27
データ構造を SoA に
例
structdata {
int a, b, c;
double x, y, z;
} d_ary[SIZE]; // AoS
int a[SIZE], b[SIZE], c[SIZE];
double x[SIZE], y[SIZE], z[SIZE]; //SoA
30
ストリップマイニング
以下のコードを考える
for (int i= 0; i < SIZE; ++i) {
hoge(A[i]);
}
for (int i = 0; i < SIZE; ++i) {
fuga(A[i]);
}
配列 A が十分長いとき、最初のループが終わった時点で、
A の先頭はキャッシュから排出されている
51
C 言語でのビット演算
// ビット演算は整数型に対してのみ使える
A= B & C;
A &= B;
A = B << 4; // 下位ビットには 0 が詰められる
A <<= 4;
A = ~B;
// 符号なし 64 ビットリテラルを扱うとき
A = UINT64_C(0xCCCCCCCCCCCCCCCC);
64
立っている一番下のビットを中心に操作
A & (A– 1); // 立っている一番下のビットをクリア
A ^ -A; // 立っている一番下のビットより上の桁を 1 に
A | -A; // さらに立っている一番下のビットも 1 に
// 立っている一番下のビットより下の桁を 1 に
A ^ (A – 1)
65.
65
立っているビット列を走査する
// i &=i-1 で i の立っている一番下のビットをクリア
for (uint64_t i = bits; i != 0; i &= i-1) {
uint64_t rmb = i & -i;
// 何らかの処理
}
立っているビットの数が少ない場合には、この方法でも
立っているビットの数を高速に数えられる















![15
最適化手法を学ぶには
「インテル ® 64 アーキテクチャー および IA-32 アーキ
テクチャー 最適化リフ レンス マニュアル」 [0][1] を読め
(完)](https://image.slidesharecdn.com/optimizationtechniqueswww-150315103212-conversion-gate01/75/slide-15-2048.jpg)
![16
最適化手法を学ぶには
「インテル ® 64 アーキテクチャー および IA-32 アーキ
テクチャー 最適化リフ レンス マニュアル」 [0][1] を読め
(完)
PDF ファイルをインテルの公式サイトからダウンロード
できます
日本語訳もあるけどちょっと古い
700 ページ以上の超大作](https://image.slidesharecdn.com/optimizationtechniqueswww-150315103212-conversion-gate01/75/slide-16-2048.jpg)







![24
局所的でないメモリアクセスを避ける
局所的でないメモリアクセスをすると、アクセスする
データがキャッシュに乗っている確率が低くなる
例 ) 行列積
for (int i = 0; i < ROWS; ++i)
for (int j = 0; j < COLS; ++j)
for (int k = 0; k < LEN; ++k)
C[i][j] += A[i][k] * B[k][j];
二次元配列 B に ROWS 要素飛びでアクセスしている](https://image.slidesharecdn.com/optimizationtechniqueswww-150315103212-conversion-gate01/75/slide-24-2048.jpg)
![25
局所的でないメモリアクセスを避ける
局所的でないメモリアクセスをすると、アクセスする
データがキャッシュに乗っている確率が低くなる
例 ) 行列積
for (int i = 0; i < ROWS; ++i)
for (int k = 0; k < LEN; ++k)
for (int j = 0; j < COLS; ++j)
C[i][j] += A[i][k] * B[k][j];
全ての配列に順番にアクセスするようになった
入れ替えた](https://image.slidesharecdn.com/optimizationtechniqueswww-150315103212-conversion-gate01/75/slide-25-2048.jpg)

![27
データ構造を SoA に
例
struct data {
int a, b, c;
double x, y, z;
} d_ary[SIZE]; // AoS
int a[SIZE], b[SIZE], c[SIZE];
double x[SIZE], y[SIZE], z[SIZE]; //SoA](https://image.slidesharecdn.com/optimizationtechniqueswww-150315103212-conversion-gate01/75/slide-27-2048.jpg)


![30
ストリップマイニング
以下のコードを考える
for (int i = 0; i < SIZE; ++i) {
hoge(A[i]);
}
for (int i = 0; i < SIZE; ++i) {
fuga(A[i]);
}
配列 A が十分長いとき、最初のループが終わった時点で、
A の先頭はキャッシュから排出されている](https://image.slidesharecdn.com/optimizationtechniqueswww-150315103212-conversion-gate01/75/slide-30-2048.jpg)

![32
ストリップマイニング
for (int i = 0; i < SIZE; i += strip_size) {
for (int j = i; j < min(SIZE, i+strip_size); ++j) {
hoge(A[j]);
}
for (int j = i; j < min(SIZE, i+strip_size); ++j) {
fuga(A[j]);
}
}](https://image.slidesharecdn.com/optimizationtechniqueswww-150315103212-conversion-gate01/75/slide-32-2048.jpg)
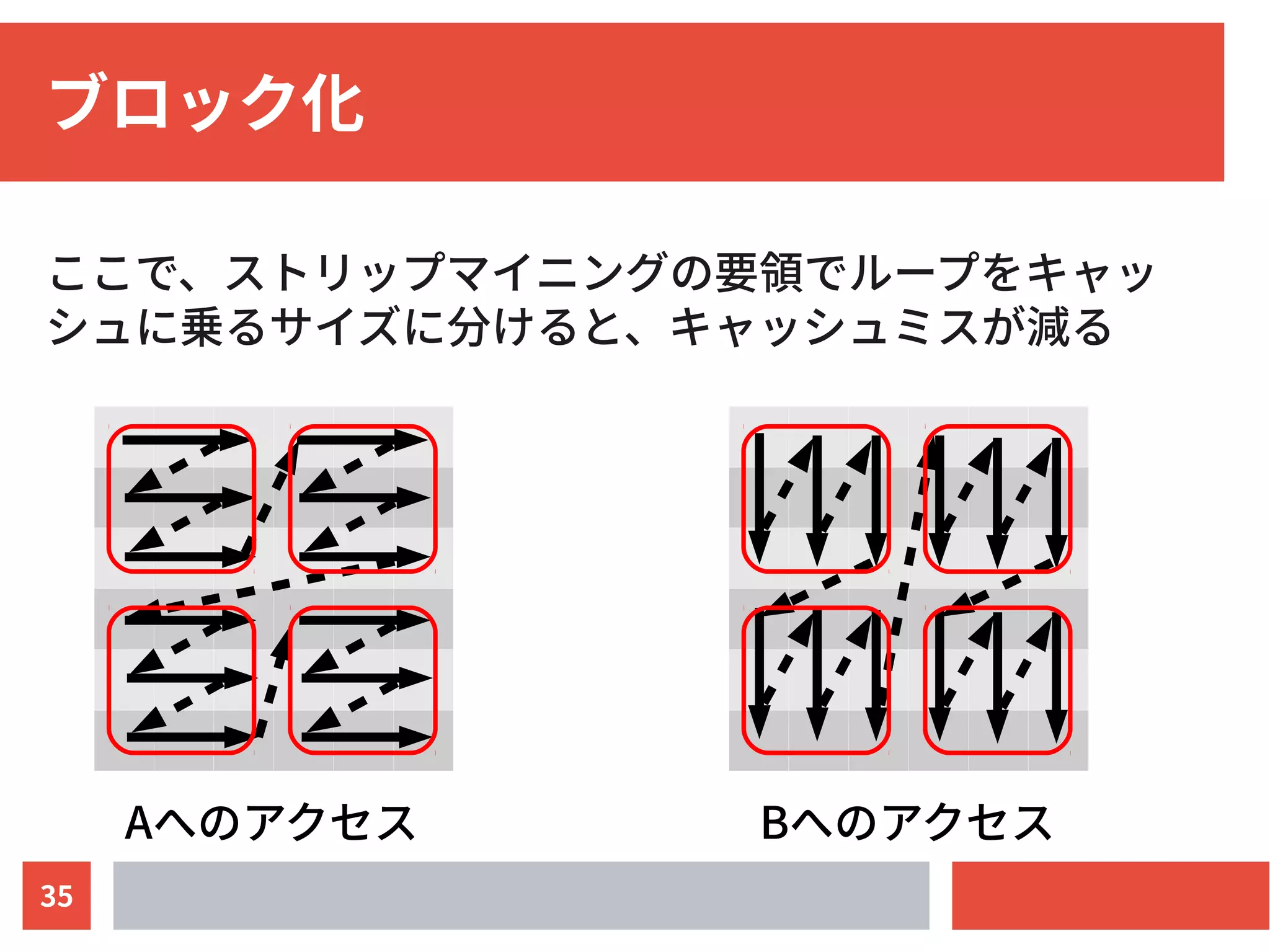
![33
ブロック化
次のコードを考える
for (int i = 0; i < SIZE; ++i) {
for (int j = 0; j < SIZE; ++j) {
A[i][j] += B[j][i];
}
}
B には飛び飛びのアクセスをしているので SIZE が大きい
と毎回キャッシュミスが発生して効率が悪い](https://image.slidesharecdn.com/optimizationtechniqueswww-150315103212-conversion-gate01/75/slide-33-2048.jpg)

![36
ブロック化
for (int i = 0; i < SIZE; i+=block_size) {
for (int j = 0; j < SIZE; j+=block_size) {
for (int ii = i; ii < i+block_size; ++ii) {
for(int jj = j; jj < j+block_size; ++jj) {
A[ii][jj] += B[jj][ii];
}
}
}
}](https://image.slidesharecdn.com/optimizationtechniqueswww-150315103212-conversion-gate01/75/slide-36-2048.jpg)

























![62
複数のビットから成るデータの配列の
ハミング距離を求める
例えば、 2 ビットから成るデータの配列のハミング距離
を求めるとき、
for (int i = 0; i < ARY_SIZE; ++i) {
uint8_t C = A[i] ^ B[i]; //8 ビットの場合
C = ((C & 0xAA) >> 1) | (C & 0x55);
result += popcount(C);
}](https://image.slidesharecdn.com/optimizationtechniqueswww-150315103212-conversion-gate01/75/slide-62-2048.jpg)





























![92
SIMD 命令とは
A[0] A[1] A[2] A[3]
B[0] B[1] B[2] B[3]
A[0]+B[0] A[1]+B[1] A[2]+B[2] A[3]+B[3]
+
256ビット](https://image.slidesharecdn.com/optimizationtechniqueswww-150315103212-conversion-gate01/75/slide-92-2048.jpg)










![103
メモリアラインメント 静的確保
alignas(32) uint64_t ary[SIZE];
ary の先頭は 32 バイト境界に合わせられる](https://image.slidesharecdn.com/optimizationtechniqueswww-150315103212-conversion-gate01/75/slide-103-2048.jpg)




![108
マスクによる条件分岐の除去
例 )
for (int i = 0; i < SIZE; ++i) {
if (a[i] > b[i]) {
c[i] += a[i];
}
}
条件分岐が入っているのでこのままでは並列に足し算で
きない](https://image.slidesharecdn.com/optimizationtechniqueswww-150315103212-conversion-gate01/75/slide-108-2048.jpg)









![118
参考文献等
[0] インテル ® 64 アーキテクチャーおよび IA-32 アーキテク
チャー最適化リファレンス・マニュアル
http://www.intel.co.jp/content/dam/www/public/ijkk/jp/ja/do
cuments/developer/248966-024JA.pdf
[1] 英語の最新版
http://www.intel.co.jp/content/dam/www/public/us/en/docum
ents/manuals/64-ia-32-architectures-optimization-manual.pdf
[2] Intel Intrinsics Guide
https://software.intel.com/sites/landingpage/Intrin
sicsGuide/](https://image.slidesharecdn.com/optimizationtechniqueswww-150315103212-conversion-gate01/75/slide-118-2048.jpg)
![119
参考文献等
[3] Intel® Architecture Instruction Set Extensions
Programming Reference
https://software.intel.com/sites/default/files/managed/0d/53/
319433-022.pdf
[4] Intel® 64 and IA-32 Architectures Software Developer’s
Manual
http://www.intel.co.jp/content/dam/www/public/us/en/docu
ments/manuals/64-ia-32-architectures-software-developer-
manual-325462.pdf
[5] CPU – Wikipedia
http://ja.wikipedia.org/wiki/CPU](https://image.slidesharecdn.com/optimizationtechniqueswww-150315103212-conversion-gate01/75/slide-119-2048.jpg)
![120
参考文献等
[6] Chess Programming Wiki
https://chessprogramming.wikispaces.com/](https://image.slidesharecdn.com/optimizationtechniqueswww-150315103212-conversion-gate01/75/slide-120-2048.jpg)























































































