SVM の動機付け
なぜSupport Vector に対してのみ Margin を最大化するとよ
いのか?
演習 7.1 と p36 の最終パラグラフ
共通のパラメータσ2 をもつガウスカーネルを用いて、Parzen
推定法を適用して、各クラスごとの入力ベクトル x の分布を
推定する。
1 1
p xt = k x, xn δ t, t n
Nt zk
n
ベイズの定理より、
p tx ∝p xt p t
7.
今、事前確率p t は無情報とすると、誤分類をなくす、すなわち事後確率
pt x が大きい t に振り分けるためには、p x t が大きい t を選べばよい。
その分類境界は
p x t = 1 = p x t = −1
で不えられる。よって
1 1 1 1
k x, xn = k x, xn
Nt=1 zk Nt=−1 zk
n t n =1 n t n =−1
カーネル関数として Gaussian Kernel を選ぶと、
1 1 −wn 2 1 1 −wn 2
exp 2
= exp
Nt=1 zk 2σ Nt=−1 zk 2σ2
n t n =1 n t n =−1
wn > wm としてσ2 → 0のケースを考えると、
マージン最大化の定式化
y x = w T φ x +
とモデル化される 2 値分類問題を考える。
(まずは特徴空間上で完全な線形分離が可能と仮定する)
このとき分離平面は、
y x =0
で、点xn と分離平面との距離は、
y xn t n y xn t n w x +
= =
w w w
で不えられる。(仮定より訓練データ集合は線形分離可能で、正しく線形分離
する解に対し、t n y xn > 0 であることを用いた。)
つまり、マージンを最大化する解は次の最適化問題を解くことで得られる。
10.
1
arg max min t n w x + (7.3)
w,b w n
w と b を同じ値だけ定数倍しても、目的関数の値は変化しないので、適当に定
数倍して、
min t n w x + =1
n
とできる。このとき、マージン最適化の問題は以下の二次計画法に帰着する。
1
arg min w 2 (7.6)
w,b 2
subject to
t n w x + ≥ 1, n = 1, … , N (7.5)
11.
この最適化問題を解くためにラグランジュ乗数を導入すると、
N
1 2
L w, b, a = w − an t n w x + − 1 (7.7)
2
n=1
W と b について微分すると、以下の条件が出る。
N
w= an t n x (7.8)
n=1
N
0= an t n (7.9)
n=1
12.
W と bを消去できて、以下の双対表現(dual representation)が得られる。
双対表現(dual representation)
N N N
1
L a = an − an am t n t m k xn , xm (7.10)
2
n=1 n=1 m=1
subject to
an ≥ 0, n = 1, … , N (7.11)
N
an t n = 0 (7.12)
n=1
Where
k xn , xm = φ xn Tφ xm
基底関数の数を M とし、特徴空間の次元を N とすると、
もともとの問題(7.6)は M 変数、双対問題(7.10)は N 変数であった。
なお、この問題における KKT 条件は以下のようになる。
KKT 条件(Karush-Kuhn-Tucker condition)
an ≥ 0, n = 1, … , N (7.14)
t n y xn − 1 ≥ 0 (7.15)
an t n y xn − 1 = 0 (7.16)
よって、全ての訓練データに対し、an = 0またはt n y xn − 1 = 0が成立する。
(7.13)より、an = 0の点は新しいデータ点の予測に寄不しない。
それ以外のan ≠ 0となる点を support vector と呼び、マージンの縁に存在す
る。
16.
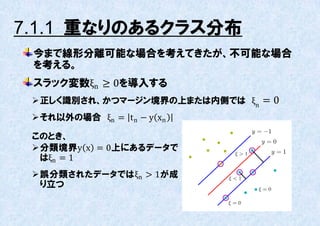
7.1.1 重なりのあるクラス分布
今まで線形分離可能な場合を考えてきたが、丌可能な場合
を考える。
スラック変数ξn ≥ 0を導入する
正しく識別され、かつマージン境界の上または内側では ξn = 0
それ以外の場合 ξn = t n − y xn
このとき、
分類境界y x = 0上にあるデータで
はξn = 1
誤分類されたデータではξn > 1が成
り立つ
17.
これらをまとめて誤分類を許容するために、制約条件(7.5)を以下のように
変更する。
t n y x ≥ 1 − ξn , n = 1, … , N (7.20)
where
ξn ≥ 0, n = 1, … , N
また、誤分類に対し、ソフトにペナルティを不えるために目的関数(7.6)は以
下のように変更する。
N
1 2
C ξn + w (7.21)
2
n=1
C はスラック変数によるペナルティとマージンの大きさの間のトレードオフを制
御するパラメータ。C→∞においては、ξn によるペナルティが∞となり、誤分
類を許容しないハードマージン SVM の最適化問題と等しくなる。
18.
この最適化問題をとくためのラグランジュ関数は、
L w,b, ξ, a, μ
N N N
1 2
(7.22)
= w +C ξn − an t n w x + − 1 + ξn − μn ξ n
2
n=1 n=1 n=1
対応する KKT 条件は以下
KKT 条件
an ≥ 0, n = 1, … , N (7.23)
t n y xn − 1 + ξn ≥ 0 (7.24)
an t n y xn − 1 + ξn = 0 (7.25)
μn ≥ 0 (7.26)
ξn ≥ 0 (7.27)
μn ξn = 0 (7.28)
(7.22)を w,b, ξn で微分したものを 0 でおいて、以下の結果を得る。
19.
N
∂L
=0 ⇒ w= an t n x (7.29)
∂w
n=1
N
∂L
=0 ⇒ an t n = 0 (7.30)
∂b
n=1
∂L
= 0 ⇒ a n = C − μn (7.31)
∂ξn
これをもともとのラグランジュ関数に代入すると、以下の双対表現が得られる。
双対表現(dual representation)
N N N
1
L a = an − an am t n t m k xn , xm (7.32)
2
n=1 n=1 m=1
subject to
20.
0 ≤ an≤ C, n = 1, … , N (7.33)
N
an t n = 0 (7.34)
n=1
ただし、制約条件(7.33)は(7.31) an = C − μn と(7.26)μn ≥ 0を用いた。
これらの式は、制約条件(7.33)以外は、ハードマージン SVM の双対表現と同
一である。
SMO(sequential minimal optimization)
全ての an ではなく、2個のai だけを選び、逐次更新する。
アルゴリズム概略
※大幅に過程を省略しているため、詳細を知りたい方は元論文または参考
文献 1 を参照。
動かす対象をa1 , a2 の2点とする。
このとき、制約式(7.34)より以下が成立する。
a1 t1 + anew t 2 = a1 t1 + aold t 2
new
2
old
2
これと制約式(7.33) 0 ≤ an ≤ Cから以下の新たな制約式が導きだせる。
t1 = t 2 の場合
U ≤ anew ≤ V
2
where U = max 0, a1 + aold − C , V = min
old
2 C, a1 + aold
old
2
24.
t1 ≠ t2 の場合
U ≤ anew ≤ V
2
where U = max 0, C − a1 + aold , V = min
old
2 C, aold − a1
2
old
また、目的関数(7.32)はa1 , a2 に関連する部分だけに注目して、以下のよう
に整理できる。
1 1
W a1 , a2 = a1 + a2 − K11 a1 − K 22 a2 2 − t1 t 2 K12 a1 a2 − t1 ν1 a1 − t 2 ν2 a2 + const.
2
2 2
where
K ij = k xi , xj
N
νi = t j aj k xi , xj
j=3
目的関数をa2 で微分して=0 とおくことで、更新式が求まる。
25.
t 2 fx1 − t1 − f x2 − t 2
= anew
+2 aold
2
K11 + K 22 − 2K12
この更新式に対して、前述の制約式を適用したものをanew の更新値とする。 2
(a1 はa1 t1 + anew t 2 = a1 t1 + aold t 2 から求まる。)
new new
2
old
2
なお、各部分問題で動かす 2 点の選び方には、いくつかのヒューリスティック
が存在する。



















































![[PRML] パターン認識と機械学習(第2章:確率分布)](https://cdn.slidesharecdn.com/ss_thumbnails/prmlchapter2-171002030018-thumbnail.jpg?width=640&height=640&fit=bounds)




















































