Download to read offline


![概要
nSemantic Segmentation [Zheng+, CVPR2021]
• 画像の各ピクセルにクラスラベルを割り当て
nVision Transformer (ViT) [Dosovitskiy+, ICLR 2021]
• Transformer [Vaswani+, NeurIPS2017]をそのまま画像に適用
• CNNに依存しない
• 課題:汎用的なバックボーンではなく,
Prediction-Taskに直接適用不可
n本論文
• Semantic Segmentationに使用できる
ViTアーキテクチャについて議論
• どのようにして課題を解決したか](https://image.slidesharecdn.com/20230418semanticsegmentationusingvisiontransformersasurvey-240420025016-3ee90061/85/Semantic-segmentation-using-Vision-Transformers-A-survey-2-320.jpg)

![Semantic Segmentationの応用
nVideo Semantic Segmentation [Shelhamer+, ECCV2016]
• ヒューマンマシンインタラクション[Gorecky+, INDIN2014]
• Augment Reality [Azuma, PTVE1997]
• 自律走行車[Janai+, FTCGV2020]
• 画像検索エンジン
nビデオ=無相関の固定画像の集合 [Jain+, CVPR2019]
• 課題
• 計算の複雑さ
• 時間的フレームレートを使用し
動画の空間次元をスケーリング
• 解決策
• 特徴の再利用
• 特徴ワーピング[Ding+, AAAI2020]](https://image.slidesharecdn.com/20230418semanticsegmentationusingvisiontransformersasurvey-240420025016-3ee90061/85/Semantic-segmentation-using-Vision-Transformers-A-survey-4-320.jpg)
![データ制限を克服するための実践的アプローチ
n教師あり学習
• コンピュータ・ビジョンや自然言語処理で好成績を収める
• 現実世界では多くのラベルデータを必要としボトルネック
n自己教師あり学習:Self-supervised Learning (SSL) [Gustavsson, DiVA2019]
• ラベルのないデータセットを用いて学習
1. 事前学習タスクを解くように設定
2. 下流タスクに適用
• 異なる特徴に対し学習された重みを使用
• Semantic SegmentationはSSLを使用して
実行できる主要な下流タスクの一つ](https://image.slidesharecdn.com/20230418semanticsegmentationusingvisiontransformersasurvey-240420025016-3ee90061/85/Semantic-segmentation-using-Vision-Transformers-A-survey-5-320.jpg)
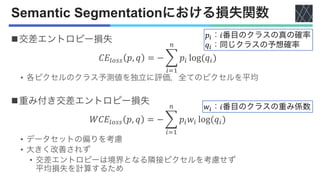
![Semantic Segmentationにおける損失関数
nフォーカル損失 [Lin+, ICCV2017]
• 交差エントロピー損失の構造を大きく変更
• 𝑝" > 0.5に対する相対的な損失を減らす
𝑝":真のクラスの予測確率
𝛼":スケーリング係数
𝛾:集中パラメータ](https://image.slidesharecdn.com/20230418semanticsegmentationusingvisiontransformersasurvey-240420025016-3ee90061/85/Semantic-segmentation-using-Vision-Transformers-A-survey-7-320.jpg)
![データセット
nPASCAL-Context [Yuan+, ECCV2020]
nADE20K [Zhou+, CVPR2017]
nKITTI [Geiger+, IJRR2013]
nCityscapes [Marius+, CVPR2016]
nIDD [Varma+, WACV2019]
nVirtual KITTI [Gaidon+, CVPR2016]
nIDDA [Alberti+, IROS2020]
n時間の都合上詳細は省略
PASCAL-Context
Cityscapes](https://image.slidesharecdn.com/20230418semanticsegmentationusingvisiontransformersasurvey-240420025016-3ee90061/85/Semantic-segmentation-using-Vision-Transformers-A-survey-8-320.jpg)
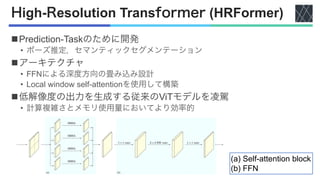
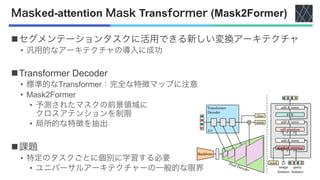
![ViTアーキテクチャの一覧
nSETR [Zheng+, CVPR2021]
nSwin-Transformer [Liu+, ICCV2021]
nSegmenter [Strudel+, ICCV2021]
nSegFormer [Xie+, NeurIPS2021]
nPVT [Wang+, ICCV2021]
nTwins [Chu+, NeurIPS2021]
nDPT [Ranftl+, ICCV2021]
nHRFormer [Yuan+, NeurIPS2021]
nMask2Former [Cheng+, CVPR2022]](https://image.slidesharecdn.com/20230418semanticsegmentationusingvisiontransformersasurvey-240420025016-3ee90061/85/Semantic-segmentation-using-Vision-Transformers-A-survey-9-320.jpg)
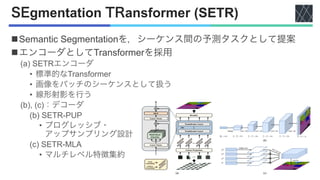
![Shifted Windows (Swin) -Transformer
n画像分類,密な予測などの汎用バックボーン
n階層的な特徴マップ
• Self-attentionの計算複雑度を線形的に
nシフトウィンドウアプローチ
• スライディングウィンドウアプローチと比ベ
レイテンシが低い
nアーキテクチャ
1. パッチ分割モジュール
2. 線形埋め込みの適用
3. 2連続Swin-Transformerブロック
n特徴マップの解像度がResNet [He+, CVPR2016]
など典型的なCNNアーキテクチャと類似](https://image.slidesharecdn.com/20230418semanticsegmentationusingvisiontransformersasurvey-240420025016-3ee90061/85/Semantic-segmentation-using-Vision-Transformers-A-survey-11-320.jpg)
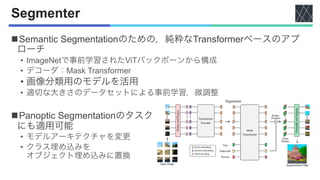
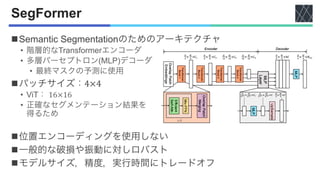
![Pyramid Vision Transformer (PVT)
nPVT v1 [Wang+, ICCV2021]
• パッチサイズ:4×4
• SegFormer [Xie+, NeurIPS2021]と同じ
• 高解像度表現学習能力が向上
• 漸進的縮小ピラミッド
• 計算負荷を軽減
• 出力解像度を段階的に縮小
n PVT v1の欠点
• 高解像度処理の計算量が大きい
• 画像の局所的な連続性が失われる
• 可変サイズの入力ができない
nPVT v2
• 3つの特徴
• Linear special reduction attention
(LSRA)
• オーバーラップパッチ
埋め込み
• 畳み込み
フィードフォワード
ネットワーク](https://image.slidesharecdn.com/20230418semanticsegmentationusingvisiontransformersasurvey-240420025016-3ee90061/85/Semantic-segmentation-using-Vision-Transformers-A-survey-14-320.jpg)
![nTwins-SVT
• Swin-Transformer [Liu+, ICCV2021]を再検討
• Spatially separable self-attention (SSSA)メカニズムを使用
• 2つのTransformerメカニズム
• Global Sub-sampled Attention (GSA)
• Locally grouped self- attention (LSA)
nTwins-PCPVT
• PVT v1 [Wang+, ICCV2021] を再検討
• Conditional position encoding (CPE)を使用
• Conditional Position encoding Vision Transformer (CPVT) [Chu+, arXiv2021]で導入
Twins](https://image.slidesharecdn.com/20230418semanticsegmentationusingvisiontransformersasurvey-240420025016-3ee90061/85/Semantic-segmentation-using-Vision-Transformers-A-survey-15-320.jpg)
![Dense Prediction Transformer (DPT)
nエンコーダ・デコーダ設計の内部にTransformerバックボーンを導入
nDPT-Base, DPT-Large
• パッチベースの埋め込み方式を採用
• 入力画像を非重複画像バッチに分割
• 変換器ブロックに供給
• 学習可能な位置埋め込みを持つ
• 特徴サイズ
Base:12層,Largs:24層
nDPT-Hybrid
• 特徴抽出器:ResNet-50
• トークン入力:ピクセルベースの特徴マップ
• Transformerブロック:MSA [Vaswani+, NeurIPS2017]
• デコーダで残差畳み込みユニットを使って結合](https://image.slidesharecdn.com/20230418semanticsegmentationusingvisiontransformersasurvey-240420025016-3ee90061/85/Semantic-segmentation-using-Vision-Transformers-A-survey-16-320.jpg)


![データセット
nPASCAL-Context
[Yuan+, ECCV2020]
nADE20K [Zhou+, CVPR2017]](https://image.slidesharecdn.com/20230418semanticsegmentationusingvisiontransformersasurvey-240420025016-3ee90061/85/Semantic-segmentation-using-Vision-Transformers-A-survey-21-320.jpg)
![データセット
nKITTI [Geiger+, IJRR2013] nCityscapes
[Marius+, CVPR2016]](https://image.slidesharecdn.com/20230418semanticsegmentationusingvisiontransformersasurvey-240420025016-3ee90061/85/Semantic-segmentation-using-Vision-Transformers-A-survey-22-320.jpg)
![データセット
nIDD [Varma+, WACV2019] nVirtual KITTI
[Gaidon+, CVPR2016]](https://image.slidesharecdn.com/20230418semanticsegmentationusingvisiontransformersasurvey-240420025016-3ee90061/85/Semantic-segmentation-using-Vision-Transformers-A-survey-23-320.jpg)
![データセット
nIDDA [Alberti+, IROS2020]](https://image.slidesharecdn.com/20230418semanticsegmentationusingvisiontransformersasurvey-240420025016-3ee90061/85/Semantic-segmentation-using-Vision-Transformers-A-survey-24-320.jpg)

Hans Thisanke, Chamli Deshan, Kavindu Chamith, Sachith Seneviratne, Rajith Vidanaarachchi, Damayanthi Herath, " Semantic segmentation using Vision Transformers: A survey" Engineering Applications of Artificial Intelligence, 2023 https://www.sciencedirect.com/science/article/abs/pii/S0952197623008539

![[DL輪読会]Swin Transformer: Hierarchical Vision Transformer using Shifted Windows](https://cdn.slidesharecdn.com/ss_thumbnails/swintransformer-210514020542-thumbnail.jpg?width=640&height=640&fit=bounds)
![SSII2022 [SS2] 少ないデータやラベルを効率的に活用する機械学習技術 〜 足りない情報をどのように補うか?〜](https://cdn.slidesharecdn.com/ss_thumbnails/ss2ssii2022-220607054716-2760bd30-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会]Batch Renormalization: Towards Reducing Minibatch Dependence in Batch-...](https://cdn.slidesharecdn.com/ss_thumbnails/dlu8f2au8aadu4f1av2-170407001546-thumbnail.jpg?width=640&height=640&fit=bounds)











![[DL輪読会]ICLR2020の分布外検知速報](https://cdn.slidesharecdn.com/ss_thumbnails/iclr2020ood-190927011524-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DL輪読会]MetaFormer is Actually What You Need for Vision](https://cdn.slidesharecdn.com/ss_thumbnails/20220121metaformer-220121085750-thumbnail.jpg?width=640&height=640&fit=bounds)




![SSII2022 [TS1] Transformerの最前線〜 畳込みニューラルネットワークの先へ 〜](https://cdn.slidesharecdn.com/ss_thumbnails/ts120220608ssiitransformerr2-220607054025-3adacf07-thumbnail.jpg?width=640&height=640&fit=bounds)





![SSII2021 [SS1] Transformer x Computer Visionの 実活用可能性と展望 〜 TransformerのCompute...](https://cdn.slidesharecdn.com/ss_thumbnails/ss1-01-210607043349-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]An Image is Worth 16x16 Words: Transformers for Image Recognition at S...](https://cdn.slidesharecdn.com/ss_thumbnails/dl10161-201016015214-thumbnail.jpg?width=640&height=640&fit=bounds)


































