Download as PDF, PPTX
















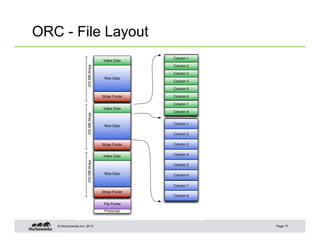
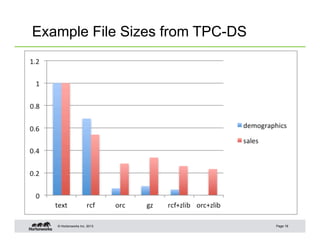








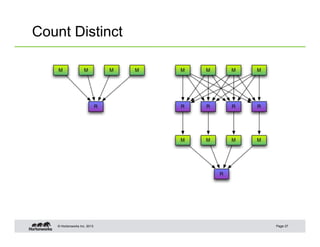





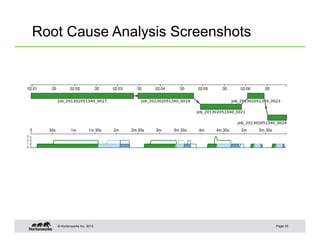


This document summarizes techniques for optimizing Hive queries, including recommendations around data layout, format, joins, and debugging. It discusses partitioning, bucketing, sort order, normalization, text format, sequence files, RCFiles, ORC format, compression, shuffle joins, map joins, sort merge bucket joins, count distinct queries, using explain plans, and dealing with skew.























































































