Download as PDF, PPTX
![@DocXavi
Module 3 - Lecture 10
Deep Convnets for
Video Processing
28 January 2016
Xavier Giró-i-Nieto
[http://pagines.uab.cat/mcv/]](https://image.slidesharecdn.com/mcv-m32016lecture10-deepconvnetsforvideoprocessing-160129073428/85/Deep-Convnets-for-Video-Processing-Master-in-Computer-Vision-Barcelona-2016-1-320.jpg)
![@DocXavi
Module 3 - Lecture 10
Deep Convnets for
Video Processing
28 January 2016
Xavier Giró-i-Nieto
[http://pagines.uab.cat/mcv/]](https://image.slidesharecdn.com/mcv-m32016lecture10-deepconvnetsforvideoprocessing-160129073428/75/Deep-Convnets-for-Video-Processing-Master-in-Computer-Vision-Barcelona-2016-1-2048.jpg)


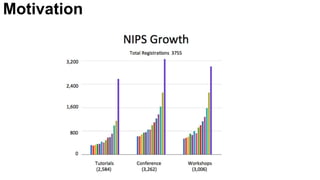
![Motivation
[Website]](https://image.slidesharecdn.com/mcv-m32016lecture10-deepconvnetsforvideoprocessing-160129073428/85/Deep-Convnets-for-Video-Processing-Master-in-Computer-Vision-Barcelona-2016-5-320.jpg)




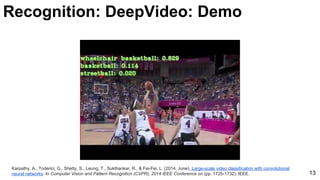
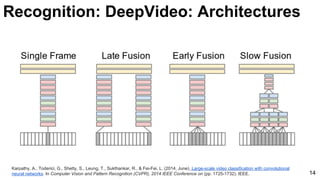
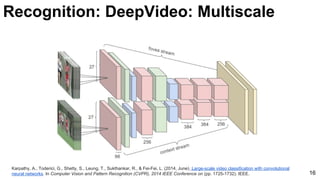
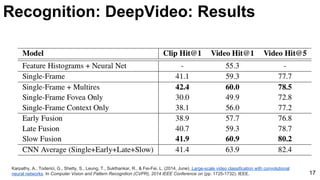
![Karpathy, A., Toderici, G., Shetty, S., Leung, T., Sukthankar, R., & Fei-Fei, L. (2014, June). Large-scale video classification with convolutional
neural networks. In Computer Vision and Pattern Recognition (CVPR), 2014 IEEE Conference on (pp. 1725-1732). IEEE. 15
Unsupervised learning [Le at al’11] Supervised learning [Karpathy et al’14]
Recognition: DeepVideo: Features](https://image.slidesharecdn.com/mcv-m32016lecture10-deepconvnetsforvideoprocessing-160129073428/85/Deep-Convnets-for-Video-Processing-Master-in-Computer-Vision-Barcelona-2016-15-320.jpg)
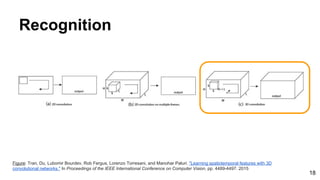

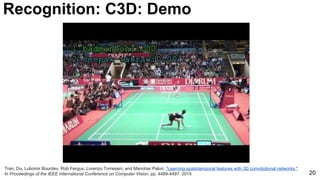

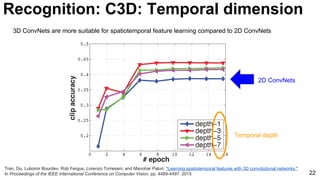
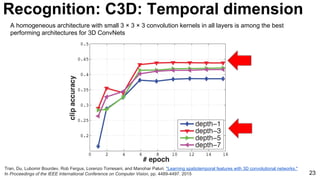
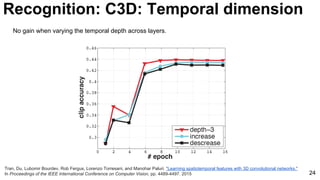


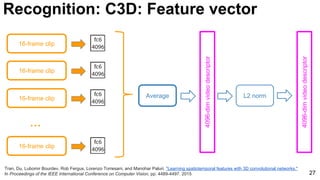
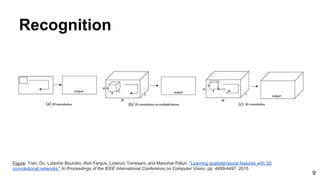
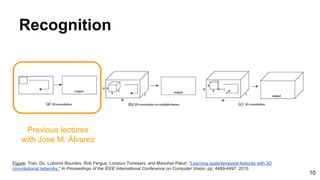
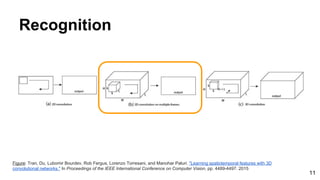
![28
Tran, Du, Lubomir Bourdev, Rob Fergus, Lorenzo Torresani, and Manohar Paluri. "Learning spatiotemporal features with 3D convolutional networks."
In Proceedings of the IEEE International Conference on Computer Vision, pp. 4489-4497. 2015
Recognition: C3D: Visualization
Based on Deconvnets by Zeiler and Fergus [ECCV 2014] - See [ReadCV Slides] for more details.](https://image.slidesharecdn.com/mcv-m32016lecture10-deepconvnetsforvideoprocessing-160129073428/85/Deep-Convnets-for-Video-Processing-Master-in-Computer-Vision-Barcelona-2016-28-320.jpg)
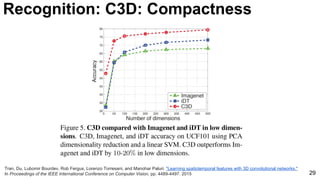
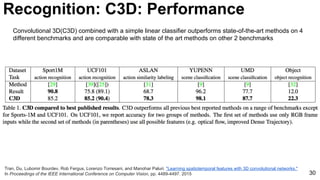

![32
Recognition: ImageNet Video
[ILSVRC 2015 Slides and videos]](https://image.slidesharecdn.com/mcv-m32016lecture10-deepconvnetsforvideoprocessing-160129073428/85/Deep-Convnets-for-Video-Processing-Master-in-Computer-Vision-Barcelona-2016-32-320.jpg)
![33
Recognition: ImageNet Video
[ILSVRC 2015 Slides and videos]](https://image.slidesharecdn.com/mcv-m32016lecture10-deepconvnetsforvideoprocessing-160129073428/85/Deep-Convnets-for-Video-Processing-Master-in-Computer-Vision-Barcelona-2016-33-320.jpg)
![34
Recognition: ImageNet Video
[ILSVRC 2015 Slides and videos]](https://image.slidesharecdn.com/mcv-m32016lecture10-deepconvnetsforvideoprocessing-160129073428/85/Deep-Convnets-for-Video-Processing-Master-in-Computer-Vision-Barcelona-2016-34-320.jpg)
![35
Recognition: ImageNet Video
[ILSVRC 2015 Slides and videos]](https://image.slidesharecdn.com/mcv-m32016lecture10-deepconvnetsforvideoprocessing-160129073428/85/Deep-Convnets-for-Video-Processing-Master-in-Computer-Vision-Barcelona-2016-35-320.jpg)
![36
Recognition: ImageNet Video
Kai Kang et al, Object Detection in Videos with TubeLets and Multi-Context Cues (ILSVRC 2015) [video] [poster]](https://image.slidesharecdn.com/mcv-m32016lecture10-deepconvnetsforvideoprocessing-160129073428/85/Deep-Convnets-for-Video-Processing-Master-in-Computer-Vision-Barcelona-2016-36-320.jpg)
![37
Recognition: ImageNet Video
Kai Kang et al, Object Detection in Videos with TubeLets and Multi-Context Cues (ILSVRC 2015) [video] [poster]](https://image.slidesharecdn.com/mcv-m32016lecture10-deepconvnetsforvideoprocessing-160129073428/85/Deep-Convnets-for-Video-Processing-Master-in-Computer-Vision-Barcelona-2016-37-320.jpg)
![38
Recognition: ImageNet Video
Kai Kang et al, Object Detection in Videos with TubeLets and Multi-Context Cues (ILSVRC 2015) [video] [poster]](https://image.slidesharecdn.com/mcv-m32016lecture10-deepconvnetsforvideoprocessing-160129073428/85/Deep-Convnets-for-Video-Processing-Master-in-Computer-Vision-Barcelona-2016-38-320.jpg)
![39
Recognition: ImageNet Video
Kai Kang et al, Object Detection in Videos with TubeLets and Multi-Context Cues (ILSVRC 2015) [video] [poster]](https://image.slidesharecdn.com/mcv-m32016lecture10-deepconvnetsforvideoprocessing-160129073428/85/Deep-Convnets-for-Video-Processing-Master-in-Computer-Vision-Barcelona-2016-39-320.jpg)



![Source: Matlab R2015b documentation for normxcorr2 by Mathworks
44
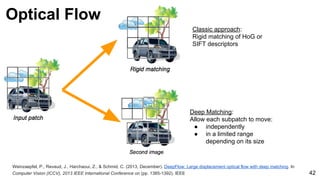
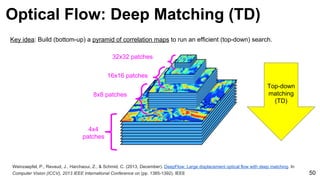
Optical Flow: 2D correlation
Image
Sub-Image
Offset of the sub-image with respect to the image [0,0].](https://image.slidesharecdn.com/mcv-m32016lecture10-deepconvnetsforvideoprocessing-160129073428/85/Deep-Convnets-for-Video-Processing-Master-in-Computer-Vision-Barcelona-2016-44-320.jpg)


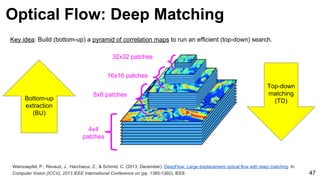
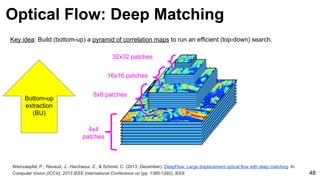
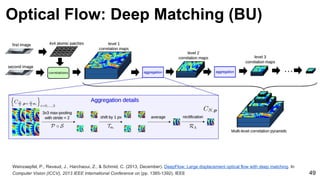

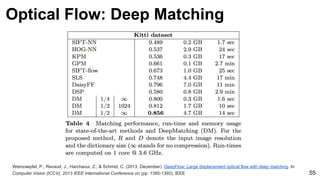
![Weinzaepfel, P., Revaud, J., Harchaoui, Z., & Schmid, C. (2013, December). DeepFlow: Large displacement optical flow with deep matching. In
Computer Vision (ICCV), 2013 IEEE International Conference on (pp. 1385-1392). IEEE 54
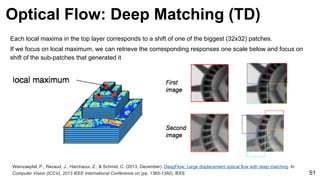
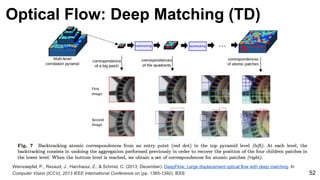
Ground truth
Dense HOG
[Brox & Malik 2011]
Deep Matching
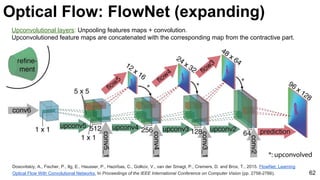
Optical Flow: Deep Matching](https://image.slidesharecdn.com/mcv-m32016lecture10-deepconvnetsforvideoprocessing-160129073428/85/Deep-Convnets-for-Video-Processing-Master-in-Computer-Vision-Barcelona-2016-54-320.jpg)


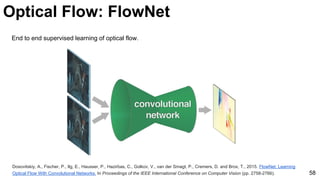
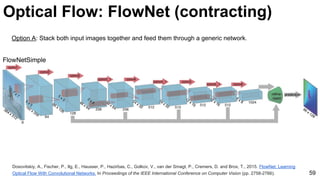
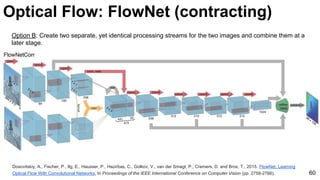
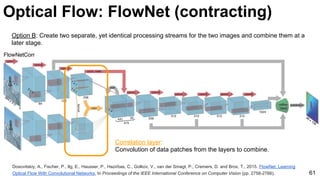

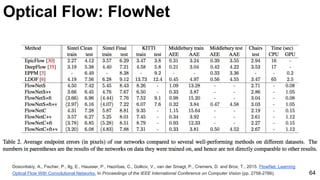




![Object tracking: FCNT
69
Wang, Lijun, Wanli Ouyang, Xiaogang Wang, and Huchuan Lu. "Visual Tracking with Fully Convolutional Networks." In Proceedings of the IEEE
International Conference on Computer Vision, pp. 3119-3127. 2015 [code]](https://image.slidesharecdn.com/mcv-m32016lecture10-deepconvnetsforvideoprocessing-160129073428/85/Deep-Convnets-for-Video-Processing-Master-in-Computer-Vision-Barcelona-2016-69-320.jpg)
![Object tracking: FCNT
70
Wang, Lijun, Wanli Ouyang, Xiaogang Wang, and Huchuan Lu. "Visual Tracking with Fully Convolutional Networks." In Proceedings of the IEEE
International Conference on Computer Vision, pp. 3119-3127. 2015 [code]
Focus on conv4-3 and conv5-3 of VGG-16 network pre-trained for ImageNet image classification.
conv4-3 conv5-3](https://image.slidesharecdn.com/mcv-m32016lecture10-deepconvnetsforvideoprocessing-160129073428/85/Deep-Convnets-for-Video-Processing-Master-in-Computer-Vision-Barcelona-2016-70-320.jpg)
![Object tracking: FCNT: Specialization
71
Wang, Lijun, Wanli Ouyang, Xiaogang Wang, and Huchuan Lu. "Visual Tracking with Fully Convolutional Networks." In Proceedings of the IEEE
International Conference on Computer Vision, pp. 3119-3127. 2015 [code]
Most feature maps in VGG-16 conv4-3 and conv5-3 are not related to the foreground regions in a tracking
sequence.](https://image.slidesharecdn.com/mcv-m32016lecture10-deepconvnetsforvideoprocessing-160129073428/85/Deep-Convnets-for-Video-Processing-Master-in-Computer-Vision-Barcelona-2016-71-320.jpg)
![Object tracking: FCNT: Localization
72
Wang, Lijun, Wanli Ouyang, Xiaogang Wang, and Huchuan Lu. "Visual Tracking with Fully Convolutional Networks." In Proceedings of the IEEE
International Conference on Computer Vision, pp. 3119-3127. 2015 [code]
Although trained for image classification, feature maps in conv5-3 enable object localization…
...but is not discriminative enough to different objects of the same category.](https://image.slidesharecdn.com/mcv-m32016lecture10-deepconvnetsforvideoprocessing-160129073428/85/Deep-Convnets-for-Video-Processing-Master-in-Computer-Vision-Barcelona-2016-72-320.jpg)
![Object tracking: Localization
73
Zhou, Bolei, Aditya Khosla, Agata Lapedriza, Aude Oliva, and Antonio Torralba. "Object detectors emerge in deep scene cnns." ICLR 2015.
[Zhou et al, ICLR 2015] “Object detectors emerge in deep scene CNNs” [Slides from ReadCV]](https://image.slidesharecdn.com/mcv-m32016lecture10-deepconvnetsforvideoprocessing-160129073428/85/Deep-Convnets-for-Video-Processing-Master-in-Computer-Vision-Barcelona-2016-73-320.jpg)
![Object tracking: FCNT: Localization
74
Wang, Lijun, Wanli Ouyang, Xiaogang Wang, and Huchuan Lu. "Visual Tracking with Fully Convolutional Networks." In Proceedings of the IEEE
International Conference on Computer Vision, pp. 3119-3127. 2015 [code]
On the other hand, feature maps from conv4-3 are more sensitive to intra-class appearance variation…
conv4-3 conv5-3](https://image.slidesharecdn.com/mcv-m32016lecture10-deepconvnetsforvideoprocessing-160129073428/85/Deep-Convnets-for-Video-Processing-Master-in-Computer-Vision-Barcelona-2016-74-320.jpg)
![Object tracking: FCNT: Architecture
75
Wang, Lijun, Wanli Ouyang, Xiaogang Wang, and Huchuan Lu. "Visual Tracking with Fully Convolutional Networks." In Proceedings of the IEEE
International Conference on Computer Vision, pp. 3119-3127. 2015 [code]
SNet=Specific Network (online update)
GNet=General Network (fixed)](https://image.slidesharecdn.com/mcv-m32016lecture10-deepconvnetsforvideoprocessing-160129073428/85/Deep-Convnets-for-Video-Processing-Master-in-Computer-Vision-Barcelona-2016-75-320.jpg)
![Object tracking: FCNT: Results
76
Wang, Lijun, Wanli Ouyang, Xiaogang Wang, and Huchuan Lu. "Visual Tracking with Fully Convolutional Networks." In Proceedings of the IEEE
International Conference on Computer Vision, pp. 3119-3127. 2015 [code]](https://image.slidesharecdn.com/mcv-m32016lecture10-deepconvnetsforvideoprocessing-160129073428/85/Deep-Convnets-for-Video-Processing-Master-in-Computer-Vision-Barcelona-2016-76-320.jpg)

















![Image Classification
97
Our past research
A. Salvador, Zeppelzauer, M., Manchon-Vizuete, D., Calafell-Orós, A., and Giró-i-Nieto, X., “Cultural Event Recognition with Visual ConvNets and Temporal
Models”, in CVPR ChaLearn Looking at People Workshop 2015, 2015. [slides]
ChaLearn Worshop](https://image.slidesharecdn.com/mcv-m32016lecture10-deepconvnetsforvideoprocessing-160129073428/85/Deep-Convnets-for-Video-Processing-Master-in-Computer-Vision-Barcelona-2016-97-320.jpg)
![Saliency Prediction
J. Pan and Giró-i-Nieto, X., “End-to-end Convolutional Network for Saliency Prediction”, in Large-scale Scene Understanding Challenge (LSUN) at CVPR
Workshops , Boston, MA (USA), 2015. [Slides]
98
Our current research
LSUN Challenge](https://image.slidesharecdn.com/mcv-m32016lecture10-deepconvnetsforvideoprocessing-160129073428/85/Deep-Convnets-for-Video-Processing-Master-in-Computer-Vision-Barcelona-2016-98-320.jpg)
![Sentiment Analysis
99
Our current research
[Slides]
CNN
V. Campos, Salvador, A., Jou, B., and Giró-i-Nieto, X., “Diving Deep into Sentiment: Understanding Fine-tuned CNNs for Visual Sentiment Prediction”, in 1st
International Workshop on Affect and Sentiment in Multimedia, Brisbane, Australia, 2015.](https://image.slidesharecdn.com/mcv-m32016lecture10-deepconvnetsforvideoprocessing-160129073428/85/Deep-Convnets-for-Video-Processing-Master-in-Computer-Vision-Barcelona-2016-99-320.jpg)


This document discusses deep convolutional networks for video processing, focusing on recognition, optical flow, and object tracking as key areas. It references various studies and works related to video classification and features learned through 3D convolutional networks, illustrating significant advancements in the field. Additionally, the content highlights demonstrations and architectural insights into effective video processing methodologies.




















































































