References
• [Platt 98]J. C. Platt, "Sequential Minimal Optimization: A Fast Algorithm for Training
Support Vector Machines", In Advances in Kernel Methods Support Vector Learning,
MIT Press, 1998.
– 元論文.基本的にこれを読めばよい
• [Cristianini+ 05] N. Cristianini, J. Shawe-Taylor (大北剛訳), “サポートベクタ―マシン入
門”, 共立出版, 2005.
– 7章でSMOを紹介
– 巻末に[Platt 98]の疑似コードに対する解説あり
• [Keerthi+ 01] S. S. Keerthi, S. K. Shevade, C. Bhattacharyya, K. R. K.
Murthy,”Improvements to Platt's SMO Algorithm for SVM Classifier Design”,
Neural Computation, vol. 13(3), pp.637-649, 2001.
– KKT条件チェックの高速化
• [Fan+ 05] R.-E. Fan, P.-H. Chen, C.-J. Lin, "Working Set Selection Using Second
Order Information for Training Support Vector Machines", Journal of Machine
Learning Research, vol.6, pp.1889?1918, 2005.
– 変数選択のWWS 3論文
– 目的関数の2次勾配の情報を用いることで適切な選択が可能
47




























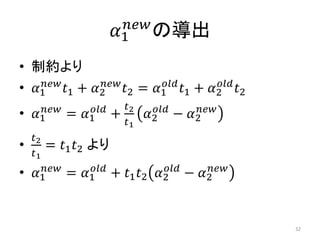




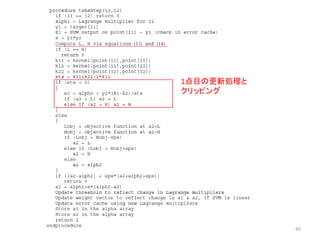
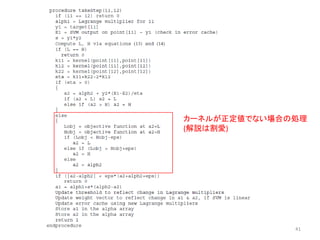
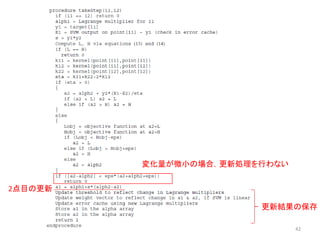
![疑似コード解説
37
[Platt 98] の疑似コードを眺める](https://image.slidesharecdn.com/20130505smoimplementation-130506122401-phpapp02/85/SMO-SVM-37-320.jpg)




![本資料で扱わなかったこと
• SMO実装に必要な情報
– 更新途中のバイアス計算
– 停止条件の解説
• SMOの改善
– KKT条件違反チェックの高速化 [Keerthi+ 01]
– LIBSVMのWSS3の解説 [Fan+ 05]
• その他
– 汎用QPソルバーの概説
※元気があればバージョンアップで対応予定
45](https://image.slidesharecdn.com/20130505smoimplementation-130506122401-phpapp02/85/SMO-SVM-45-320.jpg)

![References
• [Platt 98] J. C. Platt, "Sequential Minimal Optimization: A Fast Algorithm for Training
Support Vector Machines", In Advances in Kernel Methods Support Vector Learning,
MIT Press, 1998.
– 元論文.基本的にこれを読めばよい
• [Cristianini+ 05] N. Cristianini, J. Shawe-Taylor (大北剛訳), “サポートベクタ―マシン入
門”, 共立出版, 2005.
– 7章でSMOを紹介
– 巻末に[Platt 98]の疑似コードに対する解説あり
• [Keerthi+ 01] S. S. Keerthi, S. K. Shevade, C. Bhattacharyya, K. R. K.
Murthy,”Improvements to Platt's SMO Algorithm for SVM Classifier Design”,
Neural Computation, vol. 13(3), pp.637-649, 2001.
– KKT条件チェックの高速化
• [Fan+ 05] R.-E. Fan, P.-H. Chen, C.-J. Lin, "Working Set Selection Using Second
Order Information for Training Support Vector Machines", Journal of Machine
Learning Research, vol.6, pp.1889?1918, 2005.
– 変数選択のWWS 3論文
– 目的関数の2次勾配の情報を用いることで適切な選択が可能
47](https://image.slidesharecdn.com/20130505smoimplementation-130506122401-phpapp02/85/SMO-SVM-47-320.jpg)


![SSII2022 [TS1] Transformerの最前線〜 畳込みニューラルネットワークの先へ 〜](https://cdn.slidesharecdn.com/ss_thumbnails/ts120220608ssiitransformerr2-220607054025-3adacf07-thumbnail.jpg?width=640&height=640&fit=bounds)
















![[DL輪読会]`強化学習のための状態表現学習 -より良い「世界モデル」の獲得に向けて-](https://cdn.slidesharecdn.com/ss_thumbnails/20181026staterepresenration-181127055206-thumbnail.jpg?width=640&height=640&fit=bounds)

























































