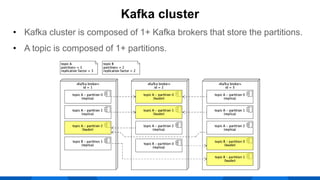
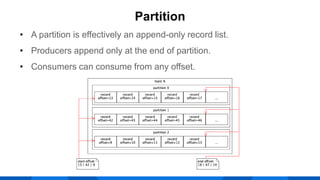
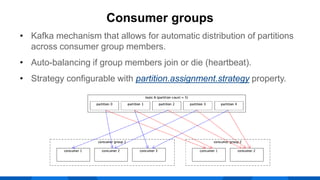
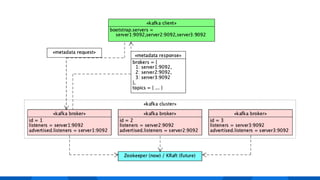
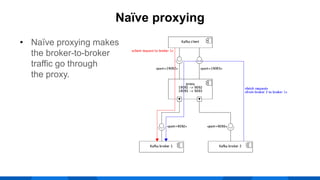
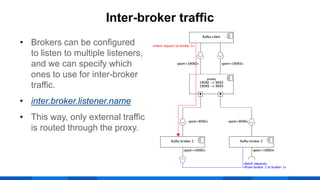
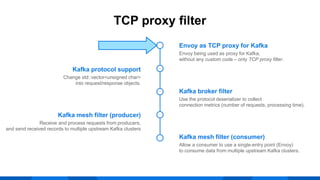
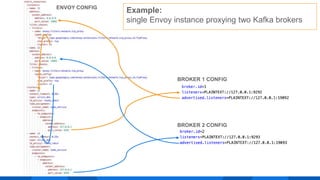
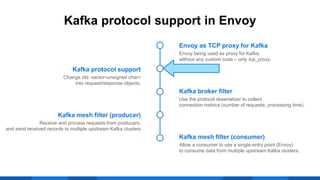
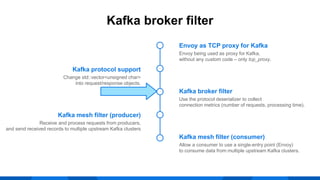
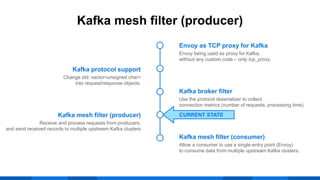
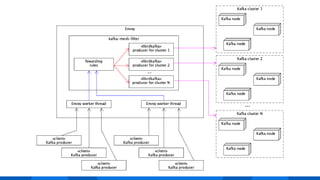
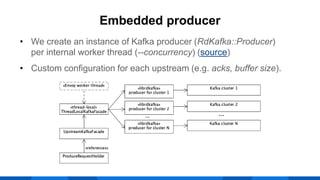
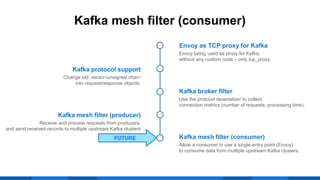
The document outlines the integration of Apache Kafka with Envoy as a proxy, elaborating on Kafka's streaming capabilities, partition management, and consumer/producer mechanics. It details the configuration of Envoy to handle Kafka traffic, including the use of TCP proxy filters and mesh filters for managing multiple upstream Kafka clusters. Additionally, it highlights various Kafka features, such as message durability, consumer group management, and the ability to process requests efficiently through smart clients.