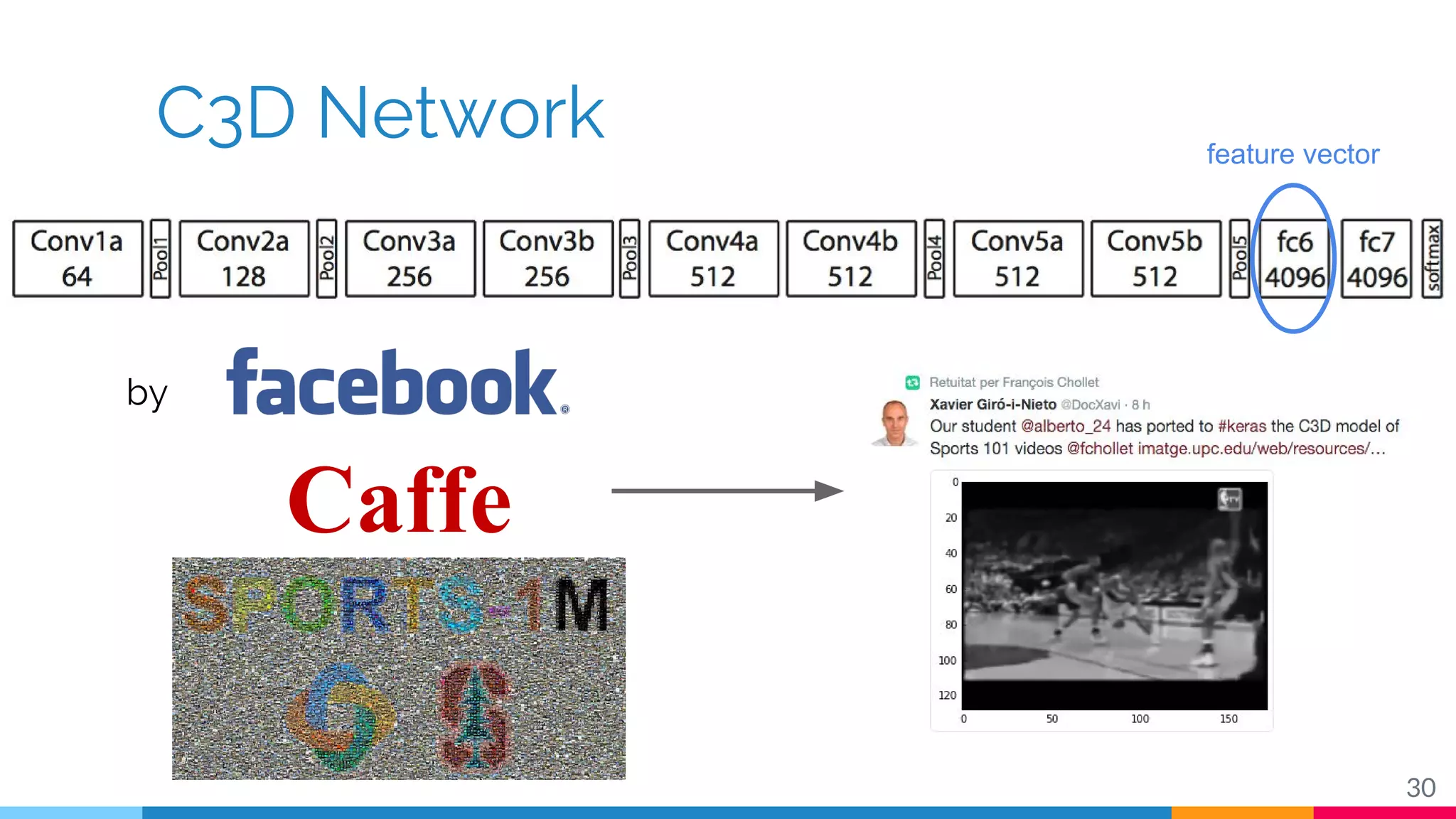

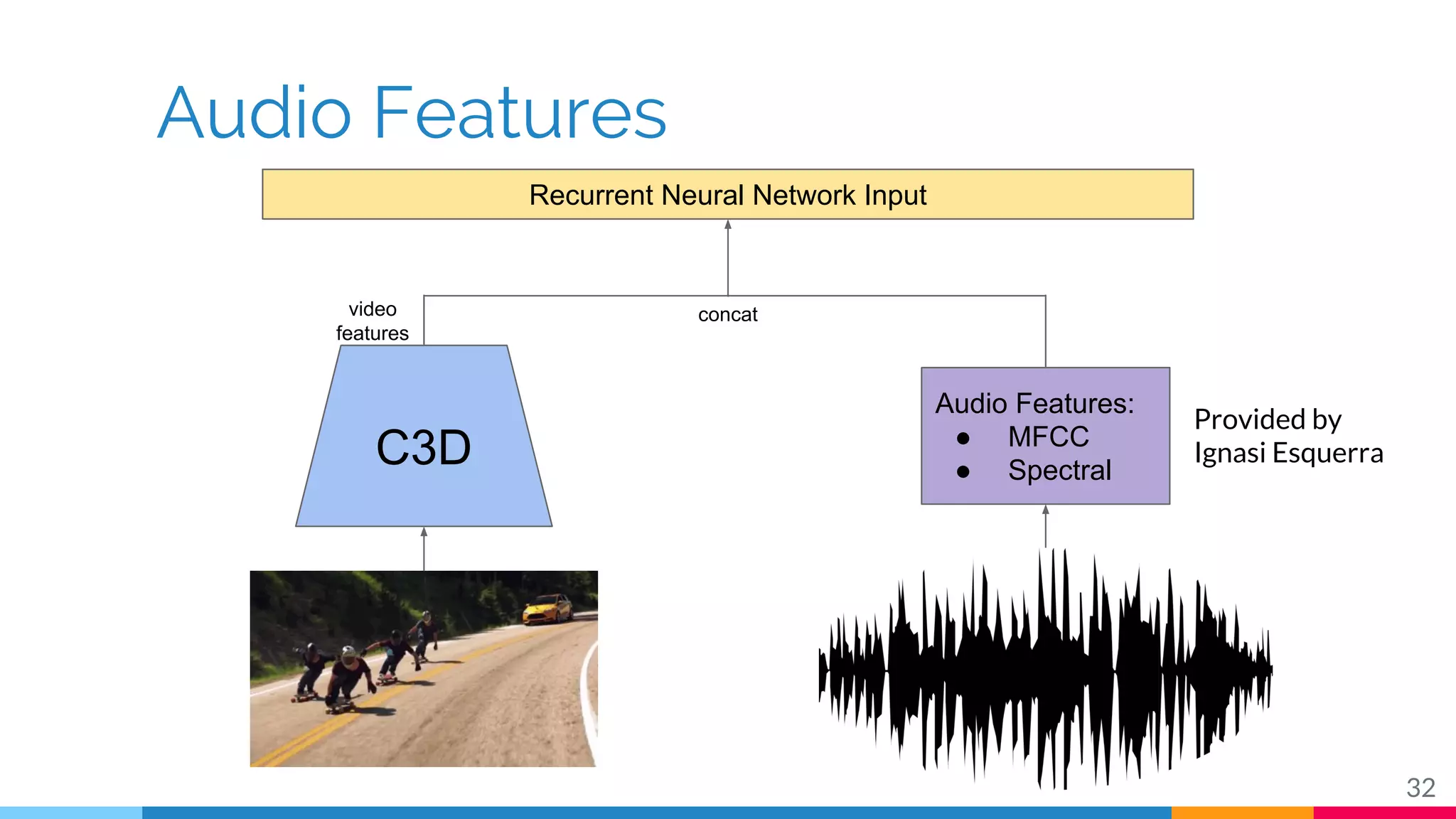

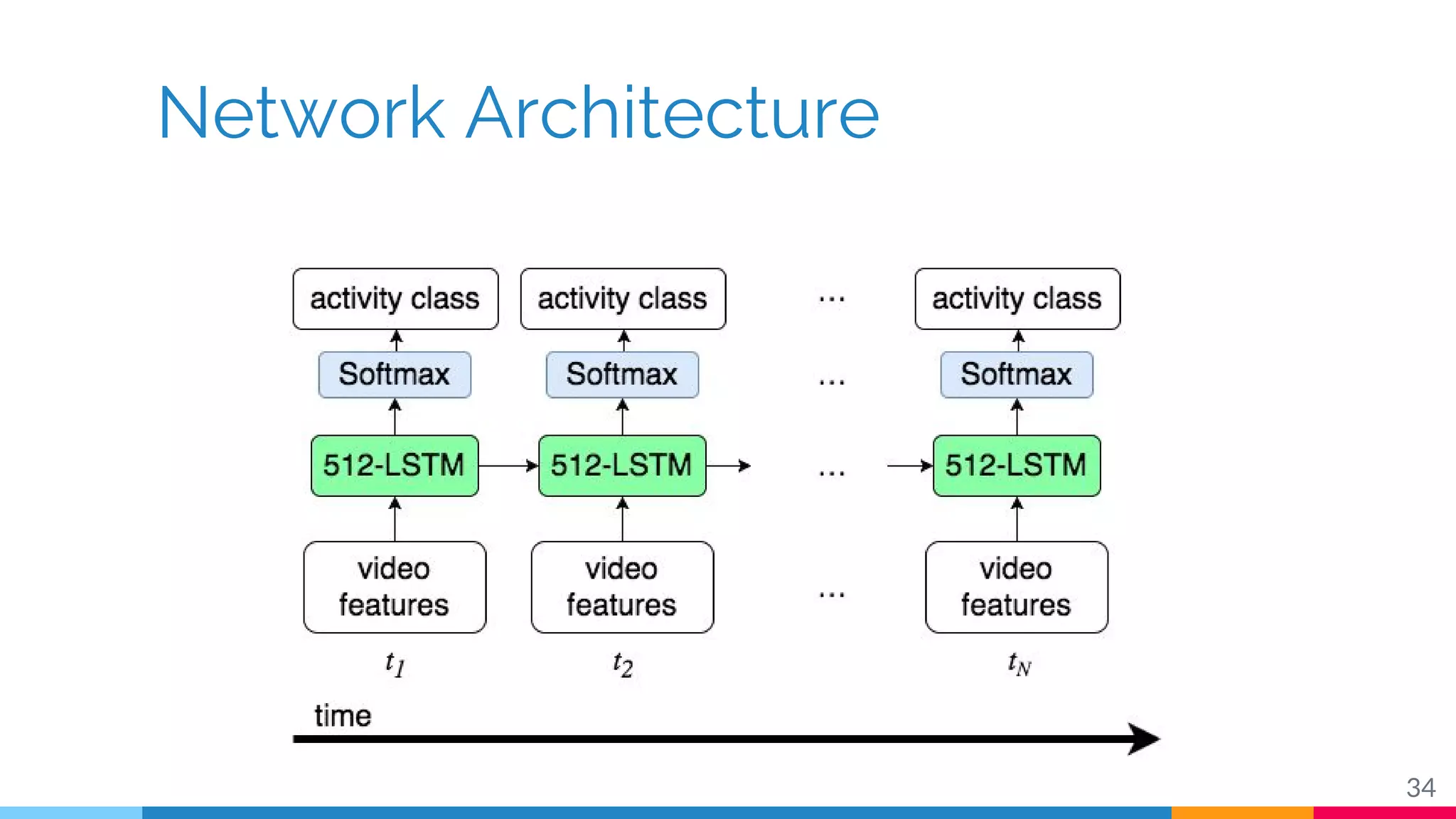
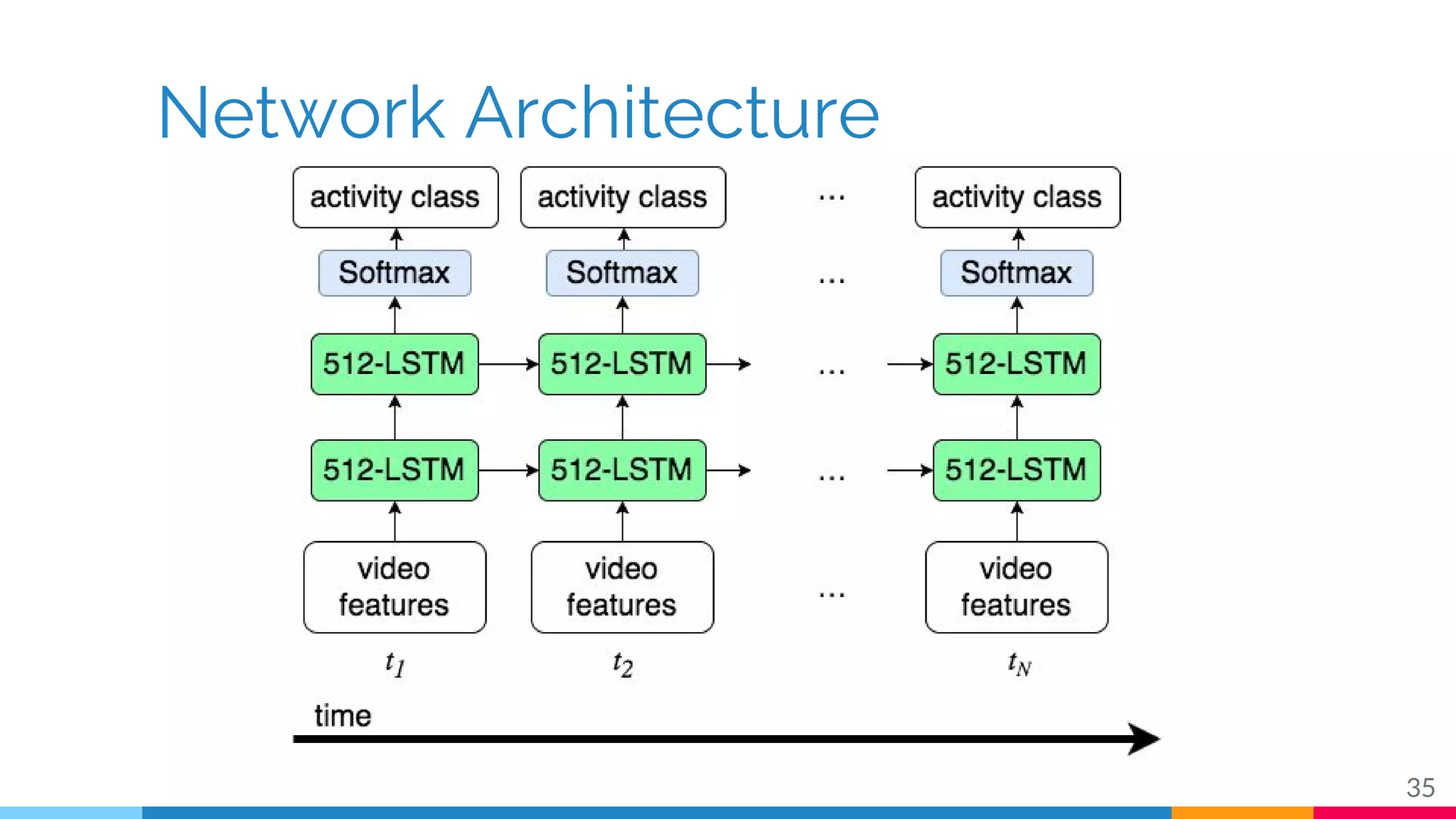
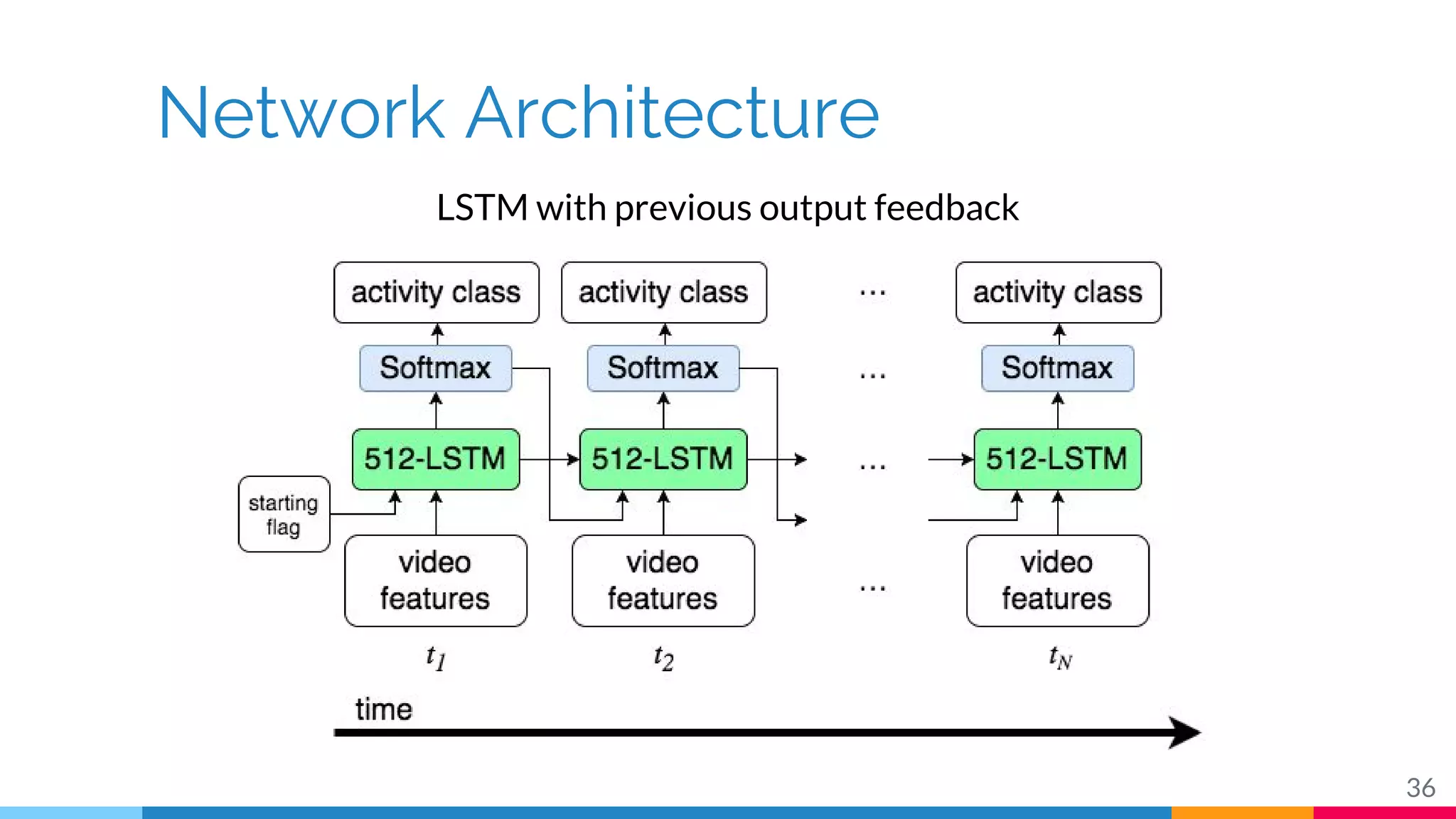




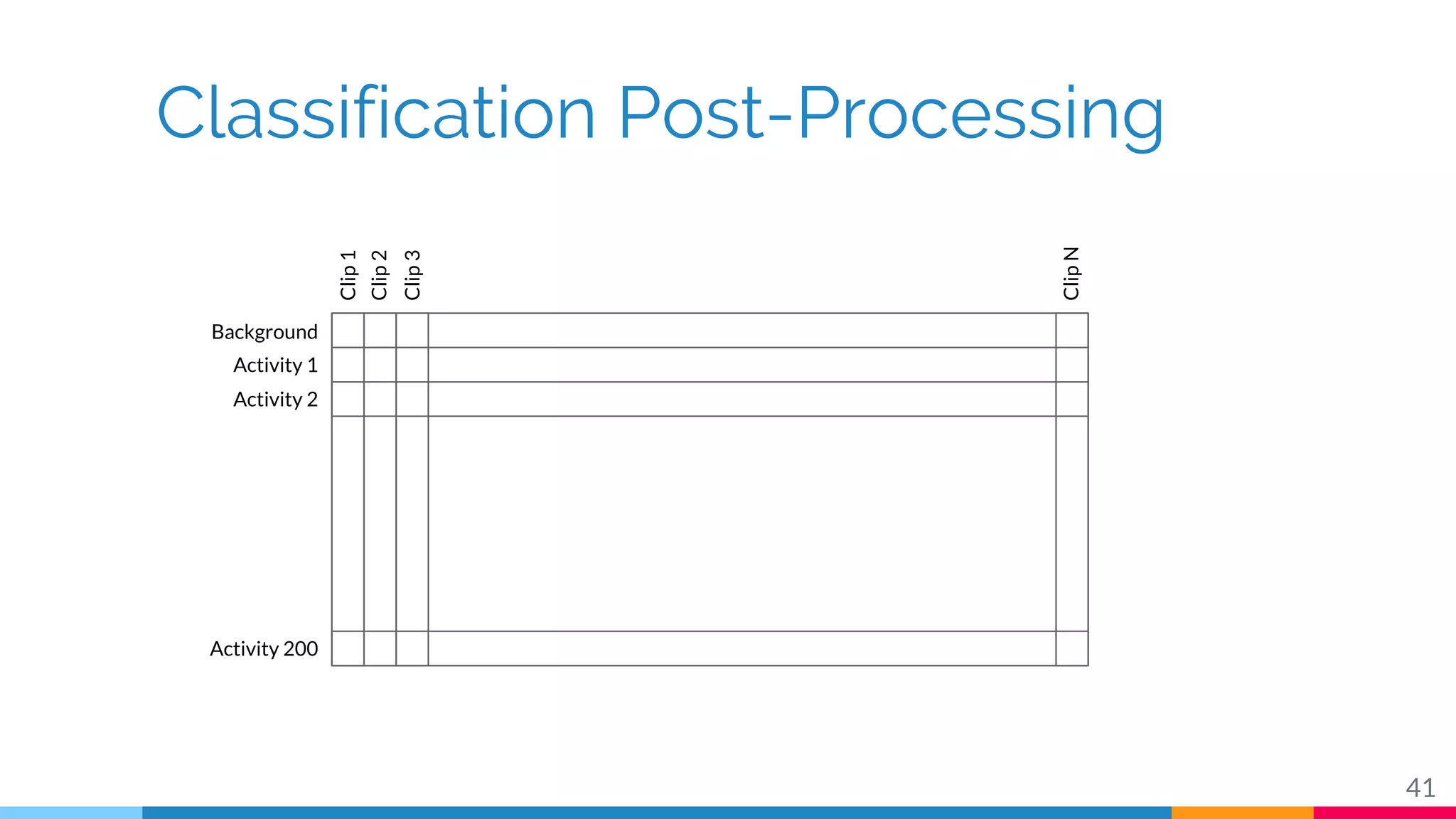
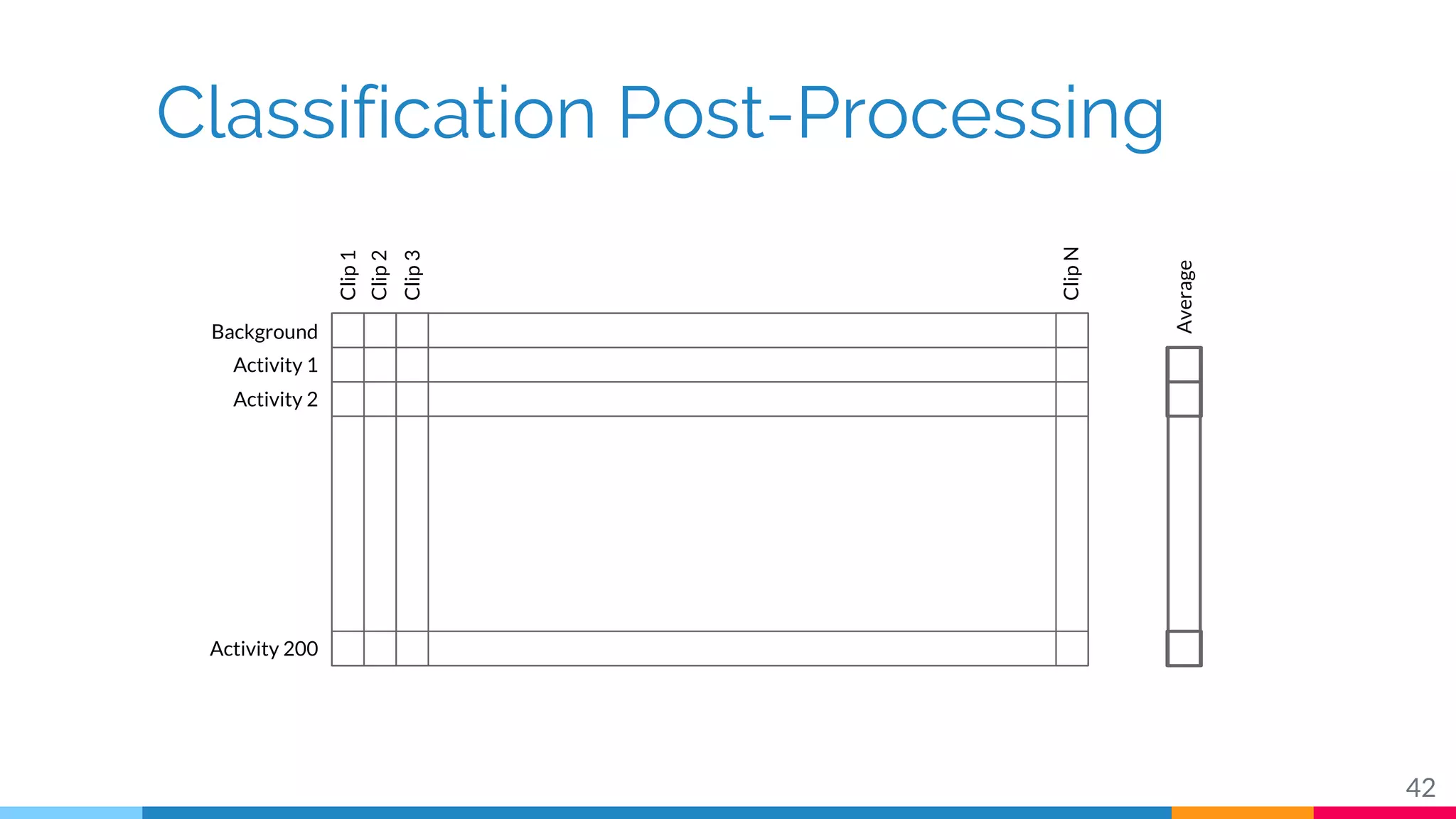
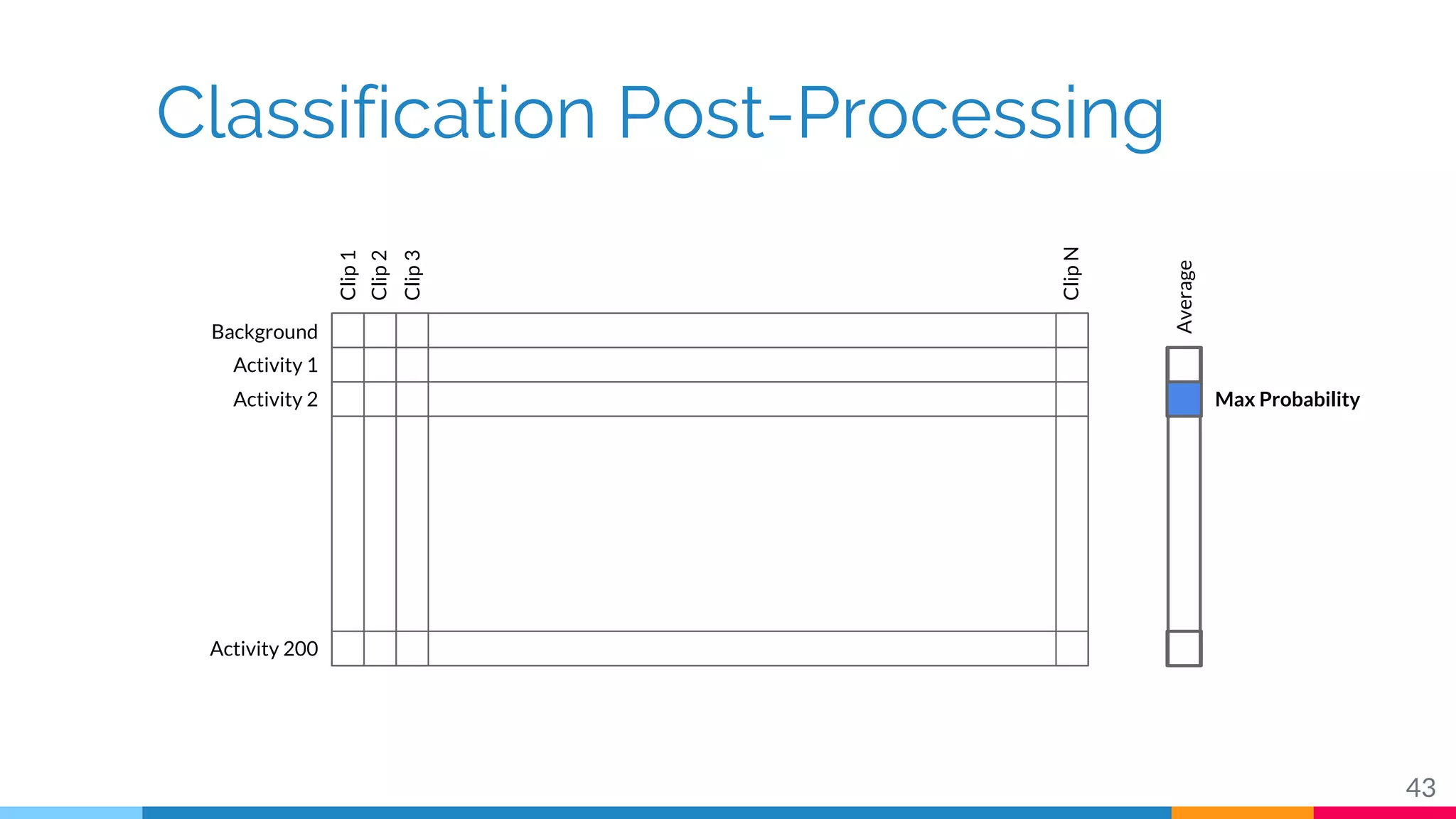

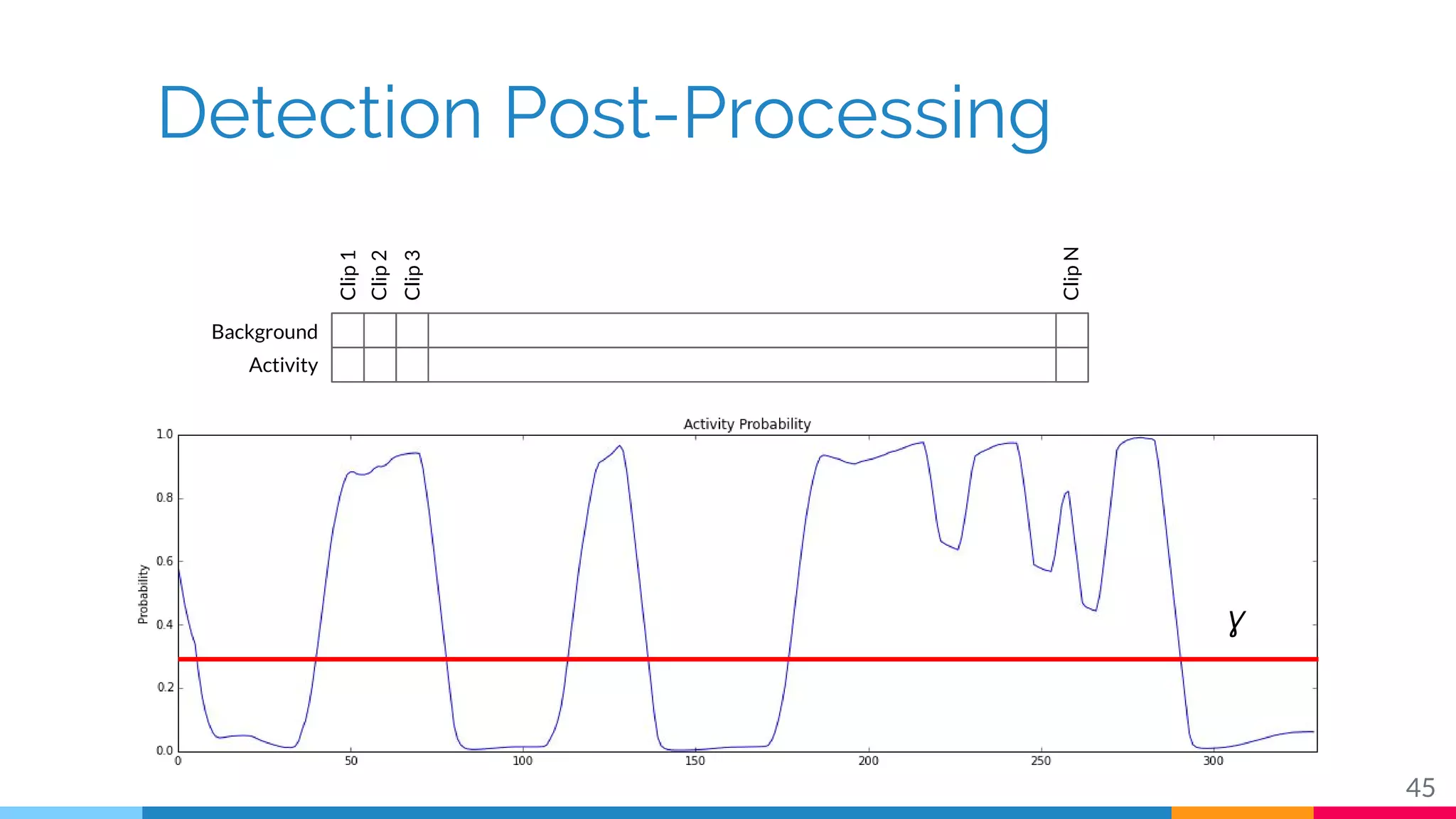
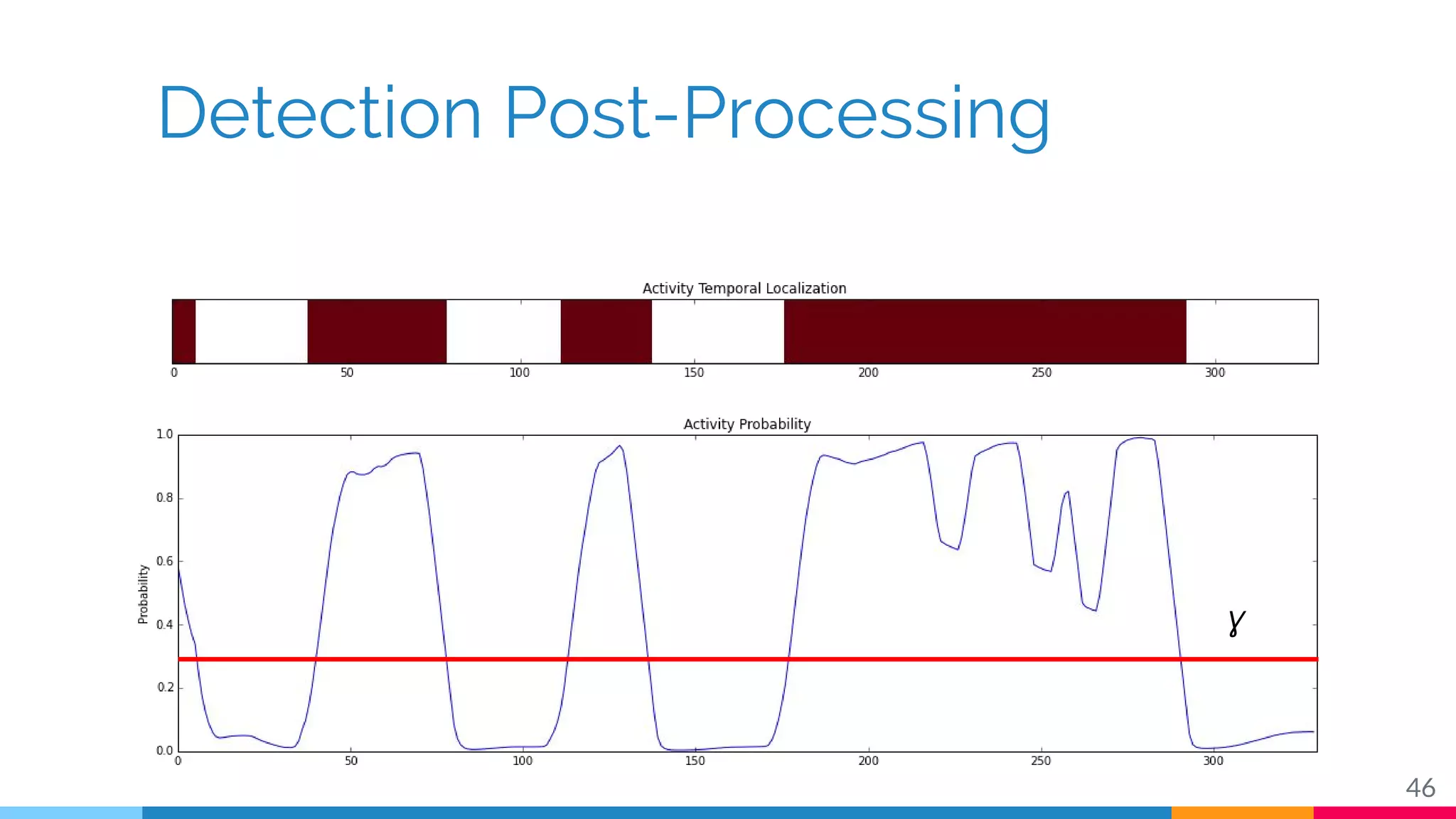


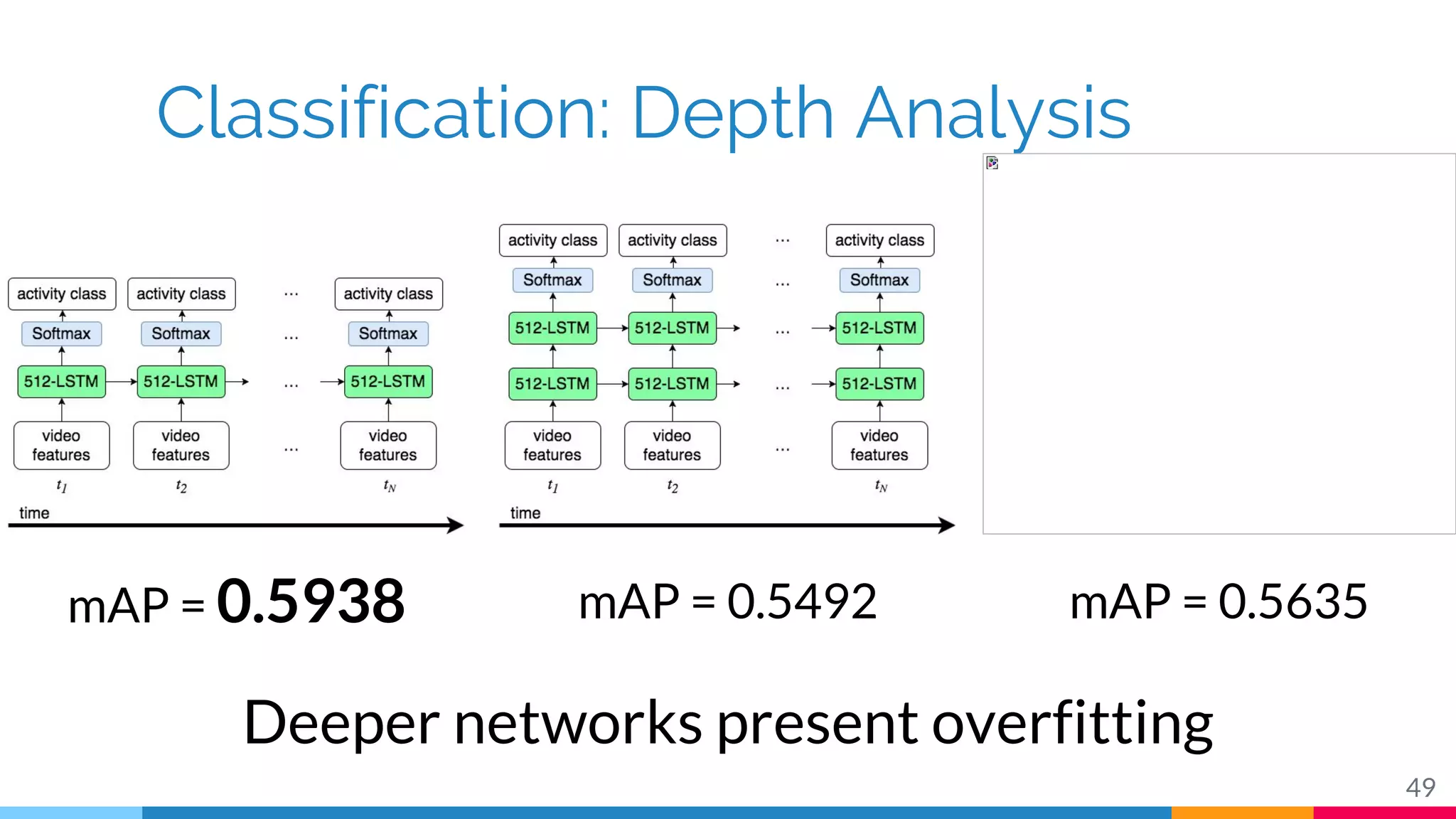
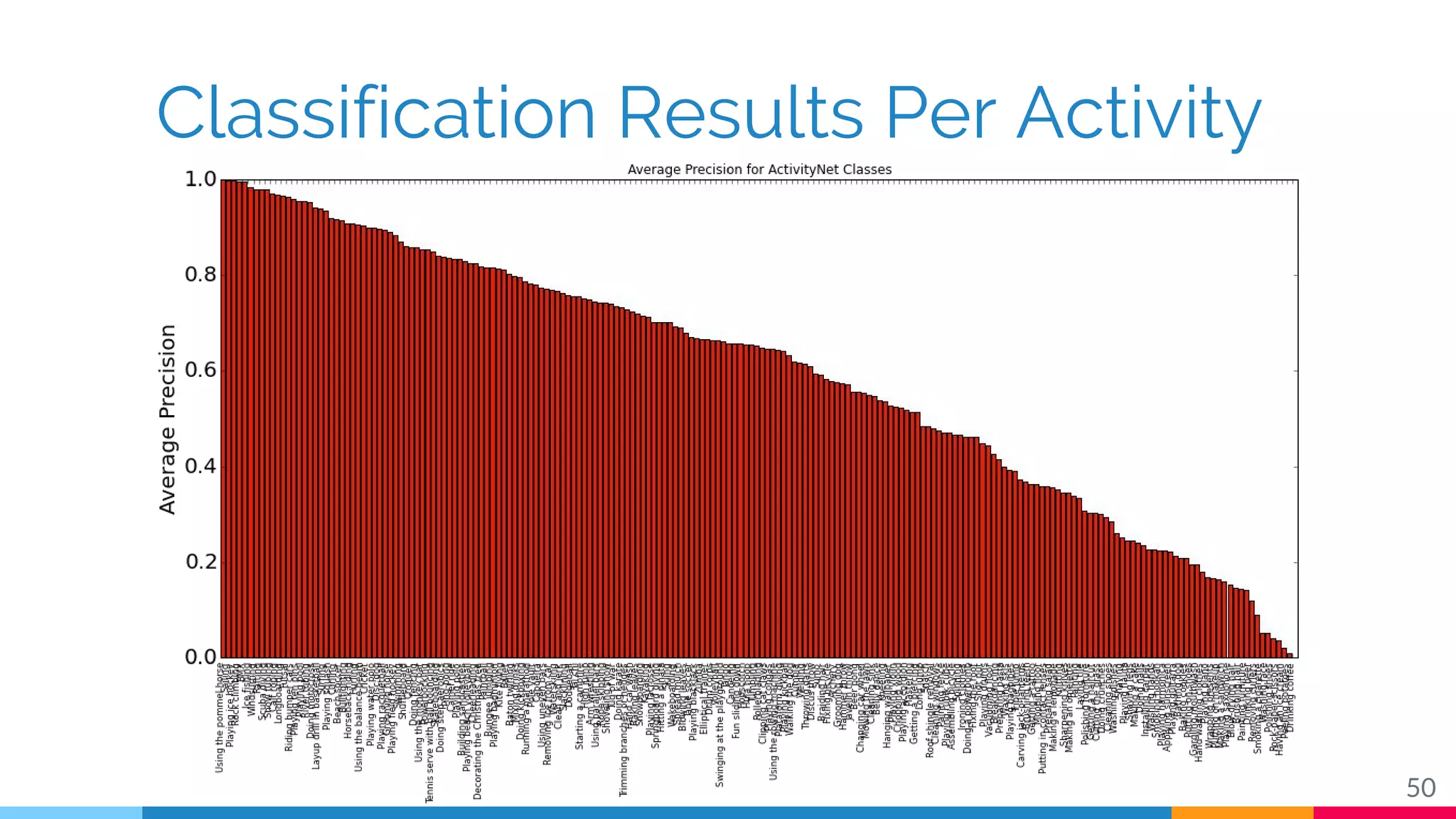
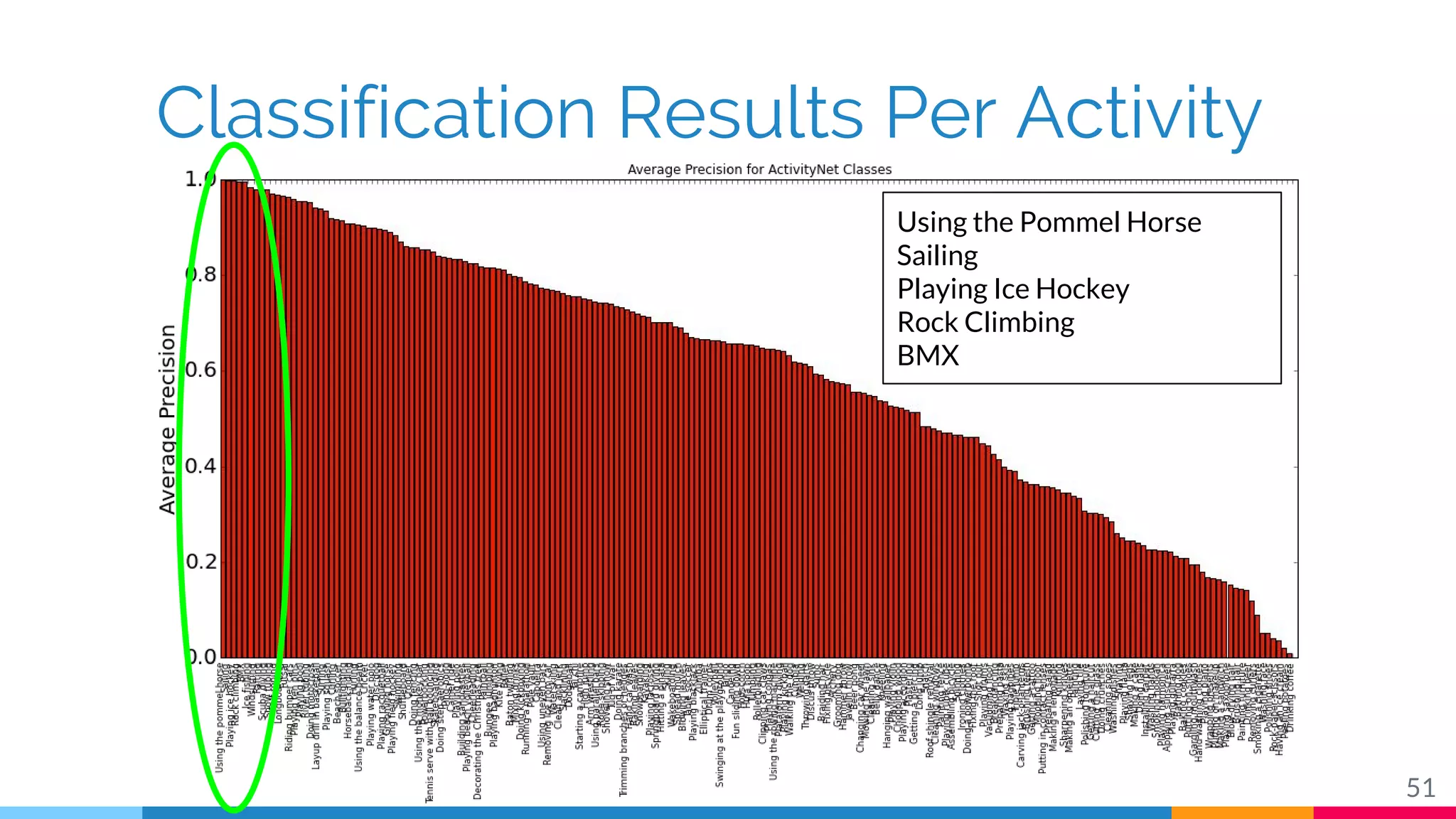
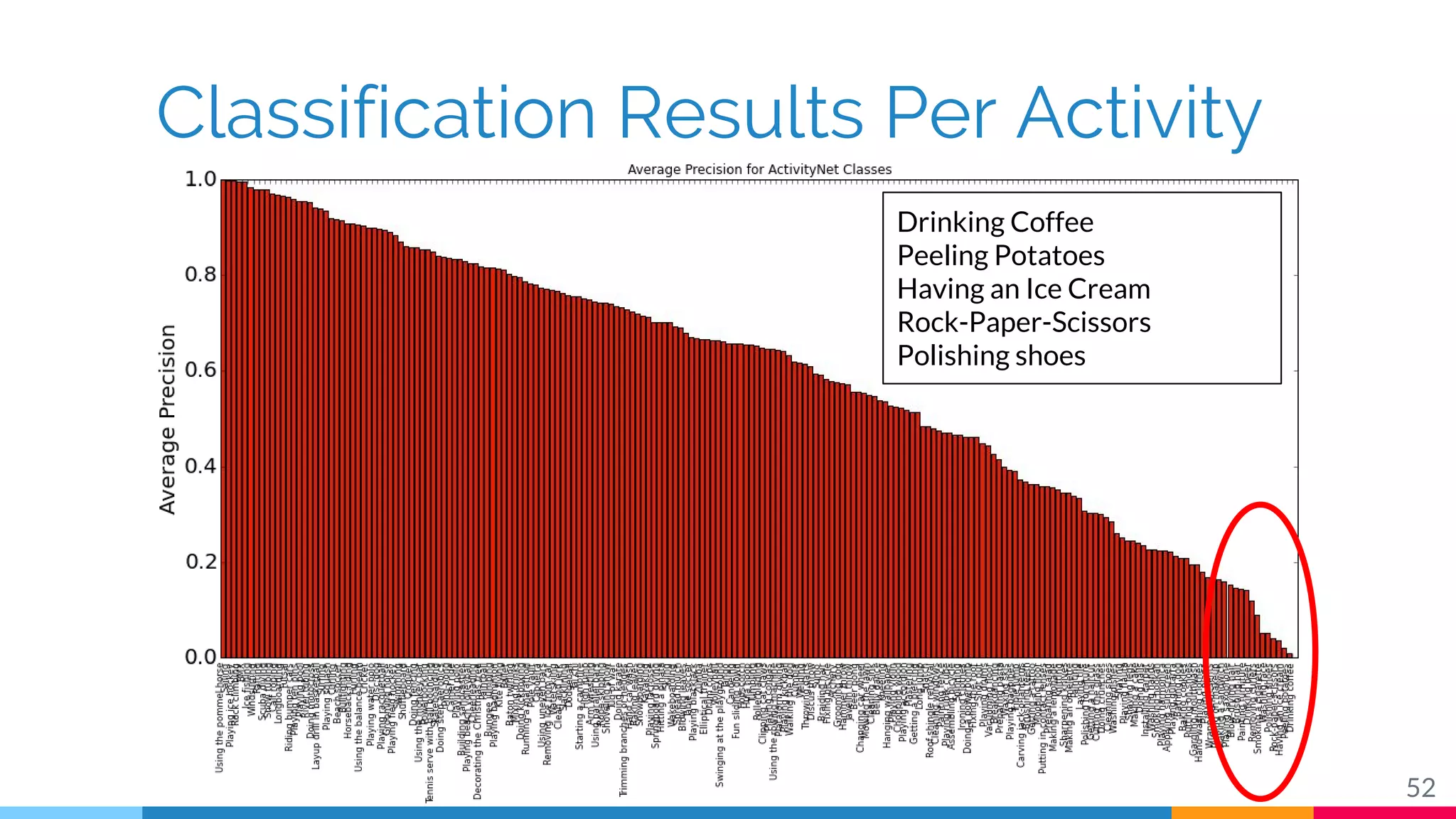
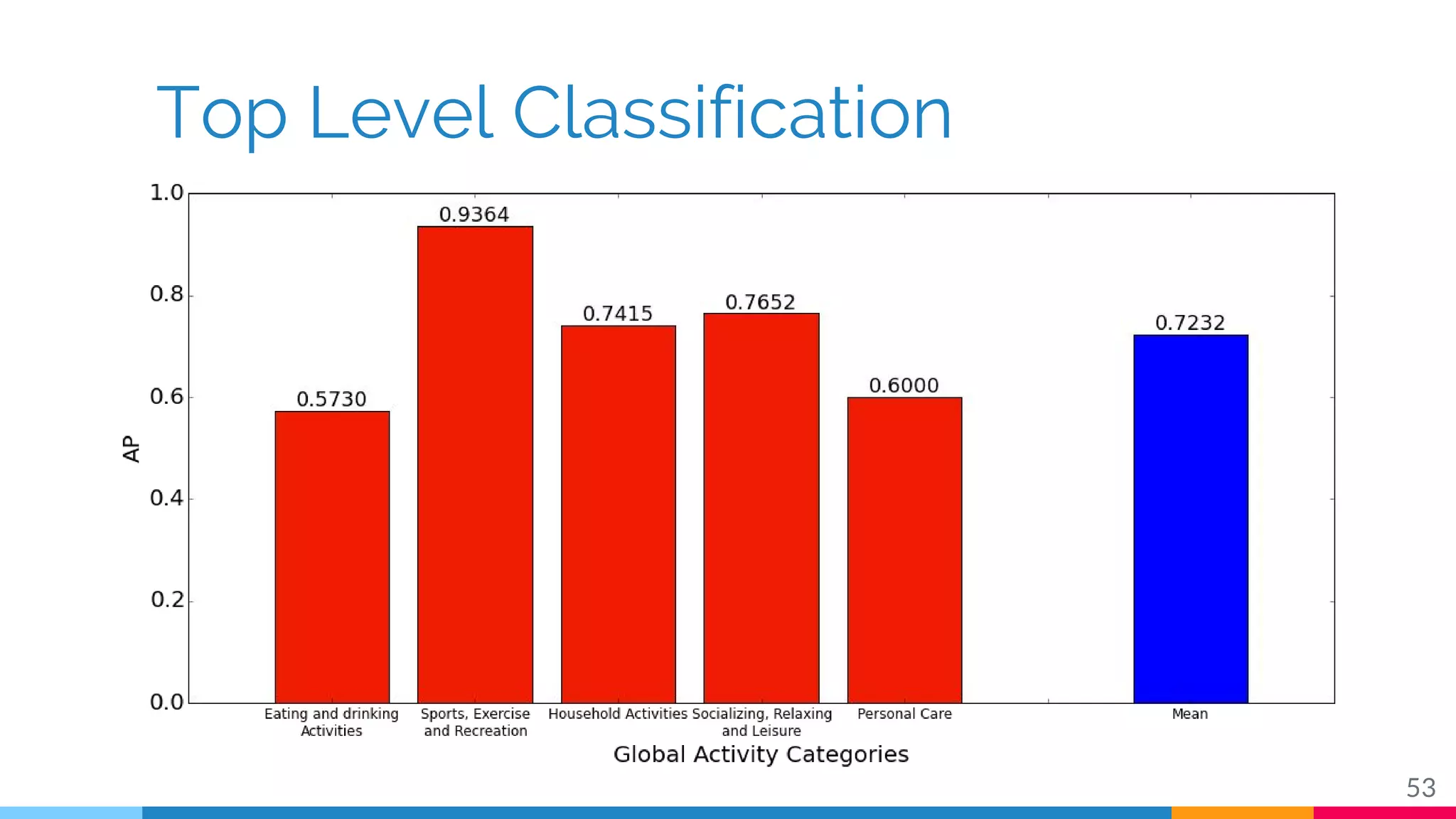
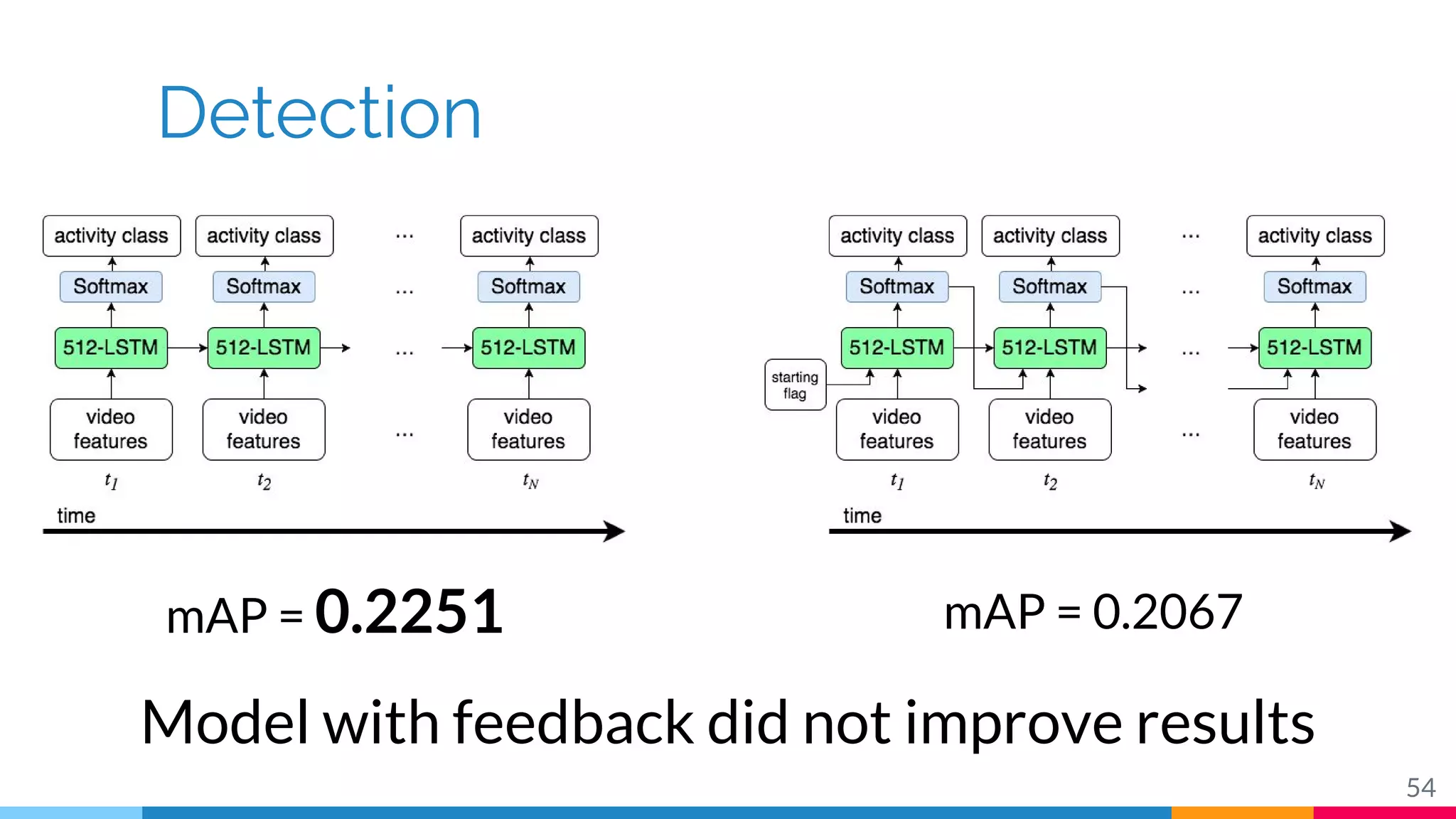
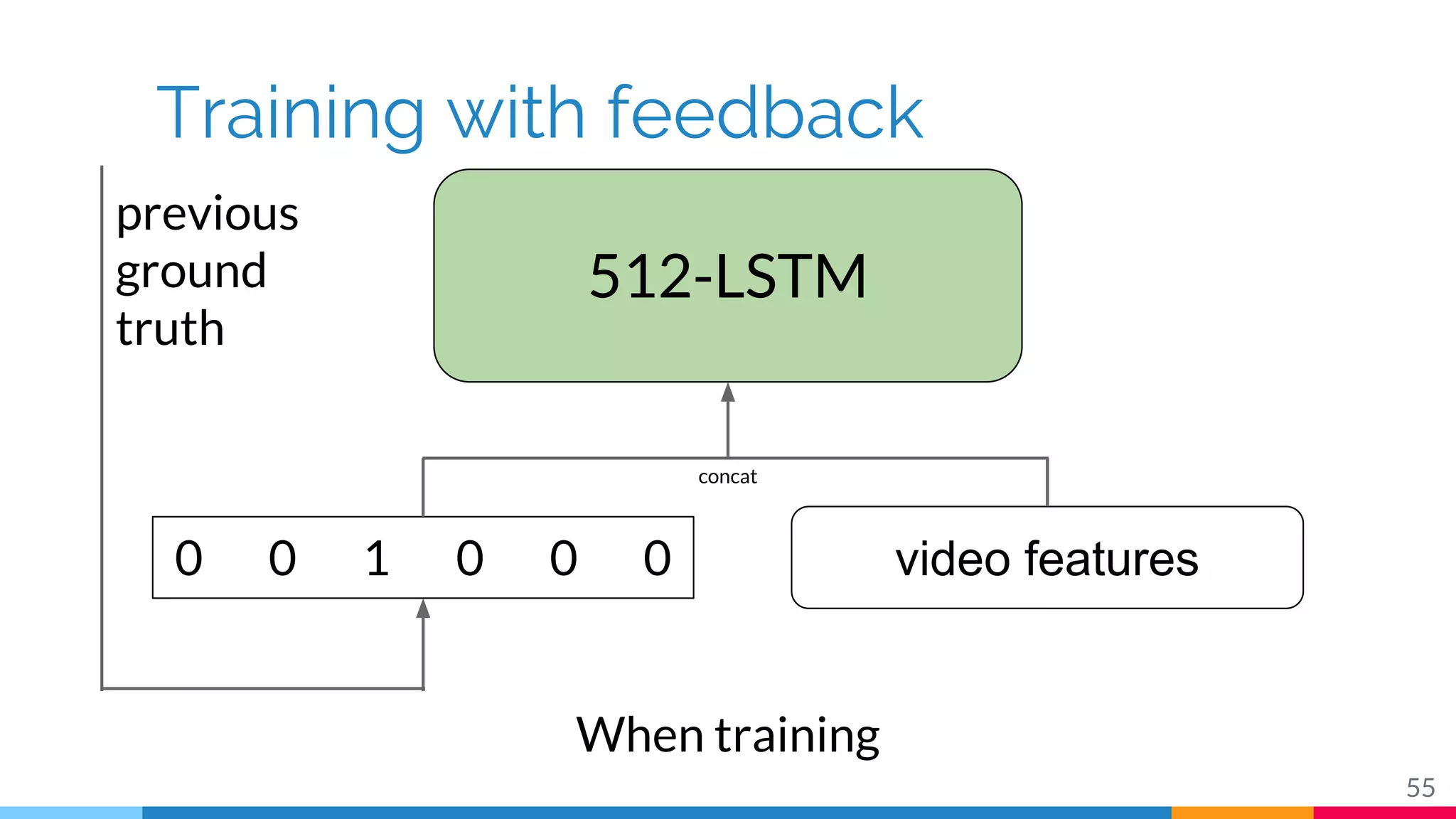
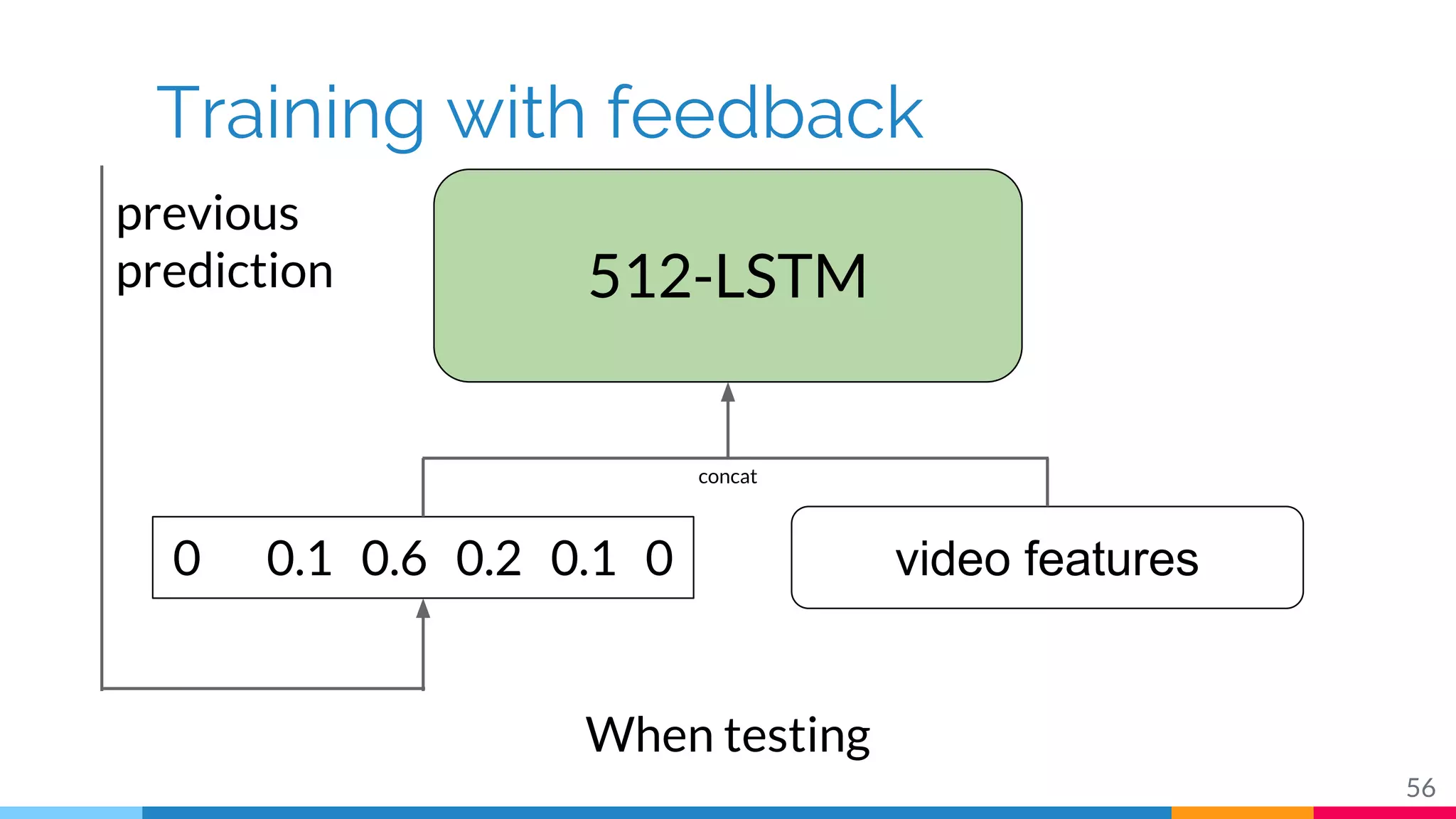
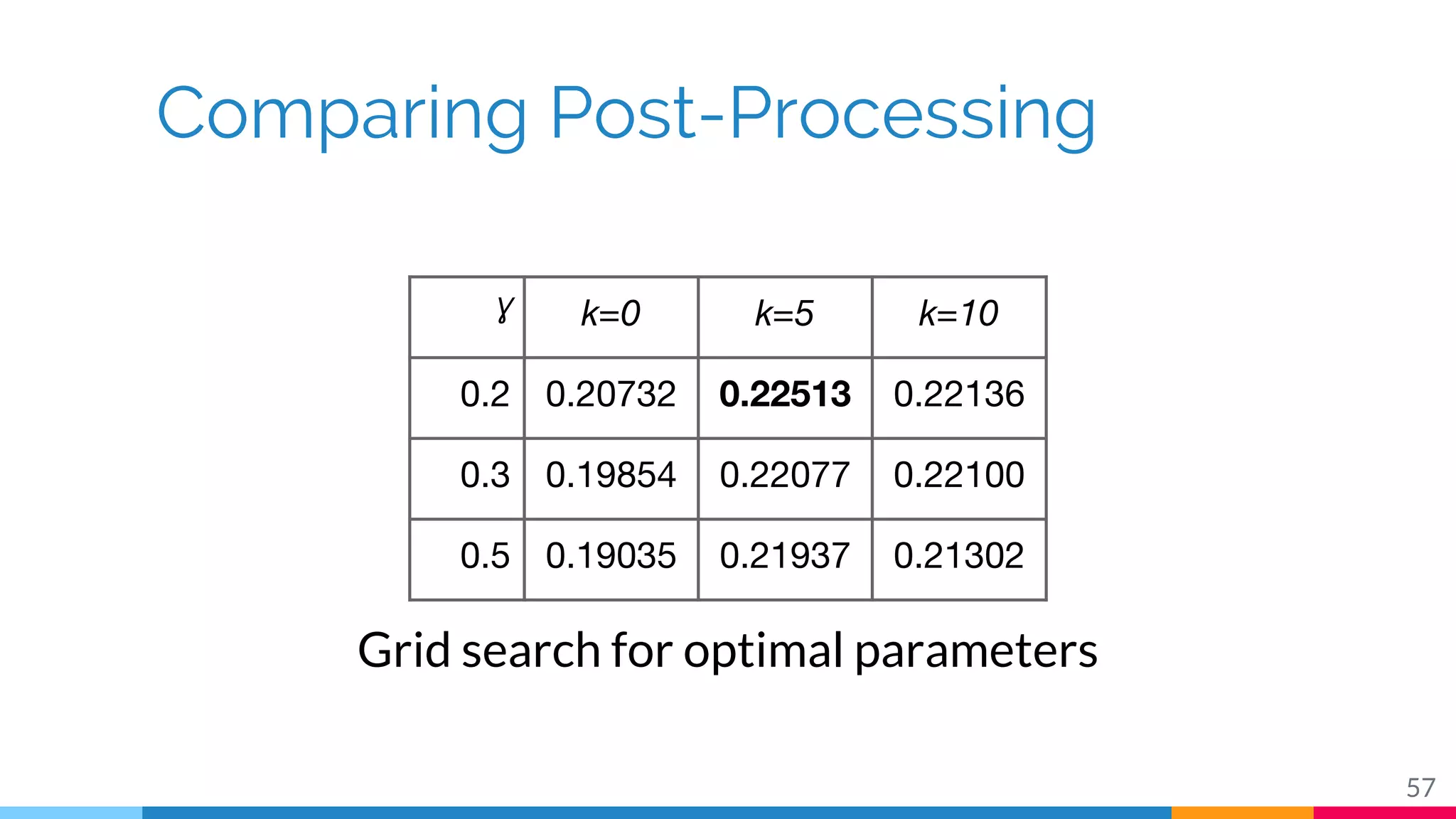
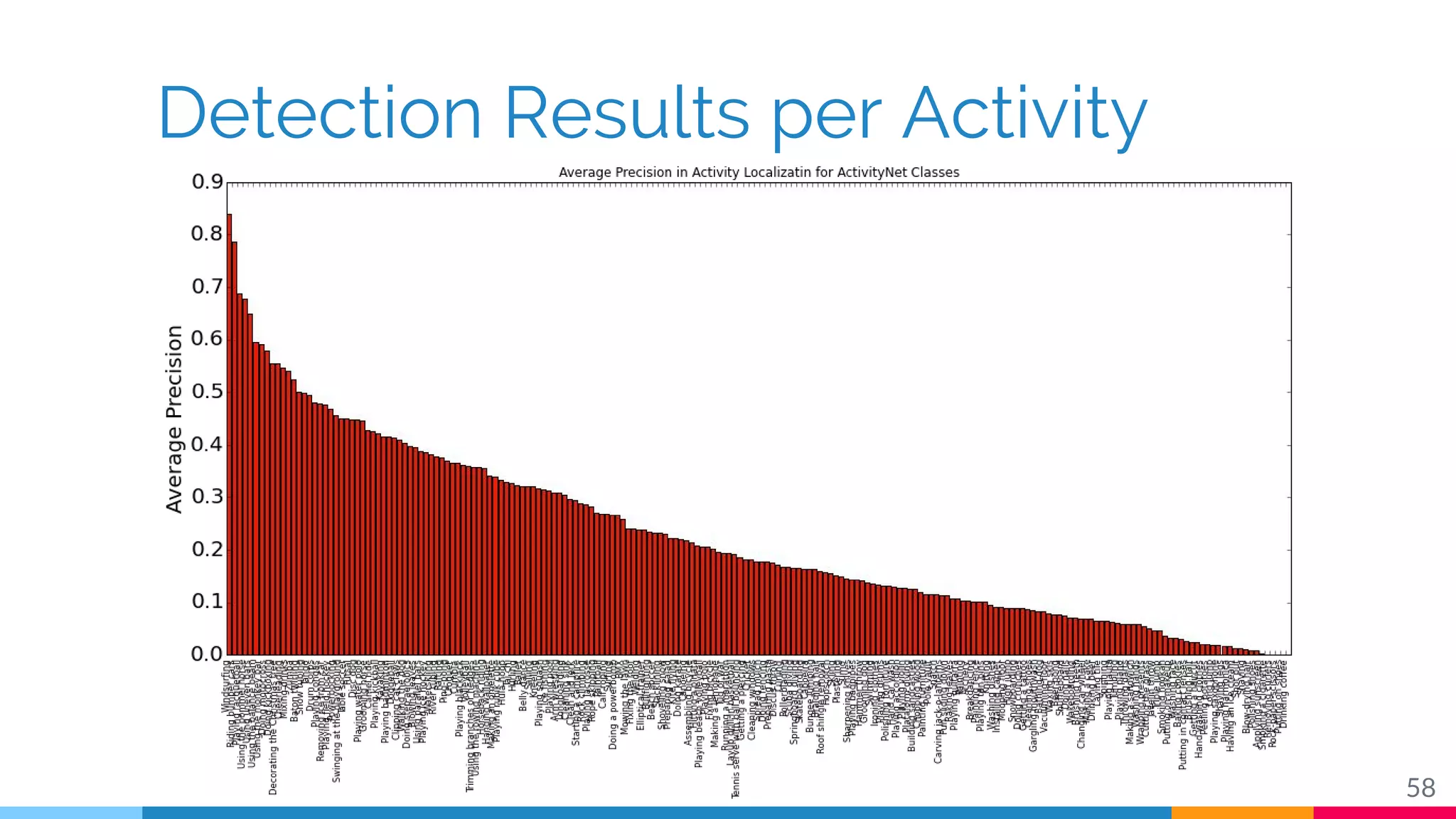
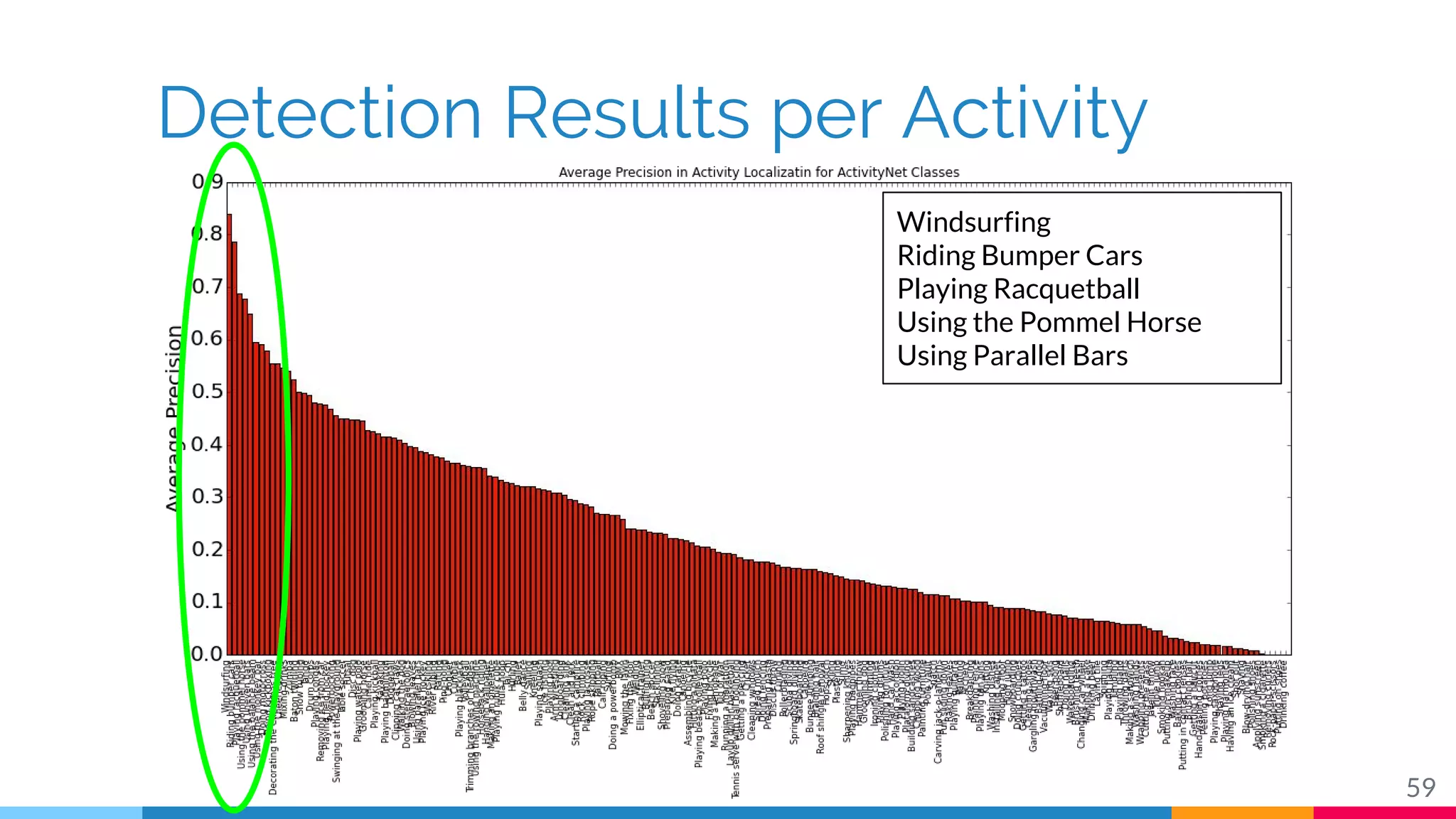
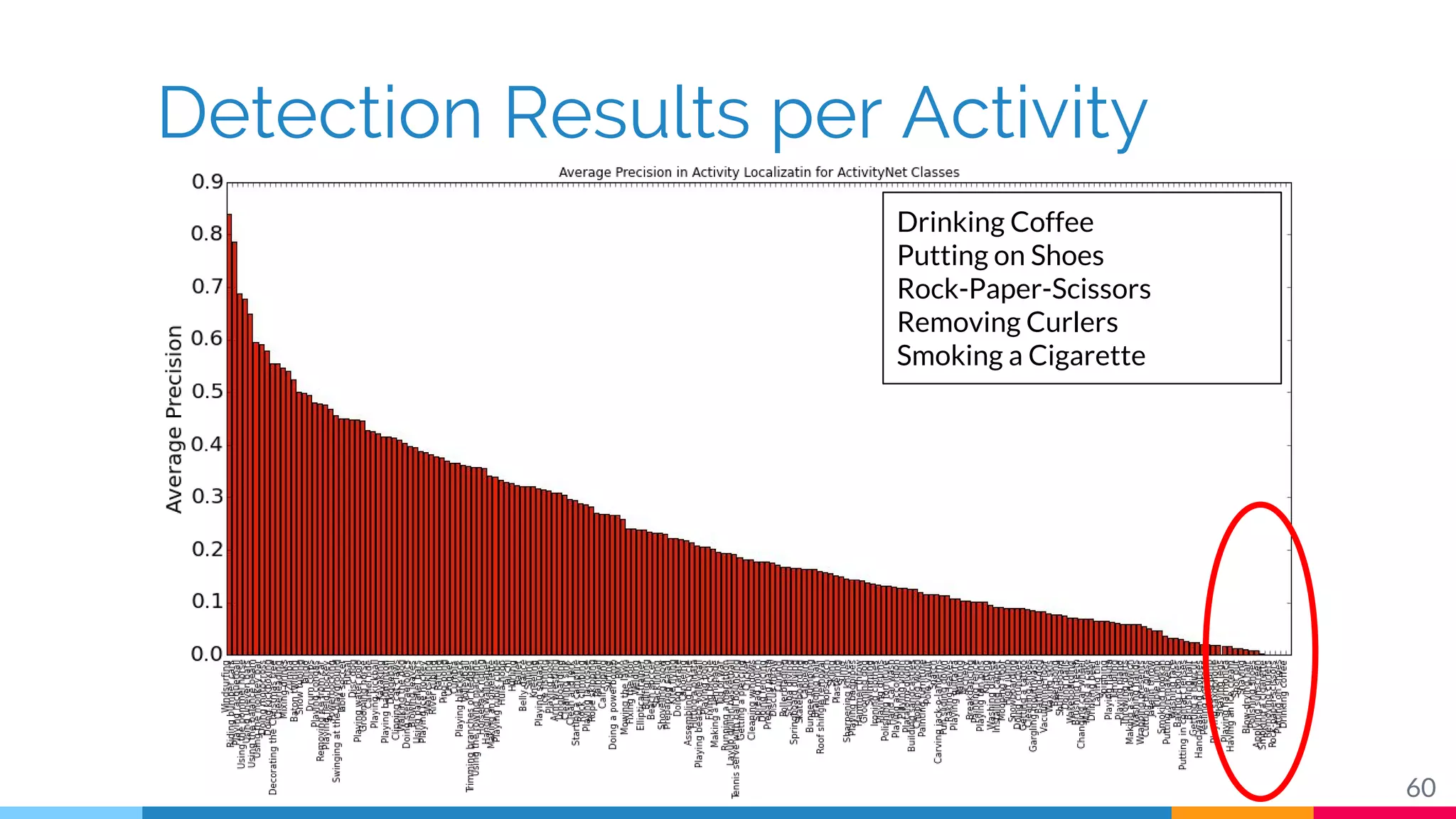
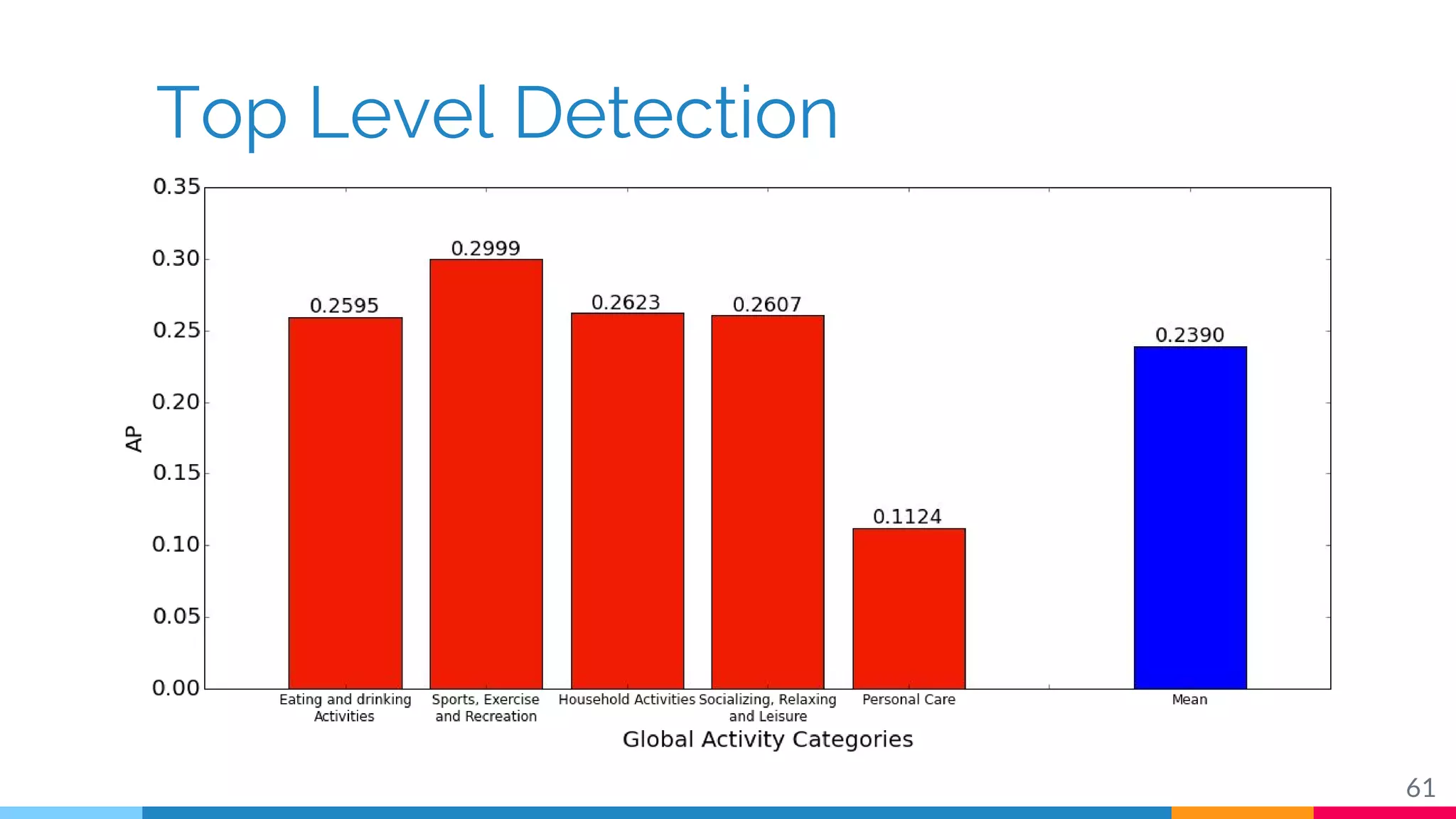


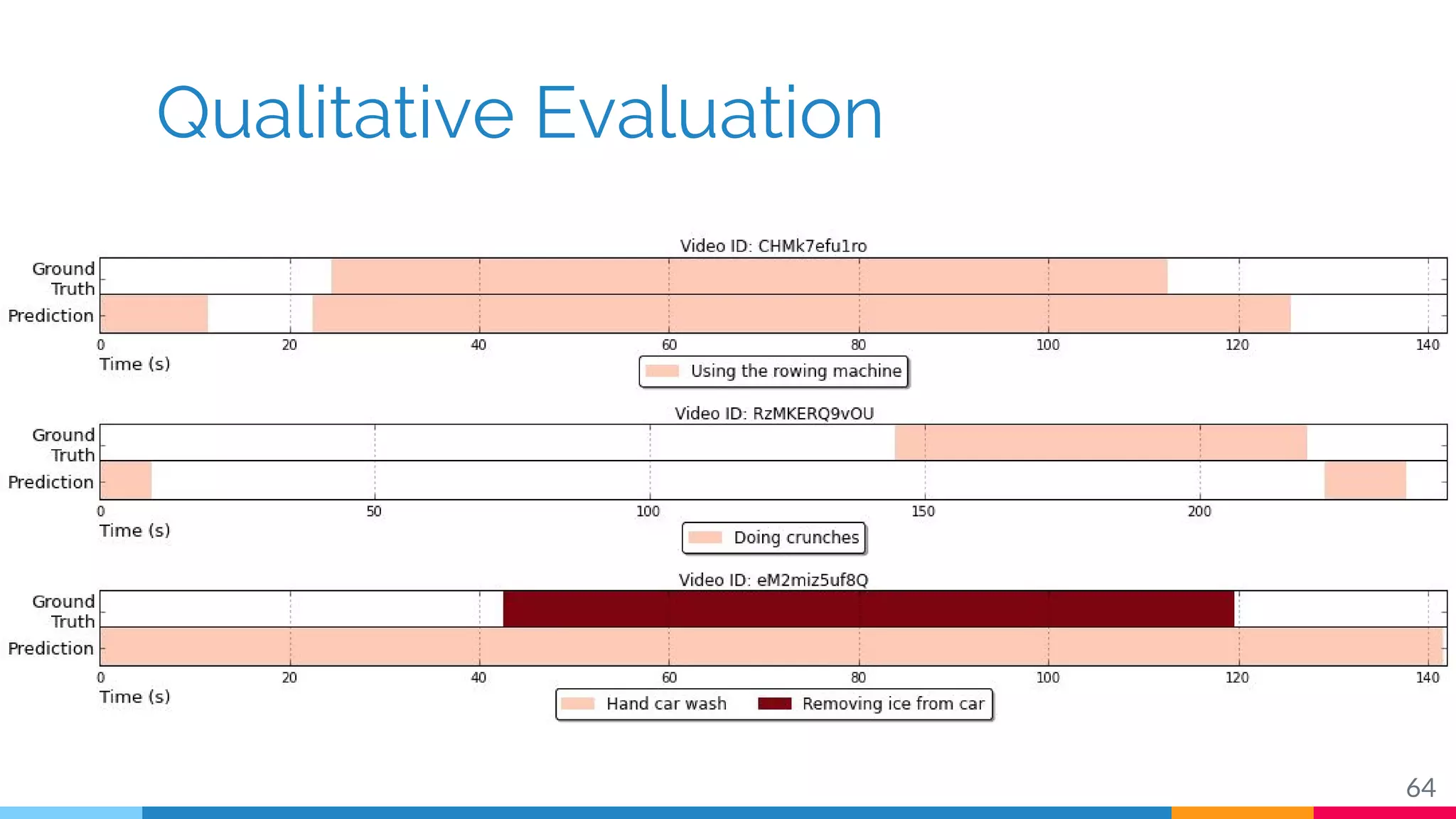

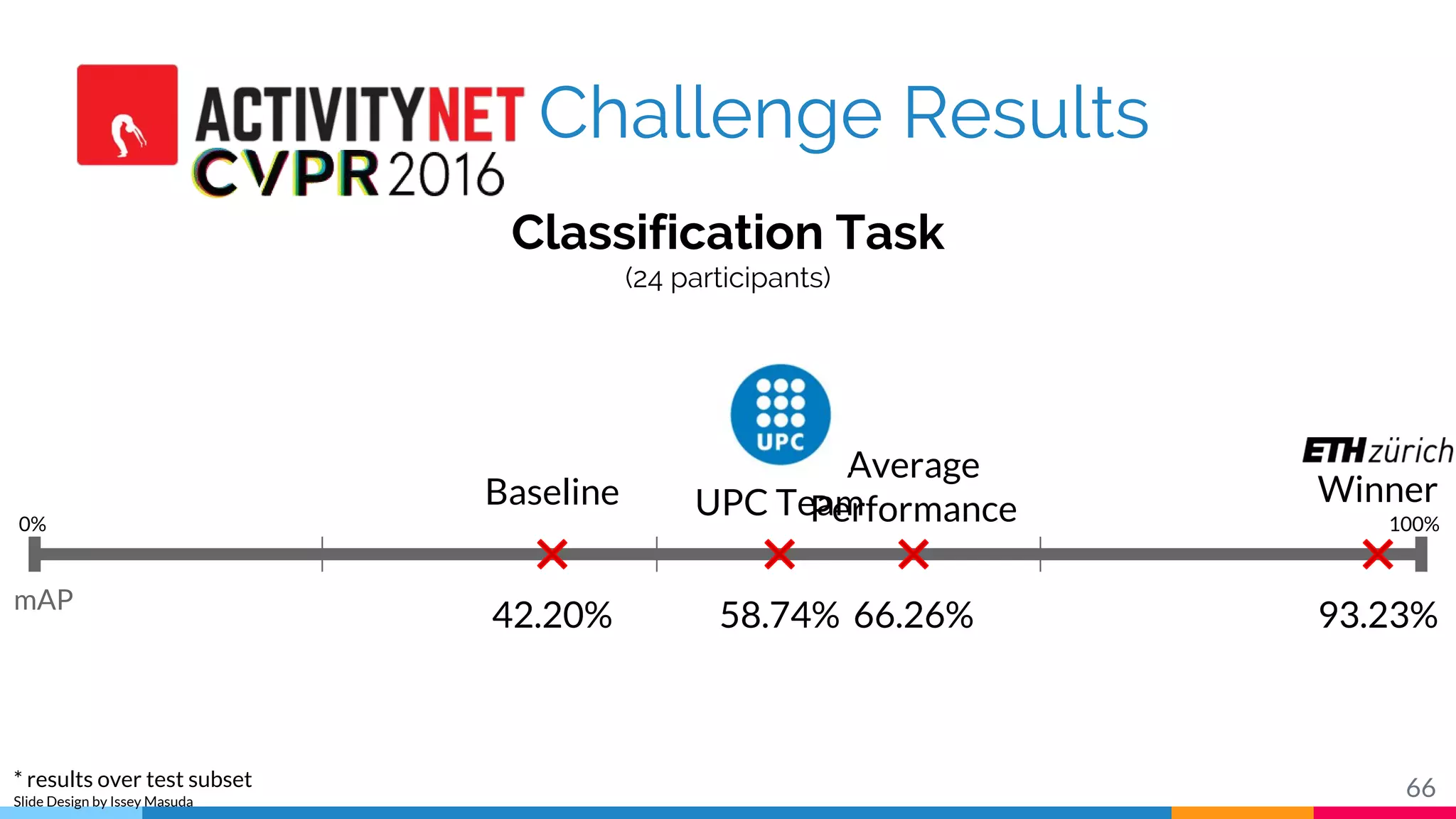



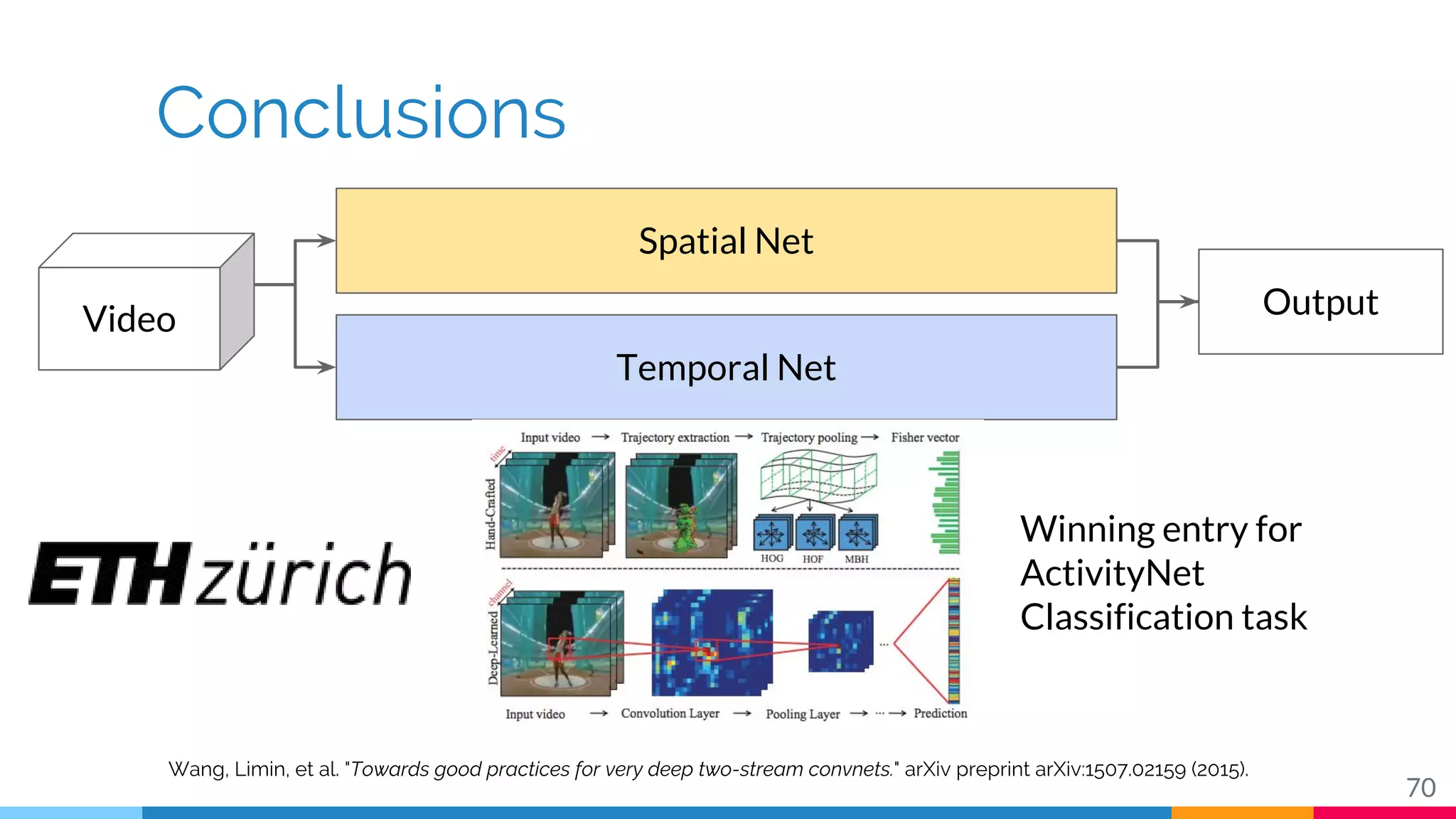



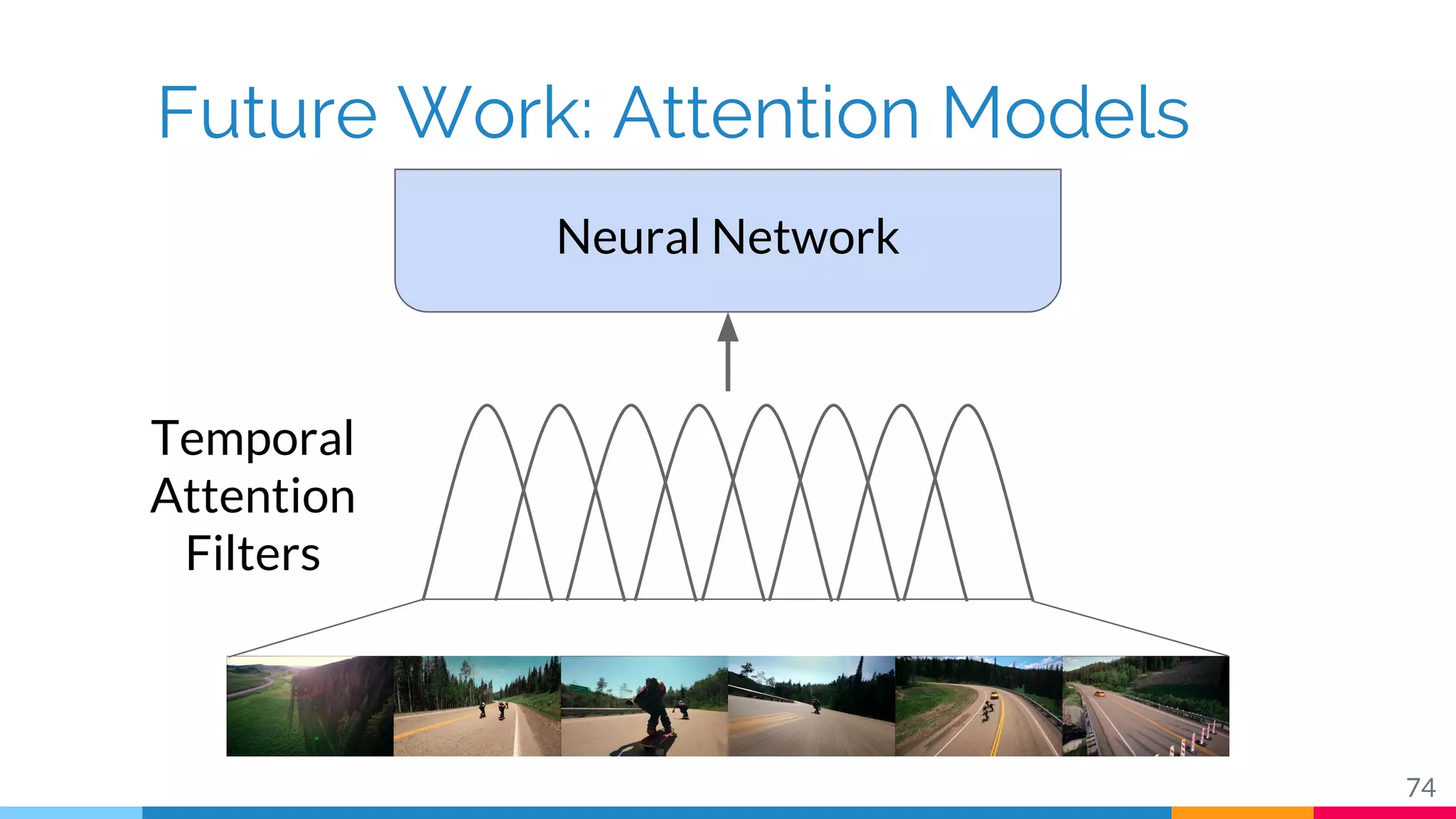






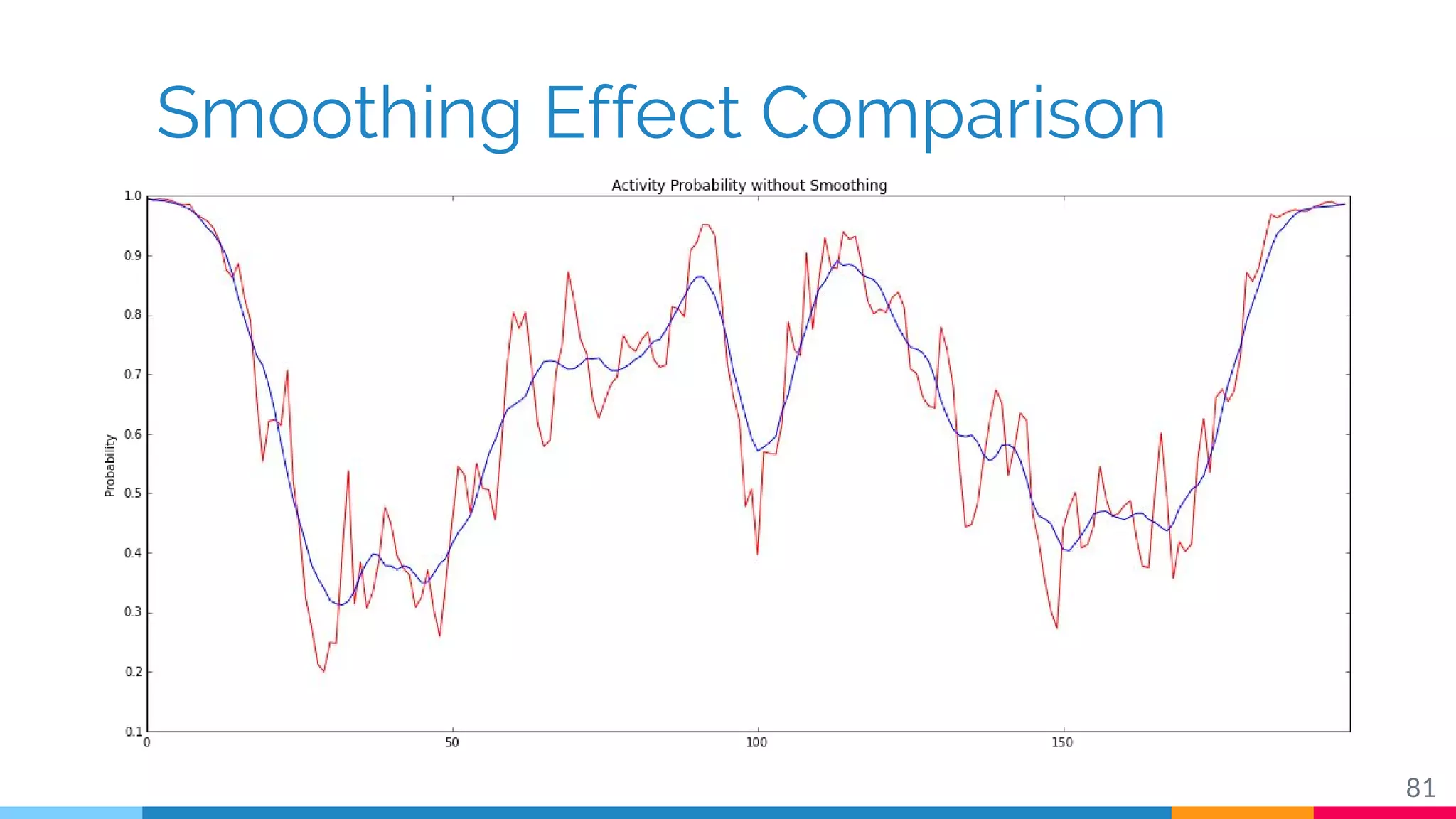
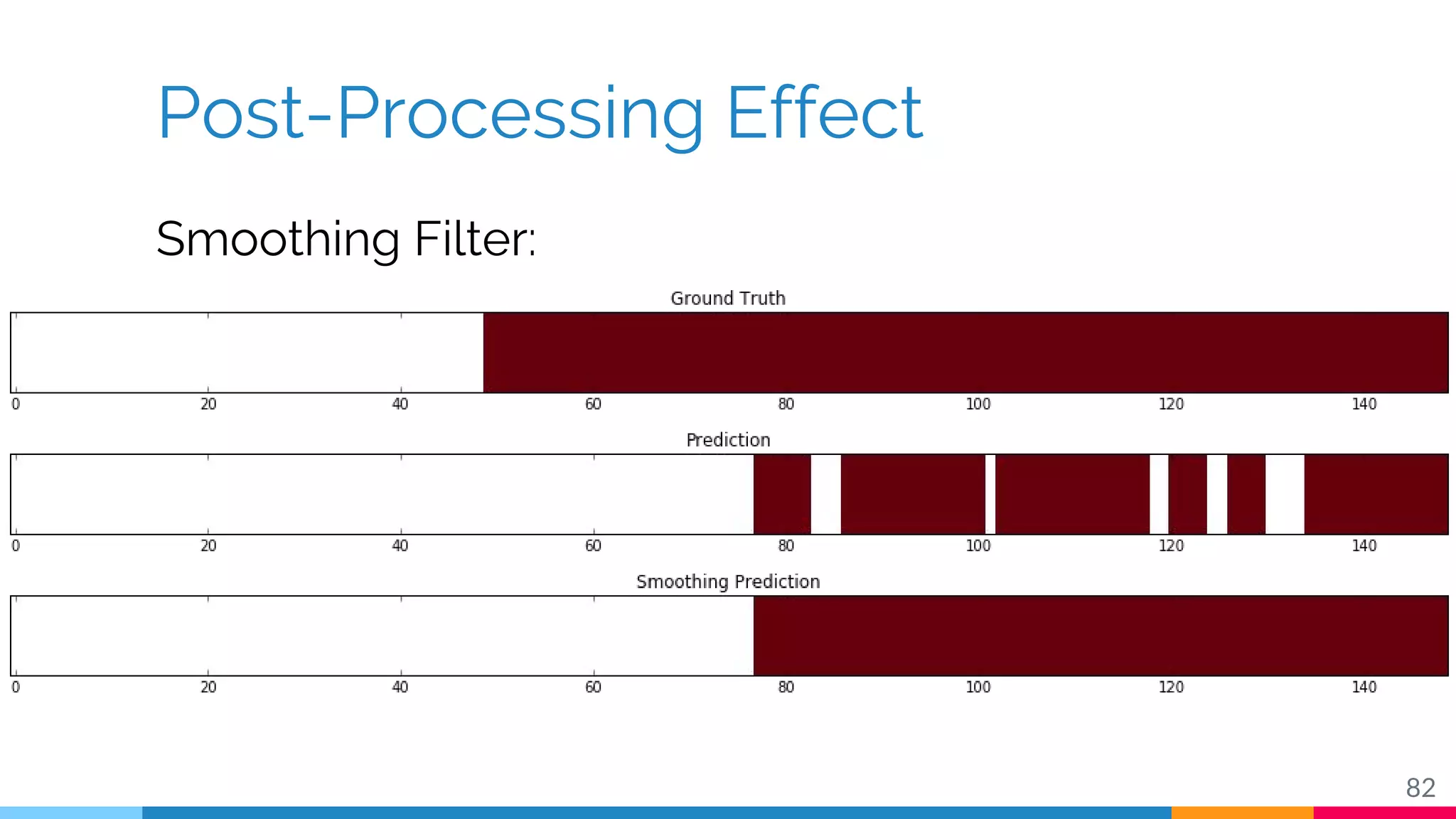

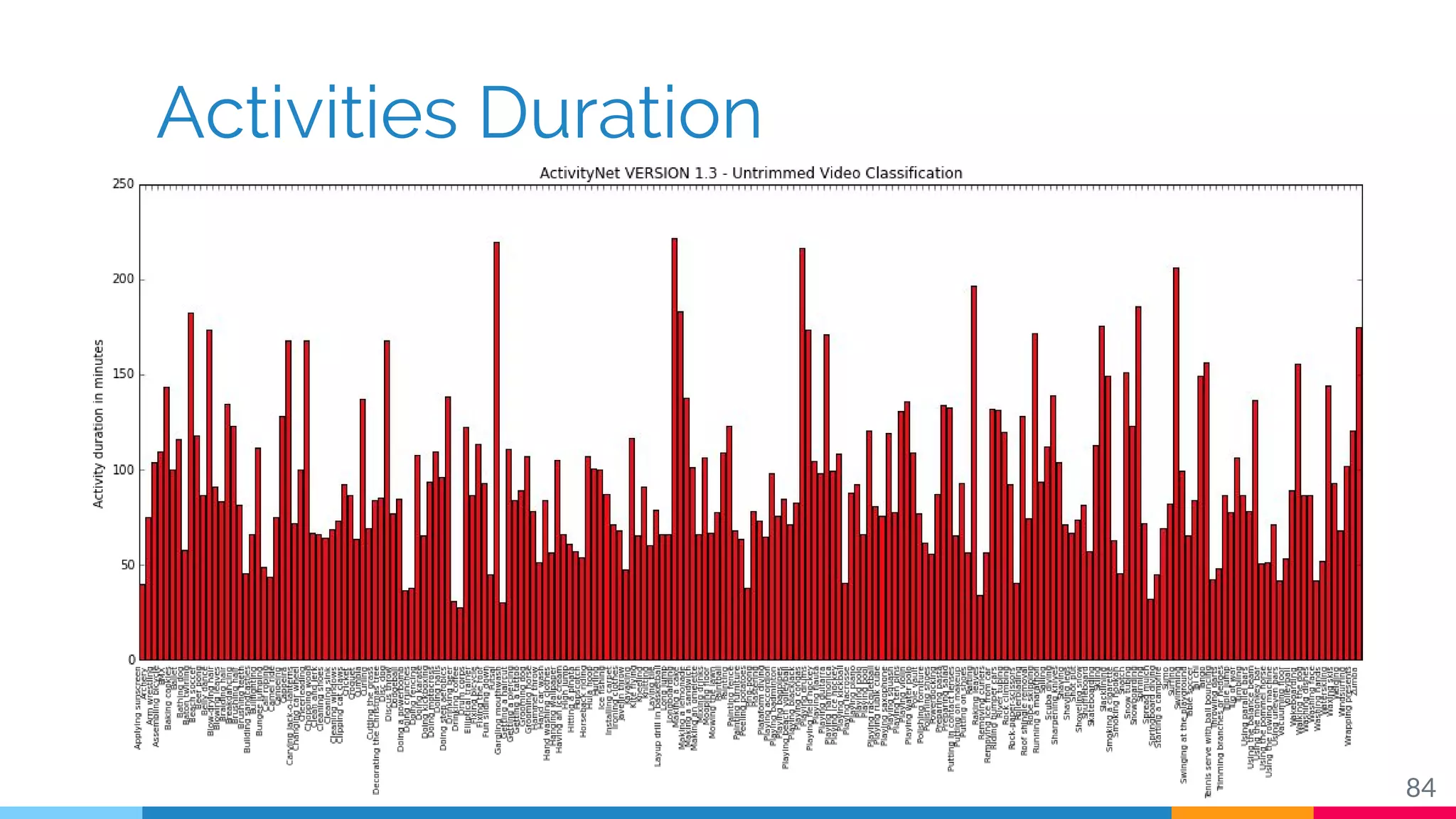
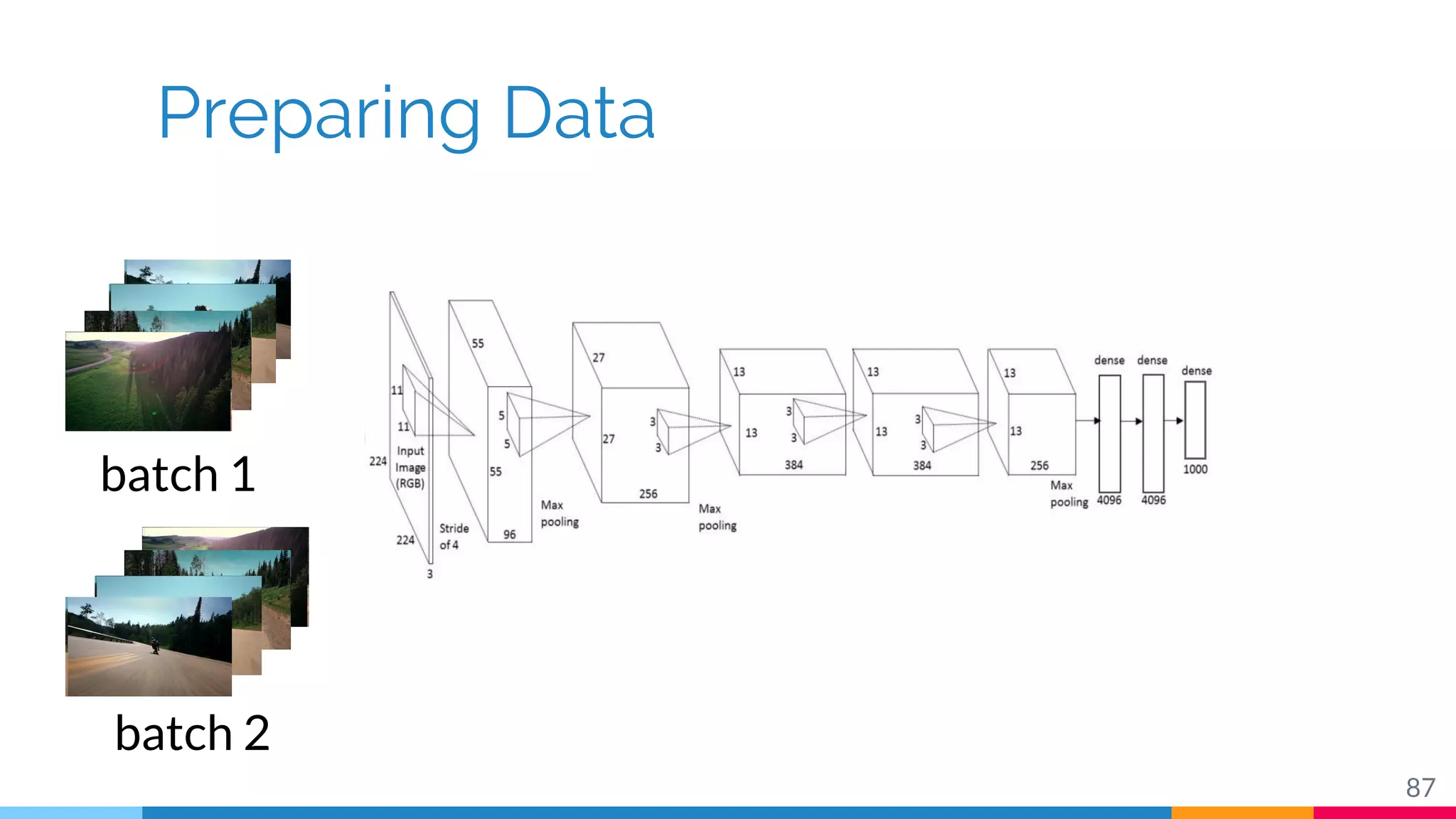
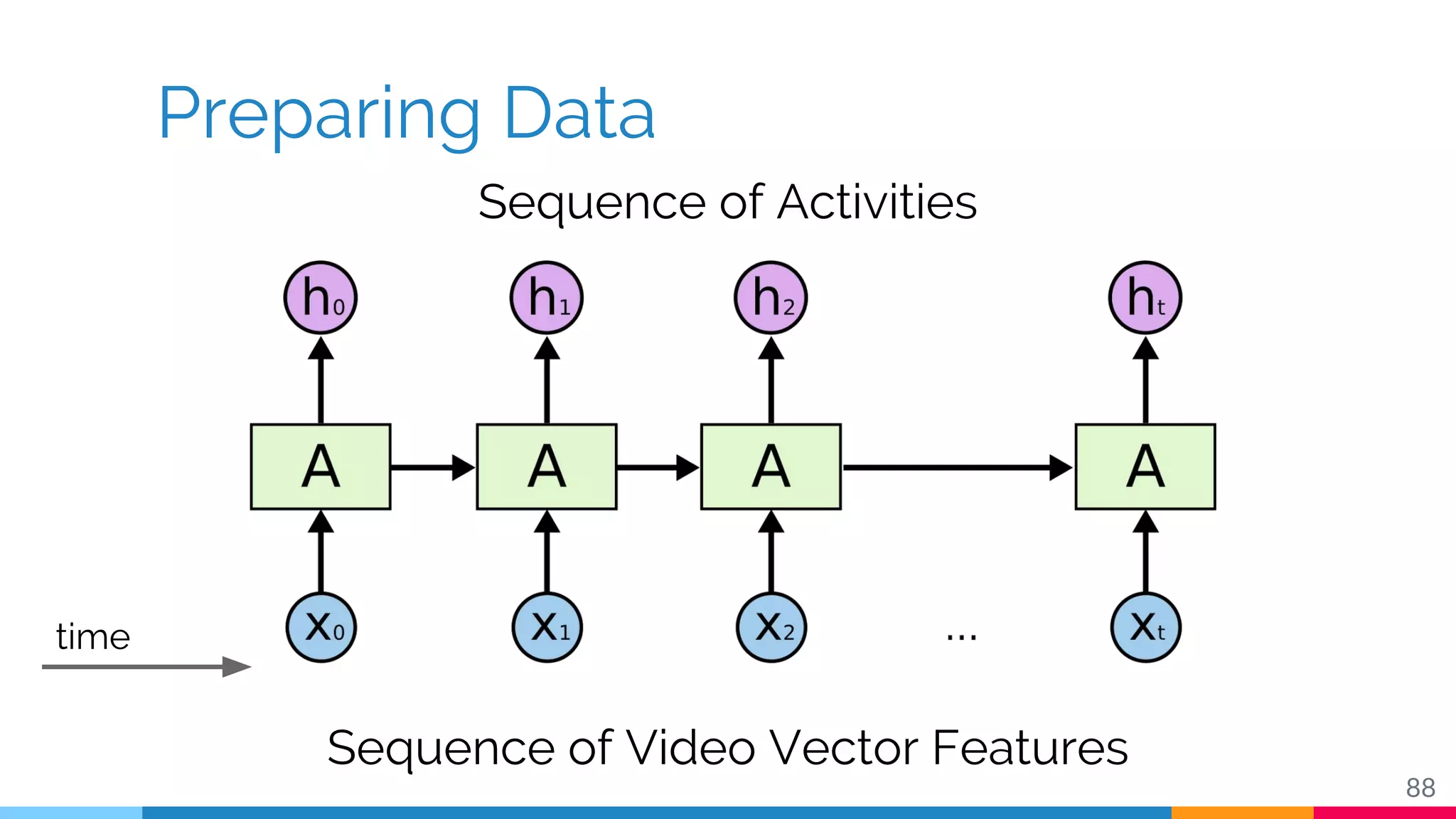
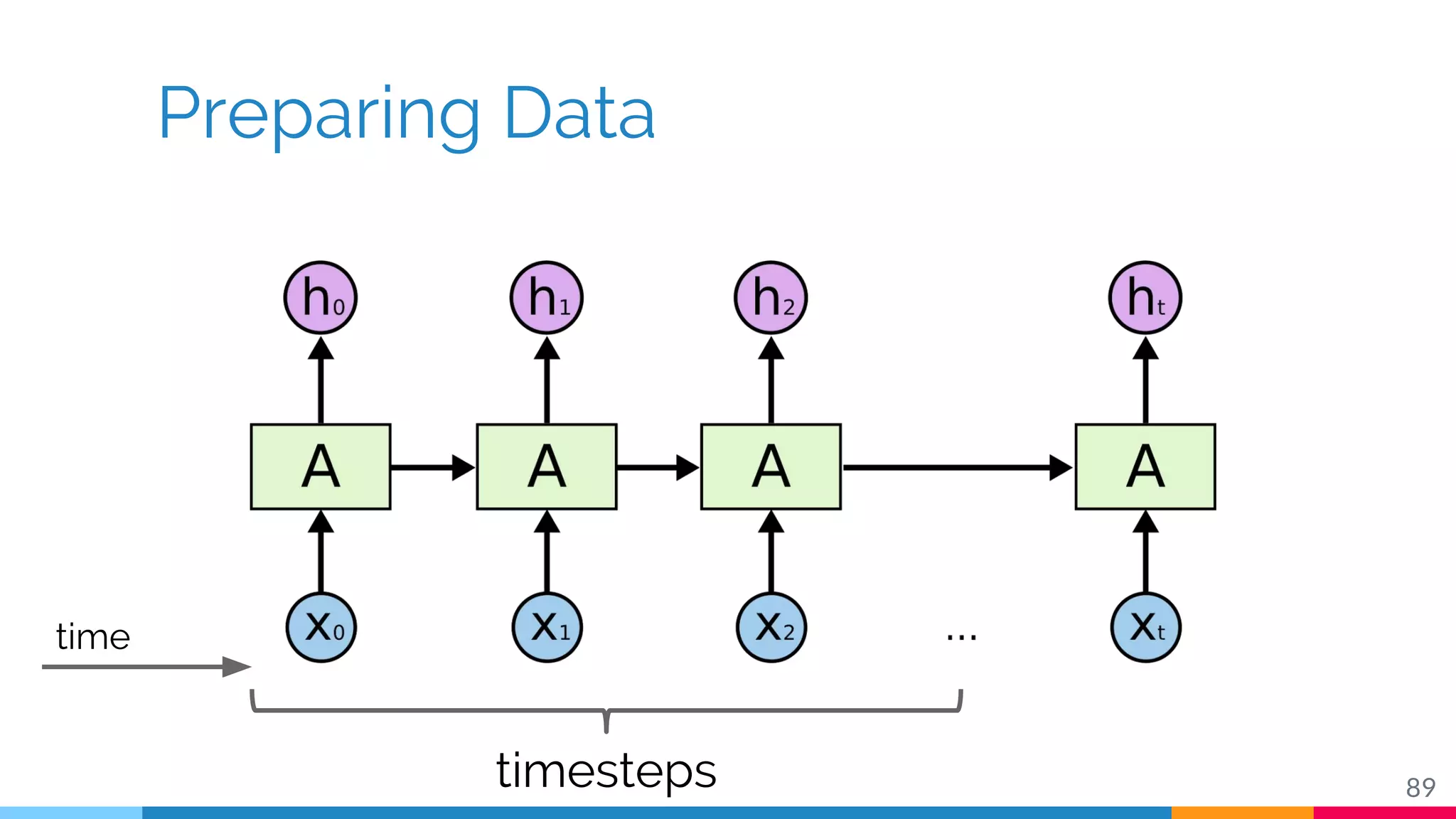
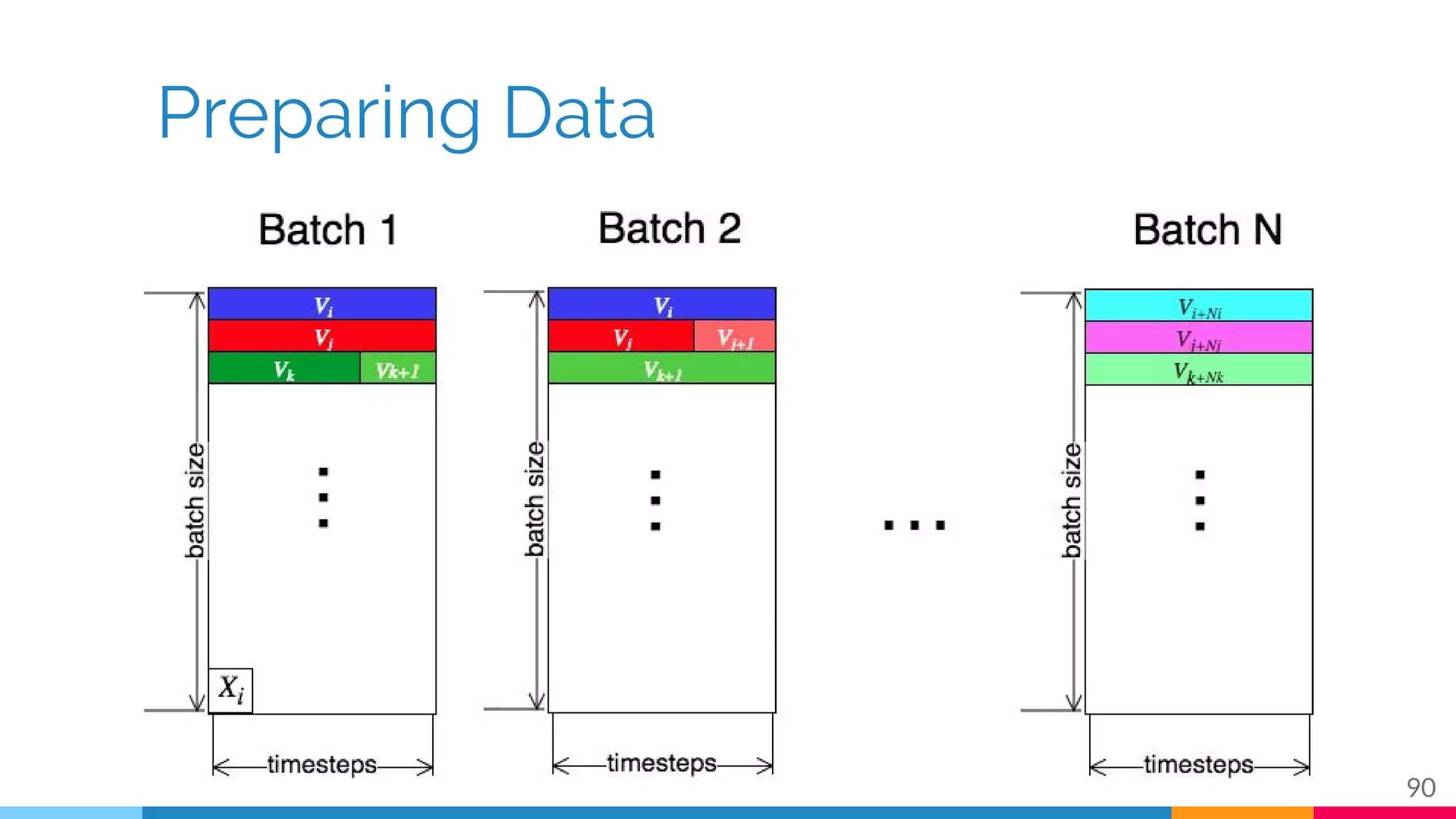
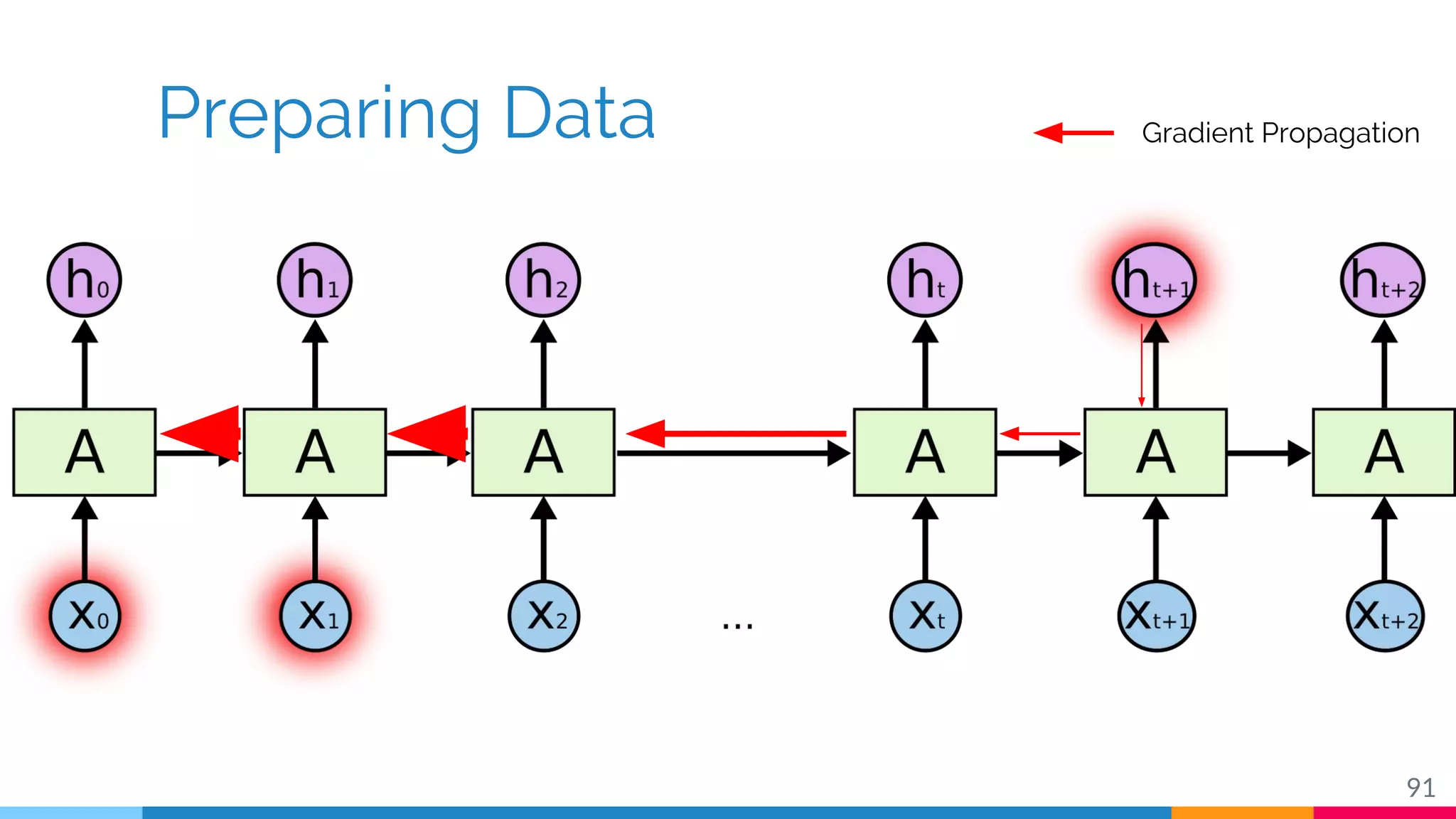
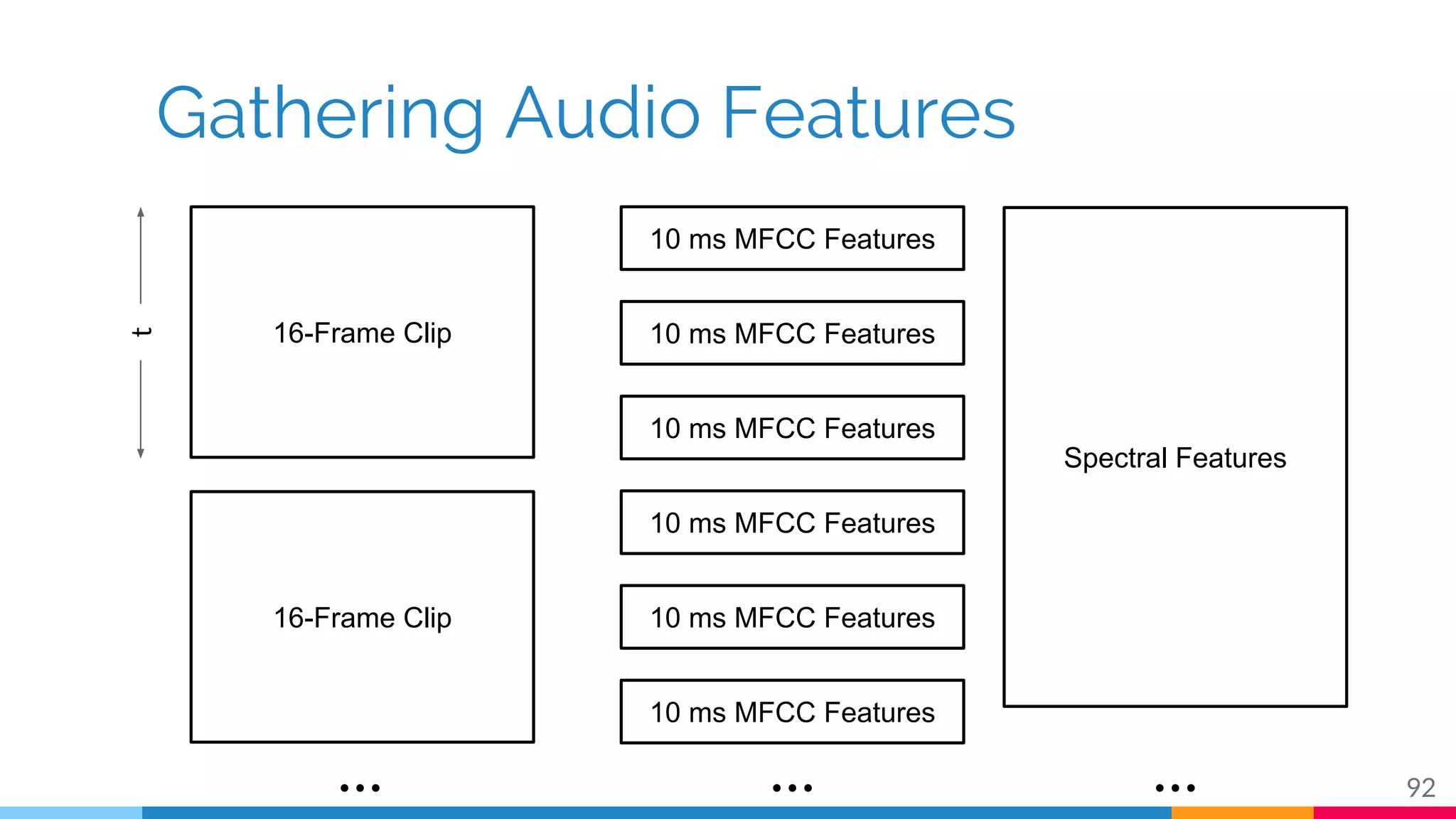
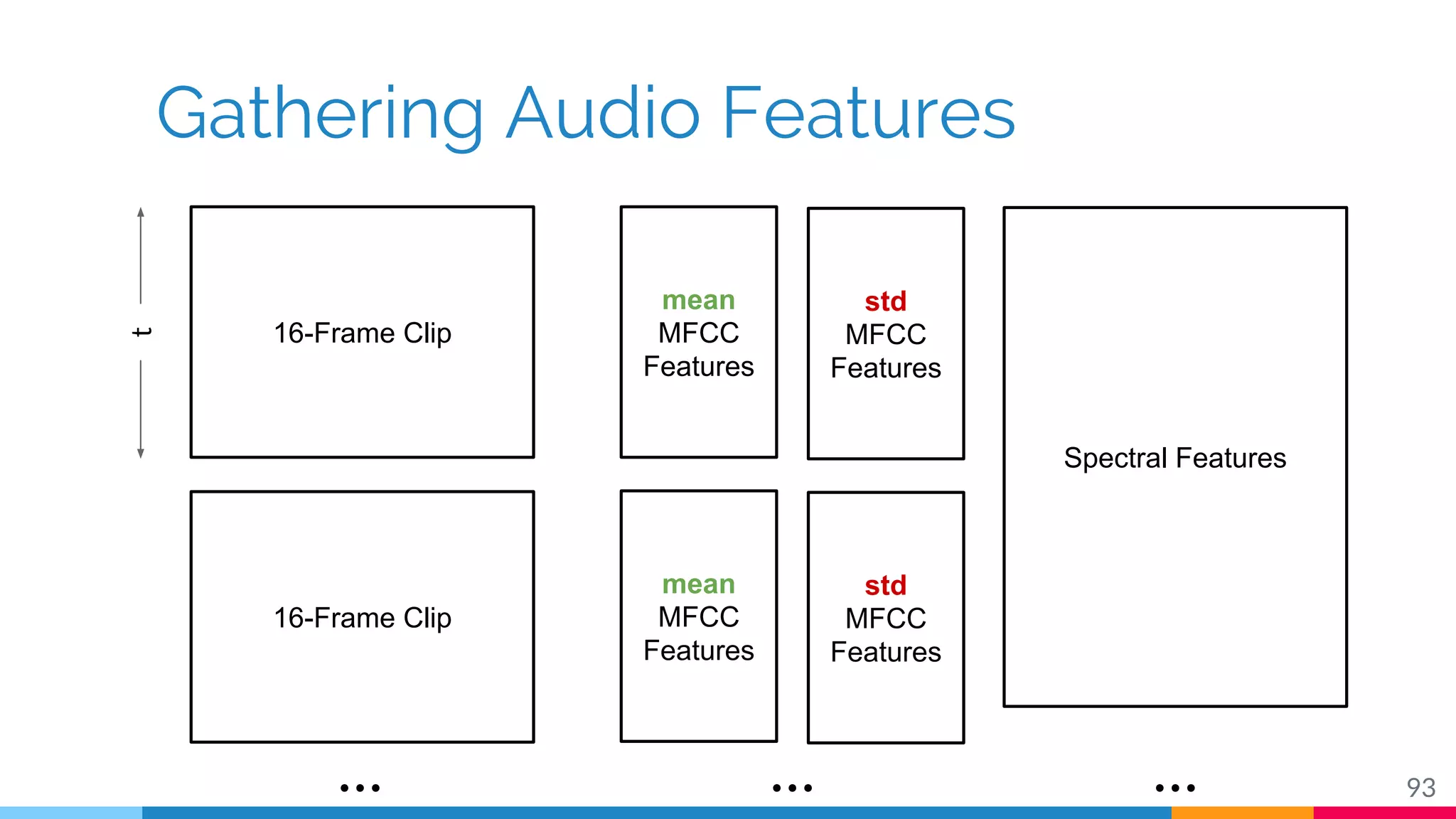
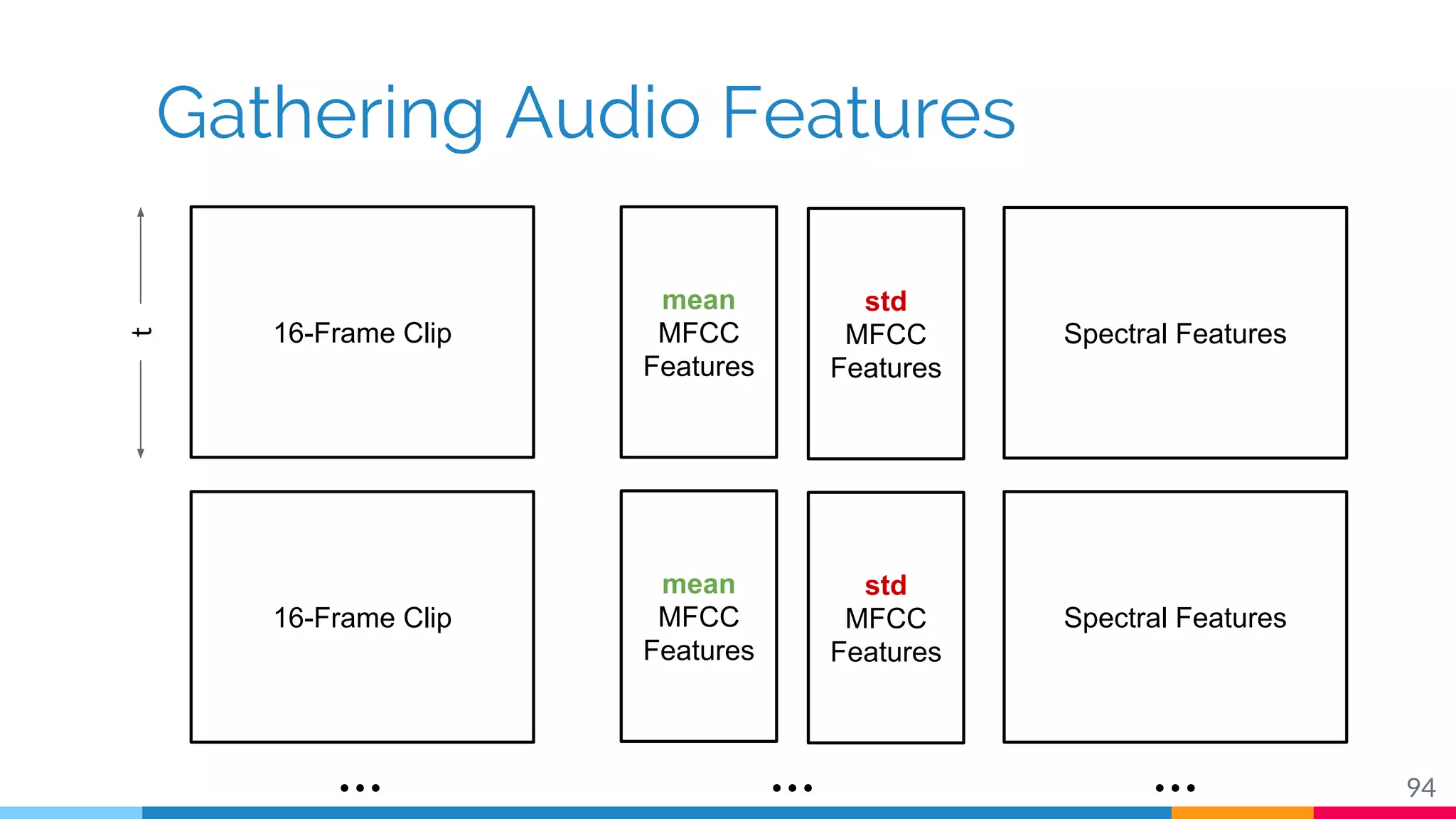
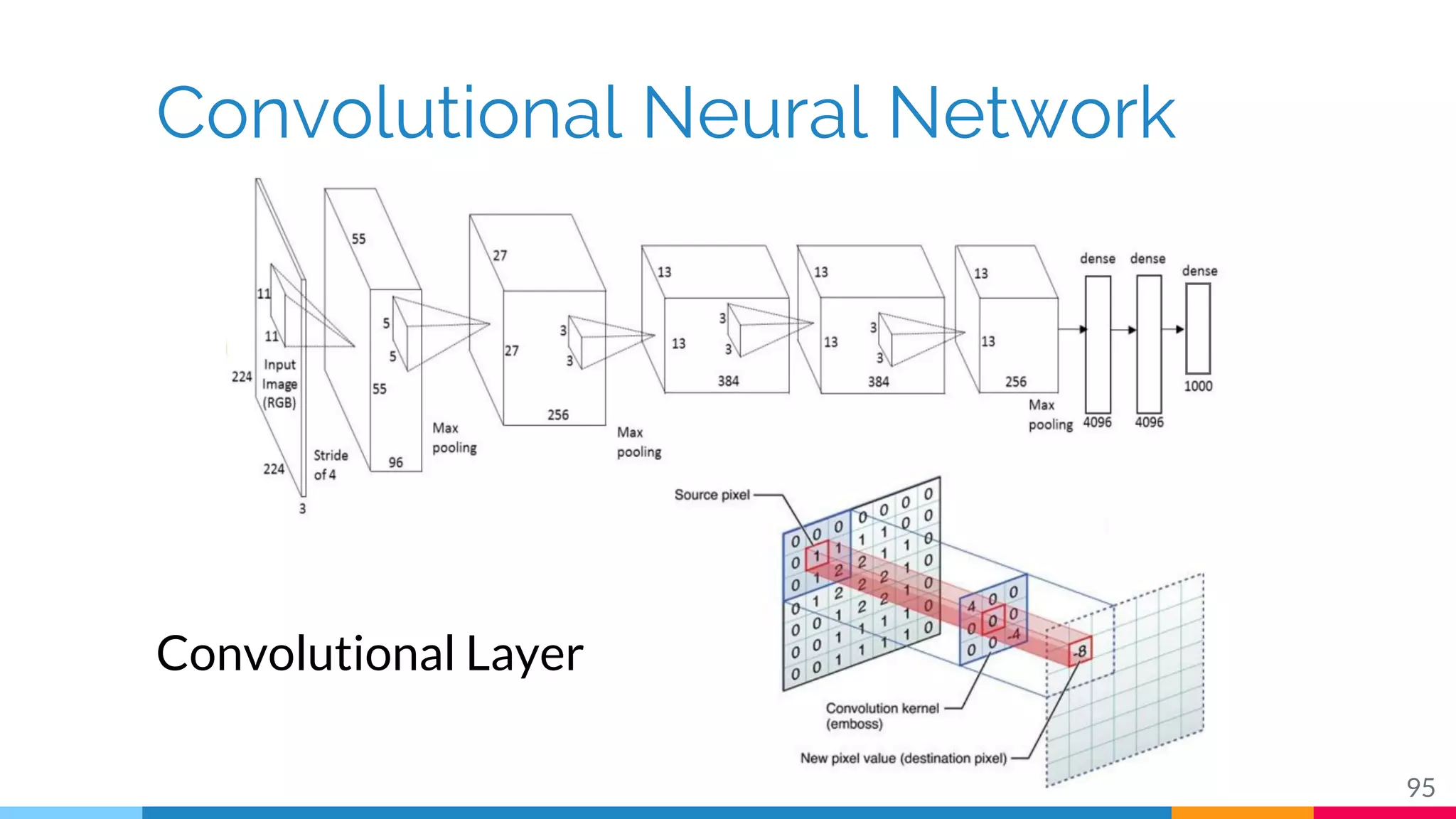
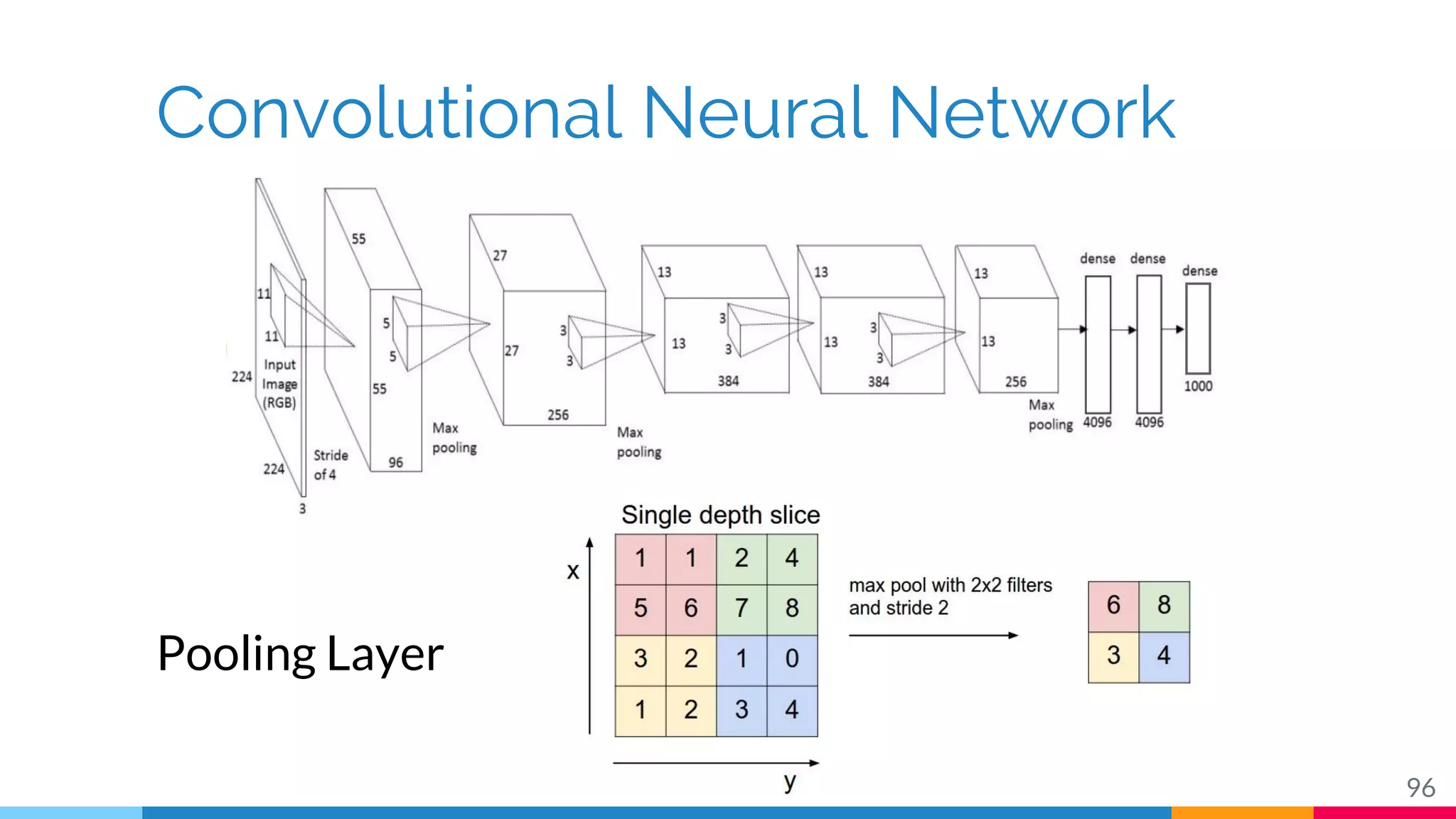
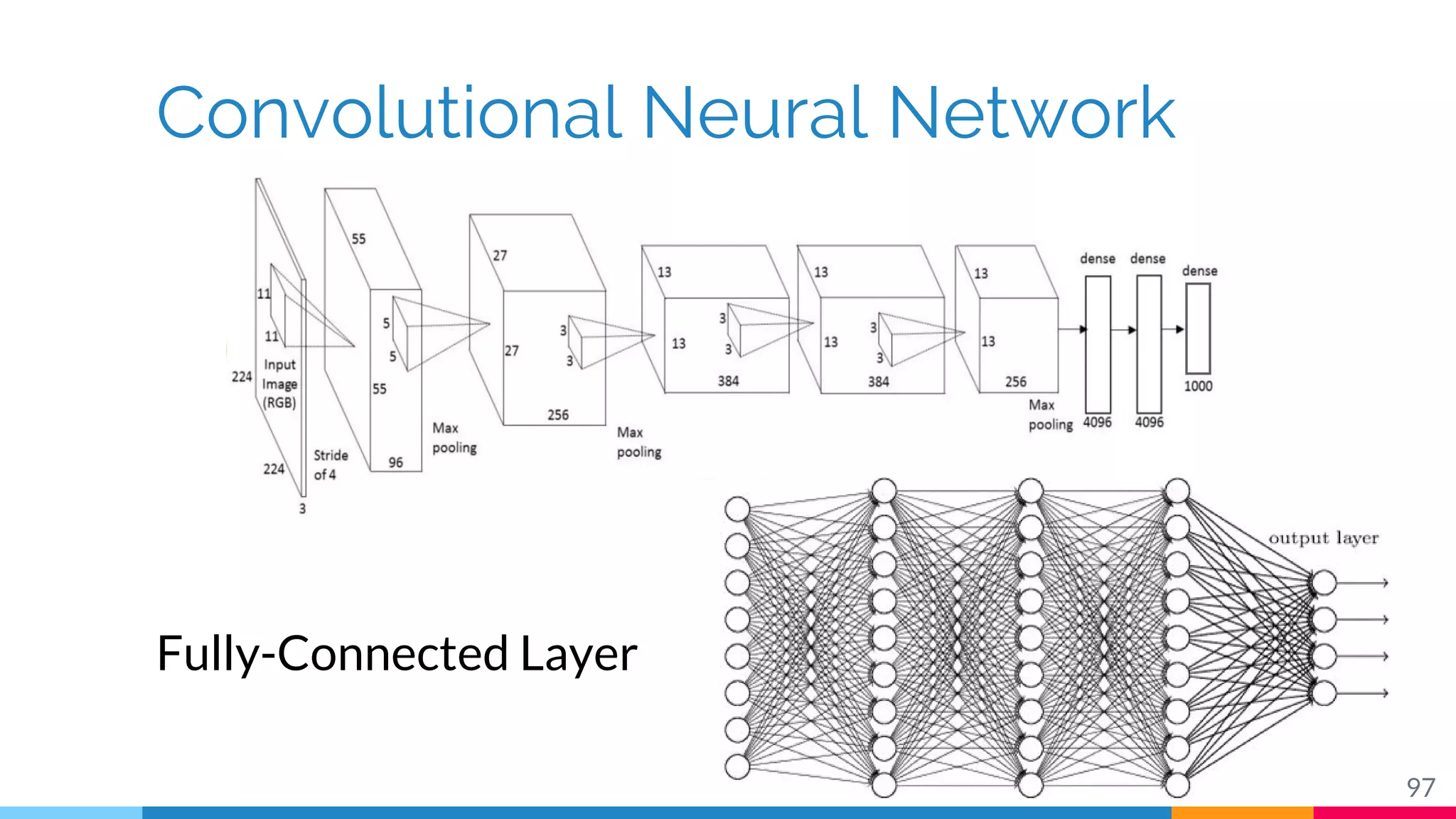
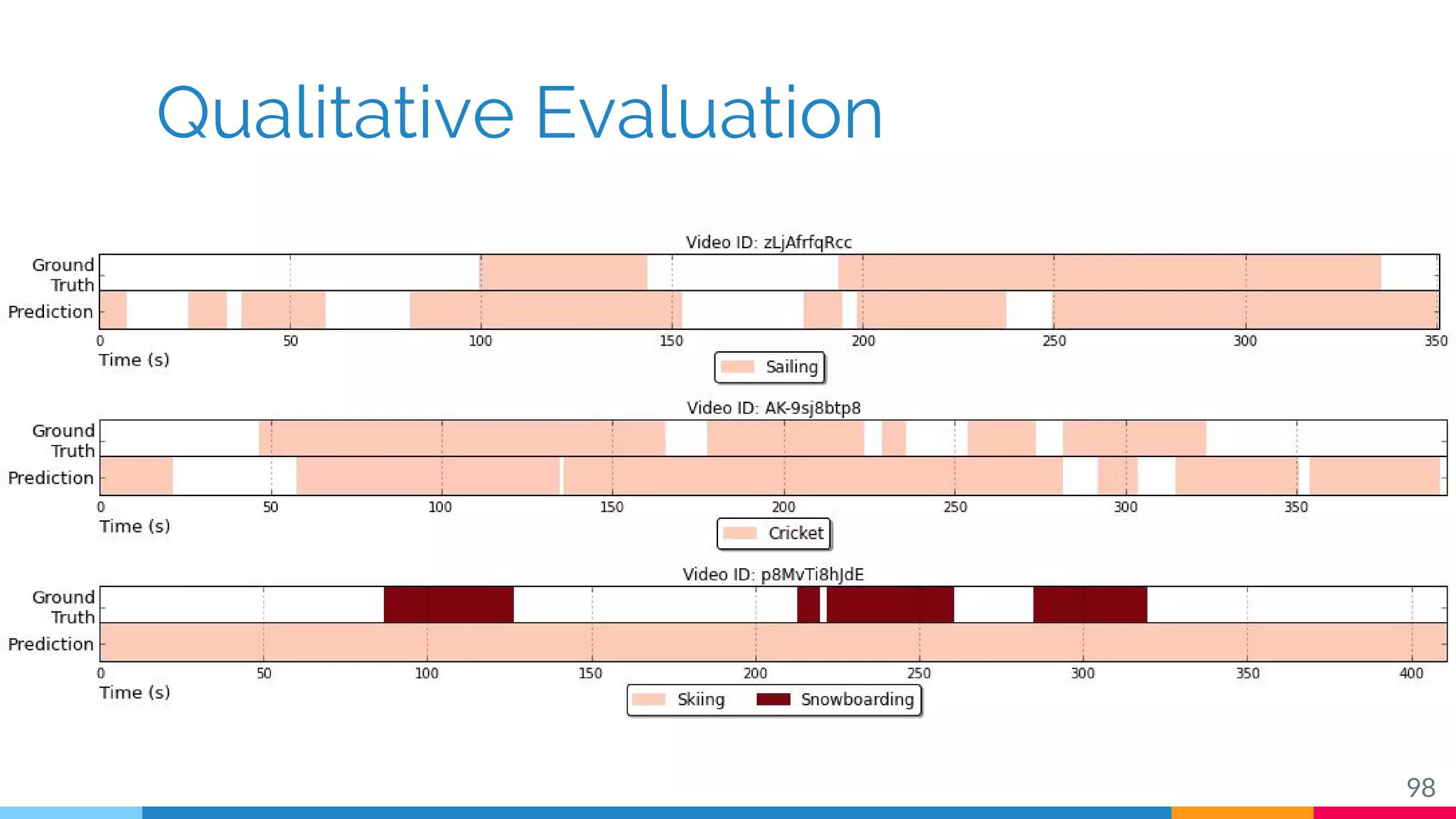

The document discusses a methodology for temporal activity detection in untrimmed videos using recurrent neural networks and convolutional neural networks. It covers the architecture, training processes, and results of classifying and detecting various activities across a large dataset of nearly 20,000 videos. The authors also highlight challenges, future work in end-to-end training, and attention models for improved performance.





































































































