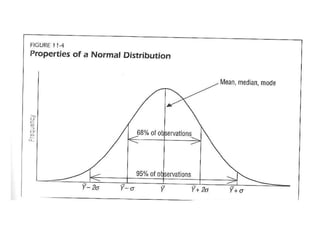
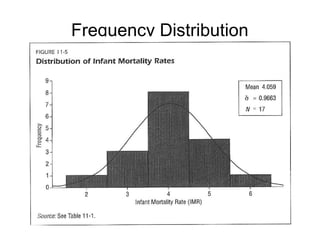
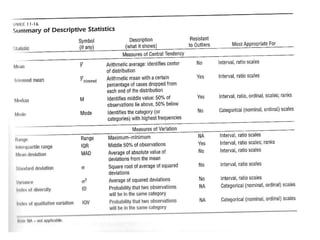
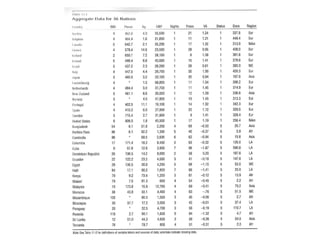
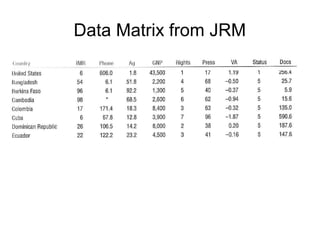
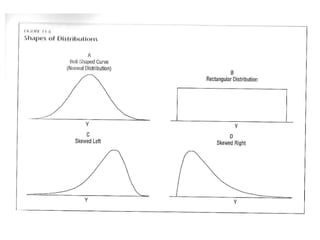
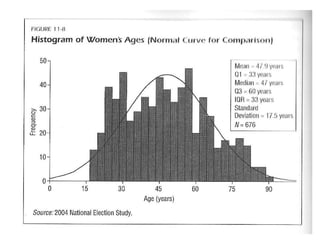
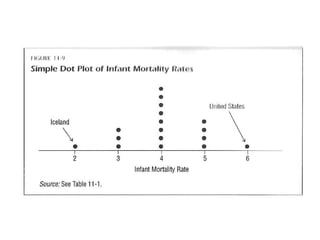
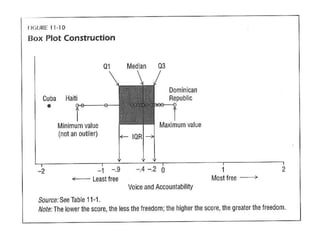
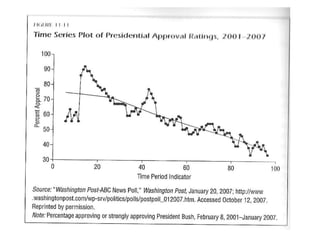
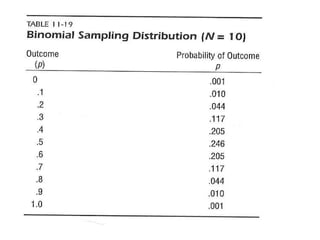
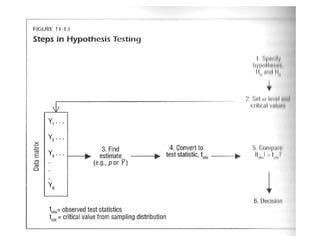
The document provides an overview of key statistical concepts including variance, standard deviation, the normal distribution, frequency distributions, data matrices, hypothesis testing, and point and interval estimation. Variance and standard deviation are measures of how dispersed data points are around the mean. The normal distribution is symmetric and bell-shaped. Hypothesis testing involves specifying a null hypothesis, alternative hypothesis, test statistic, decision rule, and critical region to determine whether to reject the null hypothesis. Point and interval estimation aims to estimate population parameters from samples and provide confidence intervals.
















































![[David m. kreps]_game_theory_and_economic_modellin(b-ok.org)](https://cdn.slidesharecdn.com/ss_thumbnails/davidm-180602005301-thumbnail.jpg?width=640&height=640&fit=bounds)











































































![Getting Started with Apache Spark: Big Data Made Simple [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/apachesparkgettingstarted-260203175547-8361bcc3-thumbnail.jpg?width=640&height=640&fit=bounds)















