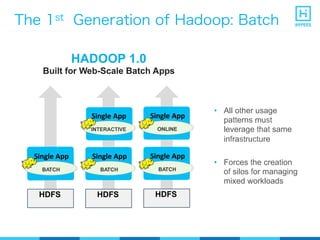
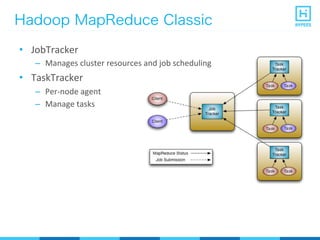
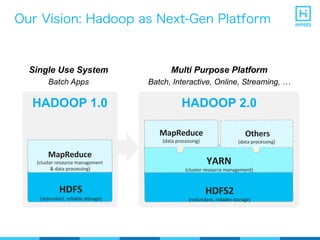
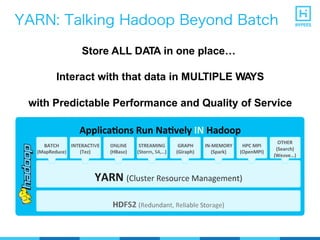
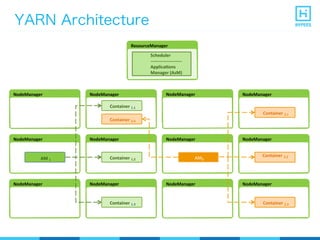
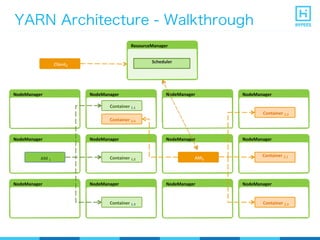
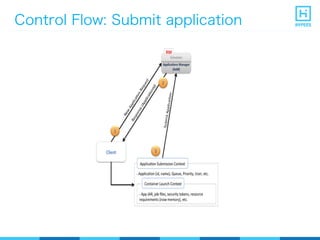
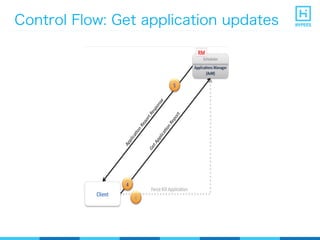
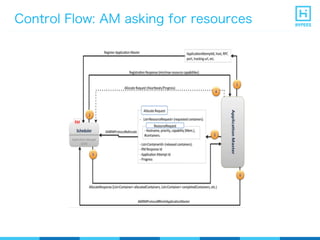
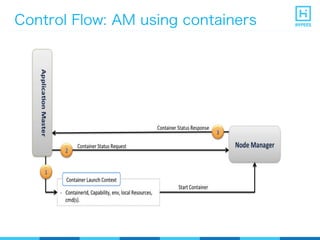
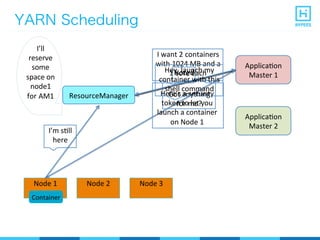
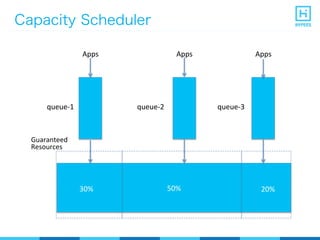
YARN (Yet Another Resource Negotiator) is a resource management framework for Hadoop clusters that improves on the scalability limitations of the original MapReduce framework. YARN separates resource management from job scheduling to allow multiple data processing engines like MapReduce, Spark, and Storm to share common cluster resources. It introduces a new architecture with a ResourceManager to allocate resources among applications and per-application ApplicationMasters to manage containers and scheduling within an application. This provides improved scalability, utilization, and multi-tenancy for a variety of workloads compared to the original Hadoop architecture.





















































































































![5G Explained! A High Level Overview [Introduction]](https://cdn.slidesharecdn.com/ss_thumbnails/5gexplainedahighleveloverview-260119165306-cc137a3e-thumbnail.jpg?width=640&height=640&fit=bounds)







