Download to read offline











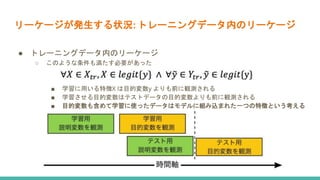







データマイニングや機械学習をやるときによく問題となる「リーケージ」を防ぐ方法について論じた論文「Leakage in Data Mining: Formulation, Detecting, and Avoidance」(Kaufman, Shachar, et al., ACM Transactions on Knowledge Discovery from Data (TKDD) 6.4 (2012): 1-21.)を解説します。 主な内容は以下のとおりです。 ・過去に起きたリーケージの事例の紹介 ・リーケージを防ぐための2つの考え方 ・リーケージの発見 ・リーケージの修正








![SSII2022 [SS2] 少ないデータやラベルを効率的に活用する機械学習技術 〜 足りない情報をどのように補うか?〜](https://cdn.slidesharecdn.com/ss_thumbnails/ss2ssii2022-220607054716-2760bd30-thumbnail.jpg?width=640&height=640&fit=bounds)

![SSII2021 [OS2-01] 転移学習の基礎:異なるタスクの知識を利用するための機械学習の方法](https://cdn.slidesharecdn.com/ss_thumbnails/os2-02final-210610091211-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DL輪読会]ドメイン転移と不変表現に関するサーベイ](https://cdn.slidesharecdn.com/ss_thumbnails/20190614iwasawa-190614005939-thumbnail.jpg?width=640&height=640&fit=bounds)





![[DL輪読会]NVAE: A Deep Hierarchical Variational Autoencoder](https://cdn.slidesharecdn.com/ss_thumbnails/nvaeadeephierarchicalvariationalautoencoder-201113004930-thumbnail.jpg?width=640&height=640&fit=bounds)



























