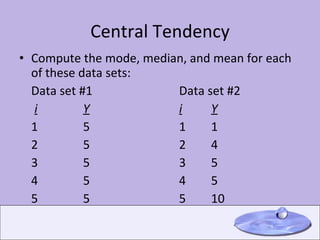
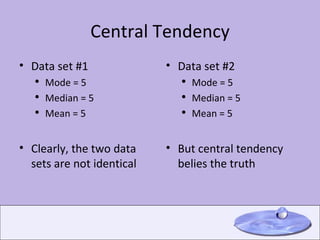
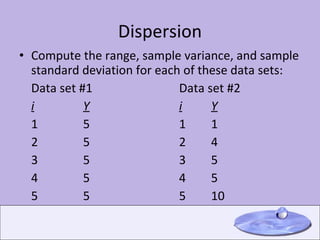
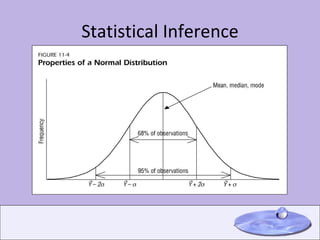
This document provides an overview of key concepts in descriptive statistics including measures of central tendency (mode, median, mean), measures of dispersion (range, variance, standard deviation), the normal distribution, z-scores, hypothesis testing, and the t-distribution. It defines each concept and provides examples of calculating and interpreting common statistics.