Download as PDF, PPTX






![Outline
Introduction
Framework Overview
Experimental Conditions
Results and Analysis
Conclusions and Future Work
Motion-Based Person Detector
We use a state-of-the-art motion-based tracker [6]:
Each pixel modelled as a mixture of Gaussians in RGB space
Background model to](https://image.slidesharecdn.com/iwaal2014fengslides-141215073354-conversion-gate02/85/A-Multiple-Kernel-Learning-Based-Fusion-Framework-for-Real-Time-Multi-View-Action-Recognition-6-320.jpg)


![Outline
Introduction
Framework Overview
Experimental Conditions
Results and Analysis
Conclusions and Future Work
Feature Representation of Videos
Use of STIP and improved dense trajectories (IDT) [7] as
local descriptor to extract visual features from a video
Person detections and frame spans to de](https://image.slidesharecdn.com/iwaal2014fengslides-141215073354-conversion-gate02/85/A-Multiple-Kernel-Learning-Based-Fusion-Framework-for-Real-Time-Multi-View-Action-Recognition-9-320.jpg)




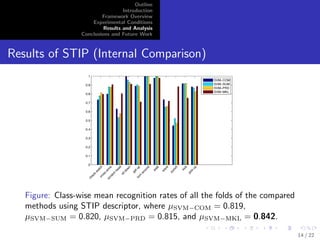
![Outline
Introduction
Framework Overview
Experimental Conditions
Results and Analysis
Conclusions and Future Work
Simple Fusion Strategies
Ki1i
Concantenation of Features: concatenate the feature
vectors of multiple views into one single feature vector such
that ~xi = [x; : : : ; x]
Sum of Classi](https://image.slidesharecdn.com/iwaal2014fengslides-141215073354-conversion-gate02/85/A-Multiple-Kernel-Learning-Based-Fusion-Framework-for-Real-Time-Multi-View-Action-Recognition-15-320.jpg)
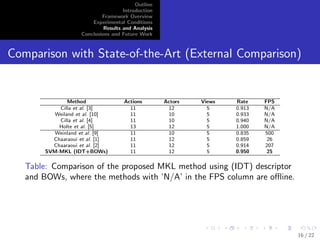







The document presents a multi-kernel learning (MKL) framework for real-time multi-view action recognition, highlighting its efficacy in improving performance compared to simpler fusion techniques. It provides detailed methodology including feature extraction, classification using SVMs, and evaluation on a specific multi-view dataset. Results demonstrate that the proposed MKL framework achieves higher classification rates than existing state-of-the-art methods, suggesting its potential for broader applications in action recognition.




![Deformable DETR Review [CDM]](https://cdn.slidesharecdn.com/ss_thumbnails/deformabledetrreviewcdm-201113070345-thumbnail.jpg?width=640&height=640&fit=bounds)
















![[Review] BoxInst: High-Performance Instance Segmentation with Box Annotations...](https://cdn.slidesharecdn.com/ss_thumbnails/boxinstreviewcdm-210627063153-thumbnail.jpg?width=640&height=640&fit=bounds)

















































































