Recommended
PDF
PDF
PDF
PDF
PDF
Xeon PhiとN体計算コーディング x86/x64最適化勉強会6(@k_nitadoriさんの代理アップ)
PDF
PDF
PDF
Wavelet matrix implementation
PDF
準同型暗号の実装とMontgomery, Karatsuba, FFT の性能
PDF
PDF
PDF
PDF
PDF
LLVMで遊ぶ(整数圧縮とか、x86向けの自動ベクトル化とか)
PDF
汎用性と高速性を目指したペアリング暗号ライブラリ mcl
PDF
ElGamal型暗号文に対する任意関数演算・再暗号化の二者間秘密計算プロトコルとその応用
PDF
Intro to SVE 富岳のA64FXを触ってみた
PDF
KEY
関東GPGPU勉強会 LLVM meets GPU
PDF
WASM(WebAssembly)入門 ペアリング演算やってみた
PDF
Intel AVX-512/富岳SVE用SIMDコード生成ライブラリsimdgen
PDF
PDF
PPTX
PDF
PPTX
PDF
GPUが100倍速いという神話をぶち殺せたらいいな ver.2013
PDF
Effective Modern C++ 読書会 Item 35
PPTX
Jenkins User Conference 東京 2015
PDF
More Related Content
PDF
PDF
PDF
PDF
PDF
Xeon PhiとN体計算コーディング x86/x64最適化勉強会6(@k_nitadoriさんの代理アップ)
PDF
PDF
PDF
Wavelet matrix implementation
What's hot
PDF
準同型暗号の実装とMontgomery, Karatsuba, FFT の性能
PDF
PDF
PDF
PDF
PDF
LLVMで遊ぶ(整数圧縮とか、x86向けの自動ベクトル化とか)
PDF
汎用性と高速性を目指したペアリング暗号ライブラリ mcl
PDF
ElGamal型暗号文に対する任意関数演算・再暗号化の二者間秘密計算プロトコルとその応用
PDF
Intro to SVE 富岳のA64FXを触ってみた
PDF
KEY
関東GPGPU勉強会 LLVM meets GPU
PDF
WASM(WebAssembly)入門 ペアリング演算やってみた
PDF
Intel AVX-512/富岳SVE用SIMDコード生成ライブラリsimdgen
PDF
PDF
PPTX
PDF
PPTX
PDF
GPUが100倍速いという神話をぶち殺せたらいいな ver.2013
PDF
Effective Modern C++ 読書会 Item 35
Viewers also liked
PPTX
Jenkins User Conference 東京 2015
PDF
KEY
PDF
もしWordPressユーザーがGitを使ったら 〜WordPressテーマを共同編集しよう〜
PDF
KEY
PDF
PDF
Similar to Prosym2012
PDF
PDF
PDF
PDF
PDF
PDF
PDF
PDF
PDF
PDF
PDF
“Symbolic bounds analysis of pointers, array indices, and accessed memory reg...
ODP
PDF
PDF
PDF
PDF
PDF
2011.12.10 関数型都市忘年会 発表資料「最近書いた、関数型言語と関連する?C++プログラムの紹介」
PDF
PPT
PDF
x64 のスカラー,SIMD 演算性能を測ってみた @ C++ MIX #10
More from MITSUNARI Shigeo
PDF
PDF
PDF
PDF
PDF
PDF
PDF
PDF
PDF
PDF
PDF
PDF
PDF
深層学習フレームワークにおけるIntel CPU/富岳向け最適化法
PDF
PDF
PDF
Lifted-ElGamal暗号を用いた任意関数演算の二者間秘密計算プロトコルのmaliciousモデルにおける効率化
PDF
PDF
PDF
PDF
Prosym2012 1. 2. 3. x86/x64アセンブラの復習(1/2)
汎用レジスタは15個(64bit時)
rax, rbx, ..., r8, ..., r15 ; 64bitレジスタ
rsp : スタックレジスタ
基本的に2オペランド
<op> <dst> <src> // dst ← op(dst, src);
dstは破壊される
アドレッシングは比較的高機能
ptr [<reg1> + <reg2> * (0|1|2|4|8) + <即値>]
例)
mov rax, rcx // rax = rcx;
add ecx, 4 // ecx += 4;
sub r8,[rax+ebx*4+12]//r8 -= *(int64_t)(rax+ebx*4+12);
夏のプログラムシンポジウム2012 3 / 33
4. x86/x64アセンブラの復習(2/2)
SIMDレジスタは16個(64bit時)
xmm0, ..., xmm15 ; 128bitレジスタ
ymm0, ..., ymm15 ; 256bitレジスタ
データ型
char x 16, int x 4, float x 8, double x 4, etc.
演算の種類
四則演算,ビット演算,特殊演算,etc.
3オペランドタイプもある
例)
movaps xmm0,[eax] //xmm0にfloat変数4個が代入される
vaddpd ymm0,ymm3,ymm2 //ymm0 = ymm3 + ymm2(double x 4)
pand xmm2, xmm4 //xmm2 &= xmm4
夏のプログラムシンポジウム2012 4 / 33
5. Xbyakの特長
C++ヘッダのみで記述
外部ライブラリのビルドやリンクが不要
対応コンパイラ : Visual Studio/gcc/clang
対応OS : Windows/Linux/Mac
実行時コード生成
Intel MASM形式に似せたDSLを提供
できるだけ自然に記述できるようにした
アドレッシングは設計時に一番悩んだ部分
かつ一番気に入ってる部分
mov(eax, 5); // mov eax, 5
add(rcx, byte[eax+ecx*4–5]);//add rcx,byte[eax+ecx*4-5]
jmp("lp"); // jmp lp
夏のプログラムシンポジウム2012 5 / 33
6. 簡単なサンプル(1/3)
整数nが与えられたときにnを足す関数を生成
ヘッダをincludeしてCodeGeneratorを継承
#include <xbyak.h>
struct Code : Xbyak::CodeGenerator {
explicit Code(int n) {
mov(eax, ptr [esp + 4]); // 32bit OS
add(eax, n);
// lea(rax, ptr [rcx + n]); // 64bit Windows
// lea(eax, ptr [edi + n]); // 64bit Linux/Mac
ret();
}
};
夏のプログラムシンポジウム2012 6 / 33
7. 簡単なサンプル(2/3)
インスタンスを生成して実行
int main(int argc, char *argv[]) {
const int n = argc == 1 ? 5 : atoi(argv[1]);
Code c(n);
auto f = (int (*)(int))c.getCode();
for (int i = 0; i < 3; i++) {
printf("%d + %d = %dn", i, n, f(i));
}
}
% ./a.out 9
0 + 9 = 9
1 + 9 = 10
2 + 9 = 11
夏のプログラムシンポジウム2012 7 / 33
8. 簡単なサンプル(3/3)
インスタンスを生成して実行
引数が9のときの関数fの中身をデバッガで確認
32bit Windowsで見てみた
mov eax,dword ptr [esp+4]
add eax,9 // ここが即値
ret
引数が3のときの関数fの中身をデバッガで確認
64bit Linuxで見てみた
0x0000000000607000 in ?? ()
1: x/i $pc
0x607000: lea eax,[edi+0x3]
// ここが即値
夏のプログラムシンポジウム2012 8 / 33
9. 応用例
ビューティフルコード8章
画像処理のためのその場コード生成
画像処理では関数内では固定のパラメータが多い
templateなどを組み合わせるとバイナリサイズが肥大化
夏のプログラムシンポジウム2012 9 / 33
10. 画像処理のためのその場コード生成
ビットマップD, Sを合成変換する関数
変換種類を示すopがループの最内部分にあるため通常の実装
では遅すぎる
1985年のWindowsではそのコードを生成するミニコンパイラ
を含んでいたらしい
for (int y = 0; y < cy; y++) {
for (int x = 0; x < cx; x++) {
switch (op) {
case 0x00: D[y][x] = 0; break;
...
case 0x60: D[y][x] = (D[y][x] ^ S[y][x]) & P[y][x];
...
} } }
夏のプログラムシンポジウム2012 10 / 33
11. Xbyakによるその場コード生成
メリット Code(const Rect& rect, int op){
// generate prolog
C++の文法でasmの制御構造を L(".lp_y");
記述できる mov(rcx, rect.width);
L(".lp_x");
極めて直感的に扱える
switch (op) {
アセンブラ独自の疑似命令を ..
覚える必要がない case 0x60:
mov(eax,ptr[ptrD+rbx]);
Cの構造体との連携が xor(eax,ptr[ptrS+rbx]);
シームレス and(eax,ptr[ptrP+rbx]);
構造体メンバのオフセット break;
取得は外部ツールでは困難 }
mov(ptr[ptrD + rbx], eax);
Xbyakなら<stddef.h>の add(rbx, 4);
offsetof(type, member) sub(rcx, 1);
をそのまま利用可能 jnz(".lp_x");
...
夏のプログラムシンポジウム2012 11 / 33
12. FFTのバタフライ演算(1/2)
ビット反転とデータ移動 void swap(double*a,int k1,int j1){
__m128d x = _mm_load_pd(a + j1);
入力は次数nとデータa __m128d y = _mm_load_pd(a + k1);
ipはビット反転用work __mm_store_pd(a + j1, y);
__mm_store_pd(a + k1, x);
nは可変だが,128とか }
256とかが多いケース void bitrv(int n,int *ip,double *a)
通常は事前に専用コード {
int j, j1, k, k1, l, m, m2;
を用意して分岐する
l = n; m = 1;
ツールでCのコードを生成 ...
するなど m2 = 2 * m;
if ((m << 3) == l) {
for (k = 0; k < m; k++) {
for (j = 0; j < k; j++) {
j1 = 2 * j + ip[k];
k1 = 2 * k + ip[j];
swap(a, j1, k1);
夏のプログラムシンポジウム2012 12 / 33
13. FFTのバタフライ演算(2/2)
修正箇所はわずか struct Code : Xbyak::CodeGenerator {
swap()をコード生成 void swap(const Reg32e& a
, int k1, int j1){
するように変更 movapd(xm0, ptr [a + j1 * 8]);
関数のプロローグと movapd(xm1, ptr [a + k1 * 8]);
エピローグを作る movapd(ptr [a + j1 * 8], xm1);
movapd(ptr [a + k1 * 8], xm0);
生成コード例 }
定数とループが全て void gen_bitrv2(int n, int *ip){
展開される const Reg64& a = rdi;
int j, j1, k, k1, l, m, m2;
movapd xm0,ptr [eax+10h] ...
movapd xm1,ptr [eax+100h] j1 = 2 * j + ip[k];
movapd ptr [eax+10h],xm1 k1 = 2 * k + ip[j];
movapd ptr [eax+100h],xm0 swap(a, j1, k1);
movapd xm0,ptr [eax+50h] ...
movapd xm1,ptr [eax+140h]
...
夏のプログラムシンポジウム2012 13 / 33
14. SSE4.1の文字列探索命令の紹介
pcmpestri, pcmpistriなど
strlenやstrstrなどを高速に実装するための命令群
複雑なパラメータを持つCISCの権化の様な命令
文字列処理の単位char or short(2byte:UTF16)の選択
符号付き・符号無しの選択
文字列の比較方法の選択
完全マッチ,文字の範囲指定,部分文字列など
入力文字列の設定
0ターミネート文字列 or [begin, end)による文字列
CF, ZF, SF, OFの各フラグに結果の様々な情報
詳細
http://www.slideshare.net/herumi/x86opti3
夏のプログラムシンポジウム2012 14 / 33
15. strstrを作ってみる
16byteずつ文字列を探索する
入力パラメータ
a : 入力テキスト(text)ポインタが格納されたレジスタ
xm0 : 検索文字(の先頭最大16byte)
12 : 文字列マッチをuint8_tの部分文字マッチさせる即値
出力フラグ
CF : 文字列を見つける前にtextが終われば1
ZF : aから16byte内に文字列がなければ0
movdqu(xm0, ptr [key]); // xm0 = *key
L(".lp");
pcmpistri(xm0, ptr [a], 12);
lea(a, ptr [a + 16]);
ja(".lp");
jnc(".notFound");
夏のプログラムシンポジウム2012 15 / 33
16. strstrのコア部分(続き)
keyの先頭文字が一致する部分を検出した
先程のループを抜けたときはcにマッチしたオフセットが入っ
ているのでそれだけ進める(add a, c)
その場所からkeyの最後まで一致しているかを確認
OF == 0なら一致しなかった
SF == 1なら見つかった
add(a, c);
mov(save_a, a); // save a
mov(save_key, key); // save key
L(".tailCmp");
movdqu(xm1, ptr [save_key]);
pcmpistri(xm1, ptr [save_a], 12);
jno(".next"); // if (OF == 0) goto .next
js(".found"); // if (SF == 1) goto .found
add(save_a, 16);
add(save_key, 16);
jmp(".tailCmp");
夏のプログラムシンポジウム2012 16 / 33
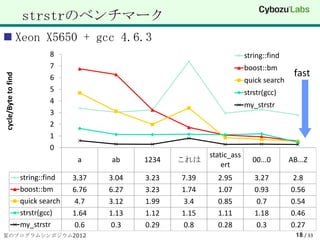
17. ベンチマーク
対象CPU, コンパイラ
Xeon X5650 + gcc 4.6.3
対象コード
gccのstrstr(これもSSE4.1を利用している)
boost 1.51のalgorithm::boyer_moore(BM法)
Quick Search(改良版BMアルゴリズム)
my_strstr
検索方法
テキスト:130MBのUTF8な日本語を多く含むもの
指定されたkey文字列がいくつあるかを探す
byte単位あたりにかかったCPU clock数を表示する
夏のプログラムシンポジウム2012 17 / 33
18. strstrのベンチマーク
Xeon X5650 + gcc 4.6.3
8 string::find
7 boost::bm
fast
cycle/Byte to find
6 quick search
5 strstr(gcc)
4 my_strstr
3
2
1
0
static_ass
a ab 1234 これは 00...0 AB...Z
ert
string::find 3.37 3.04 3.23 7.39 2.95 3.27 2.8
boost::bm 6.76 6.27 3.23 1.74 1.07 0.93 0.56
quick search 4.7 3.12 1.99 3.4 0.85 0.7 0.54
strstr(gcc) 1.64 1.13 1.12 1.15 1.11 1.18 0.46
my_strstr 0.6 0.3 0.29 0.8 0.28 0.3 0.27
夏のプログラムシンポジウム2012 18 / 33
19. 考察
ABC....Zの様なBM法やQuick Searchアルゴリズムにと
って有利な文字列すらstrstrより遅い
BM法やQuick Searchはテーブルを引いてオフセットを足すた
めパイプラインに悪影響がある
通常の文字列検索では出番がない?
// Quick Searchの検索部分
const char *find(const char *begin, const char *end) const {
while (begin <= end - len_) {
for (size_t i = 0; i < len_; i++) {
if (str_[i] != begin[i]) goto NEXT;
}
return begin;
NEXT:
begin += tbl_[static_cast<unsigned char>(begin[len_])];
}
return end;
}
夏のプログラムシンポジウム2012 19 / 33
20. strcasestrの実装
keyの大文字小文字を区別しないstrstr
コードの簡略さのためにkeyは事前に小文字化しておく
大文字小文字を区別しないマッチ方法
textを小文字にしてマッチさせる(先程のコードに委譲)
movdqu(xm0, ptr [key]); // xm0 = *key
L(".lp");
if (caseInsensitive) {
movdqu(xm1, ptr [a]);
toLower(xm1, Am1, Zp1, amA, t0, t1);//小文字化するコード生成関数
pcmpistri(xm0, xm1, 12);
} else {
pcmpistri(xm0, ptr [a], 12);
}
lea(a, ptr [a + 16]);
ja(".lp"); // if (CF == 0 and ZF = 0) goto .lp
jnc(".notFound");
夏のプログラムシンポジウム2012 20 / 33
21. toLower(1/2)
大文字を小文字にする
'A' <= c && c <= 'Z'なら c += 'a' – 'Z'
分岐無しで16byteずつまとめてやりたい
pcmpgtb x, y
x ← x > y ? 0xff : 0;をbyte単位で行う関数
if ('A' <= c && c <= 'Z') c += 'a' – 'Z';を書き換える
('A' <= c && c <= 'Z') ? ('a' – 'Z') : 0;
= ((c > 'A'–1) ? 0xff : 0) & (('Z'+1 > c) ? 0xff : 0) & ('a'–'Z');
= pcmpgtb(c, 'A'-1) & pcmpgtb('Z'+1, c) & 'a'-'Z';
夏のプログラムシンポジウム2012 21 / 33
22. toLower(2/2)
実際のコード片
/*
toLower in x
Am1 : 'A' – 1, Zp1 : 'Z' + 1, amA : 'a' - 'A'
t0, t1 : temporary register
*/
void toLower(const Xmm& x, const Xmm& Am1, const Xmm& Zp1
, const Xmm& amA , const Xmm& t0, const Xmm& t1) {
movdqa(t0, x);
pcmpgtb(t0, Am1); // -1 if c > 'A' - 1
movdqa(t1, Zp1);
pcmpgtb(t1, x); // -1 if 'Z' + 1 > c
pand(t0, t1); // -1 if [A-Z]
pand(t0, amA); // 0x20 if c in [A-Z]
paddb(x, t0); // [A-Z] -> [a-z]
}
夏のプログラムシンポジウム2012 22 / 33
23. CPU判別によるディスパッチ
コア部分再度(詳細) pcmpistri(xm0,ptr[a],12);
実験によるとCPUの世代で if (isSandyBridge) {
コードの書き方で速度が違う lea(a, ptr [a + 16]);
(lea vs add) ja(".lp");
} else {
実行時にCPU判別することで
jbe(".headCmp");
適切なコード生成を行う
add(a, 16);
10%程度速度向上があった jmp(".lp");
L(".headCmp");
}
jnc(".notFound");
if (isSandyBridge) {
lea(a,ptr[a+c-16]);
} else {
add(a, c); }
夏のプログラムシンポジウム2012 23 / 33
24. ビットを数える
簡潔データ構造
サイズnの{0, 1}からなるビットベクトルvに対して
rank(x) = #{ v[i] = 1 | 0 <= i < x }
select(m) = min { i | rank(i) = m }
を基本関数として圧縮検索などさまざまなロジックに利用
(注)普通はrank()は0 <= i <= xの範囲で定義
rankはまさにビットカウント関数
ビューティフルコード10章
「高速ビットカウントを求めて」の続き?
ここでは32bit/64bitに対するビットカウント命令
popcntの存在は前提
夏のプログラムシンポジウム2012 24 / 33
25. ナイーブな実装
岡野原さんの2006年CodeZine記事ベース
256bitごとの累積値をuint32_t a[]に保存
a[i] := rank(256 * i)
そこからの64bitごとの差分累積値をuint8_t b[]に保存
b[i] := rank(64 * i) – rank(64 * (i & ~3))
必要なメモリは(32 + 8 * 4) / 256 = 1/4(bitあたり)
rank(x) = a[i/256] + b[i/64]+ popcnt(v[i/64] & mask);
ランダムアクセスするのでキャッシュミスが頻出
. . . . . . . .
0 1 1 0 0 1 0 1 1 0 0 1 ... 0 1 0 1 1 1 1 0
. . . . . . . .
256bit 64bit
a[0] a[1] b[x+0] b[x+1] b[x+2] b[x+3]
夏のプログラムシンポジウム2012 25 / 33
26. メモリを減らして高速化できる?
キャッシュ効率の向上
テーブルは一つにまとめる
256bit単位ではなく512bit単位で集めてみる
64bitで区切ると8個
するとメモリ必要量は(32 + 32 + 8 * 8) / 512 = 1/4
変わらない
128bitで区切ると4個
メモリ必要量は(32 + 8 * 4) / 512 = 1/8
半分になる
問題点
256bitを超えるのでuint8_tな配列b[]の積算で
オーバーフローしてしまう
オンデマンドで総和を求める?
夏のプログラムシンポジウム2012 26 / 33
27. 4個未満のsum()
最適化したいコード(0 <= n < 4)
Xeonで35clk, i7で30lk程度であった(乱数生成込み)
int sum1(const uint8_t data[4], int n) {
int sum = 0;
for (int i = 0; i < n; i++) {
sum += data[i];
}
return sum;
}
XorShift128 rg;
for (int j = 0; j < C; j++) {
ret += sum1(data, rg.get() % 4);
}
夏のプログラムシンポジウム2012 27 / 33
28. ループ展開してみた
int sum2(const uint8_t data[4], int n) {
int sum = 0;
switch (n) {
case 3: sum += data[2];
case 2: sum += data[1];
case 1: sum += data[0];
}
return sum;
}
Xeon 35→26clk, i7 30→24clk
Loop Stream Detector(LSD)
夏のプログラムシンポジウム2012 28 / 33
29. psadbwを使ってみる
psadbw X, Y
MPEGなどのビデオコーデックにおいて
二つのbyte単位のデータの差の絶対値の和を求める命令
psadbw(X, Y) = sum [abs(X[i] – Y[i]) | i = 0..7]
画像の一致度を求める
Y = 0とするとXのbyte単位の和を求められる
Xをマスクして足せばよい
x0 x1 x2 x3 x4 x5 x6 x7
and
0xff 0xff 0xff 0 0 0 0 0
x0 x1 x2 0 0 0 0 0
夏のプログラムシンポジウム2012
x0 + x1 + x2 29 / 33
30. 実際のコード
int sum3(const uint8_t data[4], int n) {
uint32_t x = *reinterpret_cast<const uint32_t*>(data);
x &= (1U << (n * 8)) - 1;
V128 v(x);
v = psadbw(v, Zero());
return movd(v);
}
Xeon 35→26→10clk!
i7 30→24→10clk!
速くなった
このコードはn < 8まで適用可能
ちょっと改良すればn < 16まで可能
夏のプログラムシンポジウム2012 30 / 33
31. 128bitマスク
残りはマスクしてpopcntする部分
// 疑似コード
uint128_t mask128(int n) {
return (uint128_t(1) << n) – 1; }
int get(uint12_t x, int n) {
return popcnt_128(x & mask128(n)); }
実際には64bit整数に分解して実行する
n < 63 と n >= 64に場合分けする
uint64_t m0 = -1;
uint64_t m1 = 0;
if (!(n > 64)) m0 = mask;
if (n > 64) m1 = mask;
ret += popCount64(b0 & m0);
ret += popCount64(b1 & m1);
夏のプログラムシンポジウム2012 31 / 33
32. 分岐除去
先程のコードはgcc4.6では条件分岐命令を生成する
データがランダムなら確率50%で分岐予測が外れる
cmovを使って実装
条件が成立したときのみmovを行う命令
if (n > 64)はcarryを変更しなければ一度だけでよい
6clkぐらい速くなる
メモリアクセスの影響が多いと見えにくくなる
or(m0, -1);
and(n, 64); // ZF = (n < 64) ? 1 : 0
cmovz(m0, mask); // m0 = (!(n > 64)) ? mask : -1
cmovz(mask, idx); // mask = (n > 64) ? mask : 0
and(m0, ptr [blk + rax * 8 + 0]);
and(mask, ptr [blk + rax * 8 + 8]);
popcnt(m0, m0);
popcnt(rax, mask);
夏のプログラムシンポジウム2012 32 / 33
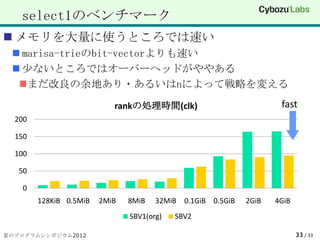
33. select1のベンチマーク
メモリを大量に使うところでは速い
marisa-trieのbit-vectorよりも速い
少ないところではオーバーヘッドがややある
まだ改良の余地あり・あるいはnによって戦略を変える
rankの処理時間(clk) fast
200
150
100
50
0
128KiB 0.5MiB 2MiB 8MiB 32MiB 0.1GiB 0.5GiB 2GiB 4GiB
SBV1(org) SBV2
夏のプログラムシンポジウム2012 33 / 33


![x86/x64アセンブラの復習(1/2)
汎用レジスタは15個(64bit時)
rax, rbx, ..., r8, ..., r15 ; 64bitレジスタ
rsp : スタックレジスタ
基本的に2オペランド
<op> <dst> <src> // dst ← op(dst, src);
dstは破壊される
アドレッシングは比較的高機能
ptr [<reg1> + <reg2> * (0|1|2|4|8) + <即値>]
例)
mov rax, rcx // rax = rcx;
add ecx, 4 // ecx += 4;
sub r8,[rax+ebx*4+12]//r8 -= *(int64_t)(rax+ebx*4+12);
夏のプログラムシンポジウム2012 3 / 33](https://image.slidesharecdn.com/prosym2012-120824234019-phpapp01/85/Prosym2012-3-320.jpg)
![x86/x64アセンブラの復習(2/2)
SIMDレジスタは16個(64bit時)
xmm0, ..., xmm15 ; 128bitレジスタ
ymm0, ..., ymm15 ; 256bitレジスタ
データ型
char x 16, int x 4, float x 8, double x 4, etc.
演算の種類
四則演算,ビット演算,特殊演算,etc.
3オペランドタイプもある
例)
movaps xmm0,[eax] //xmm0にfloat変数4個が代入される
vaddpd ymm0,ymm3,ymm2 //ymm0 = ymm3 + ymm2(double x 4)
pand xmm2, xmm4 //xmm2 &= xmm4
夏のプログラムシンポジウム2012 4 / 33](https://image.slidesharecdn.com/prosym2012-120824234019-phpapp01/85/Prosym2012-4-320.jpg)
![Xbyakの特長
C++ヘッダのみで記述
外部ライブラリのビルドやリンクが不要
対応コンパイラ : Visual Studio/gcc/clang
対応OS : Windows/Linux/Mac
実行時コード生成
Intel MASM形式に似せたDSLを提供
できるだけ自然に記述できるようにした
アドレッシングは設計時に一番悩んだ部分
かつ一番気に入ってる部分
mov(eax, 5); // mov eax, 5
add(rcx, byte[eax+ecx*4–5]);//add rcx,byte[eax+ecx*4-5]
jmp("lp"); // jmp lp
夏のプログラムシンポジウム2012 5 / 33](https://image.slidesharecdn.com/prosym2012-120824234019-phpapp01/85/Prosym2012-5-320.jpg)
![簡単なサンプル(1/3)
整数nが与えられたときにnを足す関数を生成
ヘッダをincludeしてCodeGeneratorを継承
#include <xbyak.h>
struct Code : Xbyak::CodeGenerator {
explicit Code(int n) {
mov(eax, ptr [esp + 4]); // 32bit OS
add(eax, n);
// lea(rax, ptr [rcx + n]); // 64bit Windows
// lea(eax, ptr [edi + n]); // 64bit Linux/Mac
ret();
}
};
夏のプログラムシンポジウム2012 6 / 33](https://image.slidesharecdn.com/prosym2012-120824234019-phpapp01/85/Prosym2012-6-320.jpg)
![簡単なサンプル(2/3)
インスタンスを生成して実行
int main(int argc, char *argv[]) {
const int n = argc == 1 ? 5 : atoi(argv[1]);
Code c(n);
auto f = (int (*)(int))c.getCode();
for (int i = 0; i < 3; i++) {
printf("%d + %d = %dn", i, n, f(i));
}
}
% ./a.out 9
0 + 9 = 9
1 + 9 = 10
2 + 9 = 11
夏のプログラムシンポジウム2012 7 / 33](https://image.slidesharecdn.com/prosym2012-120824234019-phpapp01/85/Prosym2012-7-320.jpg)
![簡単なサンプル(3/3)
インスタンスを生成して実行
引数が9のときの関数fの中身をデバッガで確認
32bit Windowsで見てみた
mov eax,dword ptr [esp+4]
add eax,9 // ここが即値
ret
引数が3のときの関数fの中身をデバッガで確認
64bit Linuxで見てみた
0x0000000000607000 in ?? ()
1: x/i $pc
0x607000: lea eax,[edi+0x3]
// ここが即値
夏のプログラムシンポジウム2012 8 / 33](https://image.slidesharecdn.com/prosym2012-120824234019-phpapp01/85/Prosym2012-8-320.jpg)

![画像処理のためのその場コード生成
ビットマップD, Sを合成変換する関数
変換種類を示すopがループの最内部分にあるため通常の実装
では遅すぎる
1985年のWindowsではそのコードを生成するミニコンパイラ
を含んでいたらしい
for (int y = 0; y < cy; y++) {
for (int x = 0; x < cx; x++) {
switch (op) {
case 0x00: D[y][x] = 0; break;
...
case 0x60: D[y][x] = (D[y][x] ^ S[y][x]) & P[y][x];
...
} } }
夏のプログラムシンポジウム2012 10 / 33](https://image.slidesharecdn.com/prosym2012-120824234019-phpapp01/85/Prosym2012-10-320.jpg)
![Xbyakによるその場コード生成
メリット Code(const Rect& rect, int op){
// generate prolog
C++の文法でasmの制御構造を L(".lp_y");
記述できる mov(rcx, rect.width);
L(".lp_x");
極めて直感的に扱える
switch (op) {
アセンブラ独自の疑似命令を ..
覚える必要がない case 0x60:
mov(eax,ptr[ptrD+rbx]);
Cの構造体との連携が xor(eax,ptr[ptrS+rbx]);
シームレス and(eax,ptr[ptrP+rbx]);
構造体メンバのオフセット break;
取得は外部ツールでは困難 }
mov(ptr[ptrD + rbx], eax);
Xbyakなら<stddef.h>の add(rbx, 4);
offsetof(type, member) sub(rcx, 1);
をそのまま利用可能 jnz(".lp_x");
...
夏のプログラムシンポジウム2012 11 / 33](https://image.slidesharecdn.com/prosym2012-120824234019-phpapp01/85/Prosym2012-11-320.jpg)
![FFTのバタフライ演算(1/2)
ビット反転とデータ移動 void swap(double*a,int k1,int j1){
__m128d x = _mm_load_pd(a + j1);
入力は次数nとデータa __m128d y = _mm_load_pd(a + k1);
ipはビット反転用work __mm_store_pd(a + j1, y);
__mm_store_pd(a + k1, x);
nは可変だが,128とか }
256とかが多いケース void bitrv(int n,int *ip,double *a)
通常は事前に専用コード {
int j, j1, k, k1, l, m, m2;
を用意して分岐する
l = n; m = 1;
ツールでCのコードを生成 ...
するなど m2 = 2 * m;
if ((m << 3) == l) {
for (k = 0; k < m; k++) {
for (j = 0; j < k; j++) {
j1 = 2 * j + ip[k];
k1 = 2 * k + ip[j];
swap(a, j1, k1);
夏のプログラムシンポジウム2012 12 / 33](https://image.slidesharecdn.com/prosym2012-120824234019-phpapp01/85/Prosym2012-12-320.jpg)
![FFTのバタフライ演算(2/2)
修正箇所はわずか struct Code : Xbyak::CodeGenerator {
swap()をコード生成 void swap(const Reg32e& a
, int k1, int j1){
するように変更 movapd(xm0, ptr [a + j1 * 8]);
関数のプロローグと movapd(xm1, ptr [a + k1 * 8]);
エピローグを作る movapd(ptr [a + j1 * 8], xm1);
movapd(ptr [a + k1 * 8], xm0);
生成コード例 }
定数とループが全て void gen_bitrv2(int n, int *ip){
展開される const Reg64& a = rdi;
int j, j1, k, k1, l, m, m2;
movapd xm0,ptr [eax+10h] ...
movapd xm1,ptr [eax+100h] j1 = 2 * j + ip[k];
movapd ptr [eax+10h],xm1 k1 = 2 * k + ip[j];
movapd ptr [eax+100h],xm0 swap(a, j1, k1);
movapd xm0,ptr [eax+50h] ...
movapd xm1,ptr [eax+140h]
...
夏のプログラムシンポジウム2012 13 / 33](https://image.slidesharecdn.com/prosym2012-120824234019-phpapp01/85/Prosym2012-13-320.jpg)

![strstrを作ってみる
16byteずつ文字列を探索する
入力パラメータ
a : 入力テキスト(text)ポインタが格納されたレジスタ
xm0 : 検索文字(の先頭最大16byte)
12 : 文字列マッチをuint8_tの部分文字マッチさせる即値
出力フラグ
CF : 文字列を見つける前にtextが終われば1
ZF : aから16byte内に文字列がなければ0
movdqu(xm0, ptr [key]); // xm0 = *key
L(".lp");
pcmpistri(xm0, ptr [a], 12);
lea(a, ptr [a + 16]);
ja(".lp");
jnc(".notFound");
夏のプログラムシンポジウム2012 15 / 33](https://image.slidesharecdn.com/prosym2012-120824234019-phpapp01/85/Prosym2012-15-320.jpg)
![strstrのコア部分(続き)
keyの先頭文字が一致する部分を検出した
先程のループを抜けたときはcにマッチしたオフセットが入っ
ているのでそれだけ進める(add a, c)
その場所からkeyの最後まで一致しているかを確認
OF == 0なら一致しなかった
SF == 1なら見つかった
add(a, c);
mov(save_a, a); // save a
mov(save_key, key); // save key
L(".tailCmp");
movdqu(xm1, ptr [save_key]);
pcmpistri(xm1, ptr [save_a], 12);
jno(".next"); // if (OF == 0) goto .next
js(".found"); // if (SF == 1) goto .found
add(save_a, 16);
add(save_key, 16);
jmp(".tailCmp");
夏のプログラムシンポジウム2012 16 / 33](https://image.slidesharecdn.com/prosym2012-120824234019-phpapp01/85/Prosym2012-16-320.jpg)

![考察
ABC....Zの様なBM法やQuick Searchアルゴリズムにと
って有利な文字列すらstrstrより遅い
BM法やQuick Searchはテーブルを引いてオフセットを足すた
めパイプラインに悪影響がある
通常の文字列検索では出番がない?
// Quick Searchの検索部分
const char *find(const char *begin, const char *end) const {
while (begin <= end - len_) {
for (size_t i = 0; i < len_; i++) {
if (str_[i] != begin[i]) goto NEXT;
}
return begin;
NEXT:
begin += tbl_[static_cast<unsigned char>(begin[len_])];
}
return end;
}
夏のプログラムシンポジウム2012 19 / 33](https://image.slidesharecdn.com/prosym2012-120824234019-phpapp01/85/Prosym2012-19-320.jpg)
![strcasestrの実装
keyの大文字小文字を区別しないstrstr
コードの簡略さのためにkeyは事前に小文字化しておく
大文字小文字を区別しないマッチ方法
textを小文字にしてマッチさせる(先程のコードに委譲)
movdqu(xm0, ptr [key]); // xm0 = *key
L(".lp");
if (caseInsensitive) {
movdqu(xm1, ptr [a]);
toLower(xm1, Am1, Zp1, amA, t0, t1);//小文字化するコード生成関数
pcmpistri(xm0, xm1, 12);
} else {
pcmpistri(xm0, ptr [a], 12);
}
lea(a, ptr [a + 16]);
ja(".lp"); // if (CF == 0 and ZF = 0) goto .lp
jnc(".notFound");
夏のプログラムシンポジウム2012 20 / 33](https://image.slidesharecdn.com/prosym2012-120824234019-phpapp01/85/Prosym2012-20-320.jpg)

![toLower(2/2)
実際のコード片
/*
toLower in x
Am1 : 'A' – 1, Zp1 : 'Z' + 1, amA : 'a' - 'A'
t0, t1 : temporary register
*/
void toLower(const Xmm& x, const Xmm& Am1, const Xmm& Zp1
, const Xmm& amA , const Xmm& t0, const Xmm& t1) {
movdqa(t0, x);
pcmpgtb(t0, Am1); // -1 if c > 'A' - 1
movdqa(t1, Zp1);
pcmpgtb(t1, x); // -1 if 'Z' + 1 > c
pand(t0, t1); // -1 if [A-Z]
pand(t0, amA); // 0x20 if c in [A-Z]
paddb(x, t0); // [A-Z] -> [a-z]
}
夏のプログラムシンポジウム2012 22 / 33](https://image.slidesharecdn.com/prosym2012-120824234019-phpapp01/85/Prosym2012-22-320.jpg)
![CPU判別によるディスパッチ
コア部分再度(詳細) pcmpistri(xm0,ptr[a],12);
実験によるとCPUの世代で if (isSandyBridge) {
コードの書き方で速度が違う lea(a, ptr [a + 16]);
(lea vs add) ja(".lp");
} else {
実行時にCPU判別することで
jbe(".headCmp");
適切なコード生成を行う
add(a, 16);
10%程度速度向上があった jmp(".lp");
L(".headCmp");
}
jnc(".notFound");
if (isSandyBridge) {
lea(a,ptr[a+c-16]);
} else {
add(a, c); }
夏のプログラムシンポジウム2012 23 / 33](https://image.slidesharecdn.com/prosym2012-120824234019-phpapp01/85/Prosym2012-23-320.jpg)
![ビットを数える
簡潔データ構造
サイズnの{0, 1}からなるビットベクトルvに対して
rank(x) = #{ v[i] = 1 | 0 <= i < x }
select(m) = min { i | rank(i) = m }
を基本関数として圧縮検索などさまざまなロジックに利用
(注)普通はrank()は0 <= i <= xの範囲で定義
rankはまさにビットカウント関数
ビューティフルコード10章
「高速ビットカウントを求めて」の続き?
ここでは32bit/64bitに対するビットカウント命令
popcntの存在は前提
夏のプログラムシンポジウム2012 24 / 33](https://image.slidesharecdn.com/prosym2012-120824234019-phpapp01/85/Prosym2012-24-320.jpg)
![ナイーブな実装
岡野原さんの2006年CodeZine記事ベース
256bitごとの累積値をuint32_t a[]に保存
a[i] := rank(256 * i)
そこからの64bitごとの差分累積値をuint8_t b[]に保存
b[i] := rank(64 * i) – rank(64 * (i & ~3))
必要なメモリは(32 + 8 * 4) / 256 = 1/4(bitあたり)
rank(x) = a[i/256] + b[i/64]+ popcnt(v[i/64] & mask);
ランダムアクセスするのでキャッシュミスが頻出
. . . . . . . .
0 1 1 0 0 1 0 1 1 0 0 1 ... 0 1 0 1 1 1 1 0
. . . . . . . .
256bit 64bit
a[0] a[1] b[x+0] b[x+1] b[x+2] b[x+3]
夏のプログラムシンポジウム2012 25 / 33](https://image.slidesharecdn.com/prosym2012-120824234019-phpapp01/85/Prosym2012-25-320.jpg)
![メモリを減らして高速化できる?
キャッシュ効率の向上
テーブルは一つにまとめる
256bit単位ではなく512bit単位で集めてみる
64bitで区切ると8個
するとメモリ必要量は(32 + 32 + 8 * 8) / 512 = 1/4
変わらない
128bitで区切ると4個
メモリ必要量は(32 + 8 * 4) / 512 = 1/8
半分になる
問題点
256bitを超えるのでuint8_tな配列b[]の積算で
オーバーフローしてしまう
オンデマンドで総和を求める?
夏のプログラムシンポジウム2012 26 / 33](https://image.slidesharecdn.com/prosym2012-120824234019-phpapp01/85/Prosym2012-26-320.jpg)
![4個未満のsum()
最適化したいコード(0 <= n < 4)
Xeonで35clk, i7で30lk程度であった(乱数生成込み)
int sum1(const uint8_t data[4], int n) {
int sum = 0;
for (int i = 0; i < n; i++) {
sum += data[i];
}
return sum;
}
XorShift128 rg;
for (int j = 0; j < C; j++) {
ret += sum1(data, rg.get() % 4);
}
夏のプログラムシンポジウム2012 27 / 33](https://image.slidesharecdn.com/prosym2012-120824234019-phpapp01/85/Prosym2012-27-320.jpg)
![ループ展開してみた
int sum2(const uint8_t data[4], int n) {
int sum = 0;
switch (n) {
case 3: sum += data[2];
case 2: sum += data[1];
case 1: sum += data[0];
}
return sum;
}
Xeon 35→26clk, i7 30→24clk
Loop Stream Detector(LSD)
夏のプログラムシンポジウム2012 28 / 33](https://image.slidesharecdn.com/prosym2012-120824234019-phpapp01/85/Prosym2012-28-320.jpg)
![psadbwを使ってみる
psadbw X, Y
MPEGなどのビデオコーデックにおいて
二つのbyte単位のデータの差の絶対値の和を求める命令
psadbw(X, Y) = sum [abs(X[i] – Y[i]) | i = 0..7]
画像の一致度を求める
Y = 0とするとXのbyte単位の和を求められる
Xをマスクして足せばよい
x0 x1 x2 x3 x4 x5 x6 x7
and
0xff 0xff 0xff 0 0 0 0 0
x0 x1 x2 0 0 0 0 0
夏のプログラムシンポジウム2012
x0 + x1 + x2 29 / 33](https://image.slidesharecdn.com/prosym2012-120824234019-phpapp01/85/Prosym2012-29-320.jpg)
![実際のコード
int sum3(const uint8_t data[4], int n) {
uint32_t x = *reinterpret_cast<const uint32_t*>(data);
x &= (1U << (n * 8)) - 1;
V128 v(x);
v = psadbw(v, Zero());
return movd(v);
}
Xeon 35→26→10clk!
i7 30→24→10clk!
速くなった
このコードはn < 8まで適用可能
ちょっと改良すればn < 16まで可能
夏のプログラムシンポジウム2012 30 / 33](https://image.slidesharecdn.com/prosym2012-120824234019-phpapp01/85/Prosym2012-30-320.jpg)

![分岐除去
先程のコードはgcc4.6では条件分岐命令を生成する
データがランダムなら確率50%で分岐予測が外れる
cmovを使って実装
条件が成立したときのみmovを行う命令
if (n > 64)はcarryを変更しなければ一度だけでよい
6clkぐらい速くなる
メモリアクセスの影響が多いと見えにくくなる
or(m0, -1);
and(n, 64); // ZF = (n < 64) ? 1 : 0
cmovz(m0, mask); // m0 = (!(n > 64)) ? mask : -1
cmovz(mask, idx); // mask = (n > 64) ? mask : 0
and(m0, ptr [blk + rax * 8 + 0]);
and(mask, ptr [blk + rax * 8 + 8]);
popcnt(m0, m0);
popcnt(rax, mask);
夏のプログラムシンポジウム2012 32 / 33](https://image.slidesharecdn.com/prosym2012-120824234019-phpapp01/85/Prosym2012-32-320.jpg)