Download as PDF, PPTX
![@DocXavi
Xavier Giró-i-Nieto
[http://pagines.uab.cat/mcv/]
Module 6
Deep Learning for Video:
Architectures
26th February 2019](https://image.slidesharecdn.com/mcv-m62019d1l2deeplearningarchitecturesforvideo-190329080335/75/Deep-Learning-Architectures-for-Video-Xavier-Giro-UPC-Barcelona-2019-1-2048.jpg)


![DL online courses by UPC TelecomBCN:
You can audit this one.
● MSc course [2017] [2018]
● BSc course [2018] [2019]
● 1st edition (2016)
● 2nd edition (2017)
● 3rd edition (2018)
● 4th edition (2019)
● 1st edition (2017)
● 2nd edition (2018)
● 3rd edition - NLP (2019)](https://image.slidesharecdn.com/mcv-m62019d1l2deeplearningarchitecturesforvideo-190329080335/75/Deep-Learning-Architectures-for-Video-Xavier-Giro-UPC-Barcelona-2019-4-2048.jpg)









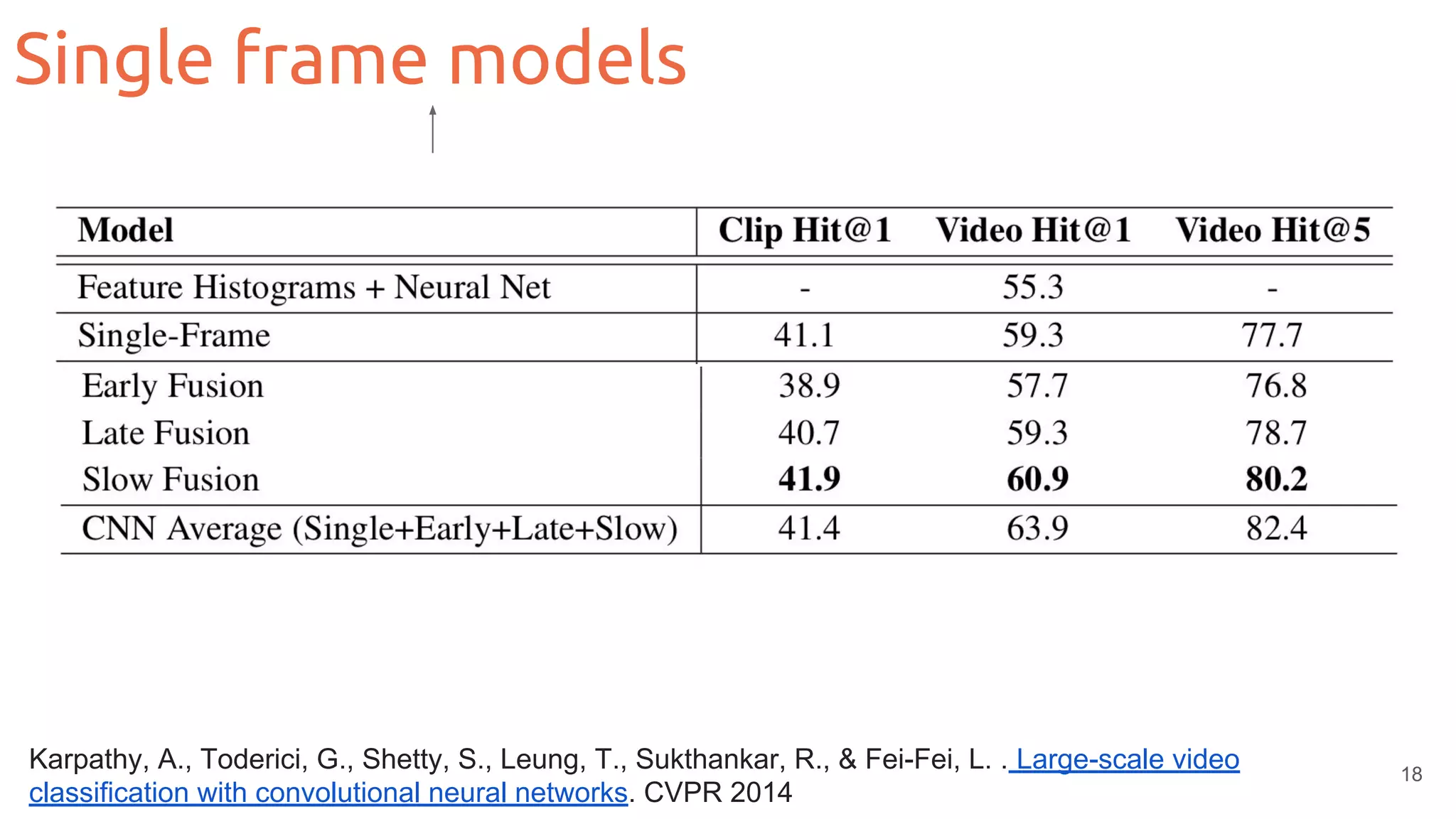

![20
João Carreira, Viorica Pătrăucean, Laurent Mazare, Andrew Zisserman, Simon Osindero, “Massively Parallel Video
Networks” ECCV 2018 [video]
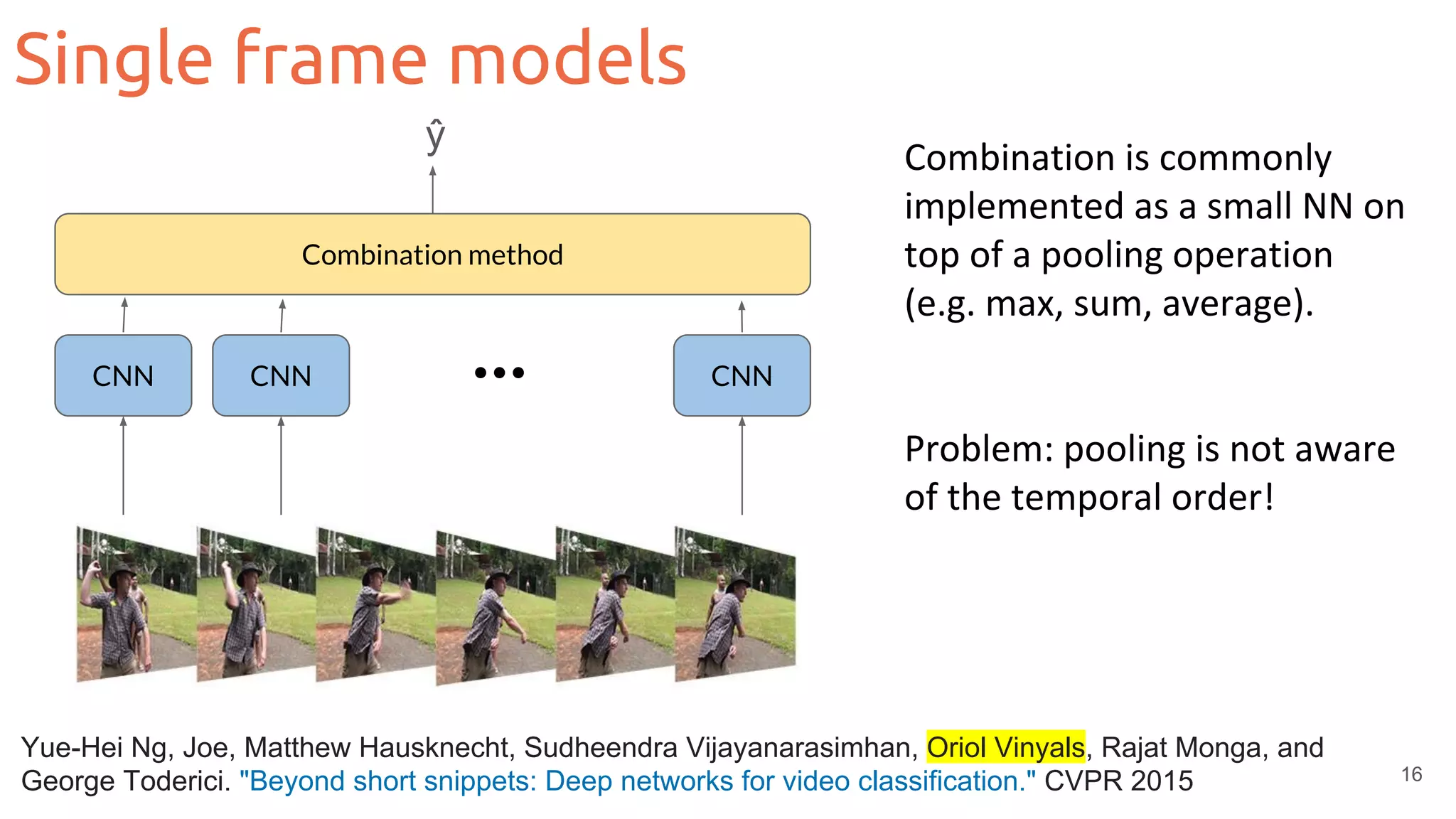
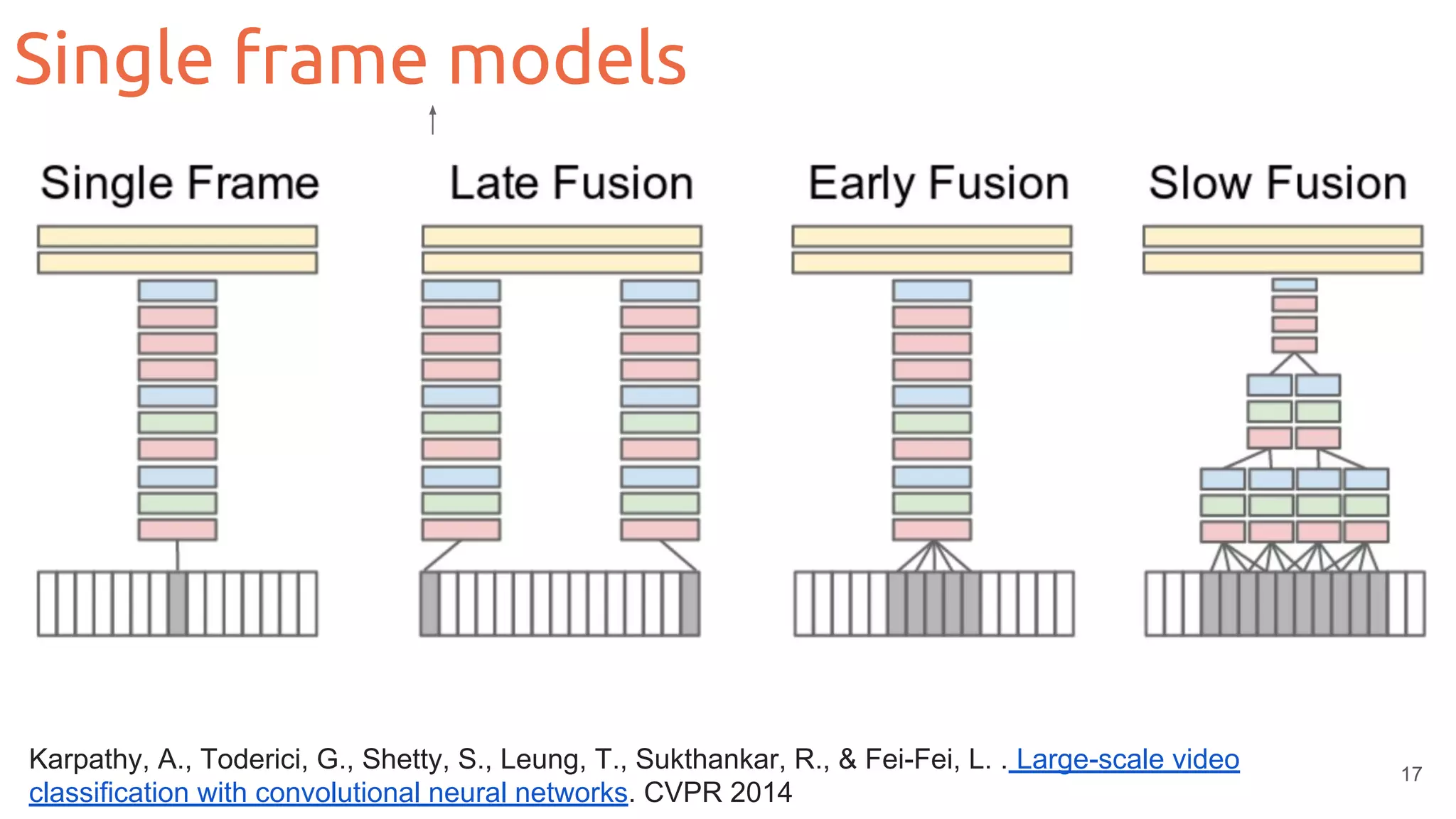
Single frame models: Temporal redundancy](https://image.slidesharecdn.com/mcv-m62019d1l2deeplearningarchitecturesforvideo-190329080335/75/Deep-Learning-Architectures-for-Video-Xavier-Giro-UPC-Barcelona-2019-20-2048.jpg)

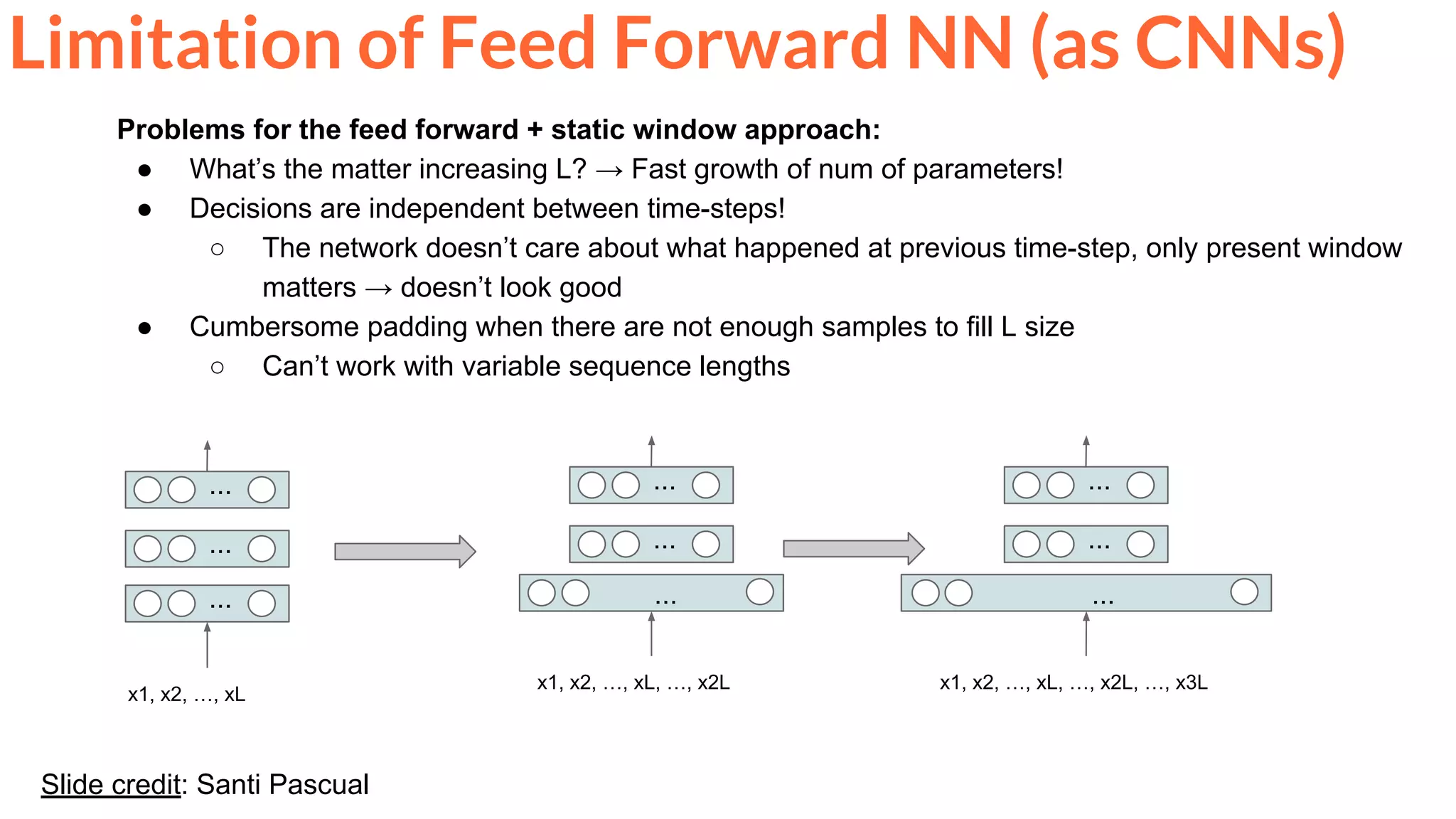
![22Slide credit: Santi Pascual
If we have a sequence of samples...
predict sample x[t+1] knowing previous values {x[t], x[t-1], x[t-2], …, x[t-τ]}
Limitation of Feed Forward NN (as CNNs)](https://image.slidesharecdn.com/mcv-m62019d1l2deeplearningarchitecturesforvideo-190329080335/75/Deep-Learning-Architectures-for-Video-Xavier-Giro-UPC-Barcelona-2019-22-2048.jpg)
![23Slide credit: Santi Pascual
Feed Forward approach:
● static window of size L
● slide the window time-step wise
...
...
...
x[t+1]
x[t-L], …, x[t-1], x[t]
x[t+1]
L
Limitation of Feed Forward NN (as CNNs)](https://image.slidesharecdn.com/mcv-m62019d1l2deeplearningarchitecturesforvideo-190329080335/75/Deep-Learning-Architectures-for-Video-Xavier-Giro-UPC-Barcelona-2019-23-2048.jpg)
![24Slide credit: Santi Pascual
Feed Forward approach:
● static window of size L
● slide the window time-step wise
...
...
...
x[t+2]
x[t-L+1], …, x[t], x[t+1]
...
...
...
x[t+1]
x[t-L], …, x[t-1], x[t]
x[t+2]
L
Limitation of Feed Forward NN (as CNNs)](https://image.slidesharecdn.com/mcv-m62019d1l2deeplearningarchitecturesforvideo-190329080335/75/Deep-Learning-Architectures-for-Video-Xavier-Giro-UPC-Barcelona-2019-24-2048.jpg)
![25Slide credit: Santi Pascual 25
Feed Forward approach:
● static window of size L
● slide the window time-step wise
x[t+3]
L
...
...
...
x[t+3]
x[t-L+2], …, x[t+1], x[t+2]
...
...
...
x[t+2]
x[t-L+1], …, x[t], x[t+1]
...
...
...
x[t+1]
x[t-L], …, x[t-1], x[t]
Limitation of Feed Forward NN (as CNNs)](https://image.slidesharecdn.com/mcv-m62019d1l2deeplearningarchitecturesforvideo-190329080335/75/Deep-Learning-Architectures-for-Video-Xavier-Giro-UPC-Barcelona-2019-25-2048.jpg)
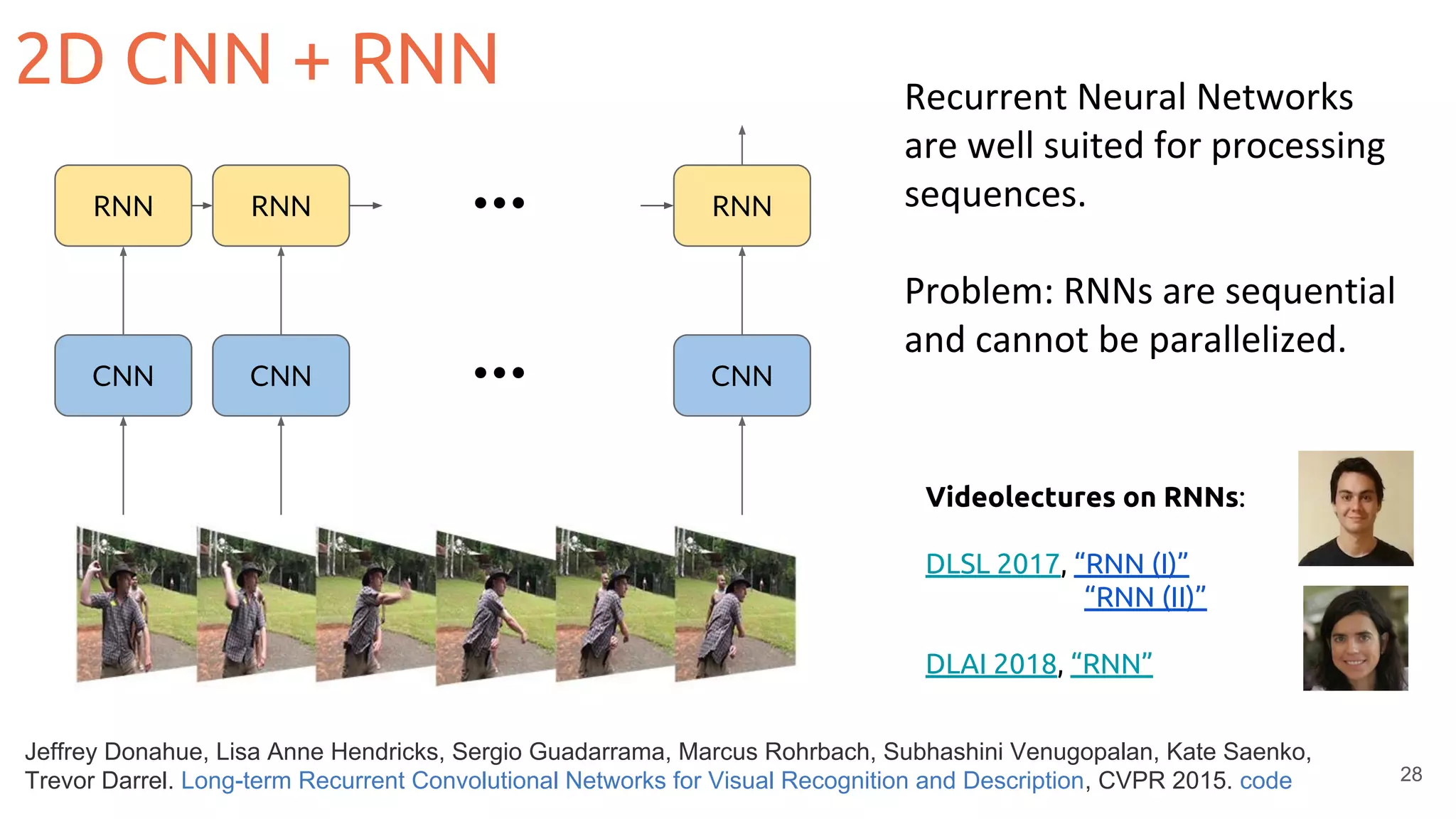
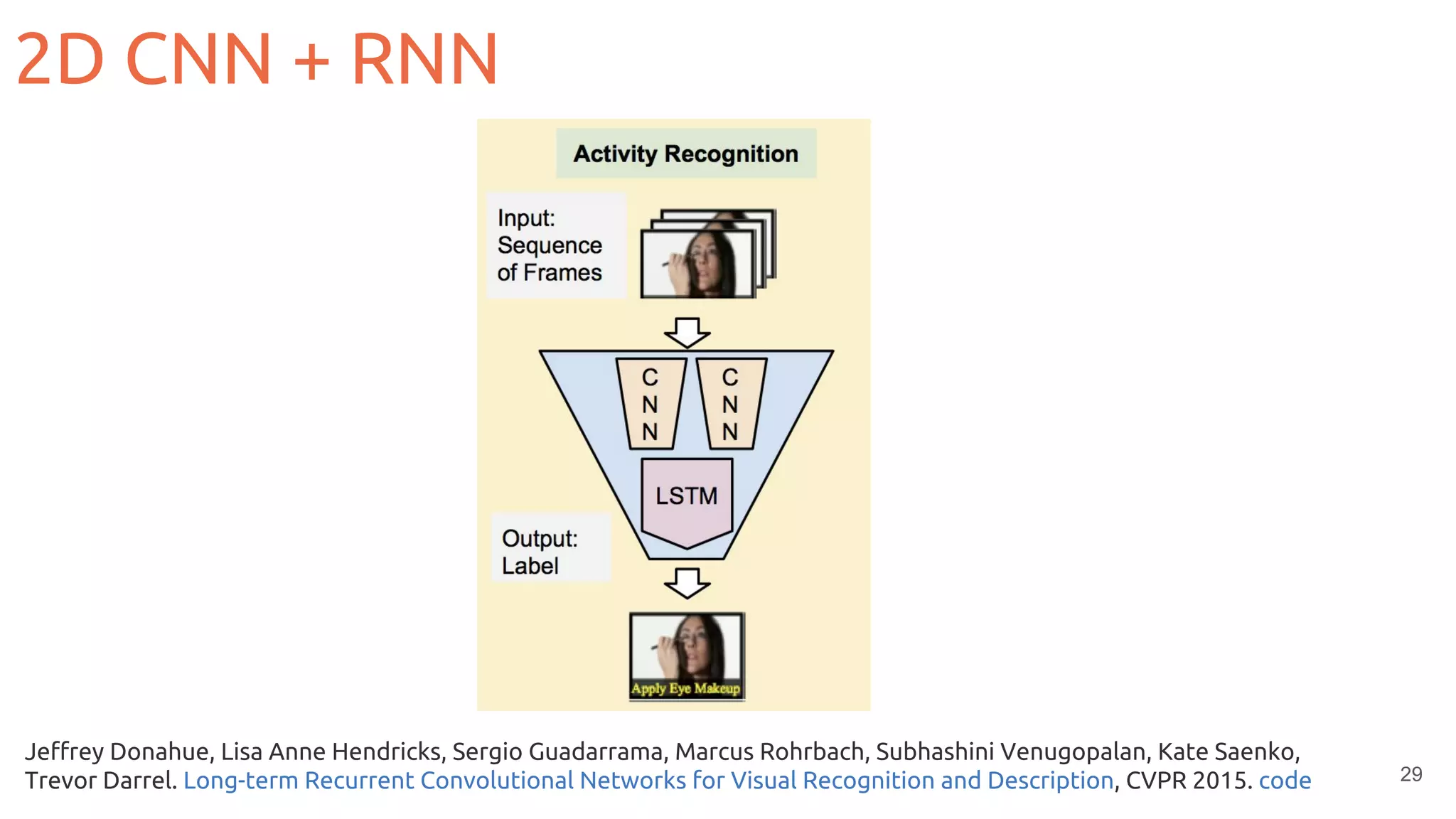
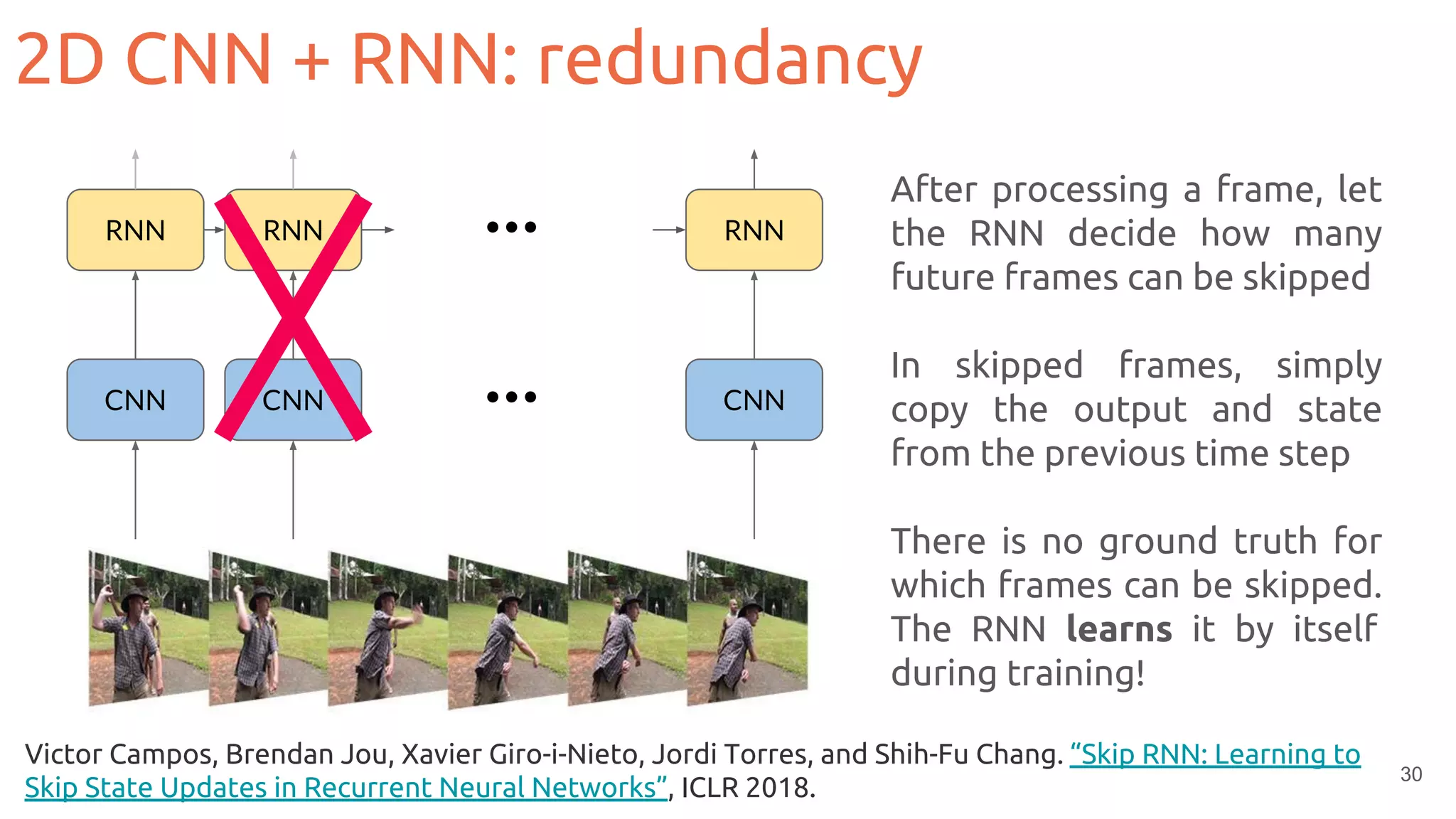

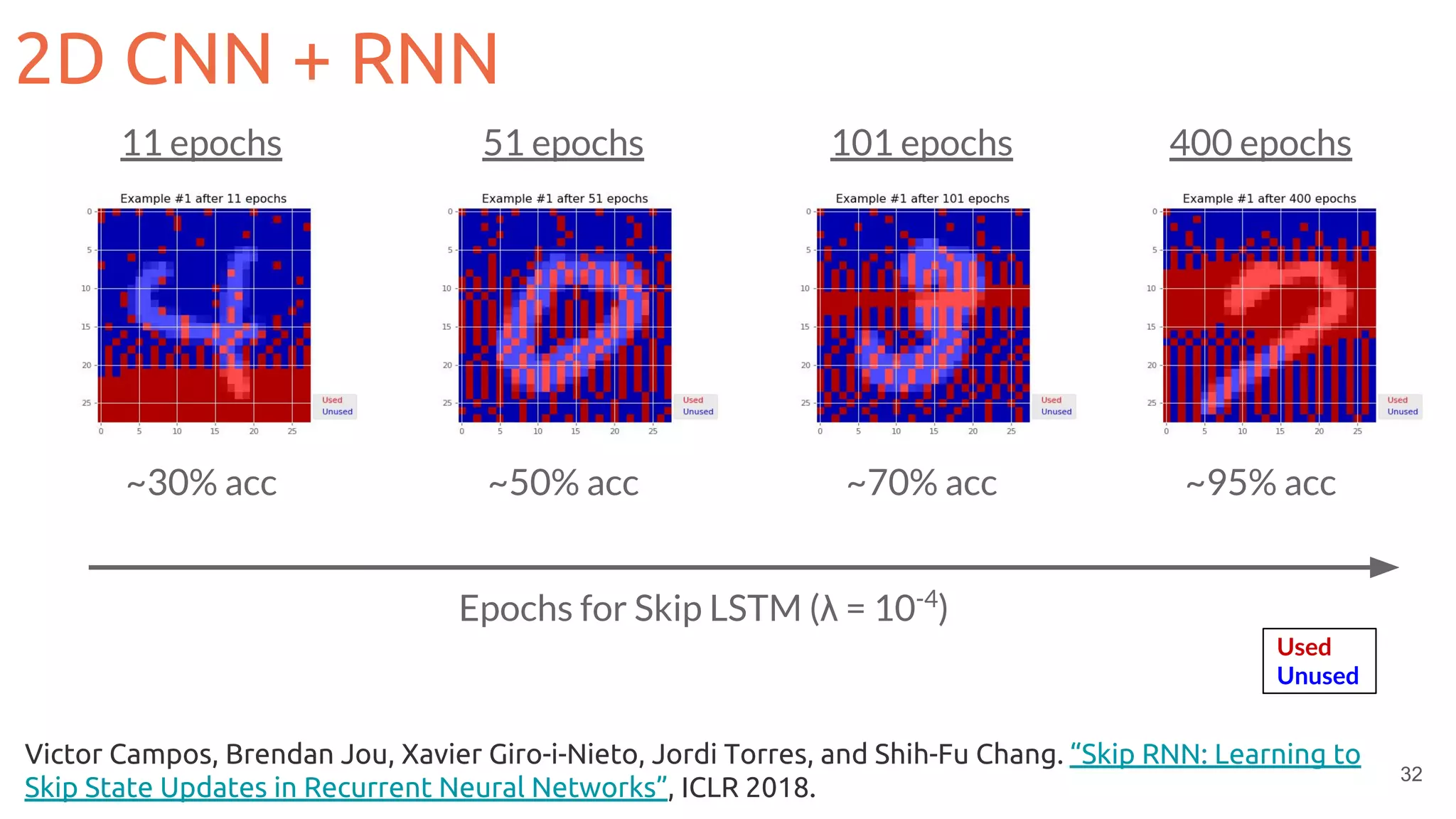


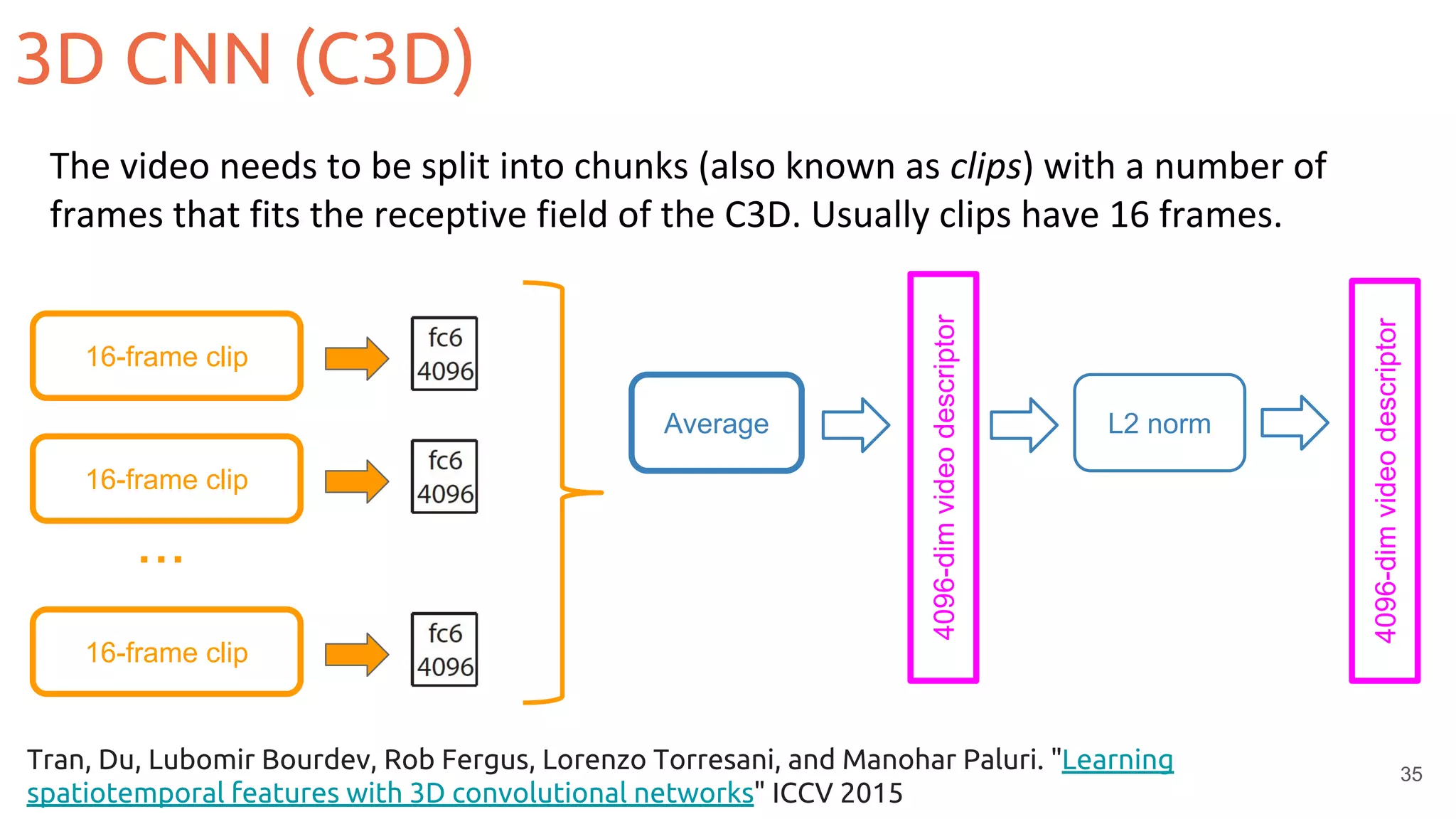
![36
3D convolutions + Residual connections
Tran, Du, Jamie Ray, Zheng Shou, Shih-Fu Chang, and Manohar Paluri. "Convnet architecture search
for spatiotemporal feature learning." arXiv preprint arXiv:1708.05038 (2017). [code]
3D CNN (Res3D)](https://image.slidesharecdn.com/mcv-m62019d1l2deeplearningarchitecturesforvideo-190329080335/75/Deep-Learning-Architectures-for-Video-Xavier-Giro-UPC-Barcelona-2019-36-2048.jpg)





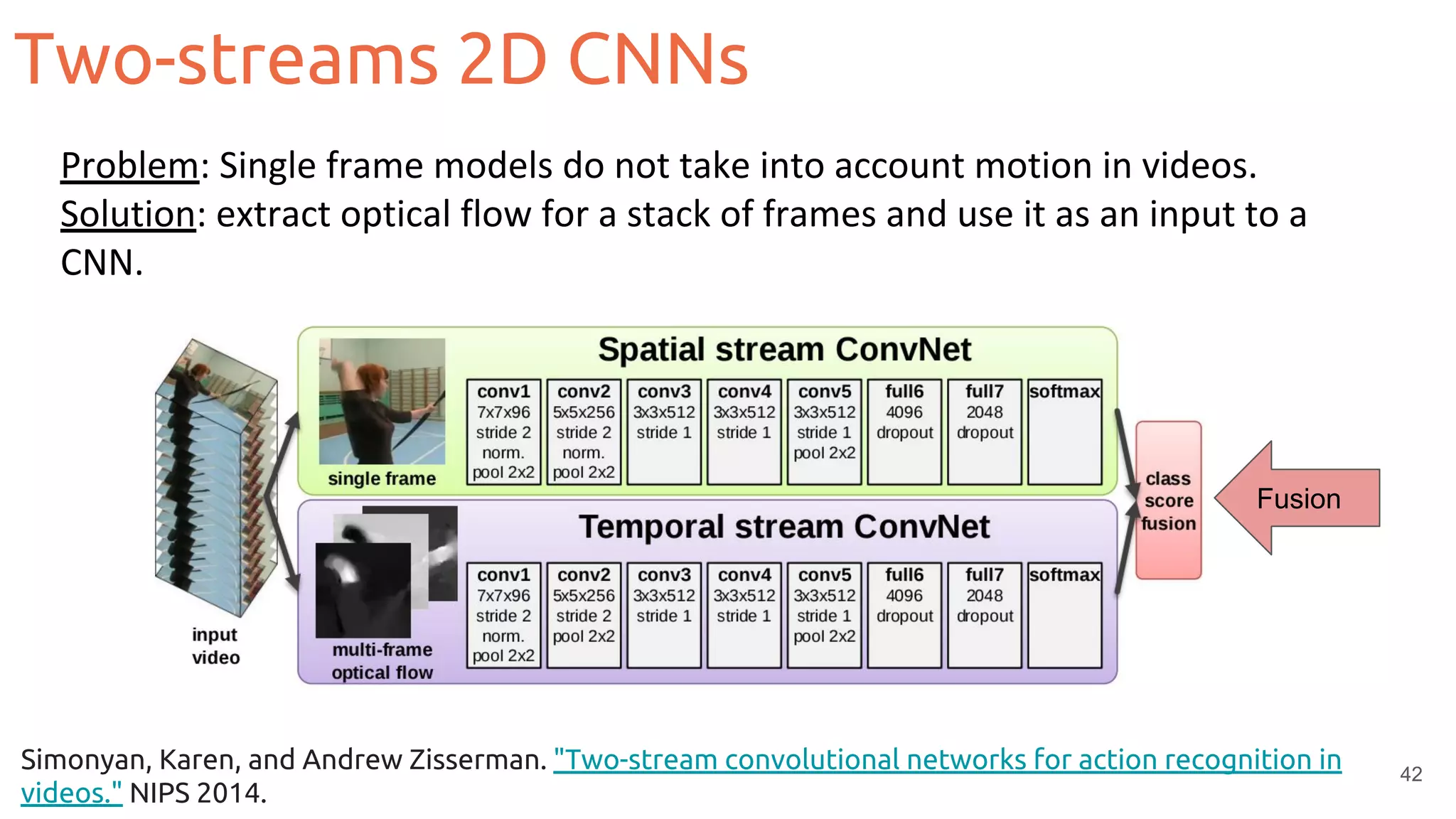
![Two-streams 2D CNNs
43Feichtenhofer, Christoph, Axel Pinz, and Andrew Zisserman. "Convolutional two-stream network fusion for video action
recognition." CVPR 2016. [code]
Fusion
Problem: Single frame models do not take into account motion in videos.
Solution: extract optical flow for a stack of frames and use it as an input to a
CNN.](https://image.slidesharecdn.com/mcv-m62019d1l2deeplearningarchitecturesforvideo-190329080335/75/Deep-Learning-Architectures-for-Video-Xavier-Giro-UPC-Barcelona-2019-43-2048.jpg)
![Two-streams 2D CNNs
44
Feichtenhofer, Christoph, Axel Pinz, and Richard Wildes. "Spatiotemporal residual networks for video action recognition."
NIPS 2016. [code]
Problem: Single frame models do not take into account motion in videos.
Solution: extract optical flow for a stack of frames and use it as an input to a
CNN.](https://image.slidesharecdn.com/mcv-m62019d1l2deeplearningarchitecturesforvideo-190329080335/75/Deep-Learning-Architectures-for-Video-Xavier-Giro-UPC-Barcelona-2019-44-2048.jpg)
![Two-streams 3D CNNs
45
Carreira, J., & Zisserman, A. . Quo vadis, action recognition? A new model and the kinetics dataset. CVPR
2017. [code]](https://image.slidesharecdn.com/mcv-m62019d1l2deeplearningarchitecturesforvideo-190329080335/75/Deep-Learning-Architectures-for-Video-Xavier-Giro-UPC-Barcelona-2019-45-2048.jpg)
![Two-streams 3D CNNs
46
Carreira, J., & Zisserman, A. . Quo vadis, action recognition? A new model and the kinetics dataset. CVPR
2017. [code]](https://image.slidesharecdn.com/mcv-m62019d1l2deeplearningarchitecturesforvideo-190329080335/75/Deep-Learning-Architectures-for-Video-Xavier-Giro-UPC-Barcelona-2019-46-2048.jpg)
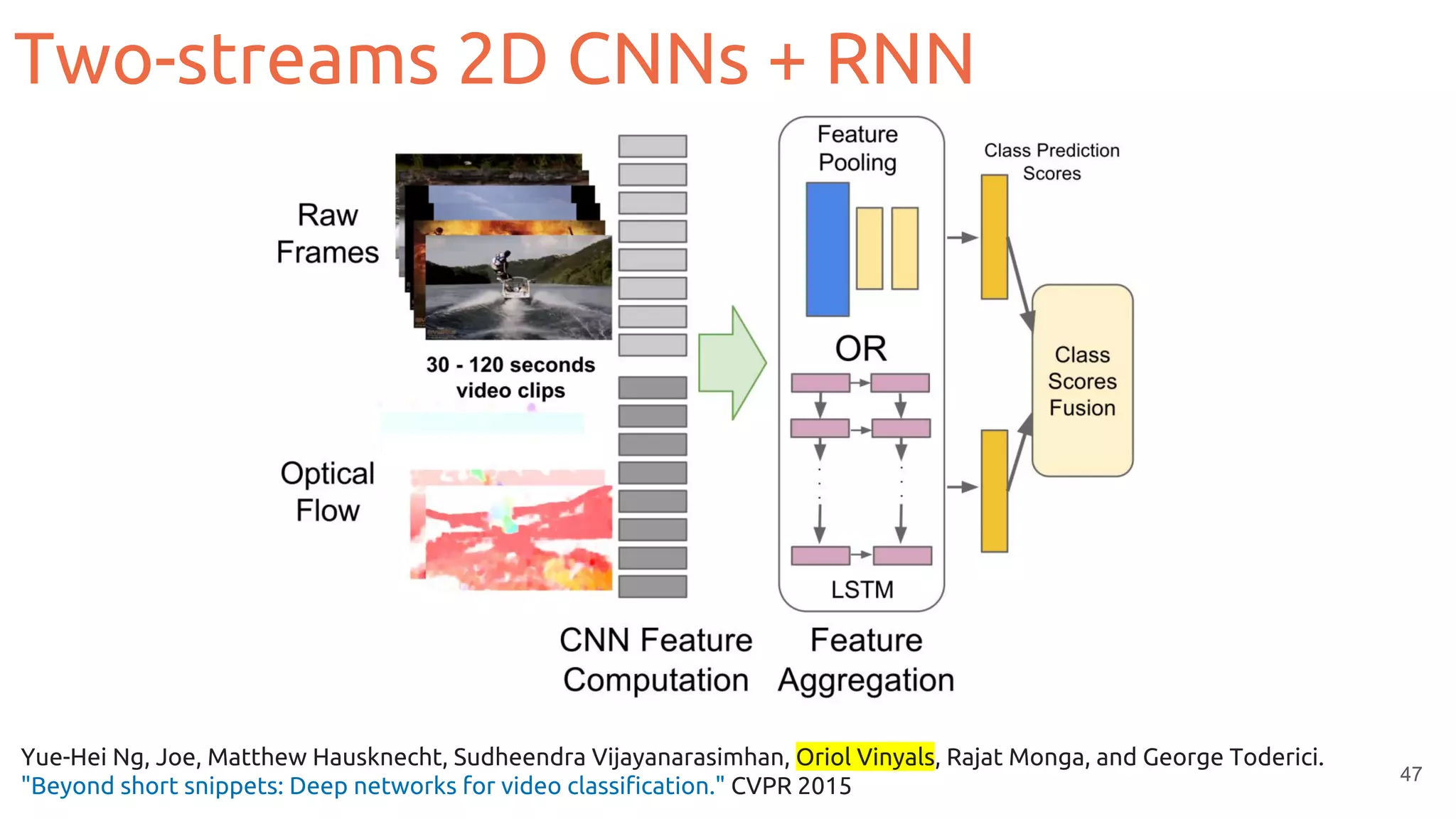





The document outlines various deep learning architectures for video analysis, including single frame models, CNN + RNN, 3D convolutions, and two-stream CNNs. It discusses the challenges of working with video data, such as temporal redundancy, and highlights the importance of efficiently handling large datasets and optimizing memory usage. Additionally, it emphasizes techniques for improving video classification performance and resource management in training deep learning models.































































![[DSC Europe 25] Jovan Bogicevic - Legacy to AI-Driven Defense: Transforming D...](https://cdn.slidesharecdn.com/ss_thumbnails/rsarluadt563hntyfc8q-3-251211083849-3e7bc4c0-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DSC Europe 25] Dunja Adzic Jovanovic - AI and Cybersecurity: Defending Data ...](https://cdn.slidesharecdn.com/ss_thumbnails/o1zylpbhrtwnixxq2xj8-7-251211083048-185086f6-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Behzad Hosseini - AI Agents in the Wild: Deploying Models tha...](https://cdn.slidesharecdn.com/ss_thumbnails/3qtejajvsjqrzwfept2c-10-251212103250-7f2b1068-thumbnail.jpg?width=640&height=640&fit=bounds)





![[DSC Europe 25] Jon Dajci - Bridging TradFi and DeFi: Building the Future of ...](https://cdn.slidesharecdn.com/ss_thumbnails/fqmhfvlbqhkihjvqvhmu-7-251211083849-6af7e325-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Debmalya Biswas - Agentification: the art of transforming man...](https://cdn.slidesharecdn.com/ss_thumbnails/r5azlggvtqiaiiusrqdr-4-251212103249-5a12c89b-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Kaja Kandare - LLM as a judge.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/arxyccaxsdsd1ba99wjw-7-251212104007-2b4e3f64-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Dusan Nesic - Securing Tomorrow’s Infrastructure: Why Cyber-P...](https://cdn.slidesharecdn.com/ss_thumbnails/qikbszfftyowjm2q6duw-1-251211083848-8f2ead6b-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DSC Europe 25] Branko Dzakula - From Defense to Attack: How AI Redefines Cyb...](https://cdn.slidesharecdn.com/ss_thumbnails/80bdzdxpr3ky2g0qvyk9-8-251211083048-ce5fc1ee-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Katherine Forrest - AI NOW: Understanding the Velocity of Cha...](https://cdn.slidesharecdn.com/ss_thumbnails/wvvbruqfrci0sfq9xwgb-4-251212104007-e5ad1987-thumbnail.jpg?width=640&height=640&fit=bounds)