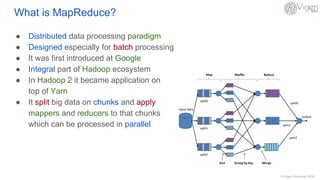
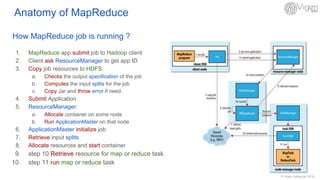
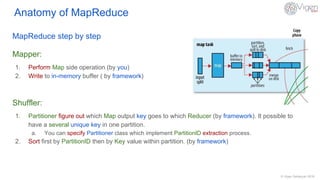
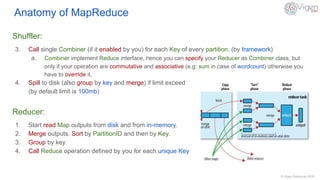
This document provides an overview of MapReduce in Hadoop. It defines MapReduce as a distributed data processing paradigm designed for batch processing large datasets in parallel. The anatomy of MapReduce is explained, including the roles of mappers, shufflers, reducers, and how a MapReduce job runs from submission to completion. Potential purposes are batch processing and long running applications, while weaknesses include iterative algorithms, ad-hoc queries, and algorithms that depend on previously computed values or shared global state.