


















![01 import java.io.IOException;
02 import java.util.StringTokenizer;
03
04 import org.apache.hadoop.conf.Configuration;
05 import org.apache.hadoop.fs.Path;
06 import org.apache.hadoop.io.IntWritable;
07 import org.apache.hadoop.io.Text;
08 import org.apache.hadoop.mapreduce.Job;
09 import org.apache.hadoop.mapreduce.Mapper;
10 import org.apache.hadoop.mapreduce.Reducer;
11 import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
12 import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
13
14 public class WordCount {
15
16 public static class TokenizerMapper
17 extends Mapper<Object, Text, Text, IntWritable>{
18
19 private final static IntWritable one = new IntWritable(1);
20 private Text word = new Text();
21
22 public void map(Object key, Text value, Context context
23 ) throws IOException, InterruptedException {
24 StringTokenizer itr = new StringTokenizer(value.toString());
25 while (itr.hasMoreTokens()) {
26 word.set(itr.nextToken());
27 context.write(word, one);
28 }
29 }
30 }
31
32 public static class IntSumReducer
33 extends Reducer<Text,IntWritable,Text,IntWritable> {
34 private IntWritable result = new IntWritable();
35
36 public void reduce(Text key, Iterable<IntWritable> values,
37 Context context
38 ) throws IOException, InterruptedException {
39 int sum = 0;
40 for (IntWritable val : values) {
41 sum += val.get();
42 }
43 result.set(sum);
44 context.write(key, result);
45 }
46 }
47
48 public static void main(String[] args) throws Exception {
49 Configuration conf = new Configuration();
50 Job job = Job.getInstance(conf, "word count");
51 job.setJarByClass(WordCount.class);
52 job.setMapperClass(TokenizerMapper.class);
53 job.setCombinerClass(IntSumReducer.class);
54 job.setReducerClass(IntSumReducer.class);
55 job.setOutputKeyClass(Text.class);
56 job.setOutputValueClass(IntWritable.class);
57 FileInputFormat.addInputPath(job, new Path(args[0]));
58 FileOutputFormat.setOutputPath(job, new Path(args[1]));
59 System.exit(job.waitForCompletion(true) ? 0 : 1);
60 }
61 }
01 import org.apache.spark.SparkContext
02 import org.apache.spark.SparkContext._
03
04 object WordCount {
05 def main(args: Array[String]): Unit = {
06 val sc = new SparkContext()
07 val lines = sc.textFile(args(0))
08 val wordCounts = lines.flatMap {line => line.split(" ")}
09 .map(word => (word, 1))
10 .reduceByKey(_ + _)
11 wordCounts.saveAsTextFile(args(1))
12 }
13 }](https://image.slidesharecdn.com/bigdataanalyticswithspark-151005141832-lva1-app6892/85/Big-Data-Analytics-with-Spark-35-320.jpg)





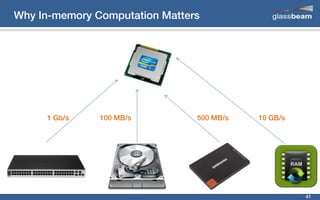
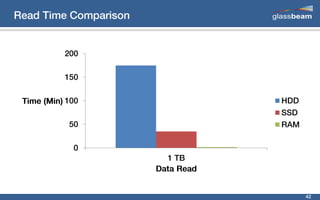

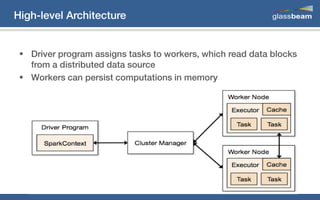
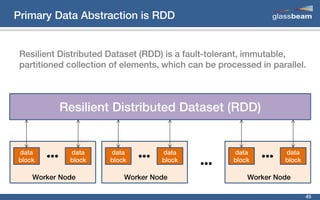











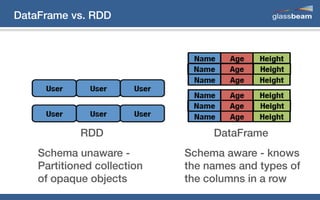













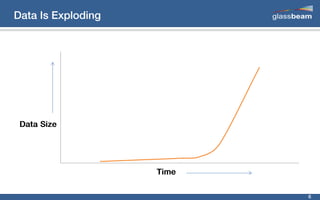
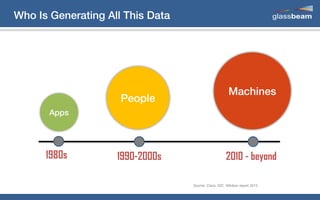
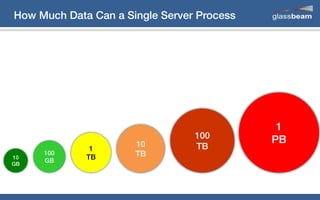
This document discusses big data analytics using Spark. It provides an overview of the history and growth of data from the 1980s to present. It then demonstrates how to perform word count analytics on text data using both traditional MapReduce techniques in Hadoop as well as using Spark. The code examples show how to tokenize text, count word frequencies, and output results.




































































![[DSC Europe 25] Bojan Banjac - AI is always right when it comes to the matter...](https://cdn.slidesharecdn.com/ss_thumbnails/syoxtqierpydwxm5srcb-4-bojan-banjac-ai-is-always-right-when-it-comes-to-the-matters-of-taste-260119101519-694ee7d7-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DSC Europe 25] Tali Fulman - Guild Meetings, Then What? Building Data Commun...](https://cdn.slidesharecdn.com/ss_thumbnails/fgohhi33rwmhqdowdj5k-tali-fulman-guild-meetings-then-what-building-data-communities-that-actually-ch-260120105855-528492c3-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Borko Kozomora - Optimizing business workflows with advances ...](https://cdn.slidesharecdn.com/ss_thumbnails/hbgekyb0txw0xpo4yfml-borko-kozomora-leading-ai-transformation-260122103838-cc29ee38-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Andrzej Kowalczyk - AI - how to start small and grow in the f...](https://cdn.slidesharecdn.com/ss_thumbnails/oy1zmo94qv6vpcqjvno2-andrzej-kowalczyk-ai-how-to-start-small-and-grow-in-the-future-1-260119121559-cf093b23-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DSC Europe 25] Laila Kakar - Leveraging AI for Strategic Excellence: Enhanci...](https://cdn.slidesharecdn.com/ss_thumbnails/eykmhrtsqmaaftwkexh7-dsc-lailakakar-1-260119101520-5f3b5616-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DSC Europe 25] Milovan Jovicic - Beyond AI's Reach: The Enduring Value of Ev...](https://cdn.slidesharecdn.com/ss_thumbnails/pyeij0hurgwq5jugmtnv-2-milovan-jovicic-beyond-ais-reach-the-enduring-value-of-evergreen-design-v2-260120105856-d6ee57e5-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DSC Europe 25] Ratko Nikolic - BI with AI: Automating Business Intelligence ...](https://cdn.slidesharecdn.com/ss_thumbnails/ecd7hahhq6qiwefuoiyw-dsc2025-ratko-nikolic-ai-data-analyst-260119101519-54d52956-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Josip Saban - Career building for data professionals.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/zroflcttkm1vmli0txea-josip-saban-career-building-for-data-professionals-260123083019-587cdb8c-thumbnail.jpg?width=640&height=640&fit=bounds)


