Download free for 30 days
Sign in
Upload
Language (EN)
Support
Business
Mobile
Social Media
Marketing
Technology
Art & Photos
Career
Design
Education
Presentations & Public Speaking
Government & Nonprofit
Healthcare
Internet
Law
Leadership & Management
Automotive
Engineering
Software
Recruiting & HR
Retail
Sales
Services
Science
Small Business & Entrepreneurship
Food
Environment
Economy & Finance
Data & Analytics
Investor Relations
Sports
Spiritual
News & Politics
Travel
Self Improvement
Real Estate
Entertainment & Humor
Health & Medicine
Devices & Hardware
Lifestyle
Change Language
Language
English
Español
Português
Français
Deutsche
Cancel
Save
Submit search
EN
Uploaded by
sleepy_yoshi
3,113 views
PRML復々習レーン#3 3.1.3-3.1.5
2012-07-16 PRML復々習レーン#3 3.1.3-3.1.5 の資料
Read more
3
Save
Share
Embed
Embed presentation
Download
Downloaded 38 times
1
/ 21
2
/ 21
3
/ 21
4
/ 21
5
/ 21
6
/ 21
7
/ 21
8
/ 21
9
/ 21
10
/ 21
11
/ 21
12
/ 21
13
/ 21
14
/ 21
15
/ 21
16
/ 21
17
/ 21
18
/ 21
19
/ 21
20
/ 21
21
/ 21
More Related Content
PDF
パターン認識と機械学習 (PRML) 第1章-「多項式曲線フィッティング」「確率論」
by
Koichi Hamada
PDF
Prml3.5 エビデンス近似〜
by
Yuki Matsubara
PDF
PRML 2.3.2-2.3.4 ガウス分布
by
Akihiro Nitta
PDF
PRML 上 2.3.6 ~ 2.5.2
by
禎晃 山崎
PDF
Prml 3 3.3
by
Arata Honda
PDF
PRML上巻勉強会 at 東京大学 資料 第2章2.3.3 〜 2.3.6
by
Hiroyuki Kato
PDF
PRML エビデンス近似 3.5 3.6.1
by
tmtm otm
PDF
PRML輪読#3
by
matsuolab
パターン認識と機械学習 (PRML) 第1章-「多項式曲線フィッティング」「確率論」
by
Koichi Hamada
Prml3.5 エビデンス近似〜
by
Yuki Matsubara
PRML 2.3.2-2.3.4 ガウス分布
by
Akihiro Nitta
PRML 上 2.3.6 ~ 2.5.2
by
禎晃 山崎
Prml 3 3.3
by
Arata Honda
PRML上巻勉強会 at 東京大学 資料 第2章2.3.3 〜 2.3.6
by
Hiroyuki Kato
PRML エビデンス近似 3.5 3.6.1
by
tmtm otm
PRML輪読#3
by
matsuolab
What's hot
PDF
パターン認識と機械学習 13章 系列データ
by
emonosuke
PPTX
Prml 1.3~1.6 ver3
by
Toshihiko Iio
PDF
2013.12.26 prml勉強会 線形回帰モデル3.2~3.4
by
Takeshi Sakaki
PDF
ベイズ統計入門
by
Miyoshi Yuya
PDF
PRML輪読#1
by
matsuolab
PDF
PRML上巻勉強会 at 東京大学 資料 第4章4.3.1 〜 4.5.2
by
Hiroyuki Kato
PDF
PRML 3.3.3-3.4 ベイズ線形回帰とモデル選択 / Baysian Linear Regression and Model Comparison)
by
Akihiro Nitta
PDF
PRML輪読#2
by
matsuolab
PDF
PRML上巻勉強会 at 東京大学 資料 第1章前半
by
Ohsawa Goodfellow
PDF
PRML輪読#5
by
matsuolab
PDF
PRML 2.4
by
kazunori sakai
PDF
PRML 2.3節 - ガウス分布
by
Yuki Soma
PPTX
PRML 3.5.2, 3.5.3, 3.6
by
Kohei Tomita
PDF
「3.1.2最小二乗法の幾何学」PRML勉強会4 @筑波大学 #prml学ぼう
by
Junpei Tsuji
PDF
PRML上巻勉強会 at 東京大学 資料 第1章後半
by
Ohsawa Goodfellow
PDF
PRML輪読#8
by
matsuolab
PDF
自動微分変分ベイズ法の紹介
by
Taku Yoshioka
PDF
PRML読書会#4資料+補足
by
Hiromasa Ohashi
PPTX
2014.01.23 prml勉強会4.2確率的生成モデル
by
Takeshi Sakaki
PDF
PRML第3章@京大PRML輪講
by
Sotetsu KOYAMADA(小山田創哲)
パターン認識と機械学習 13章 系列データ
by
emonosuke
Prml 1.3~1.6 ver3
by
Toshihiko Iio
2013.12.26 prml勉強会 線形回帰モデル3.2~3.4
by
Takeshi Sakaki
ベイズ統計入門
by
Miyoshi Yuya
PRML輪読#1
by
matsuolab
PRML上巻勉強会 at 東京大学 資料 第4章4.3.1 〜 4.5.2
by
Hiroyuki Kato
PRML 3.3.3-3.4 ベイズ線形回帰とモデル選択 / Baysian Linear Regression and Model Comparison)
by
Akihiro Nitta
PRML輪読#2
by
matsuolab
PRML上巻勉強会 at 東京大学 資料 第1章前半
by
Ohsawa Goodfellow
PRML輪読#5
by
matsuolab
PRML 2.4
by
kazunori sakai
PRML 2.3節 - ガウス分布
by
Yuki Soma
PRML 3.5.2, 3.5.3, 3.6
by
Kohei Tomita
「3.1.2最小二乗法の幾何学」PRML勉強会4 @筑波大学 #prml学ぼう
by
Junpei Tsuji
PRML上巻勉強会 at 東京大学 資料 第1章後半
by
Ohsawa Goodfellow
PRML輪読#8
by
matsuolab
自動微分変分ベイズ法の紹介
by
Taku Yoshioka
PRML読書会#4資料+補足
by
Hiromasa Ohashi
2014.01.23 prml勉強会4.2確率的生成モデル
by
Takeshi Sakaki
PRML第3章@京大PRML輪講
by
Sotetsu KOYAMADA(小山田創哲)
Similar to PRML復々習レーン#3 3.1.3-3.1.5
PDF
スパースモデリング、スパースコーディングとその数理(第11回WBA若手の会)
by
narumikanno0918
PDF
PRML復々習レーン#9 6.3-6.3.1
by
sleepy_yoshi
PDF
PRML復々習レーン#9 前回までのあらすじ
by
sleepy_yoshi
ZIP
今さら聞けないカーネル法とサポートベクターマシン
by
Shinya Shimizu
PDF
東京都市大学 データ解析入門 6 回帰分析とモデル選択 1
by
hirokazutanaka
PPTX
W8PRML5.1-5.3
by
Masahito Ohue
PPTX
PRML Chapter 5
by
Masahito Ohue
PDF
PRML 6.1章 カーネル法と双対表現
by
hagino 3000
PPTX
統計的学習の基礎_3章
by
Shoichi Taguchi
PDF
PRML 5.2.1-5.3.3 ニューラルネットワークの学習 (誤差逆伝播) / Training Neural Networks (Backpropa...
by
Akihiro Nitta
PDF
パターン認識と機械学習6章(カーネル法)
by
Yukara Ikemiya
PDF
クラシックな機械学習の入門 3. 線形回帰および識別
by
Hiroshi Nakagawa
PPTX
SVM
by
Yuki Nakayama
PDF
FOBOS
by
Hidekazu Oiwa
PDF
Deep feedforward network (Chapter 6 in Deep learning by Ian Goodfellow)
by
Tomoki Tanimura
PDF
PRML復々習レーン#7 前回までのあらすじ
by
sleepy_yoshi
PDF
レポート1
by
YoshikazuHayashi3
PDF
PATTERN RECOGNITION AND MACHINE LEARNING (1.1)
by
Yuma Yoshimoto
PDF
SVM
by
Yuki Nakayama
PDF
Re revenge chap03-1
by
裕樹 奥田
スパースモデリング、スパースコーディングとその数理(第11回WBA若手の会)
by
narumikanno0918
PRML復々習レーン#9 6.3-6.3.1
by
sleepy_yoshi
PRML復々習レーン#9 前回までのあらすじ
by
sleepy_yoshi
今さら聞けないカーネル法とサポートベクターマシン
by
Shinya Shimizu
東京都市大学 データ解析入門 6 回帰分析とモデル選択 1
by
hirokazutanaka
W8PRML5.1-5.3
by
Masahito Ohue
PRML Chapter 5
by
Masahito Ohue
PRML 6.1章 カーネル法と双対表現
by
hagino 3000
統計的学習の基礎_3章
by
Shoichi Taguchi
PRML 5.2.1-5.3.3 ニューラルネットワークの学習 (誤差逆伝播) / Training Neural Networks (Backpropa...
by
Akihiro Nitta
パターン認識と機械学習6章(カーネル法)
by
Yukara Ikemiya
クラシックな機械学習の入門 3. 線形回帰および識別
by
Hiroshi Nakagawa
SVM
by
Yuki Nakayama
FOBOS
by
Hidekazu Oiwa
Deep feedforward network (Chapter 6 in Deep learning by Ian Goodfellow)
by
Tomoki Tanimura
PRML復々習レーン#7 前回までのあらすじ
by
sleepy_yoshi
レポート1
by
YoshikazuHayashi3
PATTERN RECOGNITION AND MACHINE LEARNING (1.1)
by
Yuma Yoshimoto
SVM
by
Yuki Nakayama
Re revenge chap03-1
by
裕樹 奥田
More from sleepy_yoshi
PDF
PRML復々習レーン#2 2.3.6 - 2.3.7
by
sleepy_yoshi
PDF
SMO徹底入門 - SVMをちゃんと実装する
by
sleepy_yoshi
PDF
計算論的学習理論入門 -PAC学習とかVC次元とか-
by
sleepy_yoshi
PDF
SVM実践ガイド (A Practical Guide to Support Vector Classification)
by
sleepy_yoshi
PDF
PRML復々習レーン#10 7.1.3-7.1.5
by
sleepy_yoshi
PDF
PRML復々習レーン#15 前回までのあらすじ
by
sleepy_yoshi
PDF
ICML2013読み会: Distributed training of Large-scale Logistic models
by
sleepy_yoshi
PDF
SEXI2013読み会: Adult Query Classification for Web Search and Recommendation
by
sleepy_yoshi
PDF
PRML復々習レーン#13 前回までのあらすじ
by
sleepy_yoshi
PDF
ICML2012読み会 Scaling Up Coordinate Descent Algorithms for Large L1 regularizat...
by
sleepy_yoshi
PDF
PRML復々習レーン#3 前回までのあらすじ
by
sleepy_yoshi
PDF
WSDM2012読み会: Learning to Rank with Multi-Aspect Relevance for Vertical Search
by
sleepy_yoshi
PDF
SIGIR2012勉強会 23 Learning to Rank
by
sleepy_yoshi
PDF
PRML復々習レーン#12 前回までのあらすじ
by
sleepy_yoshi
PDF
KDD2013読み会: Direct Optimization of Ranking Measures
by
sleepy_yoshi
PDF
PRML復々習レーン#10 前回までのあらすじ
by
sleepy_yoshi
PDF
PRML復々習レーン#11 前回までのあらすじ
by
sleepy_yoshi
PDF
PRML復々習レーン#14 前回までのあらすじ
by
sleepy_yoshi
PDF
KDD2014勉強会: Large-Scale High-Precision Topic Modeling on Twitter
by
sleepy_yoshi
PDF
DSIRNLP#3 LT: 辞書挟み込み型転置インデクスFIg4.5
by
sleepy_yoshi
PRML復々習レーン#2 2.3.6 - 2.3.7
by
sleepy_yoshi
SMO徹底入門 - SVMをちゃんと実装する
by
sleepy_yoshi
計算論的学習理論入門 -PAC学習とかVC次元とか-
by
sleepy_yoshi
SVM実践ガイド (A Practical Guide to Support Vector Classification)
by
sleepy_yoshi
PRML復々習レーン#10 7.1.3-7.1.5
by
sleepy_yoshi
PRML復々習レーン#15 前回までのあらすじ
by
sleepy_yoshi
ICML2013読み会: Distributed training of Large-scale Logistic models
by
sleepy_yoshi
SEXI2013読み会: Adult Query Classification for Web Search and Recommendation
by
sleepy_yoshi
PRML復々習レーン#13 前回までのあらすじ
by
sleepy_yoshi
ICML2012読み会 Scaling Up Coordinate Descent Algorithms for Large L1 regularizat...
by
sleepy_yoshi
PRML復々習レーン#3 前回までのあらすじ
by
sleepy_yoshi
WSDM2012読み会: Learning to Rank with Multi-Aspect Relevance for Vertical Search
by
sleepy_yoshi
SIGIR2012勉強会 23 Learning to Rank
by
sleepy_yoshi
PRML復々習レーン#12 前回までのあらすじ
by
sleepy_yoshi
KDD2013読み会: Direct Optimization of Ranking Measures
by
sleepy_yoshi
PRML復々習レーン#10 前回までのあらすじ
by
sleepy_yoshi
PRML復々習レーン#11 前回までのあらすじ
by
sleepy_yoshi
PRML復々習レーン#14 前回までのあらすじ
by
sleepy_yoshi
KDD2014勉強会: Large-Scale High-Precision Topic Modeling on Twitter
by
sleepy_yoshi
DSIRNLP#3 LT: 辞書挟み込み型転置インデクスFIg4.5
by
sleepy_yoshi
PRML復々習レーン#3 3.1.3-3.1.5
1.
PRML復々習レーン#3 3.1.3-3.1.5
(代打) 2012-07-16 Yoshihiko Suhara @sleepy_yoshi
2.
ここのポイント • (1) 逐次学習
– 確率的勾配降下法 • (2) 正則化項 – 誤差関数との関係 – 特にイメージについて 2
3.
3.1.3 逐次学習
3
4.
確率的勾配降下法 (Stochastic Gradient
Descent; SGD) • 誤差関数が𝐸 = 𝑛 𝐸 𝑛 のように,データ点に対する 誤差の和で表現される場合に利用可能 • 各データ点に対する誤差関数の勾配を用いて以下 の更新式で重みベクトルを更新 – 𝜂は学習率 • 収束保証のためには,単調減少させる必要あり 𝜏+1 𝜏 𝒘 = 𝒘 − 𝜂 𝜏 𝛻𝐸 𝑛 ∞ ∞ ただし lim 𝜂 𝜏 = 0 𝜏→∞ 𝜂𝜏 = ∞ 𝜂2 < ∞ 𝜏 𝜏=1 4 𝜏=1
5.
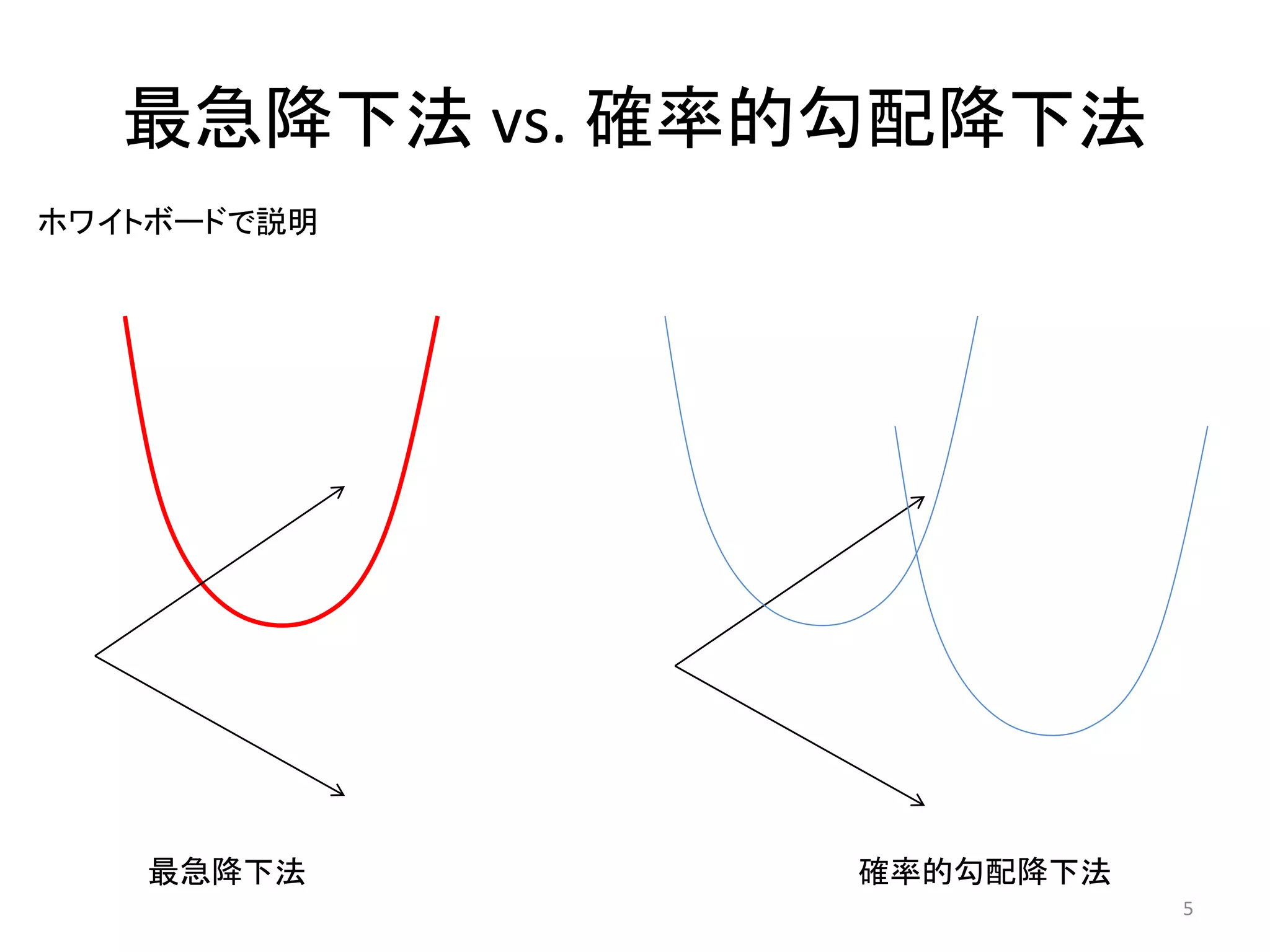
最急降下法 vs. 確率的勾配降下法 ホワイトボードで説明
最急降下法 確率的勾配降下法 5
6.
LMSアルゴリズム • LMSアルゴリズム
– 確率的勾配法を用いて最小二乗学習を行う – Widrow-Hoffの学習規則,Adalineとも呼ばれる • データ点 𝜙 𝒙 𝑛 , 𝑡 𝑛 に対する誤差関数は式(3.12)より 1 𝐸𝑛 𝒘 = 𝑡𝑛− 𝒘𝑇 𝜙 𝒙𝑛 2 2 • よって勾配𝛻𝐸 𝑛 𝒘 は 𝛻𝐸 𝑛 𝒘 = 𝑡 𝑛 − 𝒘 𝑇 𝜙 𝒙 𝑛 𝜙(𝒙 𝑛 ) 6
7.
LMSアルゴリズム INPUT: (𝒙
𝑛 , 𝑡 𝑛 ) ∈ 𝑫, 𝑇, 𝜂 OUTPUT: 𝒘 1: Initialize 𝒘0 = 𝟎 2: FOR 𝑛 in 0 to 𝑇 − 1 3: Obtain random sample (𝒙 𝑛 , 𝑡 𝑛 ) from 𝑫 4: 𝒘 𝑛+1 ← 𝑤 𝑛 − 𝜂 𝑡 𝑛 − 𝒘 𝑇 𝒙 𝑛 𝒙 𝑛 𝑛 5: ENDIF 6: ENDFOR 7: RETURN 𝒘 𝑇 7
8.
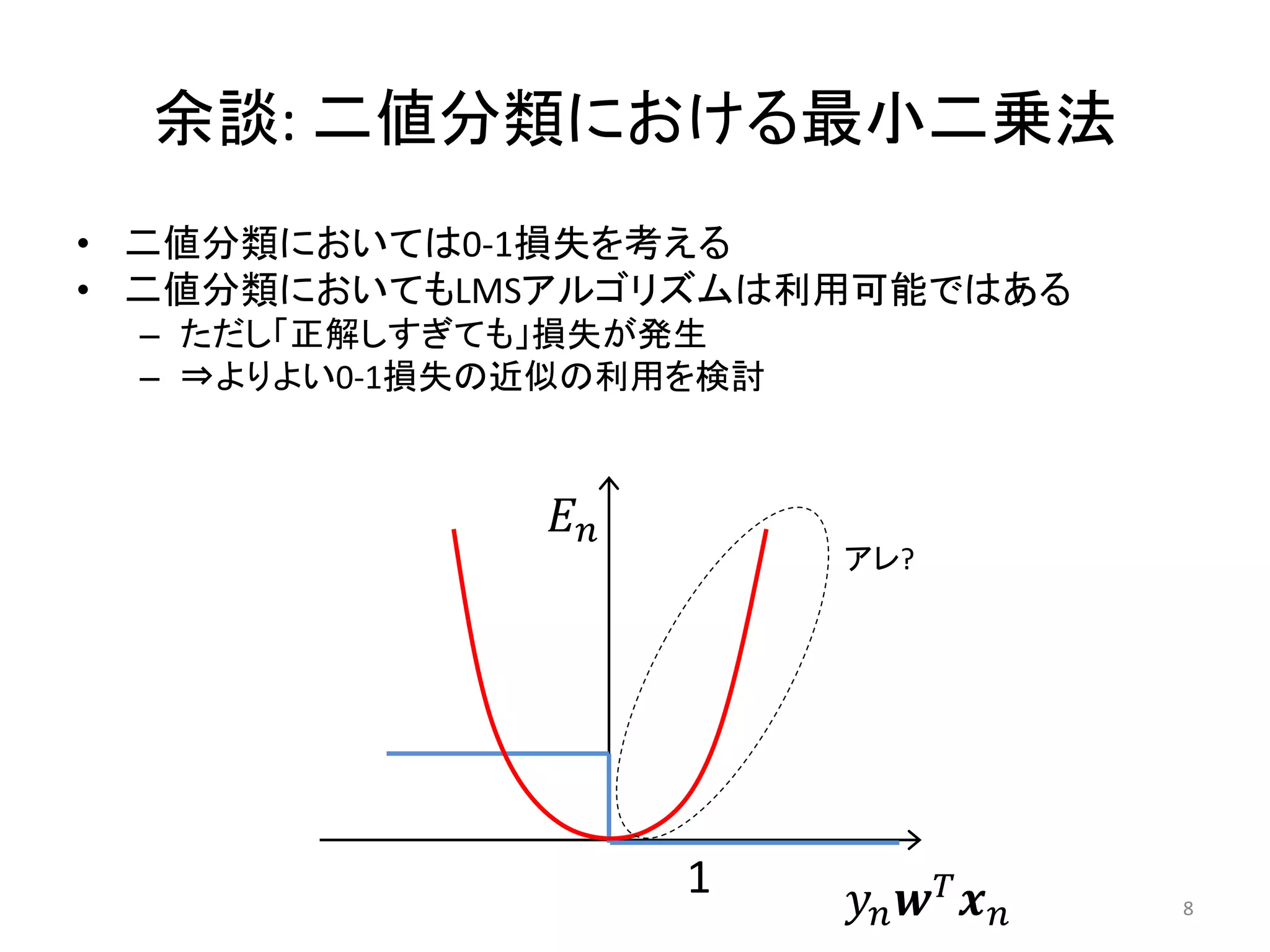
余談: 二値分類における最小二乗法 • 二値分類においては0-1損失を考える •
二値分類においてもLMSアルゴリズムは利用可能ではある – ただし「正解しすぎても」損失が発生 – ⇒よりよい0-1損失の近似の利用を検討 𝐸𝑛 アレ? 1 𝑦𝑛 𝒘 𝑇 𝒙 𝑛 8
9.
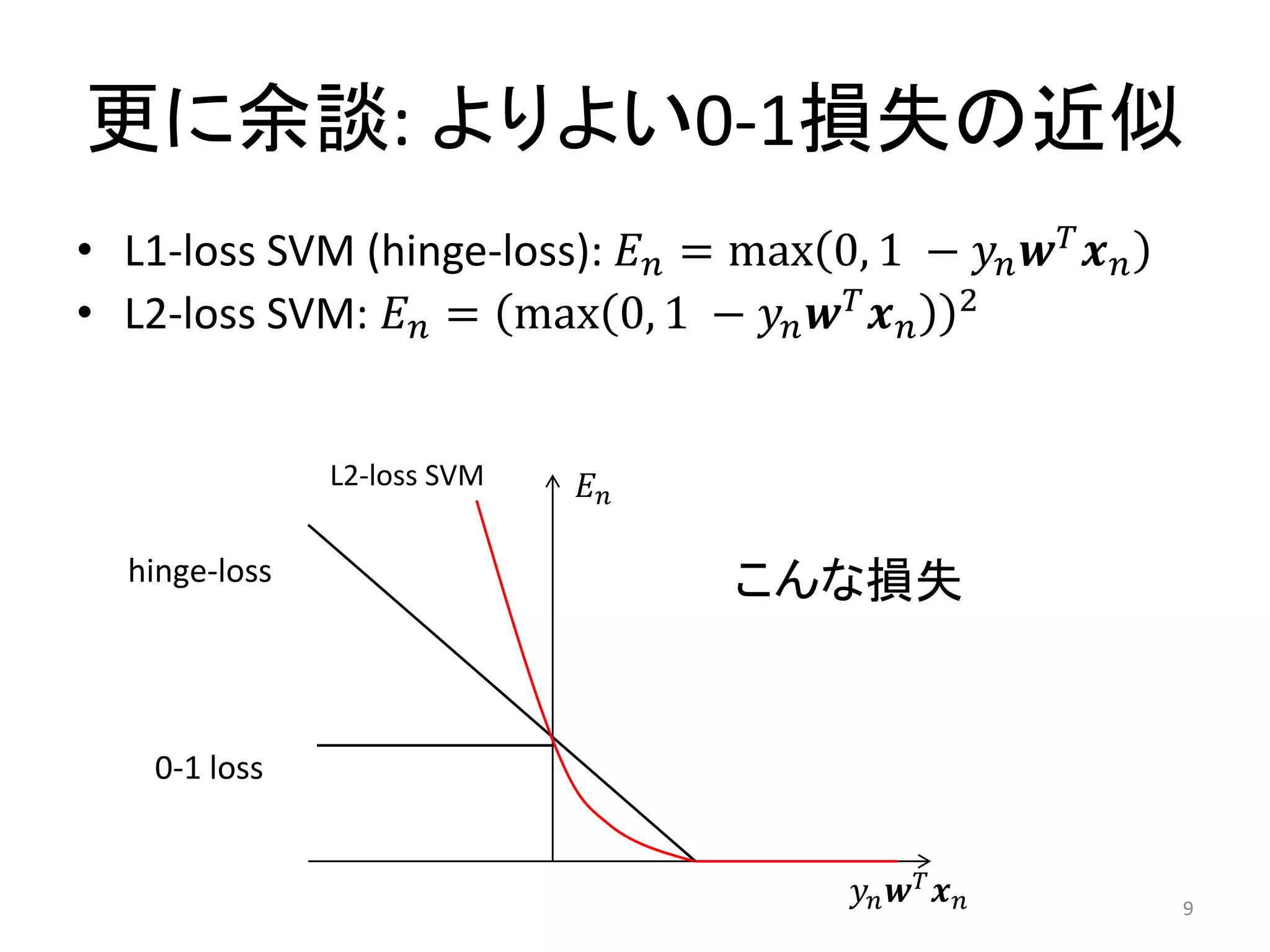
更に余談: よりよい0-1損失の近似 • L1-loss
SVM (hinge-loss): 𝐸 𝑛 = max 0, 1 − 𝑦 𝑛 𝒘 𝑇 𝒙 𝑛 • L2-loss SVM: 𝐸 𝑛 = max 0, 1 − 𝑦 𝑛 𝒘 𝑇 𝒙 𝑛 2 L2-loss SVM 𝐸𝑛 hinge-loss こんな損失 0-1 loss 𝑦𝑛 𝒘 𝑇 𝒙 𝑛 9
10.
3.1.4 正則化最小二乗法
10
11.
損失関数+正則化項 • 正則化項を加えた損失関数
𝐸 𝒘 = 𝐸 𝐷 𝒘 + 𝜆𝐸 𝑤 (𝒘) • 正則化項はたとえば重みベクトルの二乗和を 利用 (L2正則化項) 1 𝑇 𝐸𝑤 𝒘 = 𝒘 𝒘 2 11
12.
正則化最小二乗法 • 二乗誤差関数にさきほどの正則化項を加え
ると誤差関数は 𝑁 1 𝑇 2 𝜆 𝑇 𝐸 𝒘 = 𝑡𝑛− 𝒘 𝜙 𝒙𝑛 + 𝒘 𝒘 2 2 𝑛=1 • 𝒘に関する勾配を0とおき, 𝒘について解けば 以下を得る 𝒘 = 𝜆𝐈 + 𝚽 𝑇 𝚽 −1 𝚽 𝑇 𝒕 12
13.
正則化最小二乗の導出
𝑇 𝐿 𝒘 = 𝒚 − 𝑿𝒘 𝒚 − 𝑿𝒘 + 𝜆𝒘 𝑇 𝒘 𝜕 𝐿 𝒘 = −2𝑿 𝑇 𝒚 + 2𝑿 𝑇 𝑿𝒘 + 𝜆𝒘 + 𝜆𝒘 𝜕𝒘 • これを0とおく 𝑿 𝑇 𝑿𝒘 + 𝜆𝒘 = 𝑿 𝑇 𝒚 𝑿 𝑇 𝑿 + 𝑰𝜆 𝒘 = 𝑿 𝑇 𝒚 𝒘 = 𝑿 𝑇 𝑿 + 𝑰𝜆 −1 𝑿 𝑇 𝒚 行列の微分 𝜕 𝑇 𝜕 𝑇 𝒂 𝒙= 𝒙 𝒂= 𝒂 𝜕𝒙 𝜕𝒙 𝑇 13 𝑨𝑩 = 𝑩𝑇 𝑨𝑇
14.
確率的勾配法で解く場合
L2正則化LMSアルゴリズム INPUT: (𝒙 𝑛 , 𝑡 𝑛 ) ∈ 𝑫, 𝑇, 𝜂 OUTPUT: 𝒘 1: Initialize 𝒘0 = 𝟎 2: FOR 𝑛 in 0 to 𝑇 − 1 3: Obtain random sample (𝒙 𝑛 , 𝑡 𝑛 ) from 𝑫 4: 𝒘 𝑛+1 ← 𝑤 𝑛 − 𝜂 𝑡 𝑛 − 𝒘 𝑇 𝒙 𝑛 𝒙 𝑛 + 𝜆𝒘 𝑛 𝑛 5: ENDIF 6: ENDFOR 7: RETURN 𝒘 𝑇 14
15.
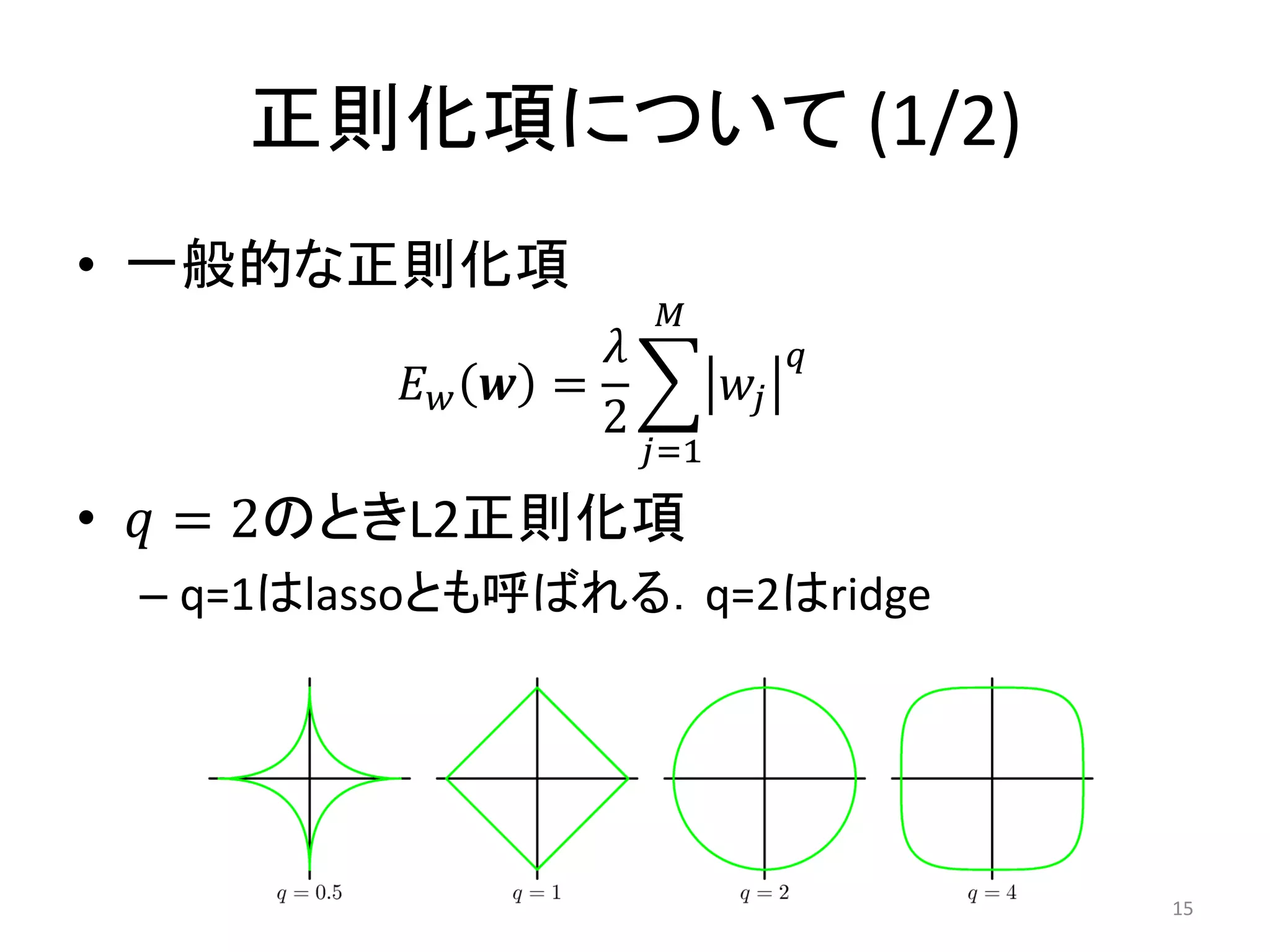
正則化項について (1/2) • 一般的な正則化項
𝑀 𝜆 𝑞 𝐸𝑤 𝒘 = 𝑤𝑗 2 𝑗=1 • 𝑞 = 2のときL2正則化項 – q=1はlassoとも呼ばれる.q=2はridge 15
16.
正則化項について (2/2) • 誤差関数と正則化項を横から眺める
– (ホワイトボード) • 二乗誤差関数+L2正則化項 (凸+凸=凸) – 証明はぐぐってください 16
17.
正則化項の解釈 • 正則化していない二乗誤差を以下の制約条件
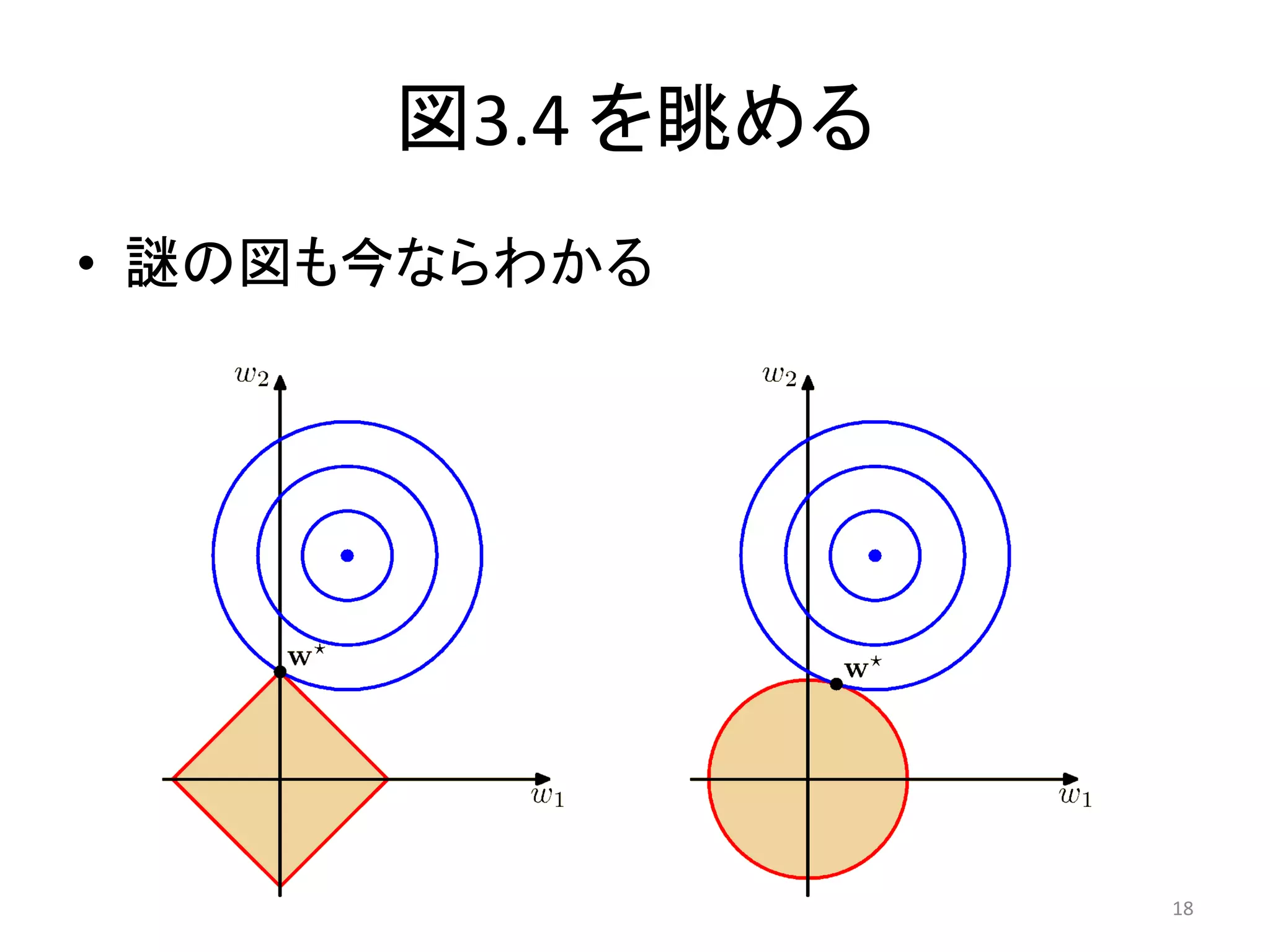
で最小化することと等しい (演習3.5) 𝑀 𝑞 𝑤𝑗 ≤ 𝜂 𝑗=1 • こたえ 𝑀 𝑞 𝜂= 𝑤 𝑗∗ 𝜆 𝑗=1 与えられた𝜆における誤差関数の最適値に依存 (゚Д゚)ハァ? 17
18.
図3.4 を眺める • 謎の図も今ならわかる
18
19.
3.1.5 出力変数が多次元の場合
19
20.
目標変数が多次元の場合 • 𝐾次元の目標ベクトル𝒕の推定を試みる
𝒚 𝒙, 𝒘 = 𝑾 𝑇 𝜙(𝒙) • 結論 (3.1.1と同様のロジック) – 最尤推定値 𝑾 𝑀𝐿 = 𝚽 𝑇 𝚽 −1 𝚽 𝑇 𝐓 – 各次元の目標変数が相互に依存しないため,𝑘 番目の目標変数を推定するためのパラメータは 𝒘 𝑘 = 𝚽 𝑇 𝚽 −1 𝚽 𝑇 𝒕 𝑘 で求めることができる 20
21.
おしまい
21
Download