Downloaded 1,486 times



















































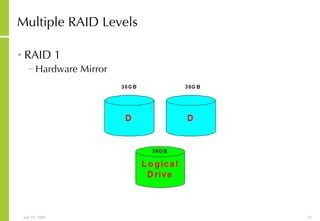
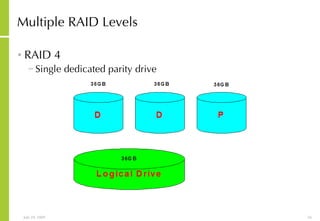
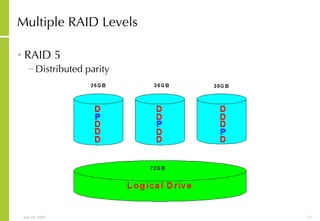
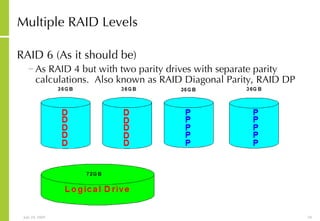





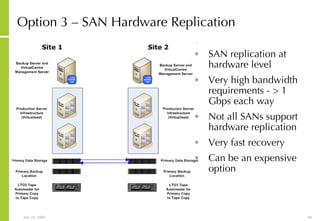
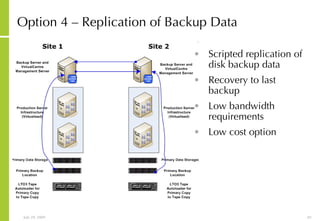

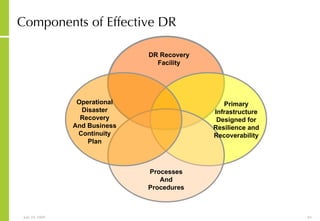








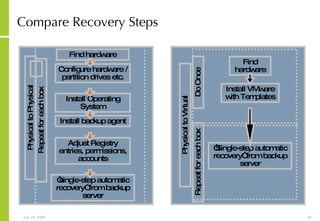






































































![More Information Alan McSweeney [email_address]](https://image.slidesharecdn.com/storagesanandbusinesscontinuityoverview-090729043721-phpapp01/85/Storage-San-And-Business-Continuity-Overview-237-320.jpg)

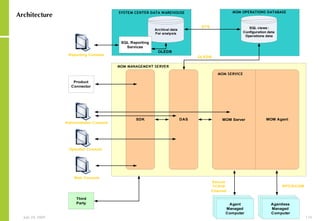
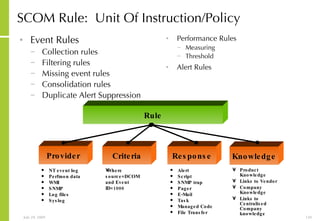
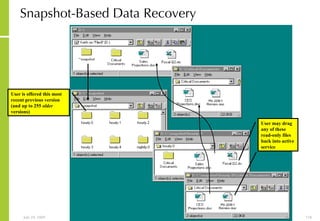
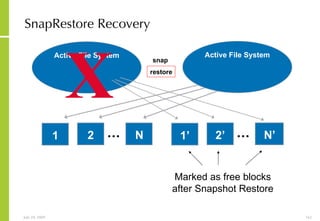
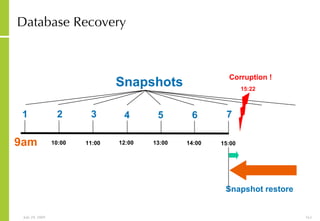
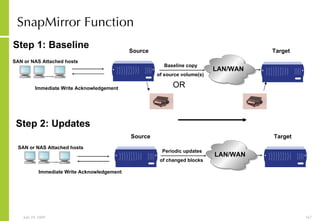
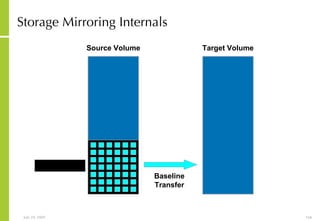
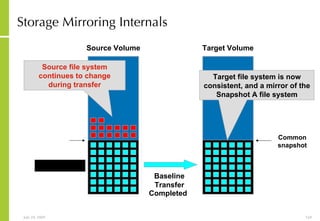
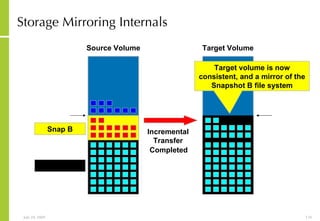
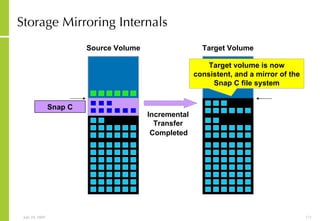
The document provides an overview of storage systems and business continuity options. It discusses various types of storage including DAS, NAS and SAN. It then covers business continuity and disaster recovery strategies like replication, snapshots and mirroring. It also discusses how server virtualization can help improve disaster recovery.











































































































