Recommended
PDF
PDF
PDF
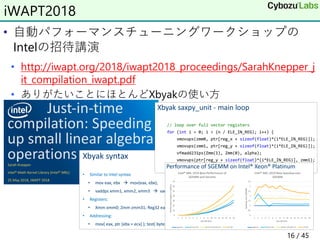
Intro to SVE 富岳のA64FXを触ってみた
PDF
ネットワーク ゲームにおけるTCPとUDPの使い分け
PPTX
PDF
PPTX
PDF
PDF
PPT
PDF
CPU / GPU高速化セミナー!性能モデルの理論と実践:実践編
PDF
PDF
【Unite Tokyo 2019】Understanding C# Struct All Things
PPTX
PDF
PDF
導入から 10 年、PHP の trait は滅びるべきなのか その適切な使いどころと弱点、将来について
PPTX
BuildKitによる高速でセキュアなイメージビルド
PDF
ARM CPUにおけるSIMDを用いた高速計算入門
PPTX
C#や.NET Frameworkがやっていること
PDF
サーバー未経験者がソーシャルゲームを通して知ったサーバーの事
PDF
PPTX
PDF
PDF
PDF
PDF
PDF
PDF
PDF
PDF
More Related Content
PDF
PDF
PDF
Intro to SVE 富岳のA64FXを触ってみた
PDF
ネットワーク ゲームにおけるTCPとUDPの使い分け
PPTX
PDF
PPTX
PDF
What's hot
PDF
PPT
PDF
CPU / GPU高速化セミナー!性能モデルの理論と実践:実践編
PDF
PDF
【Unite Tokyo 2019】Understanding C# Struct All Things
PPTX
PDF
PDF
導入から 10 年、PHP の trait は滅びるべきなのか その適切な使いどころと弱点、将来について
PPTX
BuildKitによる高速でセキュアなイメージビルド
PDF
ARM CPUにおけるSIMDを用いた高速計算入門
PPTX
C#や.NET Frameworkがやっていること
PDF
サーバー未経験者がソーシャルゲームを通して知ったサーバーの事
PDF
PPTX
PDF
PDF
PDF
PDF
PDF
PDF
Similar to Xbyakの紹介とその周辺
PDF
PDF
PPTX
PDF
PDF
PDF
セキュアVMの構築 (IntelとAMDの比較、あともうひとつ...) - AVTokyo 2009
PDF
LLVMで遊ぶ(整数圧縮とか、x86向けの自動ベクトル化とか)
PDF
PDF
PDF
PDF
PDF
PDF
PDF
PDF
オープンソース開発と、�あるフレームバッファコンソールの話�~名古屋応用編~
PPT
PDF
PDF
PDF
PDF
SpectreBustersあるいはLinuxにおけるSpectre対策
More from MITSUNARI Shigeo
PDF
PDF
PDF
PDF
PDF
PDF
PDF
PDF
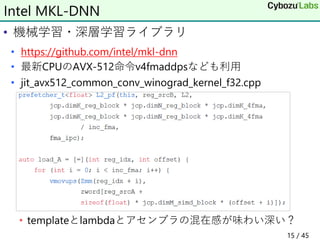
Intel AVX-512/富岳SVE用SIMDコード生成ライブラリsimdgen
PDF
PDF
PDF
PDF
PDF
PDF
深層学習フレームワークにおけるIntel CPU/富岳向け最適化法
PDF
PDF
Lifted-ElGamal暗号を用いた任意関数演算の二者間秘密計算プロトコルのmaliciousモデルにおける効率化
PDF
PDF
PDF
PDF
Xbyakの紹介とその周辺 1. 2. 3. 4. • NASM, gasなどの通常の静的なアセンブラに比べて
• コードを書きやすい(個人の感想)
• C++との連係がしやすい(個人の...)
• VMを書きやすい(略)
• V8やWebkitなどのJavaScriptエンジンも同等の
JITアセンブラを持ってる(ARMなどにも対応してる)
従来のアセンブラとの比較
4 / 45
5. 6. • MASMに似せるための各種演算子オーバーロード
• Intel命令をそのまま書けるので直感的に操作しやすい
• 小さなブロックを組み合わせて作る感覚が楽しい
雰囲気
void gen_add(const RegExp& dst, const RegExp& src);
void f(int n) {
auto addr = n > 0 ? rsi + rax * 8 + n * 8 : rdi;
mov(rax, ptr[addr]);
vgatherqpd(zmm5 | k7, ptr [rax + 64 + zmm21 * 2]);
gen_add(rsp + 8, rsi + 8);
}
6 / 45
7. • template引数で長さを指定する整数クラス
• 最大の大きさを指定するNはコンパイル時指定
• 実際の整数の大きさを指定するnは実行時指定
• このようなNを外部アセンブラと連係するのは面倒
固定多倍長加算
template<size_t N>
struct Int {
void init(size_t n); // n * 64 bit整数として利用(n < N)
uint64_t d[N];
// z = x + y
void (*add)(Int& z, const Int& x, const Int& y);
};
7 / 45
8. • 64 * n-bit加算(ビット長に応じたコード生成)
多倍長加算の例
GenAdd(int n) {
for (int i = 0; i < n; i++) {
mov(rax, ptr [x+i*8]);
if (i == 0) add(rax, ptr [y+i*8]);
else adc(rax, ptr [y+i*8]);
mov(ptr [z+i*8], rax);
}
ret(); }
add3:
mov rax, [rsi]
add rax, [rdx]
mov [rdi], rax
mov rax, [rsi + 8]
adc rax, [rdx + 8]
mov [rdi + 8], rax
mov rax, [rsi + 16]
adc rax, [rdx + 16]
mov [rdi + 16], rax
ret
add2:
mov rax, [rsi]
add rax, [rdx]
mov [rdi], rax
mov rax, [rsi + 8]
adc rax, [rdx + 8]
mov[rdi + 8], eax
ret
N=2 N=3
8 / 45
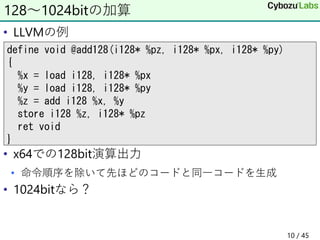
9. 10. • LLVMの例
• x64での128bit演算出力
• 命令順序を除いて先ほどのコードと同一コードを生成
• 1024bitなら?
128~1024bitの加算
define void @add128(i128* %pz, i128* %px, i128* %py)
{
%x = load i128, i128* %px
%y = load i128, i128* %py
%z = add i128 %x, %y
store i128 %z, i128* %pz
ret void
}
10 / 45
11. • 怒濤のレジスタスピル(溢れ)
• xとyを足してzに配置するとき
下位レジスタから順にやれば
データの退避は不要
• それを把握していないので
一度スタックにコピーしてる
• 無駄にSIMDを使って遅くなる
こともある
• 余談
• llcに-pre-RA-sched=list-ilp
-max-sched-reorder=16
でspillしなくなる(たまたま?)
• llc --help-hiddenすると大量の隠しオプションが現れる
• バージョン非互換なものも多い
1024bitの加算の出力
movq 16(%rsi), %r13
movq (%rsi), %rbx
movq 8(%rsi), %r15
movq 120(%rdx), %rax
movq %rax, -8(%rsp) # 8-byte Spill
movq 112(%rdx), %rax
movq 104(%rdx), %rcx
movq %rcx, -24(%rsp) # 8-byte Spill
movq 96(%rdx), %rcx
movq 88(%rdx), %rbp
movq %rbp, -32(%rsp) # 8-byte Spill
movq 80(%rdx), %r8
movq 72(%rdx), %r12
movq 64(%rdx), %r14
movq 56(%rdx), %rbp
addq (%rdx), %rbx
movq %rbx, -16(%rsp) # 8-byte Spill
...
11 / 45
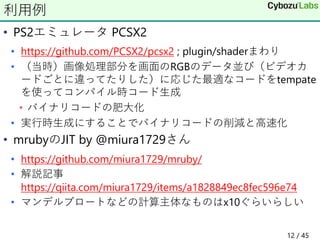
12. • PS2エミュレータ PCSX2
• https://github.com/PCSX2/pcsx2 ; plugin/shaderまわり
• (当時)画像処理部分を画面のRGBのデータ並び(ビデオカ
ードごとに違ってたりした)に応じた最適なコードをtempate
を使ってコンパイル時コード生成
• バイナリコードの肥大化
• 実行時生成にすることでバイナリコードの削減と高速化
• mrubyのJIT by @miura1729さん
• https://github.com/miura1729/mruby/
• 解説記事
https://qiita.com/miura1729/items/a1828849ec8fec596e74
• マンデルブロートなどの計算主体なものはx10ぐらいらしい
利用例
12 / 45
13. • 正規表現JITエンジン by @sinya8282
• https://github.com/sinya8282/Regen
• JavaScript VMのJIT by @Constellation
• https://github.com/Constellation/iv/
• http://labs.cybozu.co.jp/youth.html
サイボウズ・ラボユース生によるJIT
13 / 45
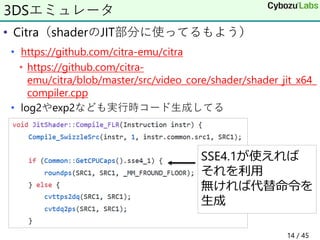
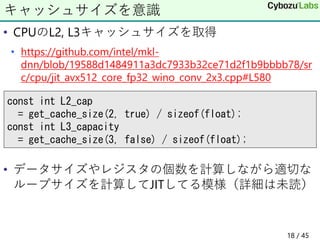
14. 15. 16. 17. 18. • CPUのL2, L3キャッシュサイズを取得
• https://github.com/intel/mkl-
dnn/blob/19588d1484911a3dc7933b32ce71d2f1b9bbbb78/sr
c/cpu/jit_avx512_core_fp32_wino_conv_2x3.cpp#L580
• データサイズやレジスタの個数を計算しながら適切な
ループサイズを計算してJITしてる模様(詳細は未読)
キャッシュサイズを意識
const int L2_cap
= get_cache_size(2, true) / sizeof(float);
const int L3_capacity
= get_cache_size(3, false) / sizeof(float);
18 / 45
19. 20. 21. • jnl(jump if not less)がIntelコンパイラでエラー
• UNIX系コンパイラは各種特殊数学関数を持っている
• jnlは次数nの第1種Bessel関数のlong double版
• j1とかy0とかynなど、そんなグローバル関数が!と思うもの
がいろいろ
• https://www.gnu.org/software/libc/manual/html_node/Speci
al-Functions.html
• コンパイラの実装によっては関数はマクロでもよいらしい
• C++17ではまともな名前でcmathに登場
• j1 → std::cyl_bessel_j(1, x)
• yn(n, x) → std::neumann(n, x)
いろいろなトラブル
21 / 45
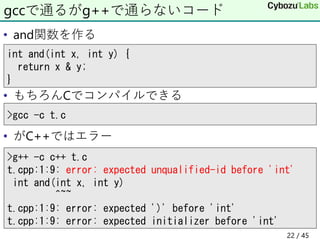
22. • and関数を作る
• もちろんCでコンパイルできる
• がC++ではエラー
gccで通るがg++で通らないコード
>g++ -c c++ t.c
t.cpp:1:9: error: expected unqualified-id before 'int'
int and(int x, int y)
^~~
t.cpp:1:9: error: expected ')' before 'int'
t.cpp:1:9: error: expected initializer before 'int'
>gcc -c t.c
int and(int x, int y) {
return x & y;
}
22 / 45
23. • C++ではand, or, xor, not, and_eq, bitorなどが予約語
• 関数名に使えない
• VCではiso646.hをincludeしないなら使える
• gcc/clangでは-fno-operator-namesオプションで無効化
• うっかり忘れると一見意味不明な大量のエラー
• Xbyakでは
• and_(), or_()などアンダースコアをつけた名前に変更
• 後方互換性のためand(), or()などもサポート
• -fno-operator-namesなしで使おうとすると
"use -fno-operator-names option"という#errorを表示してる
• どうやって?
代替表現(Alternative representations)
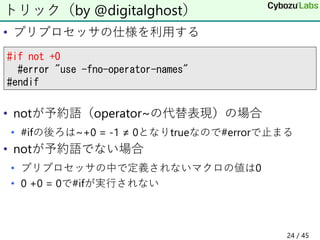
23 / 45
24. 25. • N = 32700ぐらいでエラー
• WindowsでならNがもっと大きくても動く
• メモリが足りないわけではない
Linuxでたくさんnewできないという報告
struct Code : Xbyak::CodeGenerator {
Code(int x) {
mov(eax, x);
ret();
}
};
std::vector<std::unique_ptr<Code>> v(N);
for (int i = 0; i < N; i++) {
v[i] = std::make_unique<Code>(i);
}
25 / 45
26. • 1プロセスあたりのメモリマップの上限
• デフォルト65536
• Xbyakのposix_memalign + mprotectは2個消費する
• スレッドも1スレッドあたり2個消費する
• 上限に達するとmprotectはENOMEMを返す
• XBYAK_USE_MMAP_ALLOCATORを定義すると大丈夫
• posix_memalignの代わりにmmapを使うallocator
• 何故かこの上限に掛からなくなる
• https://www.kernel.org/doc/Documentation/sysctl/vm.t
xtにはmmap, mprotect, madviseの呼び出しに影響とある
• 70万個とかでも作れるようになる
/proc/sys/vm/max_map_count
26 / 45
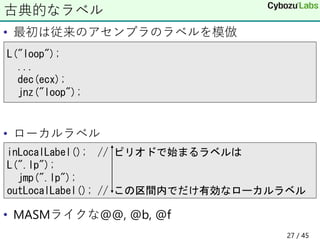
27. • 最初は従来のアセンブラのラベルを模倣
• ローカルラベル
• MASMライクな@@, @b, @f
古典的なラベル
L("loop");
...
dec(ecx);
jnz("loop");
inLocalLabel(); // ピリオドで始まるラベルは
L(".lp");
jmp(".lp");
outLocalLabel(); // この区間内でだけ有効なローカルラベル
27 / 45
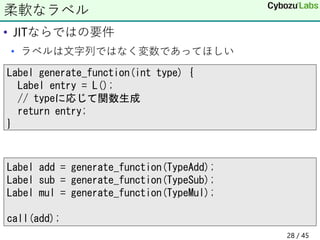
28. • JITならではの要件
• ラベルは文字列ではなく変数であってほしい
柔軟なラベル
Label generate_function(int type) {
Label entry = L();
// typeに応じて関数生成
return entry;
}
Label add = generate_function(TypeAdd);
Label sub = generate_function(TypeSub);
Label mul = generate_function(TypeMul);
call(add);
28 / 45
29. • ラベルを即値として扱う
ジャンプテーブルも作りたい
Label labelTbl, L0, L1, L2;
mov(rax, labelTbl); // アドレスを代入
jmp(ptr [rax + rcx * sizeof(void*)]);
jmp(ptr [rip + L0]);// L0への相対アドレッシングジャンプ
// ジャンプテーブル
L(labelTbl);
putL(L0); // ラベルのアドレスをメモリに配置
putL(L1);
L(L0);
mov(a, ret0);
ret();
L(L1);
...
29 / 45
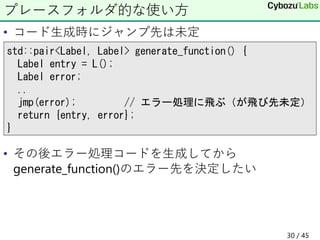
30. 31. • 2個のラベルをリンクさせる
assignL(dstLabel, srcLabel);
{add, err1} = gen_func(...); // 飛び先未定のラベル
{sub, err2} = gen_func(...); // 飛び先未定のラベル
closeErr = L();
// closeのエラー処理
criticalErr = L();
// criticalエラーの処理
asignL(err1, closeErr); //add関数内のエラーはcloseErr
asignL(err2, criticalErr); //sub関数のエラーはcriticalErr
31 / 45
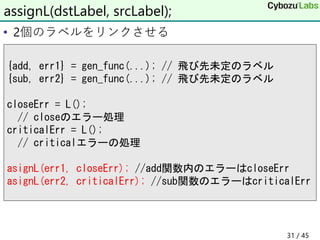
32. • 8文字からなる言語
• [ ; ポインタが示す値が0なら]にジャンプ
• ] ; 対応する[にジャンプ
• while (*cur) { ... }に相当
BrainfuckのJIT
stack<Label> labelB, labelF;
case '[':
labelB.push(L());
mov(eax, cur);
test(eax, eax);
Label F;
jz(F, T_NEAR);
labelF.push(F);
break;
case ']':
jmp(labelB.top()); labelB.pop();
L(labelF.top()); labelF.pop();
break;
B: // [
mov rax, [rcx]
test eax, eax
jz F
... // ネストする
jmp B // ]
F:
32 / 45
33. • ラベルがL()でアドレス確定されるごとに
• そのラベルを参照している全ての未定義一覧のアドレス解決
• ラベルがジャンプ命令で指定されるごとに
• 既にラベル先が確定しているものはアドレス確定
• その時点で行き先が未定義のもののものは未定義一覧に追加
• + 相対ジャンプで管理すべきものもある
• assignL()はリンクを変更
• ローカルラベルやスコープを抜けたラベルは管理外に
• 数が多いので保持し続けるとラベル解決の速度劣化に
• ラベルはコピーされるとスコープの外に出ることがある
• 参照カウンタで管理
ラベル管理の内部
33 / 45
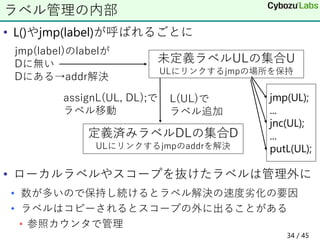
34. • L()やjmp(label)が呼ばれるごとに
• ローカルラベルやスコープを抜けたラベルは管理外に
• 数が多いので保持し続けるとラベル解決の速度劣化の要因
• ラベルはコピーされるとスコープの外に出ることがある
• 参照カウンタで管理
ラベル管理の内部
未定義ラベルULの集合U
ULにリンクするjmpの場所を保持
定義済みラベルDLの集合D
ULにリンクするjmpのaddrを解決
L(UL)で
ラベル追加
jmp(label)のlabelが
Dに無い
Dにある→addr解決
jmp(UL);
...
jnc(UL);
...
putL(UL);
assignL(UL, DL);で
ラベル移動
34 / 45
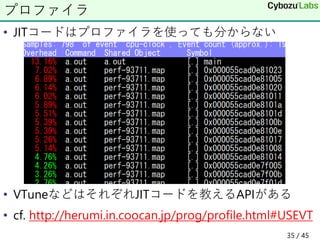
35. 36. • perfの場合/tmp/perf-<pid>.mapに1行ずつ
を書いておくと集計時に自動的に利用してくれる
perf with JIT code
アドレス サイズ 名前
PerfMap::set(const void *p, size_t n, const char *name) {
fprintf(fp, "%llx %zx %s¥n", (long long)p, n, name);
}
PerfMap pm;
pm.set(c.getCode(), c.getSize(), "fff");
pm.set(c2.getCode(), c2.getSize(), "ggg");
36 / 45
37. • testはnasm, yasmなどのツールの出力と比較して確認
• 新命令はツールが間違ってることが多いので悩ましい
• nasmは何度もバグ報告してる
• 昔はyasmの方が信頼性が高かったが最近更新されてない
• Intelのマニュアルが間違ってることもある
• 印象に残っているバグをいくつか
• VM上で未定義命令エラー
• cpuidを見てCPUが新命令に対応している判別してコード生成
• host CPUはその命令に対応しているがgestのVMは非対応
しかしVMはhostのcpuidを返していた
• 生成された命令を実行してillegal instruction(ややこしい)
バグ
37 / 45
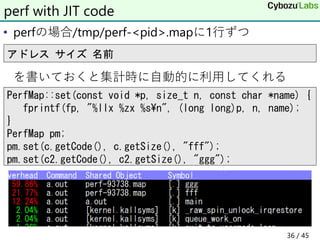
38. • t.asm
• yasm -f win32 -l t.lst t.asm
• EBFEではなくEB00が正解
• 生成オブジェクトは正しいEB00を出力
• 正しく実行はできるので結構悩んだ
• チケットには2011年に登録されていた
• https://tortall.lighthouseapp.com/projects/78676/tickets/233
-byte-code-in-listing-differs-from-emitted-bytes
• 実は最新版でも直ってない
yasmのlstとobjの不一致
jmp L
L:
1 %line 1+1 t.asm
2 00000000 EBFE jmp L
3 L:
38 / 45
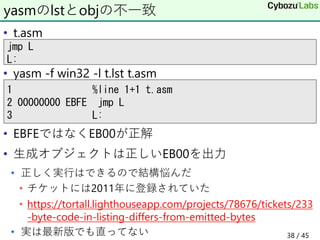
39. • 別の命令(1to2)を挟むと逆アセンブル結果がバグる
• 最初は正しい出力なので混乱した
• https://sourceware.org/bugzilla/show_bug.cgi?id=23025
• 報告して10時間でpatchが作成された
objdumpの逆アセンブル出力
>objdump -M x86-64 -D -b binary -m i386 vcvtpd2dq.bin
67 c5 fb e6 40 20 vcvtpd2dqx 0x20(%eax),%xmm0; (X)
67 c5 ff e6 40 20 vcvtpd2dqy 0x20(%eax),%xmm0; (Y)
67 62 f1 ff 18 e6 40 04 vcvtpd2dq 0x20(%eax){1to2},%xmm0
67 c5 fb e6 40 20 vcvtpd2dq 0x20(%eax),%xmm0 ; (X')
67 c5 ff e6 40 20 vcvtpd2dq 0x20(%eax),%xmm0 ; (Y')
39 / 45
40. • vgatherdps(zmm0|k1, ptr [rax + zmm18]); が
vgatherdps(zmm0|k1, ptr [rax + zmm2]);になるバグ
• VSIBエンコーディング
• 従来のSIB ; [eax + ebx * scale + offset] ; レジスタ8種類
• 64bit対応 ; 16種類レジスタを表現するため1bit増える
• その1bitはREXプレフィックスの中に
• VSIB ; AVX2でSIMDレジスタを指定できるようになった
XbyakのVSIBエンコーディングバグ
SDM2.3.12 Vector SIB(VSIB) Memory Addressing 40 / 45
41. • VSIBやREXでは足りない
• ?mm16~?mm31までのレジスタはどうやって指定?
• EVEX.vvvvビット
• addpd(zmm31, zmm30, zmm20);などはちゃんと実装していた
• SDM2.6.1 Instruction Format and EVEX
• VSIBのときEVEX.V'をoffにするのだった
• 単なる見落とだがVSIB Memory Addressingのところの記述は
変わってないし……(言い訳)
AVX-512でレジスタは32個
EVEXV’ High-16 NDS/VIDX register specifier
P[19] Combine with EVEX.vvvv or when VSIB present.
41 / 45
42. 43. • Intel Software Development Emulator
• https://software.intel.com/en-us/articles/intel-software-
development-emulator
• 当たり前だが一番信頼できる
• xed -mpx -64 -ir <rawobj>でdisassemblerとして利用可能
• vgatherdps(zmm0|k1, ptr[rax + zmm2]);
の出力は正しくdisasできるのに
vgatherdps(zmm0|k1, ptr[rax + zmm0]);
の出力はエラー
• 両方とも同じエンコードパスを通るのに何故?
Intel SDEの仕様に悩む
ERROR: GATHER_REGS Could not decode at offset: 0x0
PC: 0x0: [62F27D49920400]
43 / 45
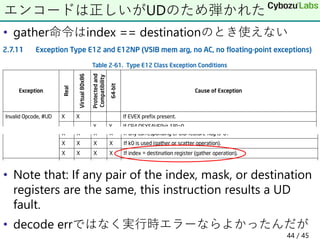
44. • gather命令はindex == destinationのとき使えない
• Note that: If any pair of the index, mask, or destination
registers are the same, this instruction results a UD
fault.
• decode errではなく実行時エラーならよかったんだが
エンコードは正しいがUDのため弾かれた
44 / 45
45.



![• MASMに似せるための各種演算子オーバーロード
• Intel命令をそのまま書けるので直感的に操作しやすい
• 小さなブロックを組み合わせて作る感覚が楽しい
雰囲気
void gen_add(const RegExp& dst, const RegExp& src);
void f(int n) {
auto addr = n > 0 ? rsi + rax * 8 + n * 8 : rdi;
mov(rax, ptr[addr]);
vgatherqpd(zmm5 | k7, ptr [rax + 64 + zmm21 * 2]);
gen_add(rsp + 8, rsi + 8);
}
6 / 45](https://image.slidesharecdn.com/kernelvm-20180922-180922080227/85/Xbyak-6-320.jpg)
![• template引数で長さを指定する整数クラス
• 最大の大きさを指定するNはコンパイル時指定
• 実際の整数の大きさを指定するnは実行時指定
• このようなNを外部アセンブラと連係するのは面倒
固定多倍長加算
template<size_t N>
struct Int {
void init(size_t n); // n * 64 bit整数として利用(n < N)
uint64_t d[N];
// z = x + y
void (*add)(Int& z, const Int& x, const Int& y);
};
7 / 45](https://image.slidesharecdn.com/kernelvm-20180922-180922080227/85/Xbyak-7-320.jpg)
![• 64 * n-bit加算(ビット長に応じたコード生成)
多倍長加算の例
GenAdd(int n) {
for (int i = 0; i < n; i++) {
mov(rax, ptr [x+i*8]);
if (i == 0) add(rax, ptr [y+i*8]);
else adc(rax, ptr [y+i*8]);
mov(ptr [z+i*8], rax);
}
ret(); }
add3:
mov rax, [rsi]
add rax, [rdx]
mov [rdi], rax
mov rax, [rsi + 8]
adc rax, [rdx + 8]
mov [rdi + 8], rax
mov rax, [rsi + 16]
adc rax, [rdx + 16]
mov [rdi + 16], rax
ret
add2:
mov rax, [rsi]
add rax, [rdx]
mov [rdi], rax
mov rax, [rsi + 8]
adc rax, [rdx + 8]
mov[rdi + 8], eax
ret
N=2 N=3
8 / 45](https://image.slidesharecdn.com/kernelvm-20180922-180922080227/85/Xbyak-8-320.jpg)








![• N = 32700ぐらいでエラー
• WindowsでならNがもっと大きくても動く
• メモリが足りないわけではない
Linuxでたくさんnewできないという報告
struct Code : Xbyak::CodeGenerator {
Code(int x) {
mov(eax, x);
ret();
}
};
std::vector<std::unique_ptr<Code>> v(N);
for (int i = 0; i < N; i++) {
v[i] = std::make_unique<Code>(i);
}
25 / 45](https://image.slidesharecdn.com/kernelvm-20180922-180922080227/85/Xbyak-25-320.jpg)

![• ラベルを即値として扱う
ジャンプテーブルも作りたい
Label labelTbl, L0, L1, L2;
mov(rax, labelTbl); // アドレスを代入
jmp(ptr [rax + rcx * sizeof(void*)]);
jmp(ptr [rip + L0]);// L0への相対アドレッシングジャンプ
// ジャンプテーブル
L(labelTbl);
putL(L0); // ラベルのアドレスをメモリに配置
putL(L1);
L(L0);
mov(a, ret0);
ret();
L(L1);
...
29 / 45](https://image.slidesharecdn.com/kernelvm-20180922-180922080227/85/Xbyak-29-320.jpg)
![• 8文字からなる言語
• [ ; ポインタが示す値が0なら]にジャンプ
• ] ; 対応する[にジャンプ
• while (*cur) { ... }に相当
BrainfuckのJIT
stack<Label> labelB, labelF;
case '[':
labelB.push(L());
mov(eax, cur);
test(eax, eax);
Label F;
jz(F, T_NEAR);
labelF.push(F);
break;
case ']':
jmp(labelB.top()); labelB.pop();
L(labelF.top()); labelF.pop();
break;
B: // [
mov rax, [rcx]
test eax, eax
jz F
... // ネストする
jmp B // ]
F:
32 / 45](https://image.slidesharecdn.com/kernelvm-20180922-180922080227/85/Xbyak-32-320.jpg)



![• vgatherdps(zmm0|k1, ptr [rax + zmm18]); が
vgatherdps(zmm0|k1, ptr [rax + zmm2]);になるバグ
• VSIBエンコーディング
• 従来のSIB ; [eax + ebx * scale + offset] ; レジスタ8種類
• 64bit対応 ; 16種類レジスタを表現するため1bit増える
• その1bitはREXプレフィックスの中に
• VSIB ; AVX2でSIMDレジスタを指定できるようになった
XbyakのVSIBエンコーディングバグ
SDM2.3.12 Vector SIB(VSIB) Memory Addressing 40 / 45](https://image.slidesharecdn.com/kernelvm-20180922-180922080227/85/Xbyak-40-320.jpg)
![• VSIBやREXでは足りない
• ?mm16~?mm31までのレジスタはどうやって指定?
• EVEX.vvvvビット
• addpd(zmm31, zmm30, zmm20);などはちゃんと実装していた
• SDM2.6.1 Instruction Format and EVEX
• VSIBのときEVEX.V'をoffにするのだった
• 単なる見落とだがVSIB Memory Addressingのところの記述は
変わってないし……(言い訳)
AVX-512でレジスタは32個
EVEXV’ High-16 NDS/VIDX register specifier
P[19] Combine with EVEX.vvvv or when VSIB present.
41 / 45](https://image.slidesharecdn.com/kernelvm-20180922-180922080227/85/Xbyak-41-320.jpg)

![• Intel Software Development Emulator
• https://software.intel.com/en-us/articles/intel-software-
development-emulator
• 当たり前だが一番信頼できる
• xed -mpx -64 -ir <rawobj>でdisassemblerとして利用可能
• vgatherdps(zmm0|k1, ptr[rax + zmm2]);
の出力は正しくdisasできるのに
vgatherdps(zmm0|k1, ptr[rax + zmm0]);
の出力はエラー
• 両方とも同じエンコードパスを通るのに何故?
Intel SDEの仕様に悩む
ERROR: GATHER_REGS Could not decode at offset: 0x0
PC: 0x0: [62F27D49920400]
43 / 45](https://image.slidesharecdn.com/kernelvm-20180922-180922080227/85/Xbyak-43-320.jpg)