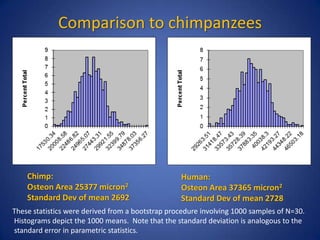
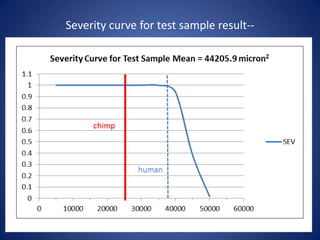
The document outlines a histomorphometric test protocol to distinguish between human and non-human skeletal remains through the measurement of osteon area. It emphasizes the statistical methodology needed for validation of results, comparing human data with chimpanzee data to demonstrate the test's effectiveness. The results show that the test can reliably identify human remains without erroneous results, even when small sample sizes are used.



![Histomorphology as a solution
• Some patterns are
decisively nonhuman
(e.g. plexiform bone)
• Presence of primary and
secondary osteons is a
hallmark of human
bone, but not unique
• This allows us to REJECT
human as the origin, but
not ACCEPT!
[Note the assymmetry]](https://image.slidesharecdn.com/byrd-statisticalconsiderationsofthehistomorphometrictestprotocol1-140328112215-phpapp01/85/Byrd-statistical-considerations-of-the-histomorphometric-test-protocol-1-3-320.jpg)