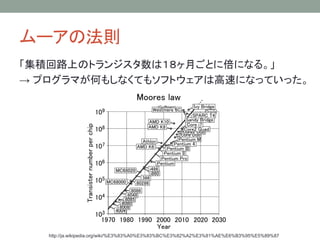
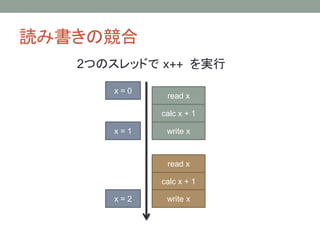
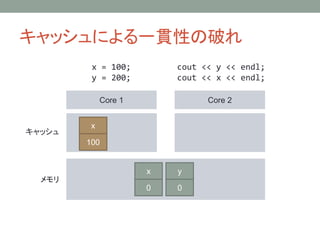
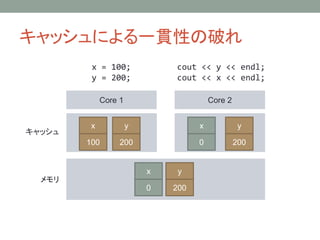
キャッシュによる一貫性の破れ
Core 1 Core2
キャッシュ
メモリ
x = 100;
y = 200;
cout << y << endl;
cout << x << endl;
y
0
x
0
x
100
18.
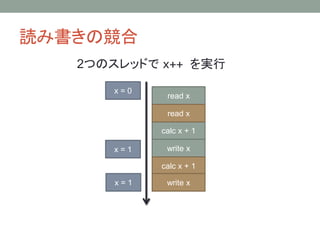
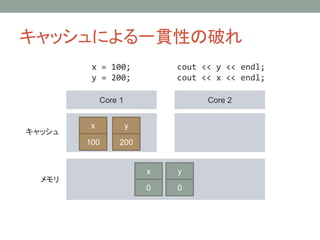
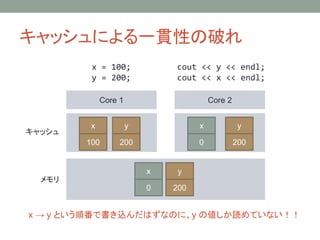
キャッシュによる一貫性の破れ
Core 1 Core2
キャッシュ
メモリ
x = 100;
y = 200;
cout << y << endl;
cout << x << endl;
y
0
x
0
x
100
y
200
19.
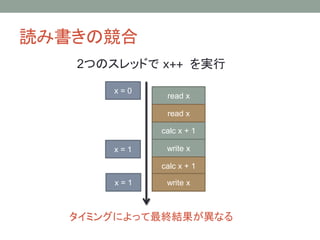
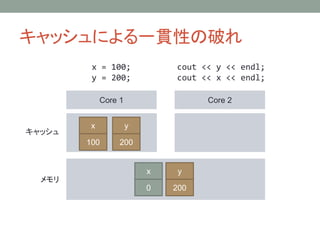
キャッシュによる一貫性の破れ
Core 1 Core2
キャッシュ
メモリ
x = 100;
y = 200;
cout << y << endl;
cout << x << endl;
y
0
x
0
x
100
y
200
y
200
20.
キャッシュによる一貫性の破れ
Core 1 Core2
キャッシュ
メモリ
x = 100;
y = 200;
cout << y << endl;
cout << x << endl;
y
0
x
0
x
100
y
200
y
200
y
200
21.
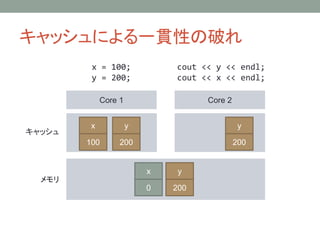
キャッシュによる一貫性の破れ
Core 1 Core2
キャッシュ
メモリ
x = 100;
y = 200;
cout << y << endl;
cout << x << endl;
y
0
x
0
x
100
y
200
y
200
y
200
x
0
22.
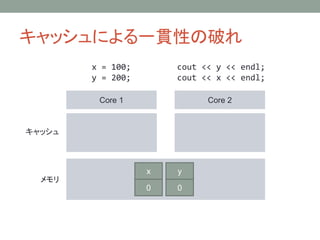
キャッシュによる一貫性の破れ
Core 1 Core2
キャッシュ
メモリ
x = 100;
y = 200;
cout << y << endl;
cout << x << endl;
y
0
x
0
x
100
y
200
y
200
y
200
x
0
x → y という順番で書き込んだはずなのに、y の値しか読めていない!!
23.
コンパイラによる最適化
// Thread 1
ans= complex_computation();
done = true;
// Thread 2
while (!done)
/* busy loop */;
cout << ans << endl;
bool done = false; // global variable
double ans = 0.0; // global variable
24.
コンパイラによる最適化
// Thread 1
ans= complex_computation();
done = true;
// Thread 2
while (!done)
/* busy loop */;
cout << ans << endl;
コンパイラ先生
「ループ一周ごとに !done を
評価するのは無駄では?」
bool done = false; // global variable
double ans = 0.0; // global variable
25.
コンパイラによる最適化
// Thread 1
ans= complex_computation();
done = true;
// Thread 2
if (!done) {
while (true)
/* busy loop */;
}
cout << ans << endl;
コンパイラ先生
「最適化しといたで!!!」
bool done = false; // global variable
double ans = 0.0; // global variable
26.
コンパイラによる最適化
// Thread 1
ans= complex_computation();
done = true;
// Thread 2
if (!done) {
while (true)
/* busy loop */;
}
cout << ans << endl;
コンパイラ先生
「最適化しといたで!!!」
無限ループ!!
bool done = false; // global variable
double ans = 0.0; // global variable
用語
• オブジェクト
• 規格上の定義はregion of storage.
• メモリ上に固有の領域を持っている存在。
• 変数とか配列の要素とか一時オブジェクトとか。
• 評価
• 式の値を計算したり、式の副作用を発動させたりすること。
• 一つの式が複数回評価されたり、一回も評価されなかったりする。
• 例えば、以下のプログラムの場合、x = 42 は 10 回評価される。
• for (int i = 0; i < 10; ++i)
x = 42;
31.
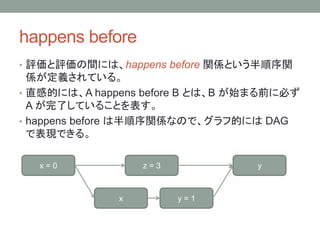
happens before
• 評価と評価の間には、happensbefore 関係という半順序関
係が定義されている。
• 直感的には、A happens before B とは、B が始まる前に必ず
A が完了していることを表す。
• happens before は半順序関係なので、グラフ的には DAG
で表現できる。
x = 0
x y = 1
z = 3 y
data race
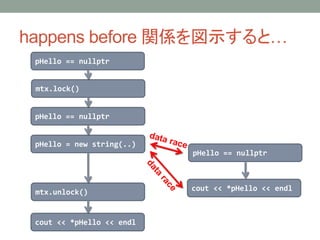
• 2つの評価 A, B が以下の4条件を満たすとき、
プログラムに data race があるという。
1. A, B が同一の非アトミックオブジェクトに対する操作
2. A, B の少なくとも一方が書き込み操作
3. A happens before B でない
4. B happens before A でない
• プログラムに data race があるとき、undefined behavior
が起こる。
34.
data race
bool done= false; // global variable
double ans = 0.0; // global variable
// Thread 1
ans = complex_computation();
done = true;
// Thread 2
while (!done)
/* busy loop */;
cout << ans << endl;
同一の非アトミックオブジェクトに対する操作
一方は書き込み操作
お互いに happens before でない
35.
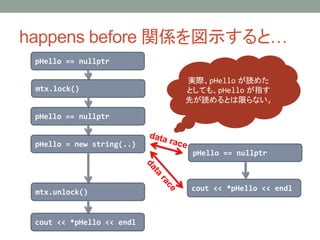
data race
bool done= false; // global variable
double ans = 0.0; // global variable
// Thread 1
ans = complex_computation();
done = true;
// Thread 2
while (!done)
/* busy loop */;
cout << ans << endl;
同一の非アトミックオブジェクトに対する操作
一方は書き込み操作
お互いに happens before でない
undefined behavior
atomic
std::atomic<int> x; //0 で初期化される
x.store(42); // x に 42 を書き込む
cout << x.load() << endl; // x の値を読む
x.fetch_add(1); // 値を 1 増やす
cout << x.load() << endl; // 43 が出力される
// x == y ならば x に 100 を代入 (いわゆるCAS)
int y = 43;
x.compare_exchange_strong(y, 100);
38.
atomic と happensbefore
アトミックオブジェクト M に対する書き込み操作 W と
M に対する読み込み操作 R があるとする。
もし R が W の書き込んだ値を読んだとすると、
W happens before R が成り立つ。
(このとき W synchronizes with R という)
※ memory_order が relaxed や consume でない場合
39.
atomic と happensbefore
std::atomic<bool> done = false; // global variable
double ans = 0.0; // global variable
// Thread 1
ans = complex_computation();
done.store(true);
// Thread 2
while (!done.load())
/* busy loop */;
cout << ans << endl;
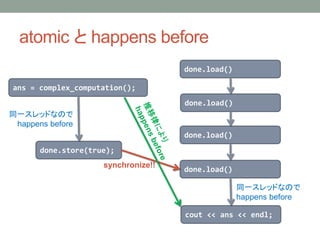
• atomic 変数を使うことにより、done に関する data race を解消。
• done の store-load により、ans の書き込みと ans の読み込みの
間にも happens before 関係が入る。
40.
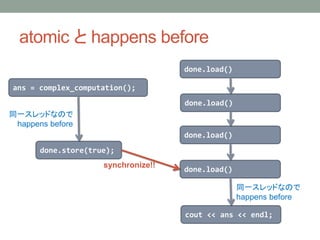
atomic と happensbefore
ans = complex_computation();
done.store(true);
done.load()
done.load()
done.load()
done.load()
cout << ans << endl;
同一スレッドなので
happens before
synchronize!!
同一スレッドなので
happens before
41.
atomic と happensbefore
ans = complex_computation();
done.store(true);
done.load()
done.load()
done.load()
done.load()
cout << ans << endl;
同一スレッドなので
happens before
synchronize!!
同一スレッドなので
happens before
mutex と happensbefore
• 単一の mutex に対する lock(), unlock() はある全順序 S
に従って起こる。
• スレッドA, B, C, D があるときに、スレッド A から見て C → D の順で
ロックを取ったように見えたとしたら、B から見ても C → D の順でロック
を取ったように見える。
• U をある mutex に対する unlock 操作、
L を同じ mutex に対する lock 操作とする。
このとき、S の上で U < L ならば U happens before L である。


























![mutex
map<string, string> pages; // global variable
mutex pages_mutex; // global variable
void save_page(const string& url) {
result = (url にアクセスして内容を取得);
pages_mutex.lock(); // 例外安全性はとりあえず置いておく
pages[url] = result;
pages_mutex.unlock();
}
int main() {
// 並列にウェブサイトをクロール
thread t1(save_page, "http://foo");
thread t2(save_page, "http://bar");
t1.join(); t2.join();
}](https://image.slidesharecdn.com/c-150424105445-conversion-gate01/85/C-43-320.jpg)






















































![JavaDayTokyo2015 [3-1]](https://cdn.slidesharecdn.com/ss_thumbnails/jdt2015-31-150409074859-conversion-gate01-thumbnail.jpg?width=640&height=640&fit=bounds)




















