Download as PDF, PPTX
![[course site]
Xavier Giro-i-Nieto
xavier.giro@upc.edu
Associate Professor
Universitat Politecnica de Catalunya
Technical University of Catalonia
Video Analysis
Day 2 Lecture 2
#DLUPC](https://image.slidesharecdn.com/dlcv2017d4l2videoanalysis-170627133055/85/Video-Analysis-D4L2-2017-UPC-Deep-Learning-for-Computer-Vision-1-320.jpg)




![6
(Slides by Dídac Surís) Abu-El-Haija, Sami, Nisarg Kothari, Joonseok Lee, Paul Natsev, George Toderici, Balakrishnan Varadarajan, and Sudheendra
Vijayanarasimhan. "Youtube-8m: A large-scale video classification benchmark." arXiv preprint arXiv:1609.08675 (2016). [project]
Activity Recognition: Datasets](https://image.slidesharecdn.com/dlcv2017d4l2videoanalysis-170627133055/85/Video-Analysis-D4L2-2017-UPC-Deep-Learning-for-Computer-Vision-6-320.jpg)









![19Feichtenhofer, Christoph, Axel Pinz, and Andrew Zisserman. "Convolutional two-stream network fusion for video action recognition." CVPR 2016. [code]
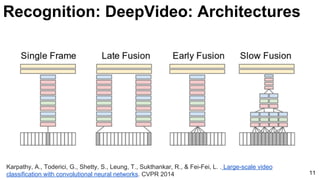
Recognition: Two stream
Two CNNs in paralel:
● One for RGB images
● One for Optical flow (hand-crafted features)
Fusion at a convolutional layer](https://image.slidesharecdn.com/dlcv2017d4l2videoanalysis-170627133055/85/Video-Analysis-D4L2-2017-UPC-Deep-Learning-for-Computer-Vision-19-320.jpg)































![Object tracking: FCNT
60
Wang, Lijun, Wanli Ouyang, Xiaogang Wang, and Huchuan Lu. "Visual Tracking with Fully Convolutional Networks." ICCV 2015 [code]](https://image.slidesharecdn.com/dlcv2017d4l2videoanalysis-170627133055/85/Video-Analysis-D4L2-2017-UPC-Deep-Learning-for-Computer-Vision-60-320.jpg)
![Object tracking: FCNT
61
Wang, Lijun, Wanli Ouyang, Xiaogang Wang, and Huchuan Lu. "Visual Tracking with Fully Convolutional Networks." CVPR 2015 [code]
Focus on conv4-3 and conv5-3 of VGG-16 network pre-trained for ImageNet image classification.
conv4-3 conv5-3](https://image.slidesharecdn.com/dlcv2017d4l2videoanalysis-170627133055/85/Video-Analysis-D4L2-2017-UPC-Deep-Learning-for-Computer-Vision-61-320.jpg)
![Object tracking: FCNT: Specialization
62
Wang, Lijun, Wanli Ouyang, Xiaogang Wang, and Huchuan Lu. "Visual Tracking with Fully Convolutional Networks." In Proceedings of the IEEE
International Conference on Computer Vision, pp. 3119-3127. 2015 [code]
Most feature maps in VGG-16 conv4-3 and conv5-3 are not related to the foreground regions in a tracking
sequence.](https://image.slidesharecdn.com/dlcv2017d4l2videoanalysis-170627133055/85/Video-Analysis-D4L2-2017-UPC-Deep-Learning-for-Computer-Vision-62-320.jpg)
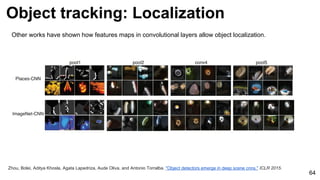
![Object tracking: FCNT: Localization
63
Wang, Lijun, Wanli Ouyang, Xiaogang Wang, and Huchuan Lu. "Visual Tracking with Fully Convolutional Networks." In Proceedings of the IEEE
International Conference on Computer Vision, pp. 3119-3127. 2015 [code]
Although trained for image classification, feature maps in conv5-3 enable object localization…
...but is not discriminative enough to different objects of the same category.](https://image.slidesharecdn.com/dlcv2017d4l2videoanalysis-170627133055/85/Video-Analysis-D4L2-2017-UPC-Deep-Learning-for-Computer-Vision-63-320.jpg)
![Object tracking: FCNT: Localization
65
Wang, Lijun, Wanli Ouyang, Xiaogang Wang, and Huchuan Lu. "Visual Tracking with Fully Convolutional Networks." In Proceedings of the IEEE
International Conference on Computer Vision, pp. 3119-3127. 2015 [code]
On the other hand, feature maps from conv4-3 are more sensitive to intra-class appearance variation…
conv4-3 conv5-3](https://image.slidesharecdn.com/dlcv2017d4l2videoanalysis-170627133055/85/Video-Analysis-D4L2-2017-UPC-Deep-Learning-for-Computer-Vision-65-320.jpg)
![Object tracking: FCNT: Architecture
66
Wang, Lijun, Wanli Ouyang, Xiaogang Wang, and Huchuan Lu. "Visual Tracking with Fully Convolutional Networks." In Proceedings of the IEEE
International Conference on Computer Vision, pp. 3119-3127. 2015 [code]
SNet=Specific Network (online update)
GNet=General Network (fixed)](https://image.slidesharecdn.com/dlcv2017d4l2videoanalysis-170627133055/85/Video-Analysis-D4L2-2017-UPC-Deep-Learning-for-Computer-Vision-66-320.jpg)
![Object tracking: FCNT: Results
67
Wang, Lijun, Wanli Ouyang, Xiaogang Wang, and Huchuan Lu. "Visual Tracking with Fully Convolutional Networks." In Proceedings of the IEEE
International Conference on Computer Vision, pp. 3119-3127. 2015 [code]](https://image.slidesharecdn.com/dlcv2017d4l2videoanalysis-170627133055/85/Video-Analysis-D4L2-2017-UPC-Deep-Learning-for-Computer-Vision-67-320.jpg)


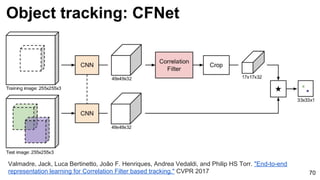


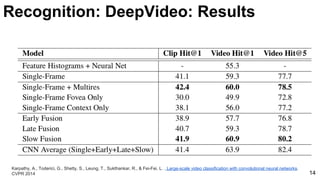
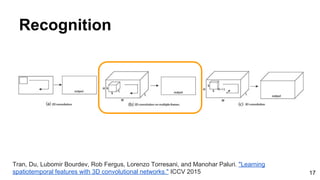
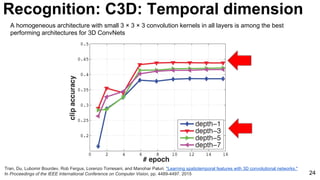
The document provides an overview of video analysis techniques including recognition, optical flow, and object tracking. For recognition, it discusses approaches using convolutional neural networks like DeepVideo that perform classification on frames. It also covers models using optical flow as input like two-stream networks as well as 3D CNNs like C3D that directly learn spatiotemporal features. For optical flow, it summarizes FlowNet which uses a CNN to learn optical flow end-to-end. And for object tracking, it mentions deep learning methods like MDNet that train domain-specific layers to generalize across sequences.
































































![[DSC Europe 25] Danilo Djukanovic - From Vibes to KPIs: Turning Culture Into ...](https://cdn.slidesharecdn.com/ss_thumbnails/inqestws5wf0cik2glgv-3-danilo-djukanovic-from-vibes-to-kpis-presentation-260114111931-dacff81f-thumbnail.jpg?width=640&height=640&fit=bounds)


















![[DSC Europe 25] Stefan Brankovic - #ResumeIsDead. AI-Powered Interviews and C...](https://cdn.slidesharecdn.com/ss_thumbnails/qnmbsv0xq3uysdrq3sev-2-stefan-brankovic-job-bolt-260114111931-a065aa3d-thumbnail.jpg?width=640&height=640&fit=bounds)