Download as PDF, PPTX


























![Data Integration Specification
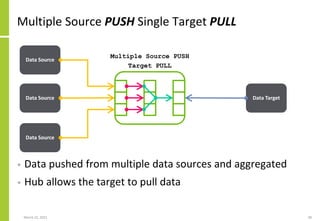
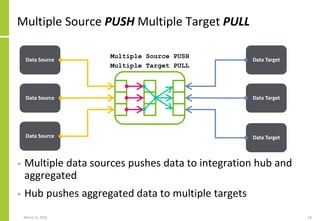
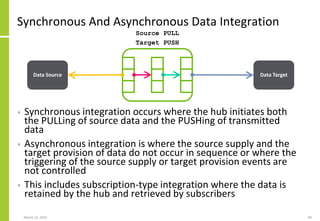
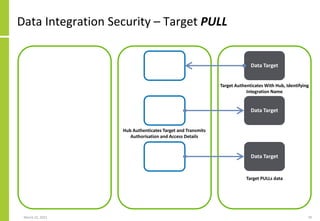
• Data integration can be logically specified as follows
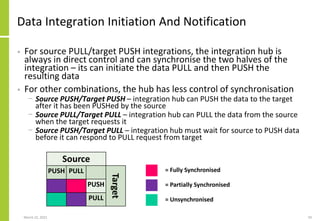
{Integration{Name, Attributes}
Sources
{Source1,TechnologyType,Direction,Attributes}
{Source2,TechnologyType,Direction,Attributes}
{…}
}
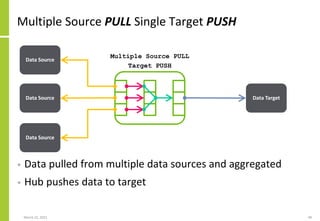
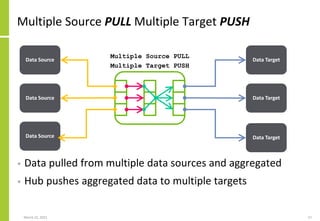
{Transformation
{Name, Attributes}
Steps
{Step1,<Processing>}
{Step2,<Processing>}
[…]
}
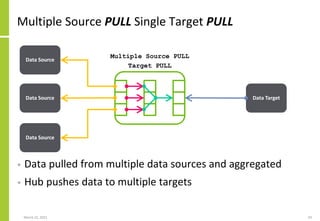
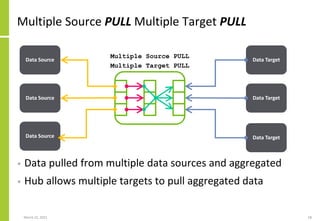
Targets
{Target1,TechnologyType,Direction,Attributes}
{Target2,TechnologyType,Direction,Attributes}
{…}
}
March 22, 2021 73
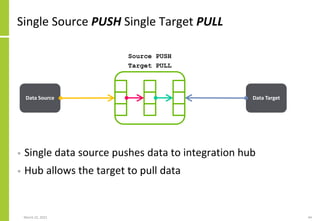
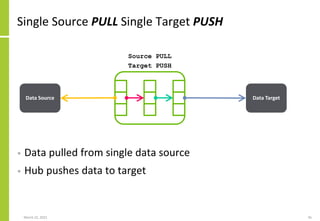
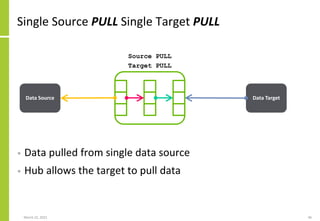
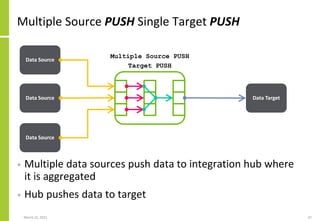
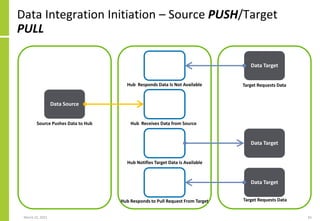
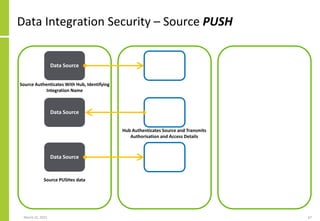
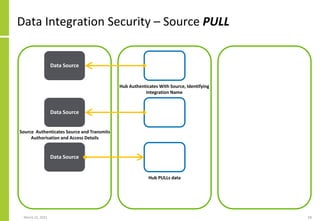
Set of data sources, the mechanisms
by which data is transferred, the
transfer direction (PUSH/PULL) and
the extended integration attributes
The transformation performed on
the source data to create the data
sent to or made available to the
target
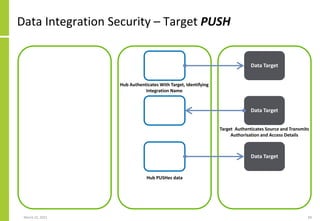
Set of data targets, the mechanisms
by which data is transferred, the
transfer direction (PUSH/PULL) and
the extended integration attributes
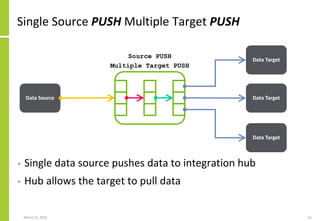
Overall integration identifier and
attributes](https://image.slidesharecdn.com/dataintegrationaccessflowexchangetransferloadandextractarchitecture-210323082255/85/Data-Integration-Access-Flow-Exchange-Transfer-Load-And-Extract-Architecture-73-320.jpg)


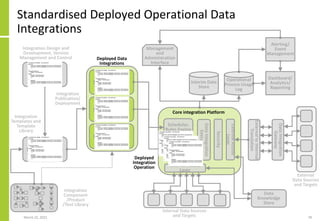



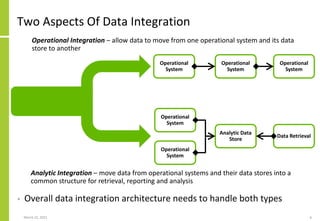
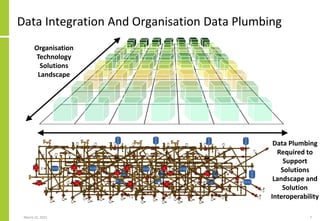
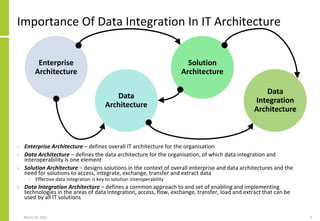
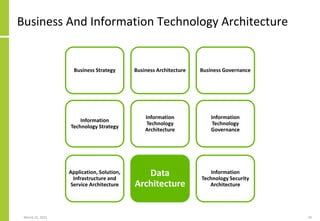
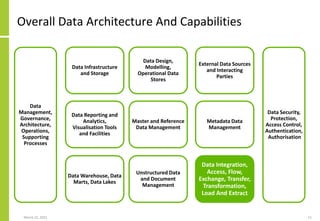
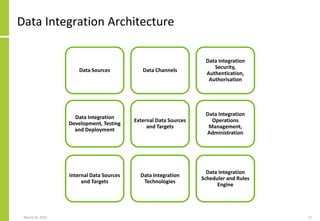
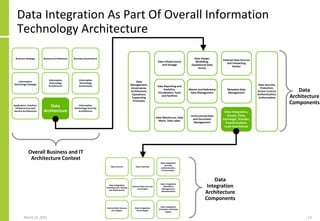
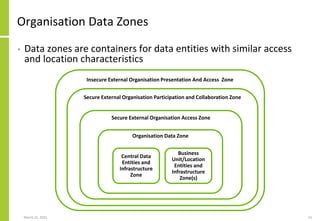
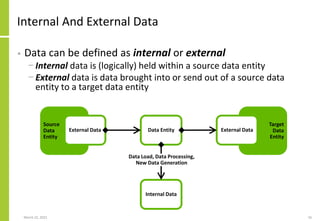
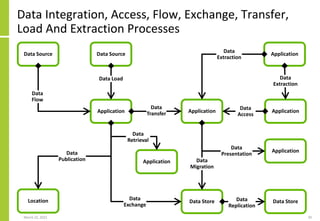
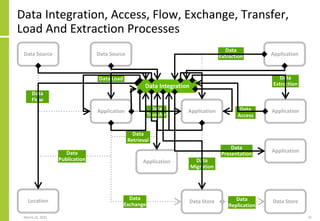
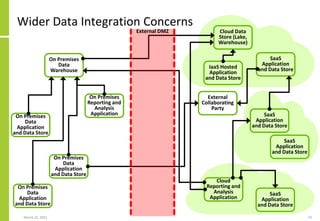
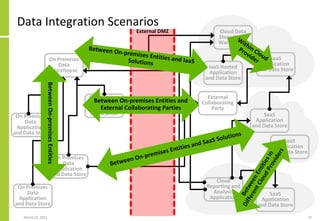
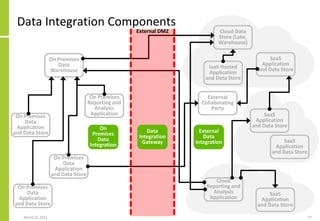
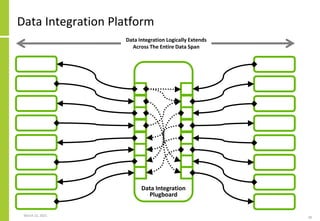
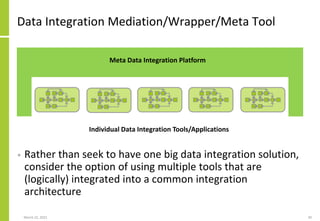
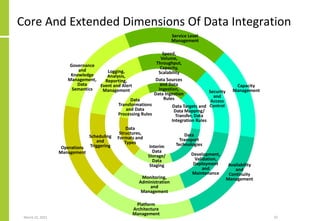
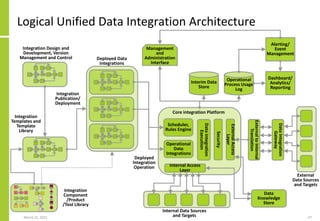
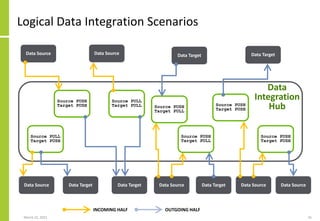
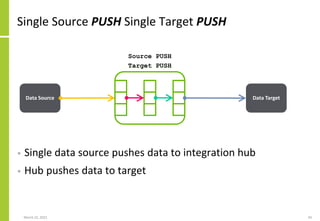
The document discusses the architecture and importance of data integration in organizations, emphasizing its role in enabling effective data flow, exchange, and interoperability across various data landscapes. It highlights the evolution and current state of data integration, identifying challenges such as inconsistent integration approaches and the complexity of managing multiple data sources. The text also outlines the architectural components and characteristics necessary for a robust data integration framework, as well as trends and issues affecting data integration in an increasingly cloud-centric environment.








































![[DSC Europe 24] Josip Saban - Buidling cloud data platforms in enterprises](https://cdn.slidesharecdn.com/ss_thumbnails/josipsaban-buidlingclouddataplatformsinenterprises-250217194546-5568421d-thumbnail.jpg?width=640&height=640&fit=bounds)







































![[DSC Europe 25] Josip Saban - Career building for data professionals.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/zroflcttkm1vmli0txea-josip-saban-career-building-for-data-professionals-260123083019-587cdb8c-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DSC Europe 25] Tamas Srancsik - How To Teach Your AI Football? An Argument f...](https://cdn.slidesharecdn.com/ss_thumbnails/bcjh1m9xtbosv20ucftb-tamas-srancsik-how-to-teach-your-ai-football-260121115910-08b53e9e-thumbnail.jpg?width=640&height=640&fit=bounds)




![[DSC Europe 25] Jovan Sumarac - Real-World Applications of Computer Vision in...](https://cdn.slidesharecdn.com/ss_thumbnails/fiksms22smcpopvvld03-jovan-sumarac-real-life-applications-of-computer-vision-in-automotive-systems-260120105855-de622abb-thumbnail.jpg?width=640&height=640&fit=bounds)