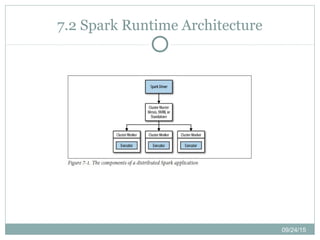
This chapter discusses running Spark applications on a cluster. It describes Spark's runtime architecture with a driver program and executor processes. It also covers options for deploying Spark, including the standalone cluster manager, Hadoop YARN, Apache Mesos, and Amazon EC2. The chapter provides guidance on configuring resources, packaging code, and choosing a cluster manager based on needs.