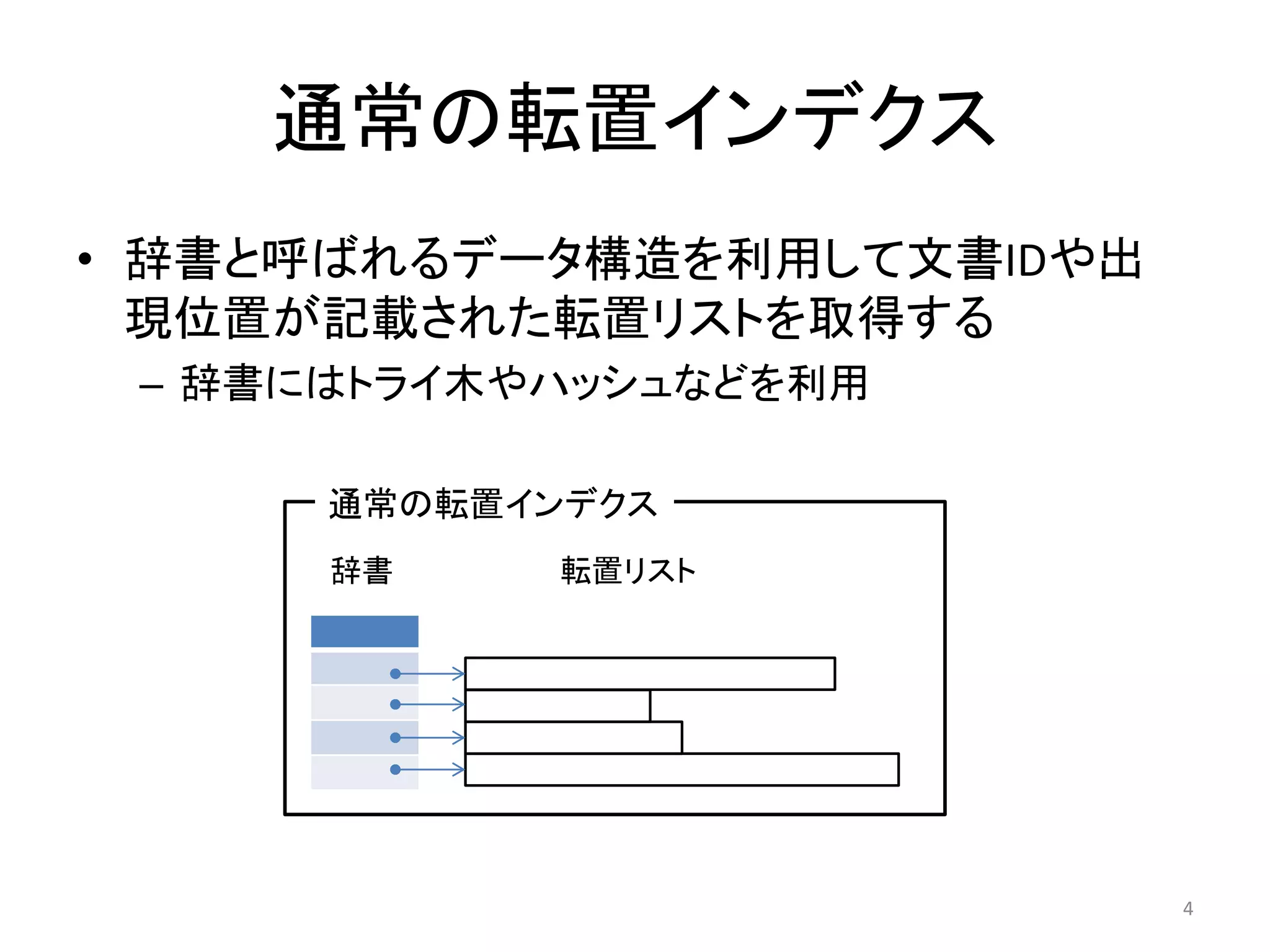
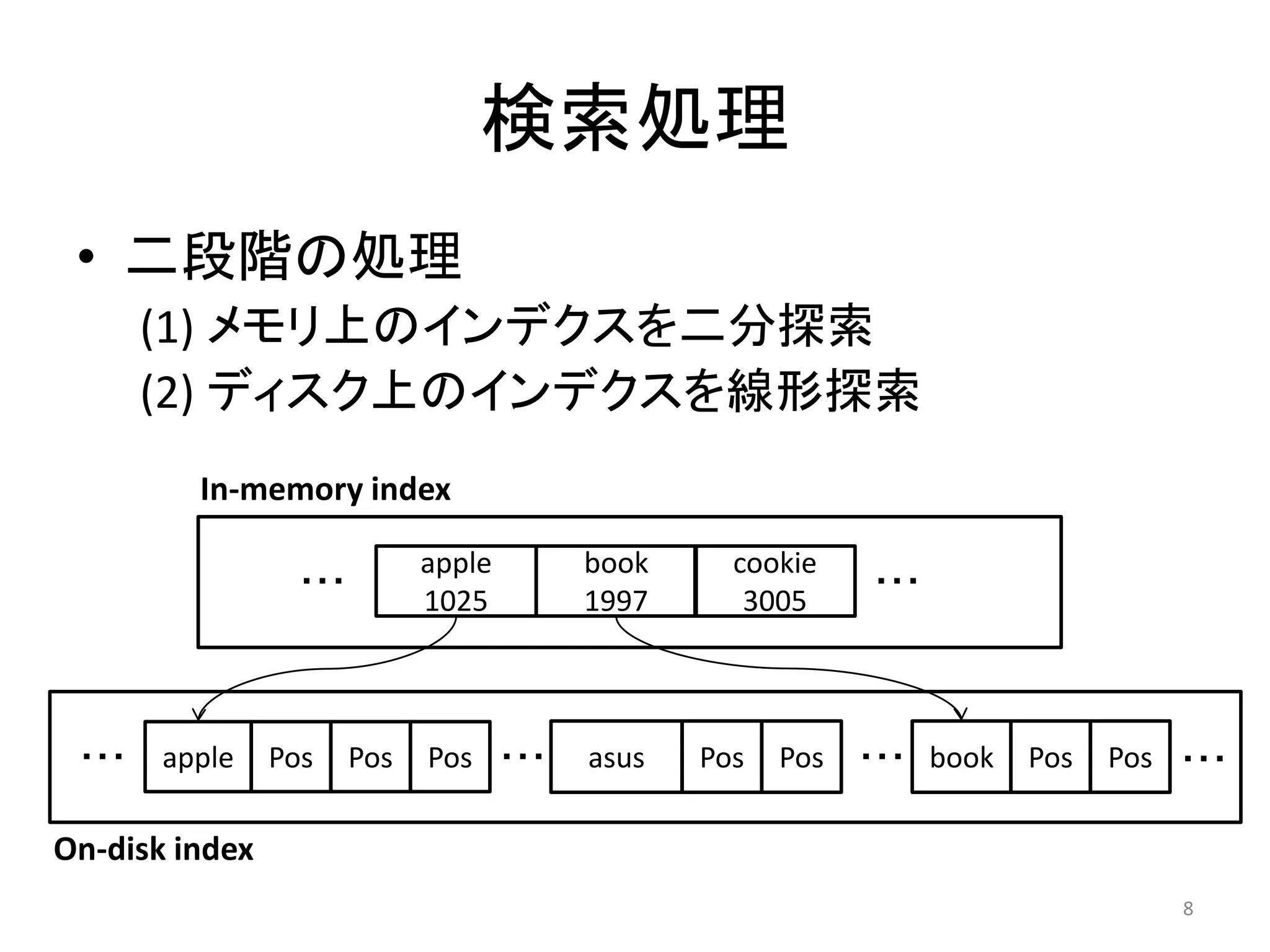
検索処理
• 二段階の処理
(1) メモリ上のインデクスを二分探索
(2) ディスク上のインデクスを線形探索
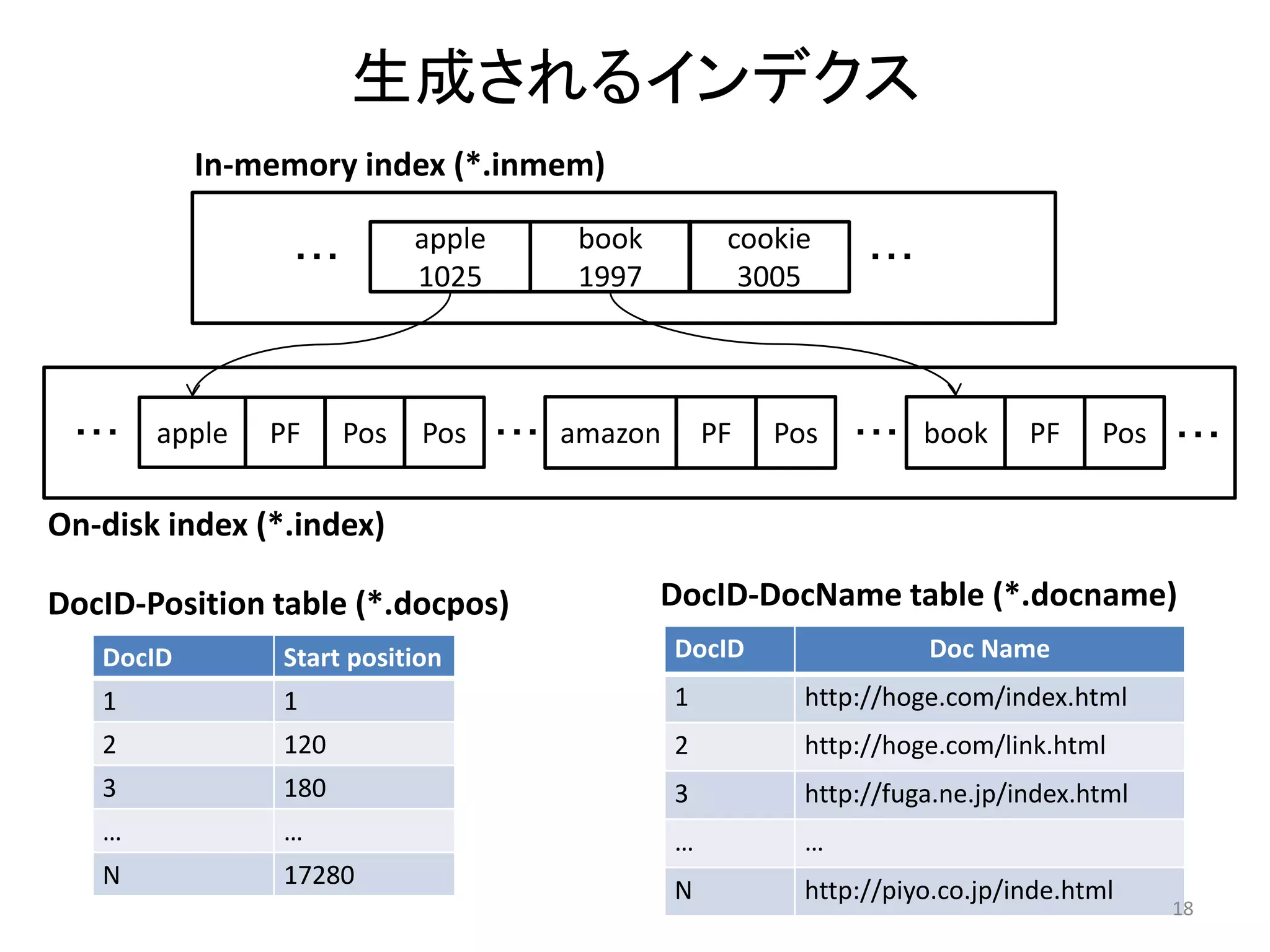
In-memory index
apple book cookie
・・・ ・・・
1025 1997 3005
・・・ apple Pos Pos Pos ・・・ asus Pos Pos ・・・ book Pos Pos ・・・
On-disk index
8
9.
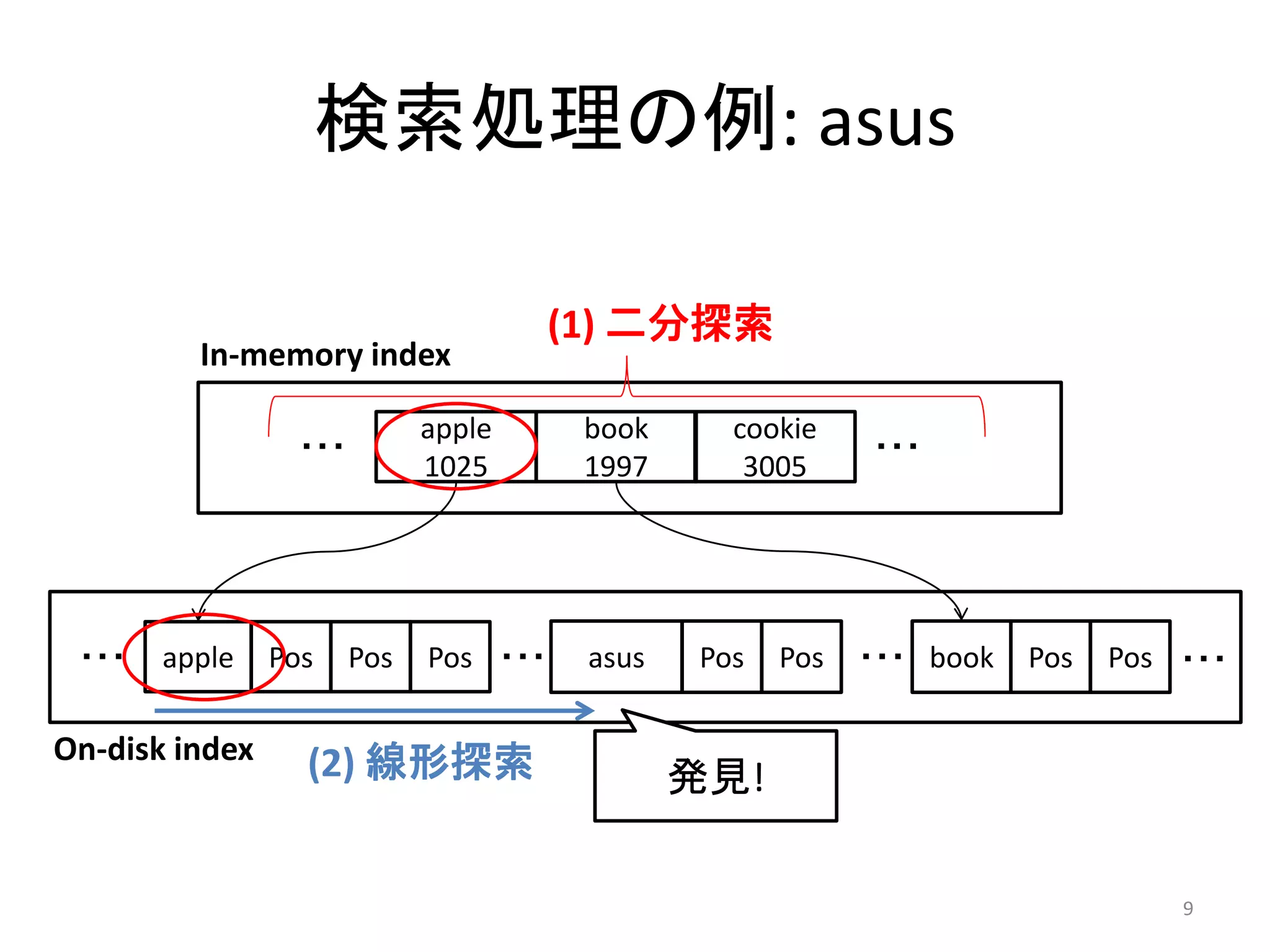
検索処理の例: asus
(1) 二分探索
In-memory index
apple book cookie
・・・ ・・・
1025 1997 3005
・・・ apple Pos Pos Pos ・・・ asus Pos Pos ・・・ book Pos Pos ・・・
On-disk index (2) 線形探索 発見!
9
10.
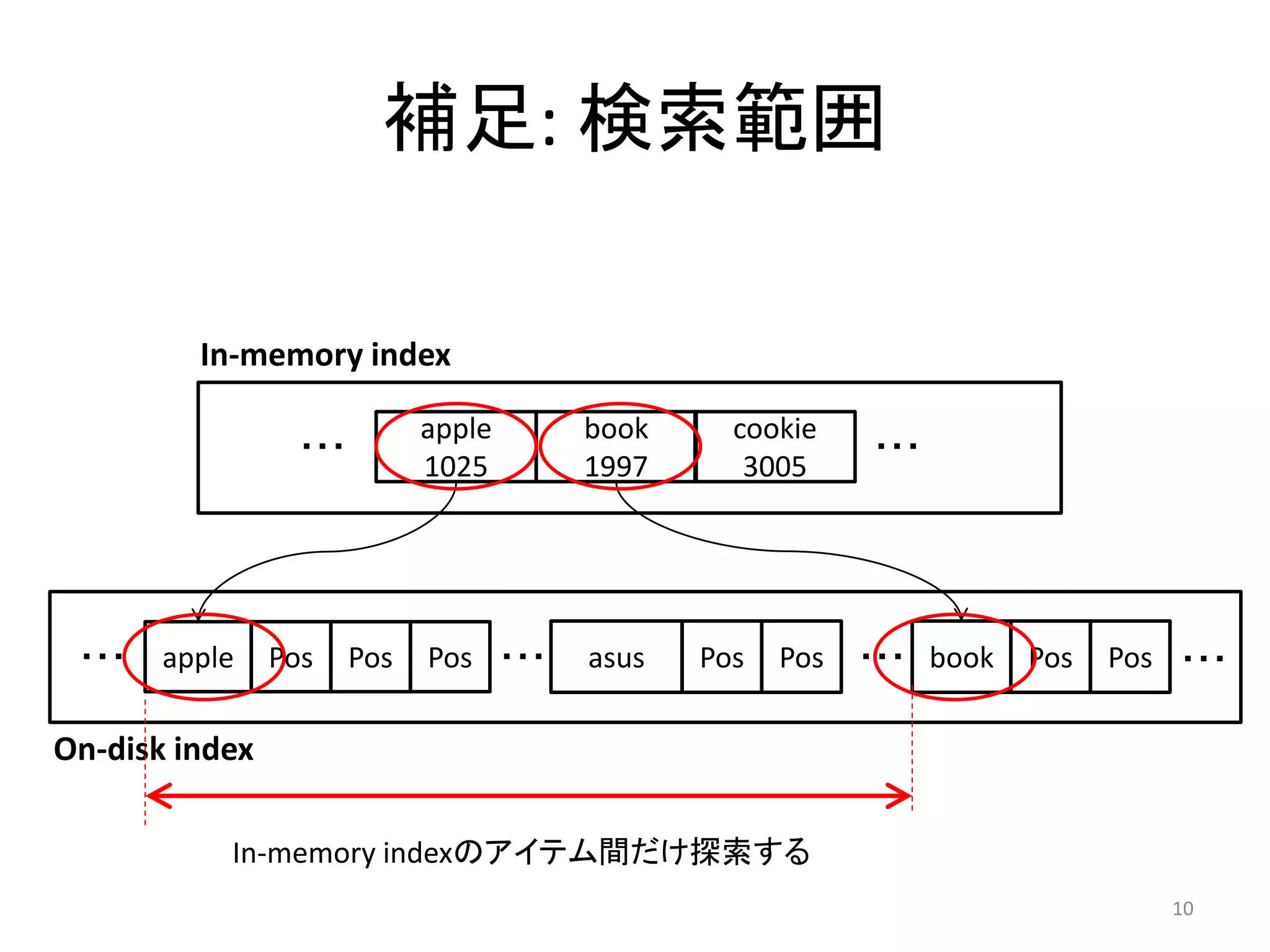
補足: 検索範囲
In-memory index
apple book cookie
・・・ ・・・
1025 1997 3005
・・・ apple Pos Pos Pos ・・・ asus Pos Pos ・・・ book Pos Pos ・・・
On-disk index
In-memory indexのアイテム間だけ探索する
10
明日のために
• Dictionary Interleaving形式のインデクスは辞
書を明示的に持たないため,複数インデクス
をマージしやすい
– Merge-based index construction に適した形式
• 山田さんの記事[4]を参考
• 複数インデクスを入力して,マージ結果を出
力するような使い方ができる検索エンジンが
できるんじゃないかな
21
22.
References
• [1] StefanButtcher, Charles L. A. Clarke and Gordon V. Cormack,
“Information Retrieval”, The MIT Press, 2010.
• [2] Stefan Buttcher, “Multi-User File System Search”, Ph.D thesis,
University of Waterloo, Canada, 2007.
– 著者のひとりButtcher氏の博士論文.Interleaving Dictionaryの初出?
– 4.4.2 Interleaving Posting Lists and Dictionary Entries
• [3] Jeffrey Dean, “Challenges in Building Large-Scale Information
Retrieval Systems”, WSDM ‘09 Tutorial, 2009.
– フラットな形式のインデクスについてはid:llameradaさんの翻訳記事が参
考になる
• http://d.hatena.ne.jp/llamerada/20090317/1237302640
• [4] 山田浩之. 検索エンジンはいかにして動くのか?
– 第10回 動的な索引構築
• http://gihyo.jp/dev/serial/01/search-engine/0010
22

![背景
• 昨年のGWの出来事
– ブッチャー本 [1] 読んでたら辞書挟み込み型インデクスについて記述
があり,実装したくなった
– 偶然にも明日からGW
– とりあえずやっつけで実装
– ちゃんと仕上げようとするとそのまま忘れ去るので,区切りをつける
意味でとりあえず公開…するの忘れて一年が経った
ブッチャー本 2](https://image.slidesharecdn.com/20120930dictionaryinterleavingpublish-120930020652-phpapp01/75/DSIRNLP-3-LT-FIg4-5-2-2048.jpg)


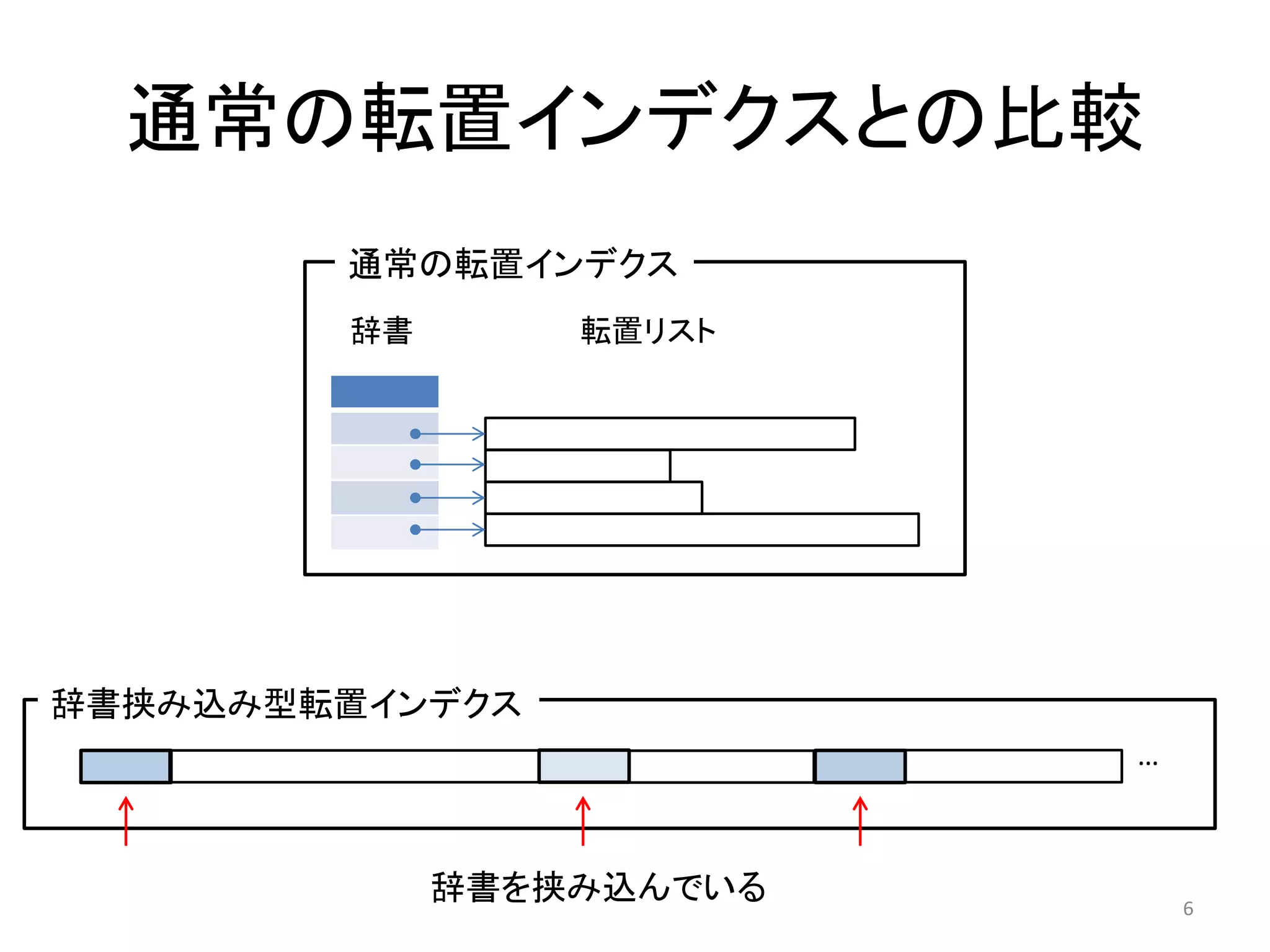
![Fig4.5: 辞書挟み込み型転置インデクス
• 辞書をインデクスに挟み込んだ形式の転置イン
デクス[1][2]
– 文献[1]の図4.5で説明されていたからFig4.5と命名
ブッチャー本 Fig4.5 (p.115)
さて,どのように検索するのか?
7](https://image.slidesharecdn.com/20120930dictionaryinterleavingpublish-120930020652-phpapp01/75/DSIRNLP-3-LT-FIg4-5-7-2048.jpg)

![Fig4.5の実装
• インデクス構築処理
– 一度通常の転置インデクスを構築してからOn-diskインデクスとIn-
memoryインデクスを構築
– 転置インデクスはやる気のない実装
• 辞書はstd::map
• 転置リストはstd::vector
• インデクス検索処理
– 構築したOn-diskインデクスはmmapで読み込む
– On-diskインデクスにはDocID: Pos, Pos; DocID: Pos, Posではなくて
全てフラットなPosition情報だけを利用
• 位置情報を取得した後に文書IDをルックアップすることでDocIDを取得
• WSDM ’09のGoogle講演を参考 [3]
12](https://image.slidesharecdn.com/20120930dictionaryinterleavingpublish-120930020652-phpapp01/75/DSIRNLP-3-LT-FIg4-5-12-2048.jpg)

![インデクス構築
Usage: ./index_writer <input filename> <output index path> [block size]
# 例
$ ./index_write sample.dat hoge 1024
Index construction done.
sample.dat
http://www.hoge.com/ 飛ばねえ 豚 は ただ の 豚 だ
http://www.bar.com/ 豚肉 は おいしい
http://www.piyo.com/ 豚 は 豚 で も ただ の 豚
・・・
• 入力フォーマット
– 各行が<DocName>¥t<Text>
• Textはトークン毎にスペース区切り
• 改行を含めることができない 14](https://image.slidesharecdn.com/20120930dictionaryinterleavingpublish-120930020652-phpapp01/75/DSIRNLP-3-LT-FIg4-5-14-2048.jpg)


![block sizeて何よ?
Usage: ./index_writer <input filename> <output index path> [block size]
# 例
$ ./index_write sample.dat hoge 1024
apple book cookie
・・・ ・・・
1025 1997 3005
・・・ apple PF Pos Pos ・・・ amazon PF Pos ・・・ book PF Pos ・・・
block size = この幅の上限
17](https://image.slidesharecdn.com/20120930dictionaryinterleavingpublish-120930020652-phpapp01/75/DSIRNLP-3-LT-FIg4-5-17-2048.jpg)


![明日のために
• Dictionary Interleaving 形式のインデクスは辞
書を明示的に持たないため,複数インデクス
をマージしやすい
– Merge-based index construction に適した形式
• 山田さんの記事[4]を参考
• 複数インデクスを入力して,マージ結果を出
力するような使い方ができる検索エンジンが
できるんじゃないかな
21](https://image.slidesharecdn.com/20120930dictionaryinterleavingpublish-120930020652-phpapp01/75/DSIRNLP-3-LT-FIg4-5-21-2048.jpg)
![References
• [1] Stefan Buttcher, Charles L. A. Clarke and Gordon V. Cormack,
“Information Retrieval”, The MIT Press, 2010.
• [2] Stefan Buttcher, “Multi-User File System Search”, Ph.D thesis,
University of Waterloo, Canada, 2007.
– 著者のひとりButtcher氏の博士論文.Interleaving Dictionaryの初出?
– 4.4.2 Interleaving Posting Lists and Dictionary Entries
• [3] Jeffrey Dean, “Challenges in Building Large-Scale Information
Retrieval Systems”, WSDM ‘09 Tutorial, 2009.
– フラットな形式のインデクスについてはid:llameradaさんの翻訳記事が参
考になる
• http://d.hatena.ne.jp/llamerada/20090317/1237302640
• [4] 山田浩之. 検索エンジンはいかにして動くのか?
– 第10回 動的な索引構築
• http://gihyo.jp/dev/serial/01/search-engine/0010
22](https://image.slidesharecdn.com/20120930dictionaryinterleavingpublish-120930020652-phpapp01/75/DSIRNLP-3-LT-FIg4-5-22-2048.jpg)










































































