Download as PDF, PPTX
![Open-ended
Visual Question-Answering
[thesis][web][code]
Issey Masuda Mora Santiago Pascual de la PuenteXavier Giró i Nieto](https://image.slidesharecdn.com/tfgisseymasudaoralpresentation-160715105427/85/Open-ended-Visual-Question-Answering-1-320.jpg)

















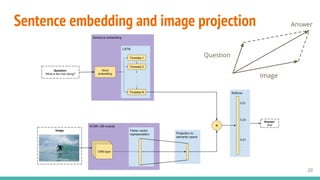






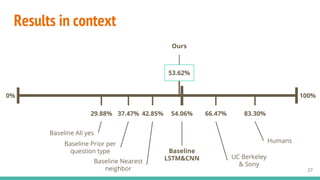


























The document presents a roadmap for open-ended visual question-answering (VQA), discussing its introduction, methodology, results, and future work. It emphasizes the use of deep learning techniques such as convolutional neural networks and long short-term memory networks to predict answers based on both visual and textual representations. The findings reveal a competitive performance of the proposed VQA models in comparison to existing baselines, with specific focus on generating answers rather than merely classifying them.



























![Prepositions of place [โหมดความเข้ากันได้]](https://cdn.slidesharecdn.com/ss_thumbnails/prepositionsofplace-111004011102-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)











![Prepositions powerpoint[1]](https://cdn.slidesharecdn.com/ss_thumbnails/prepositionspowerpoint1-120209065321-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)



























































