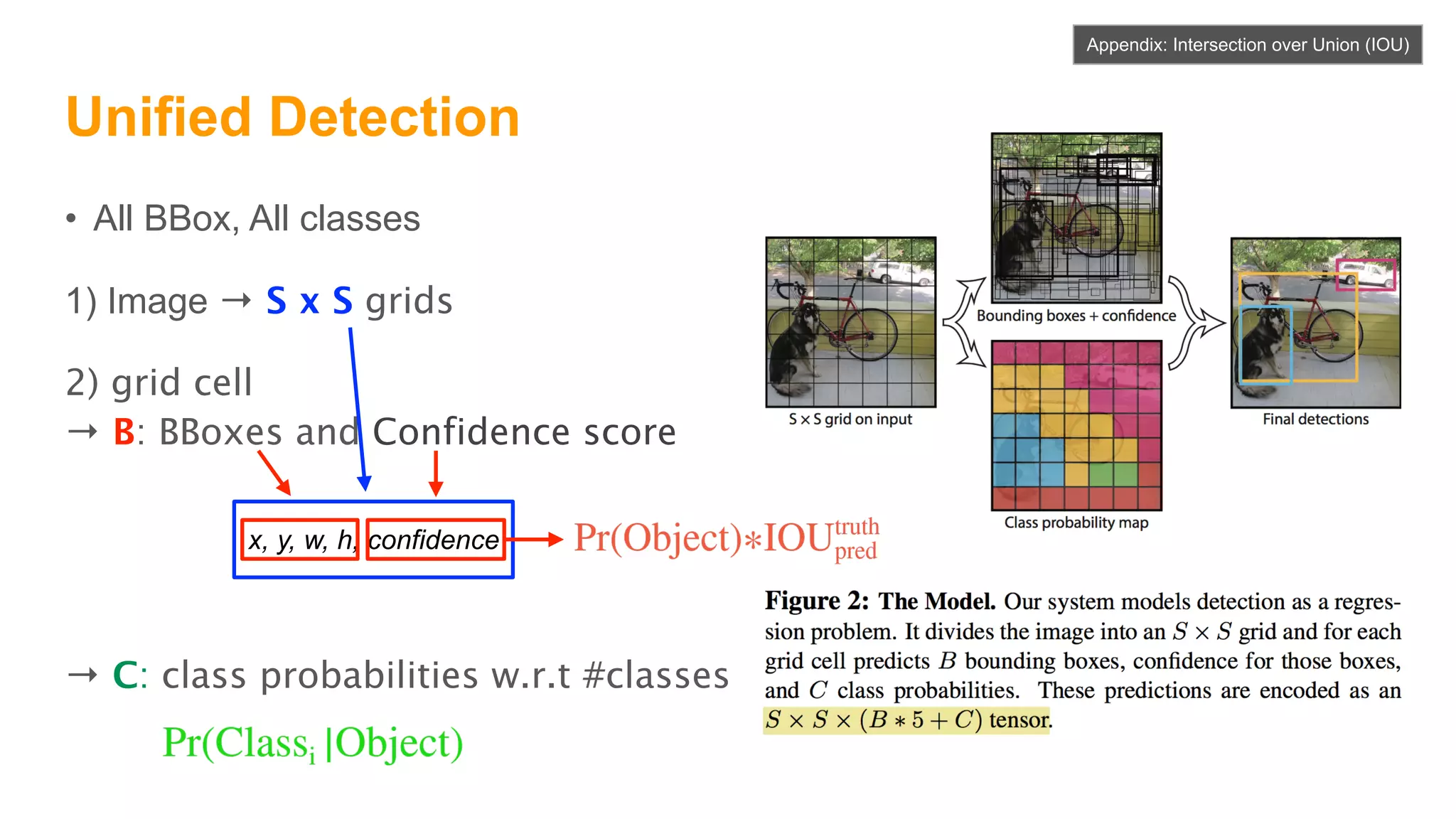
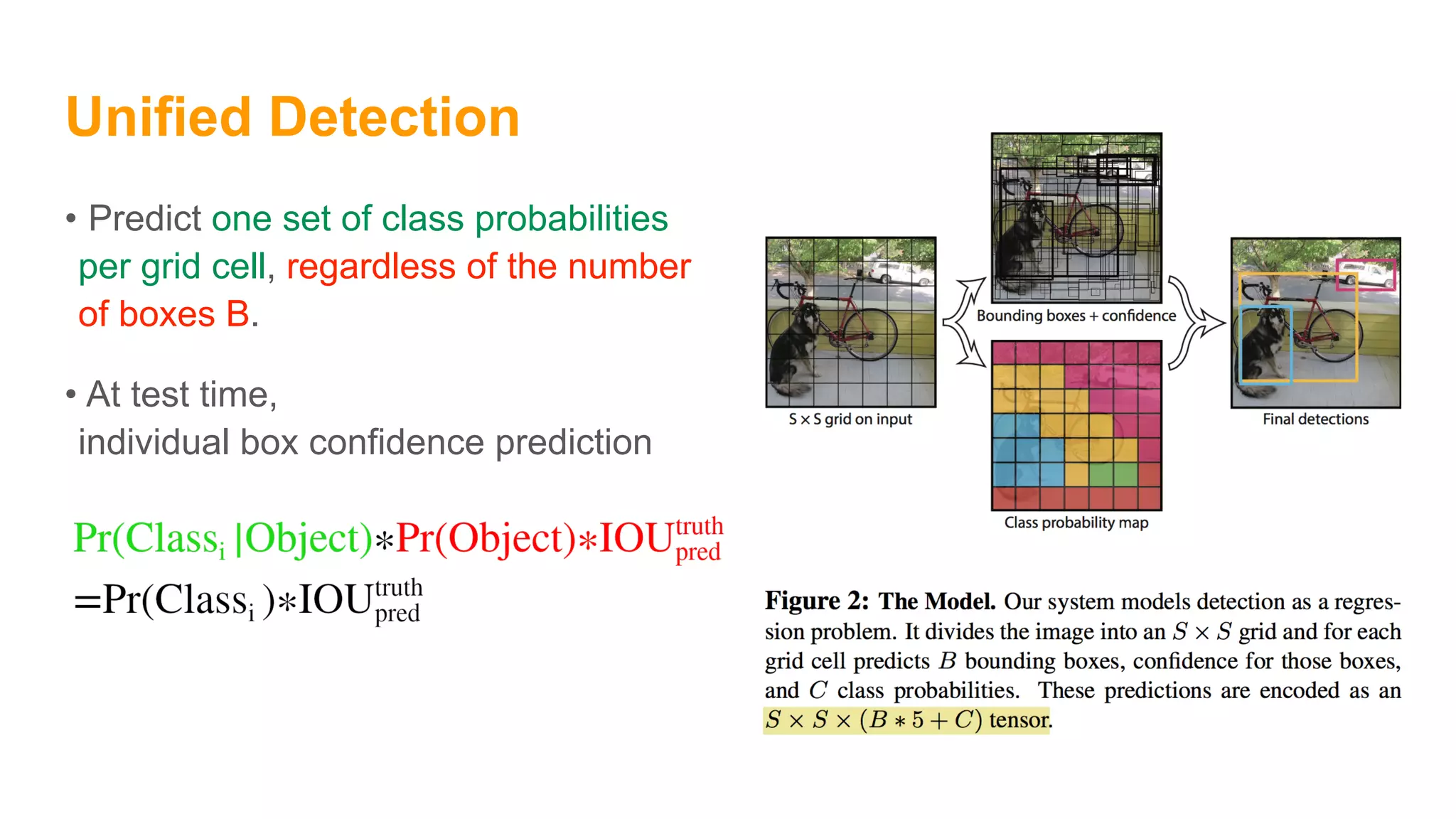
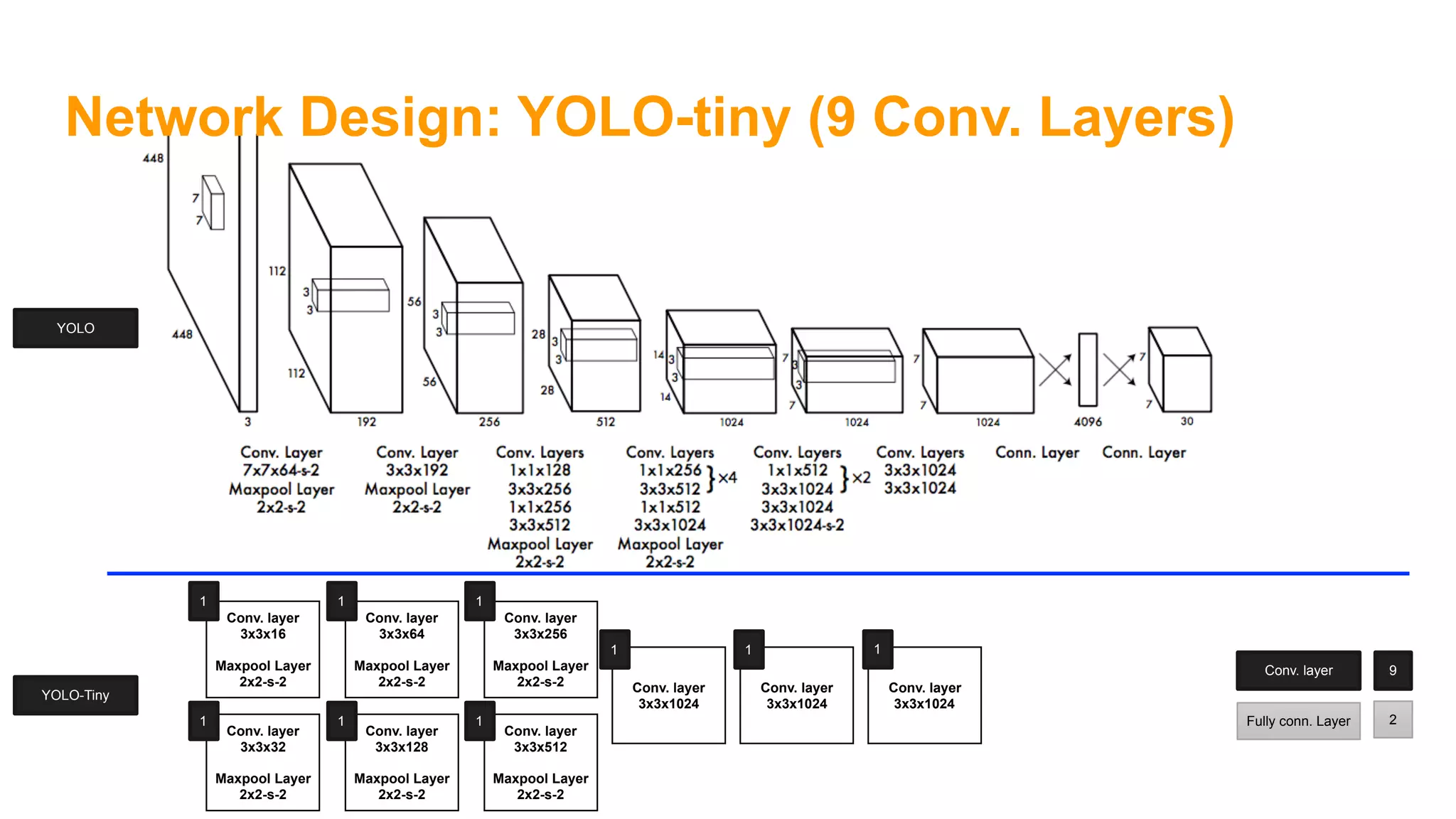
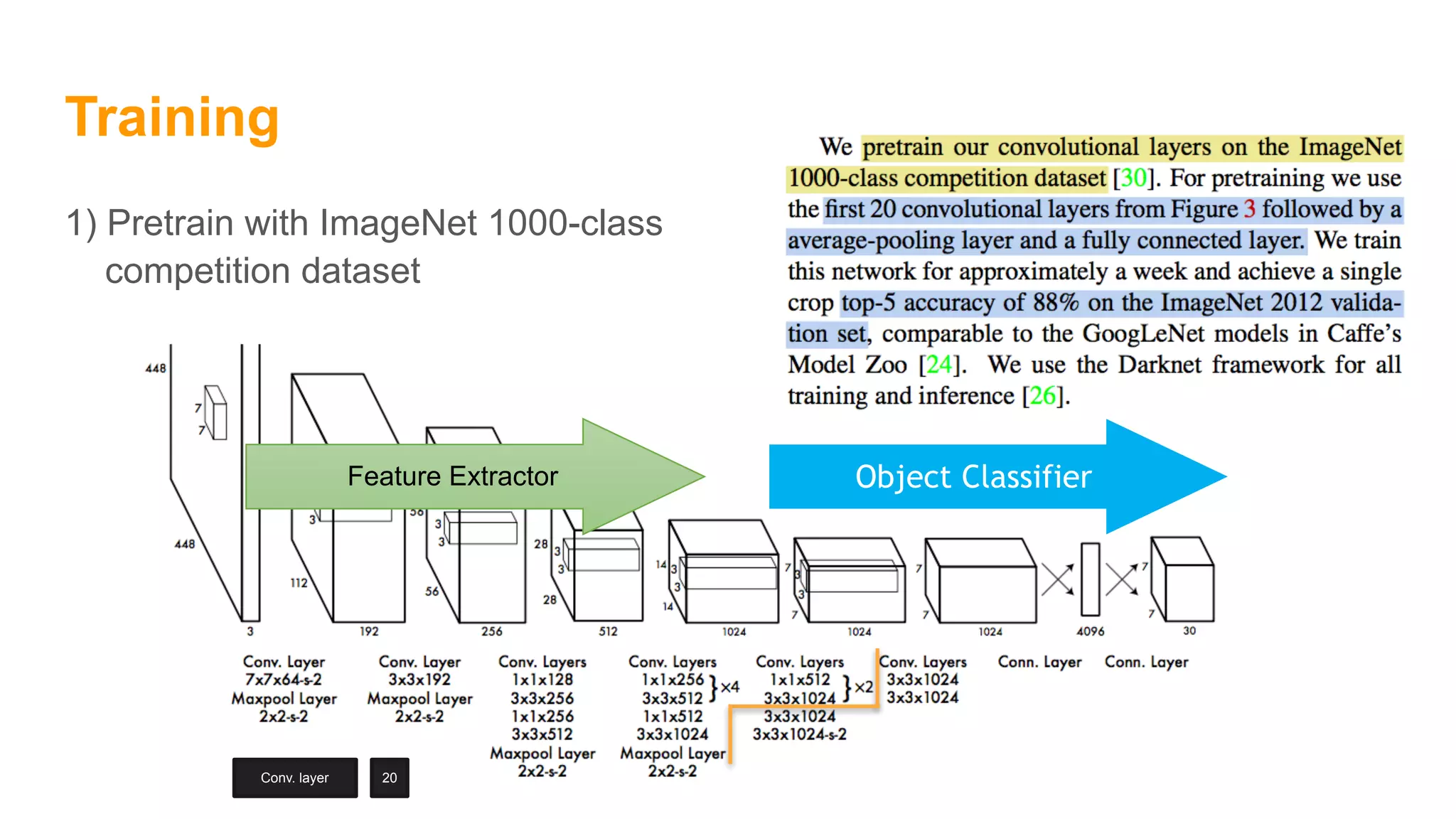
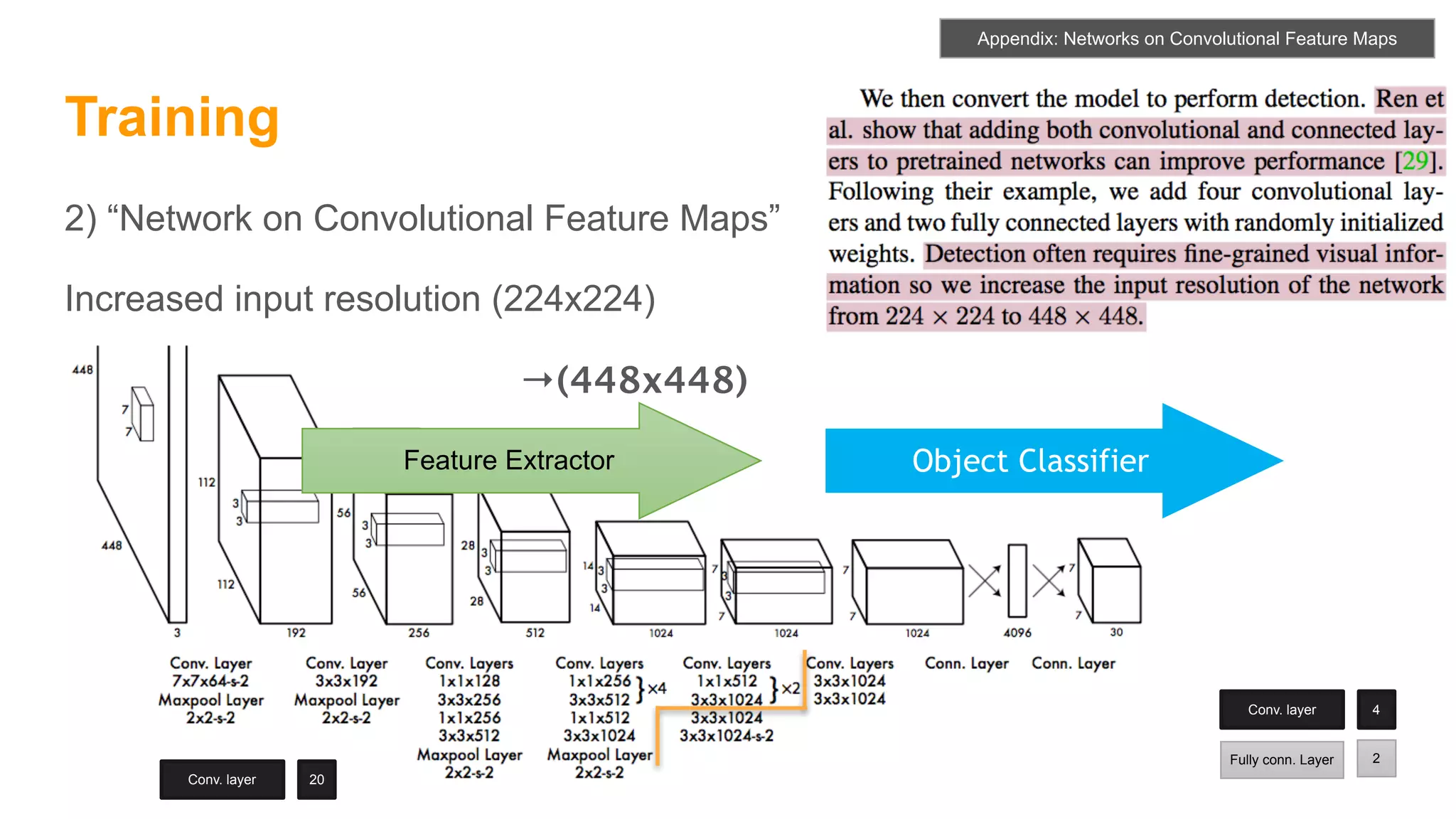
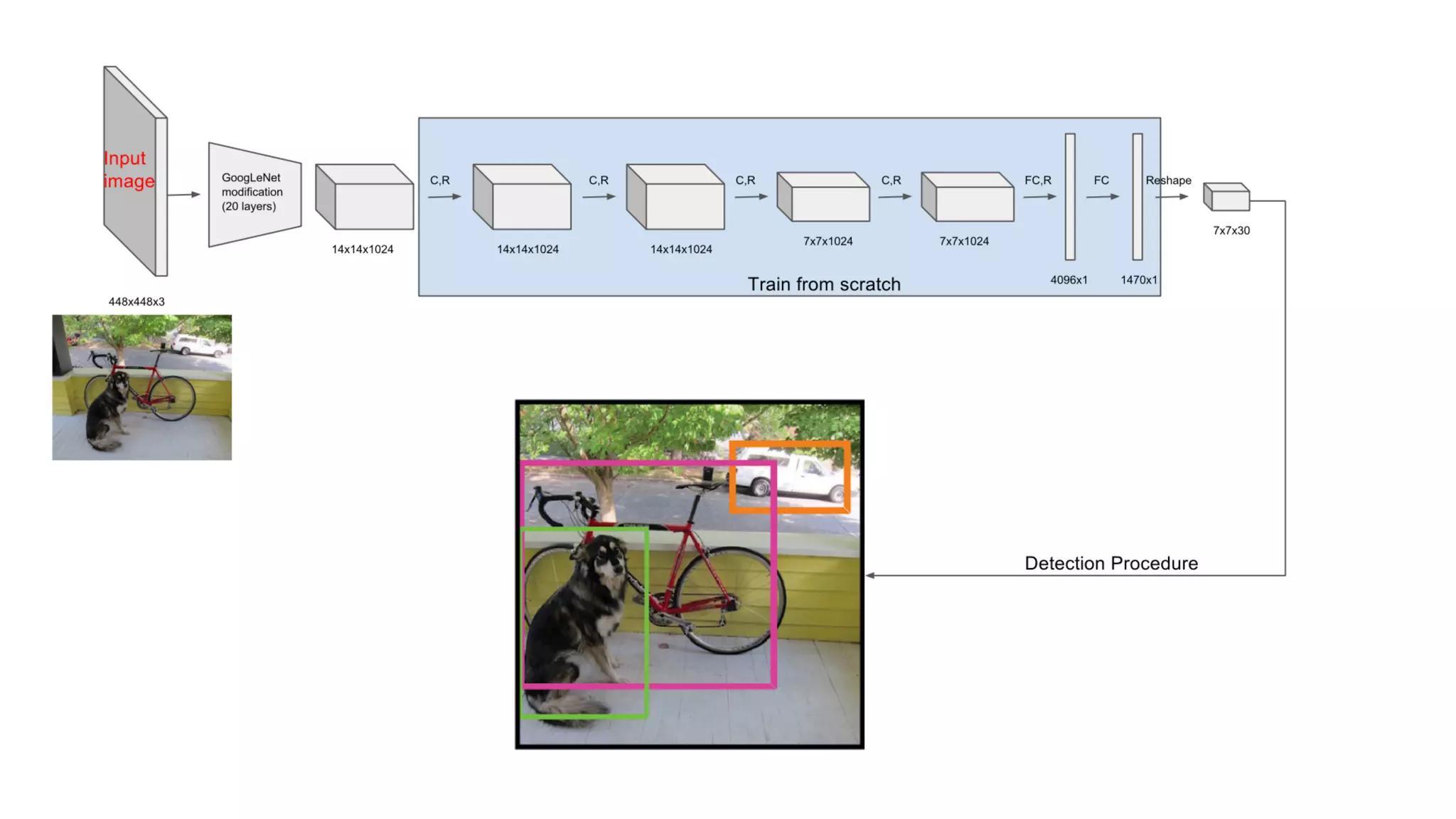
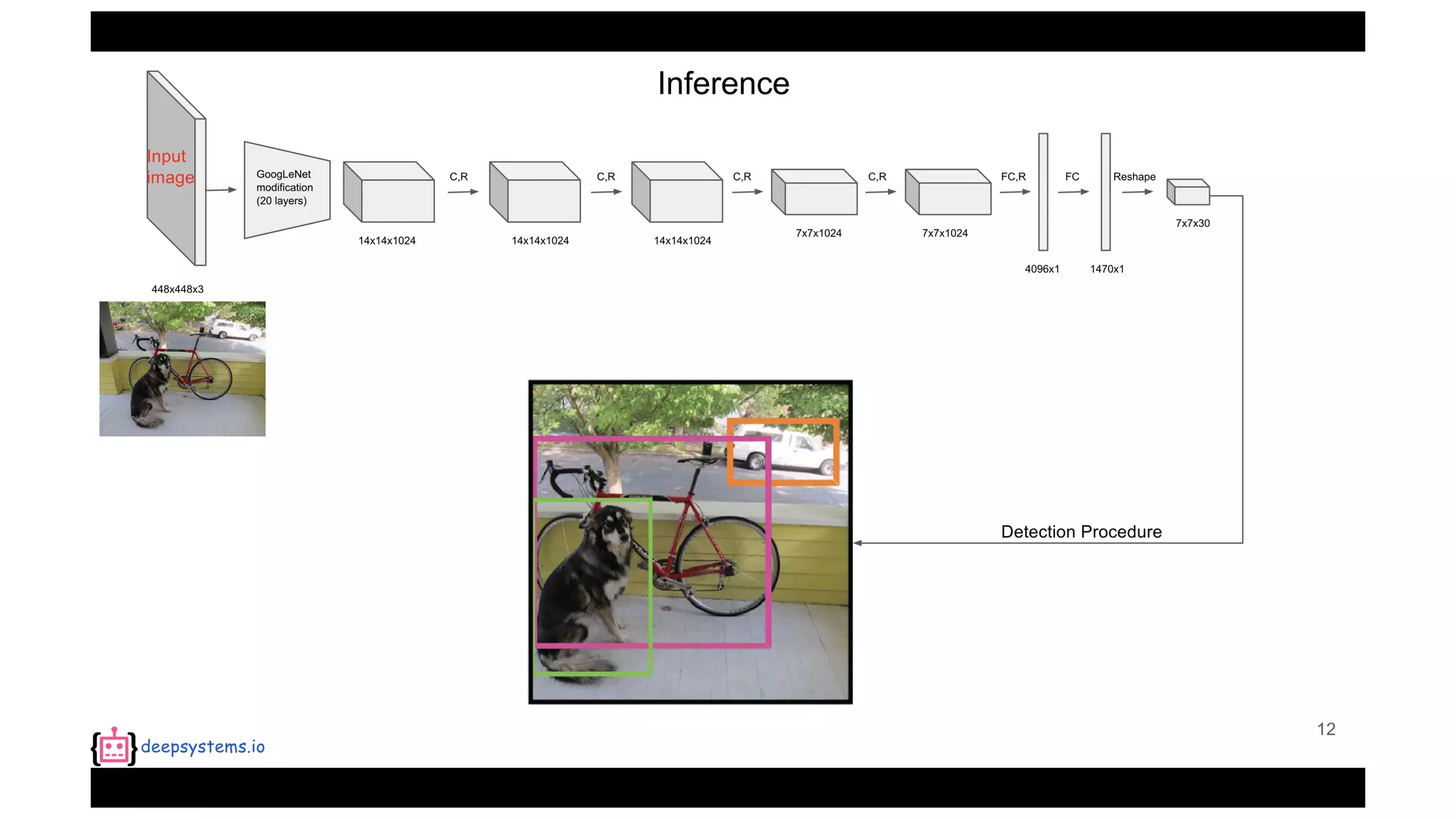
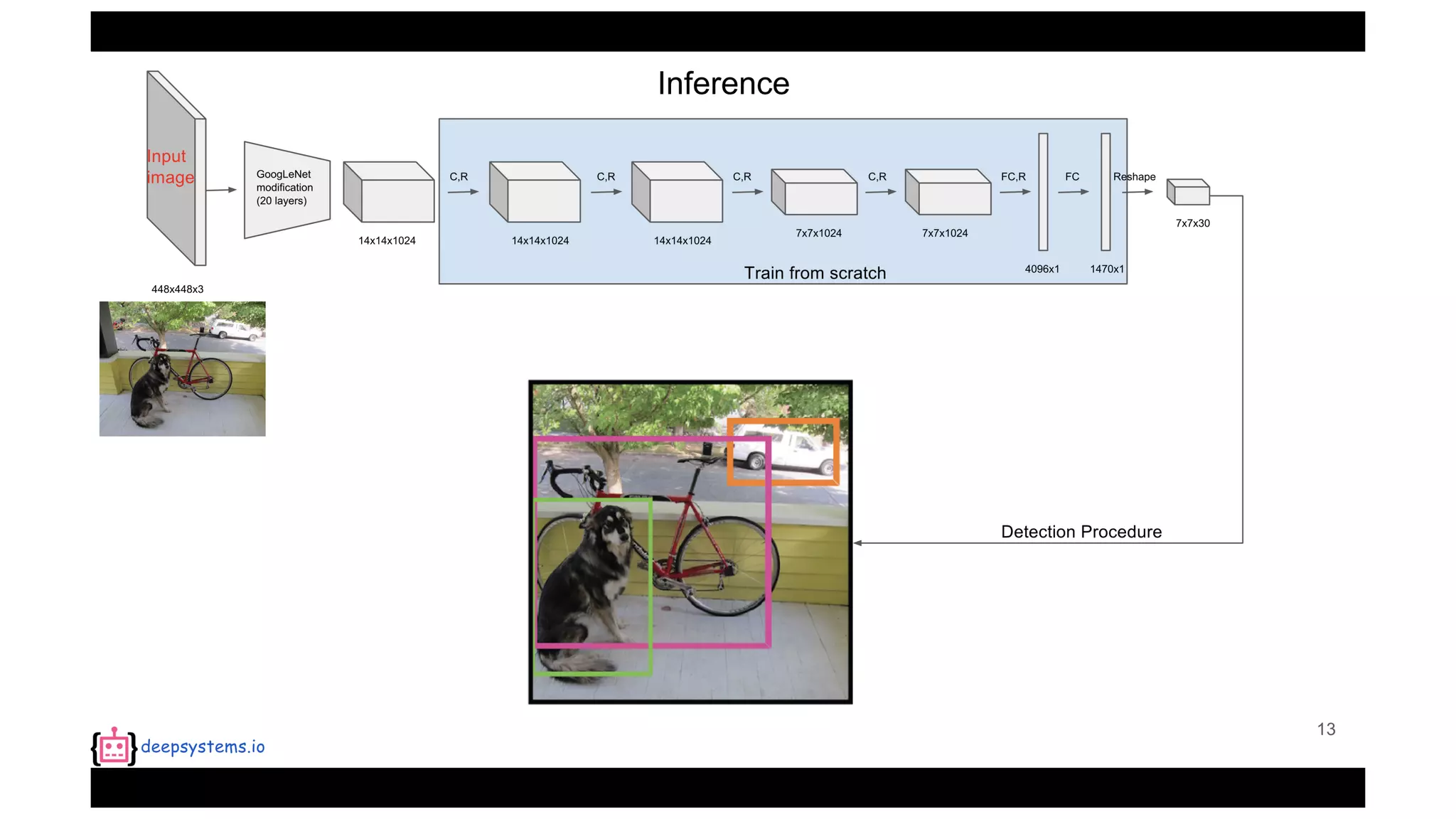
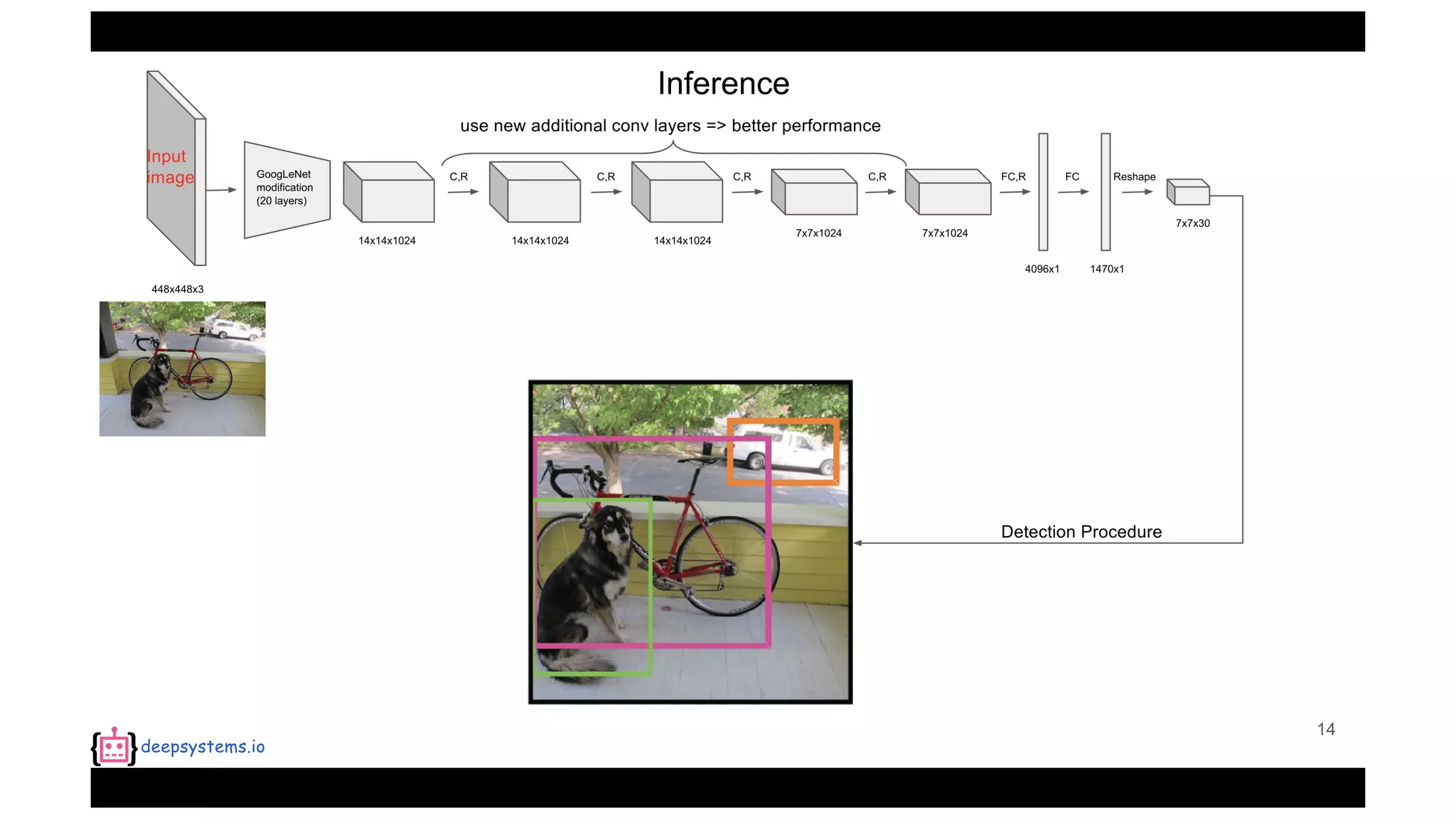
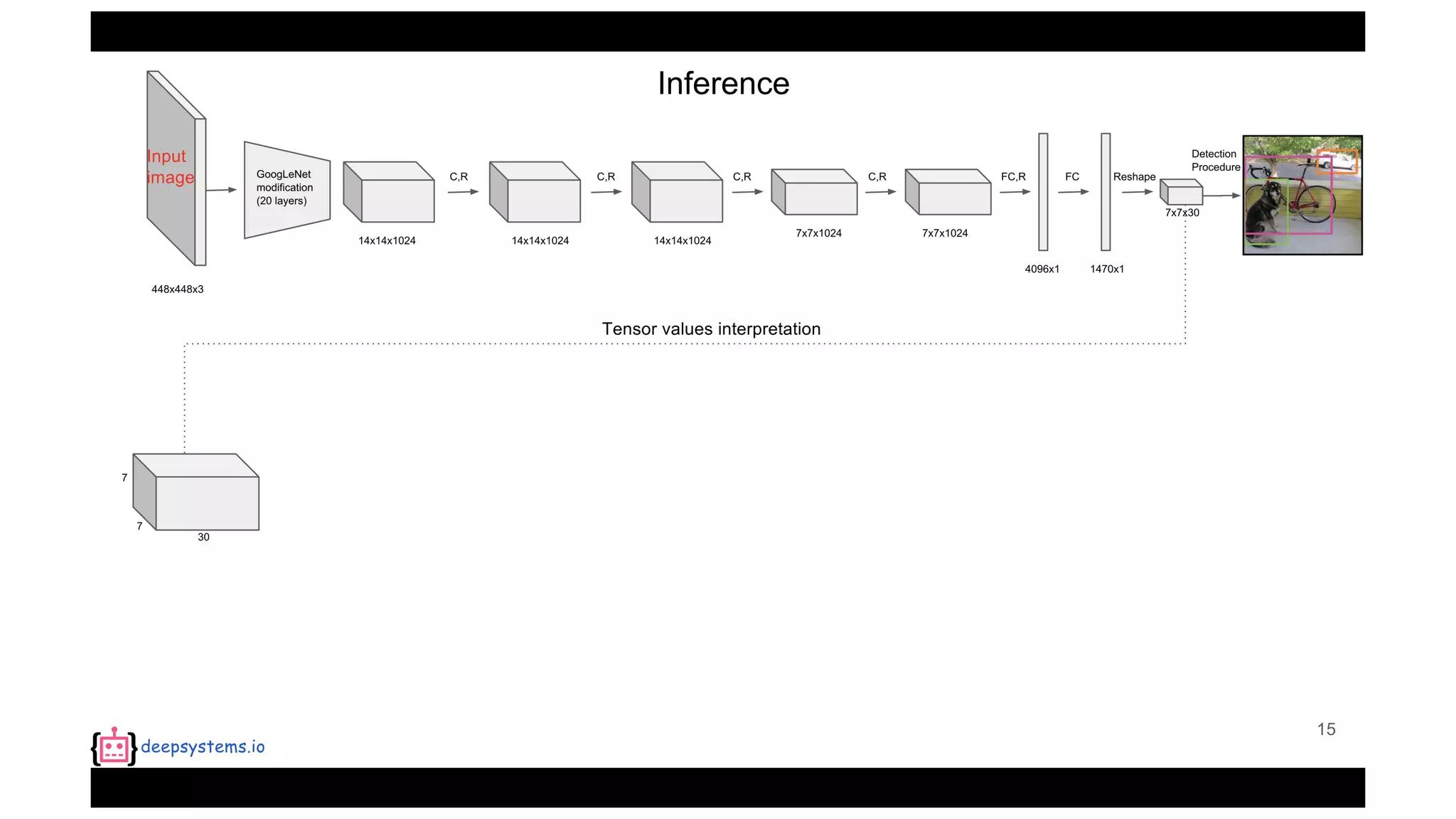
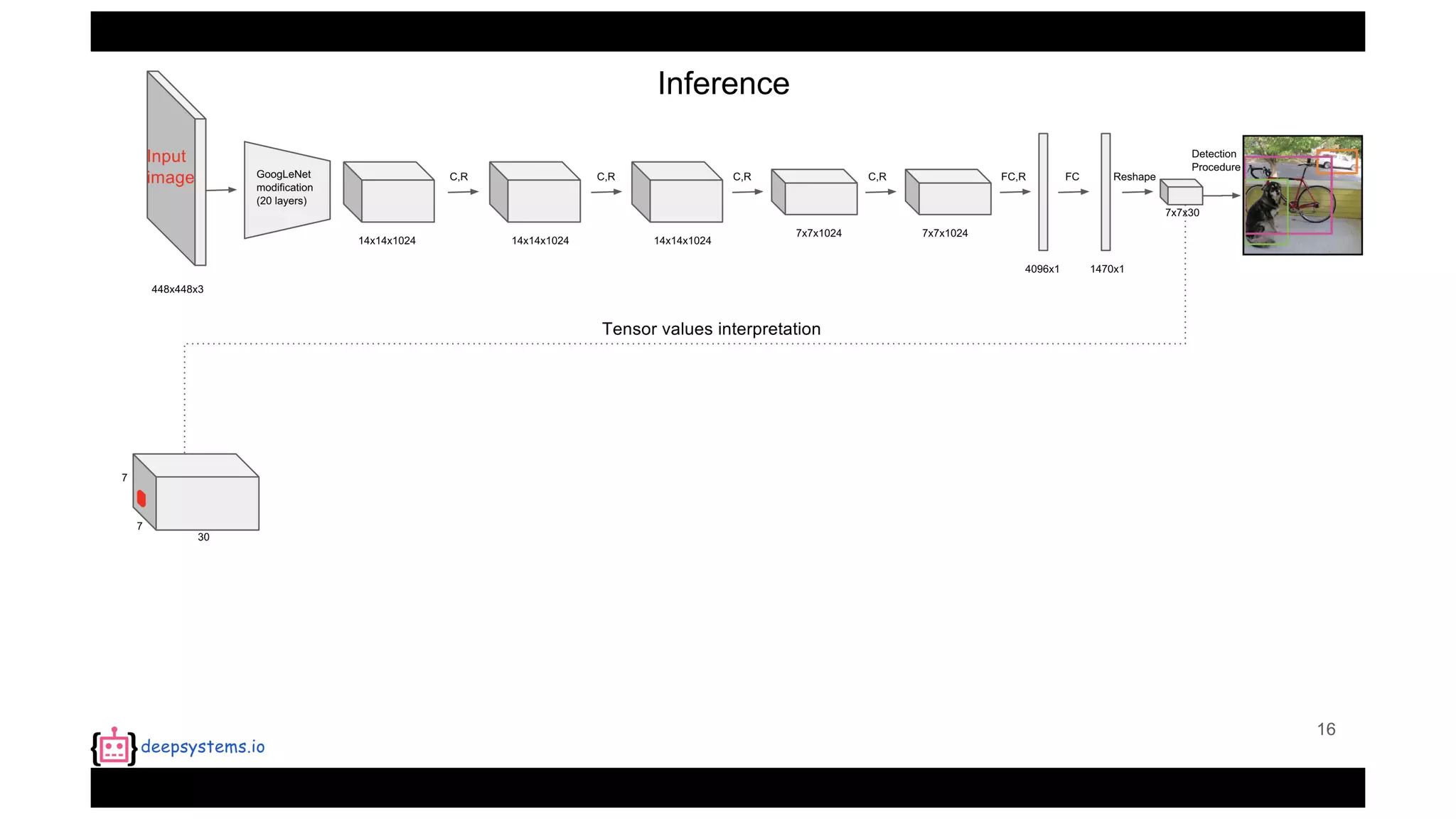
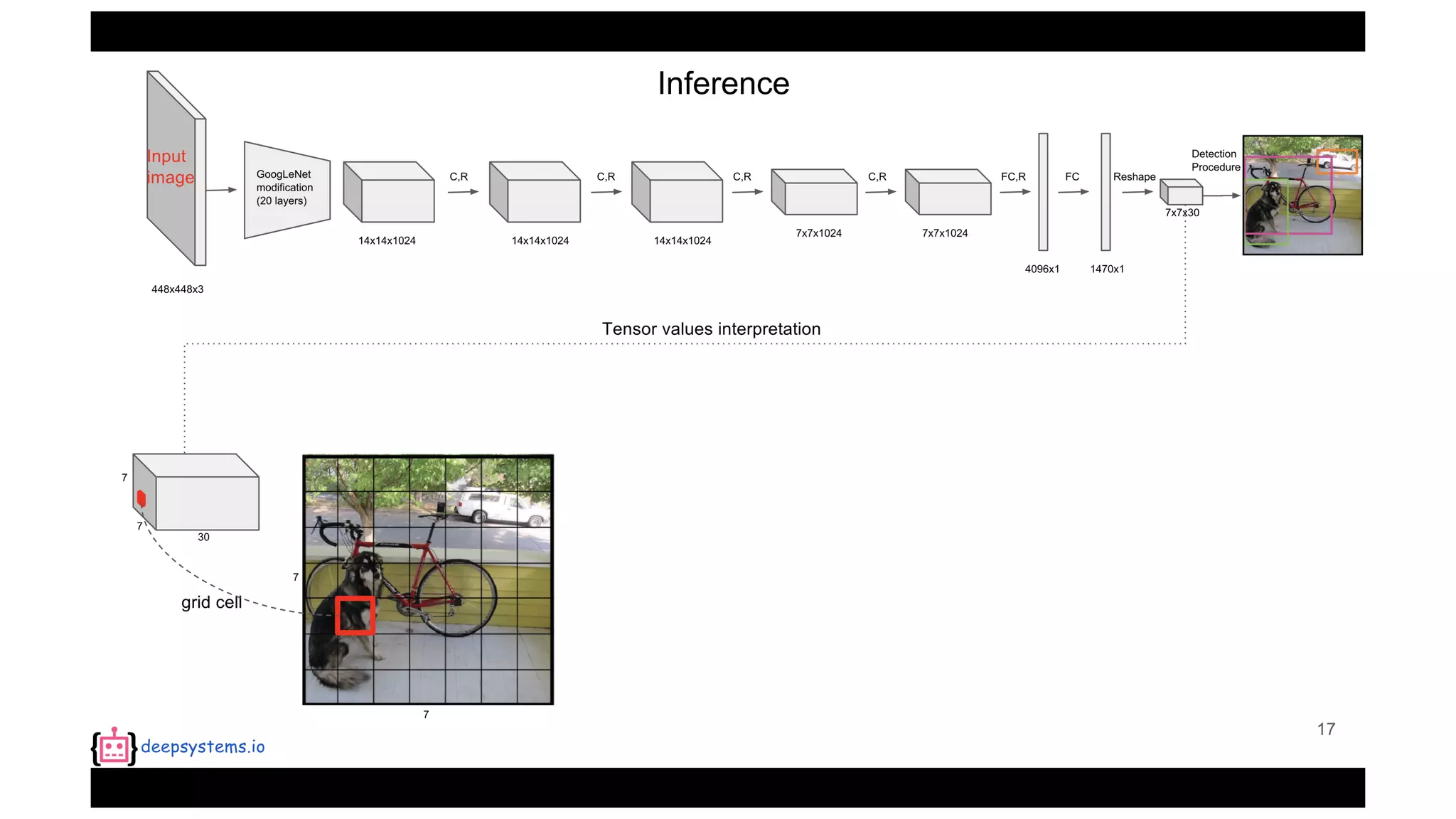
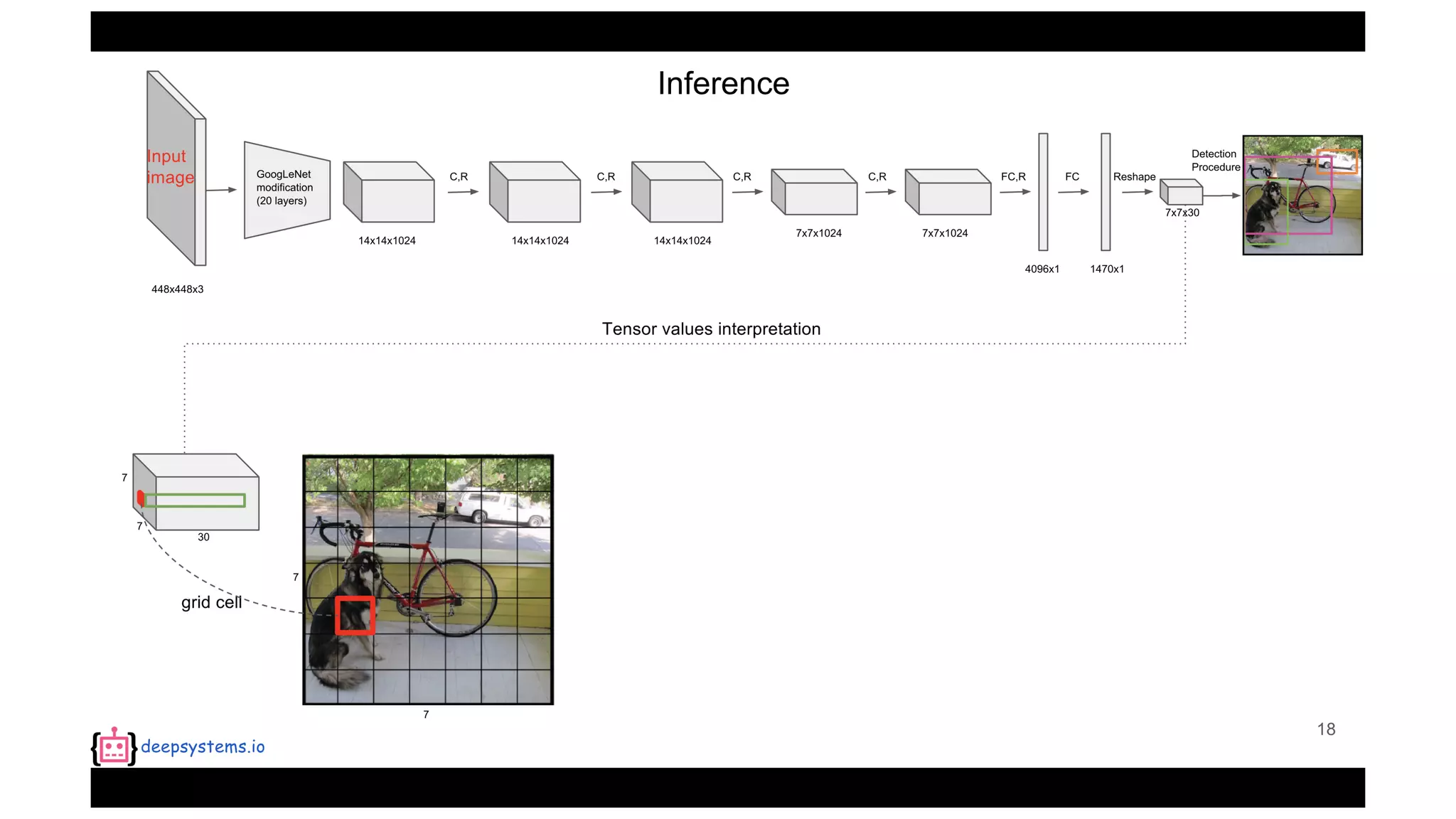
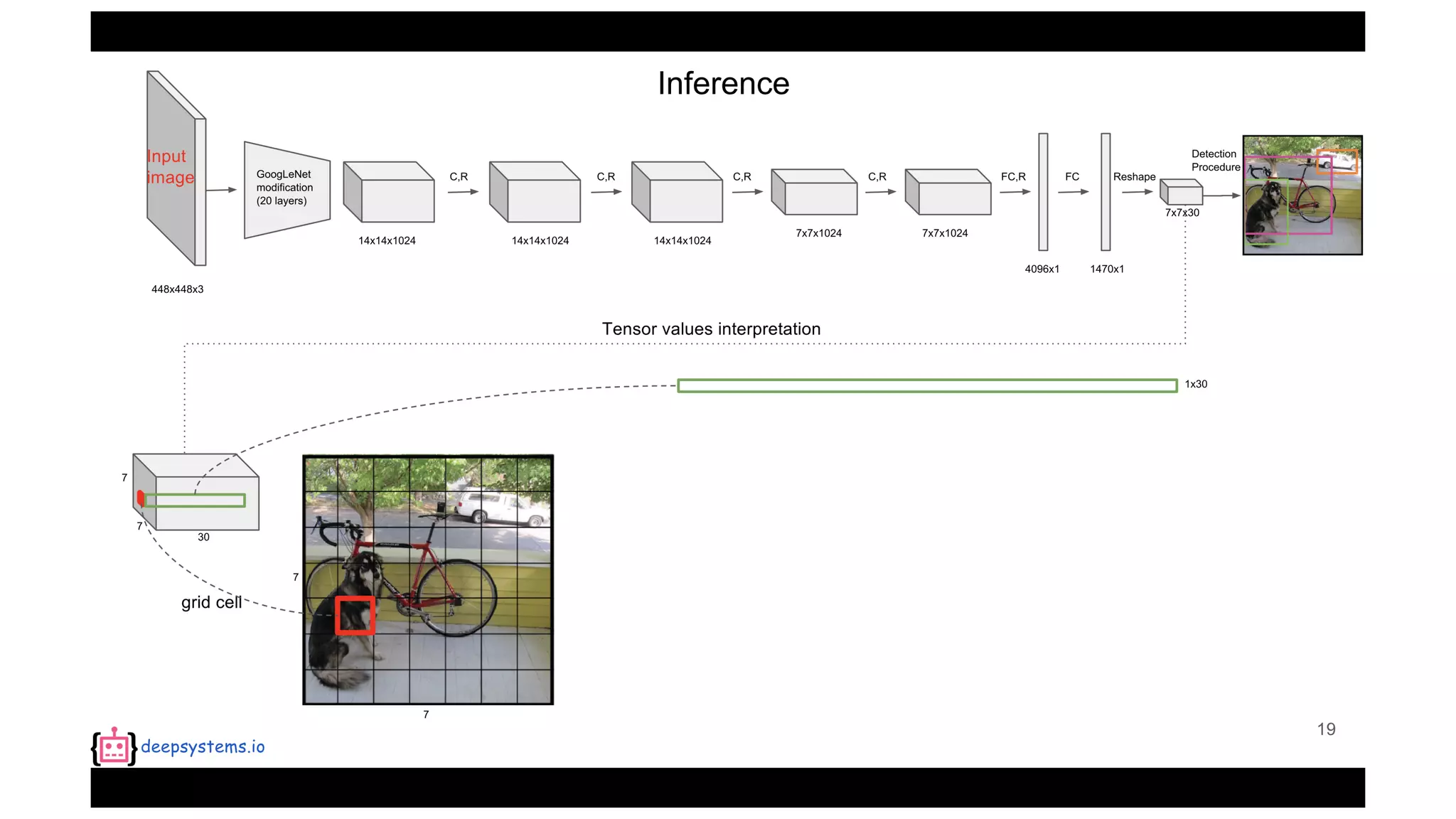
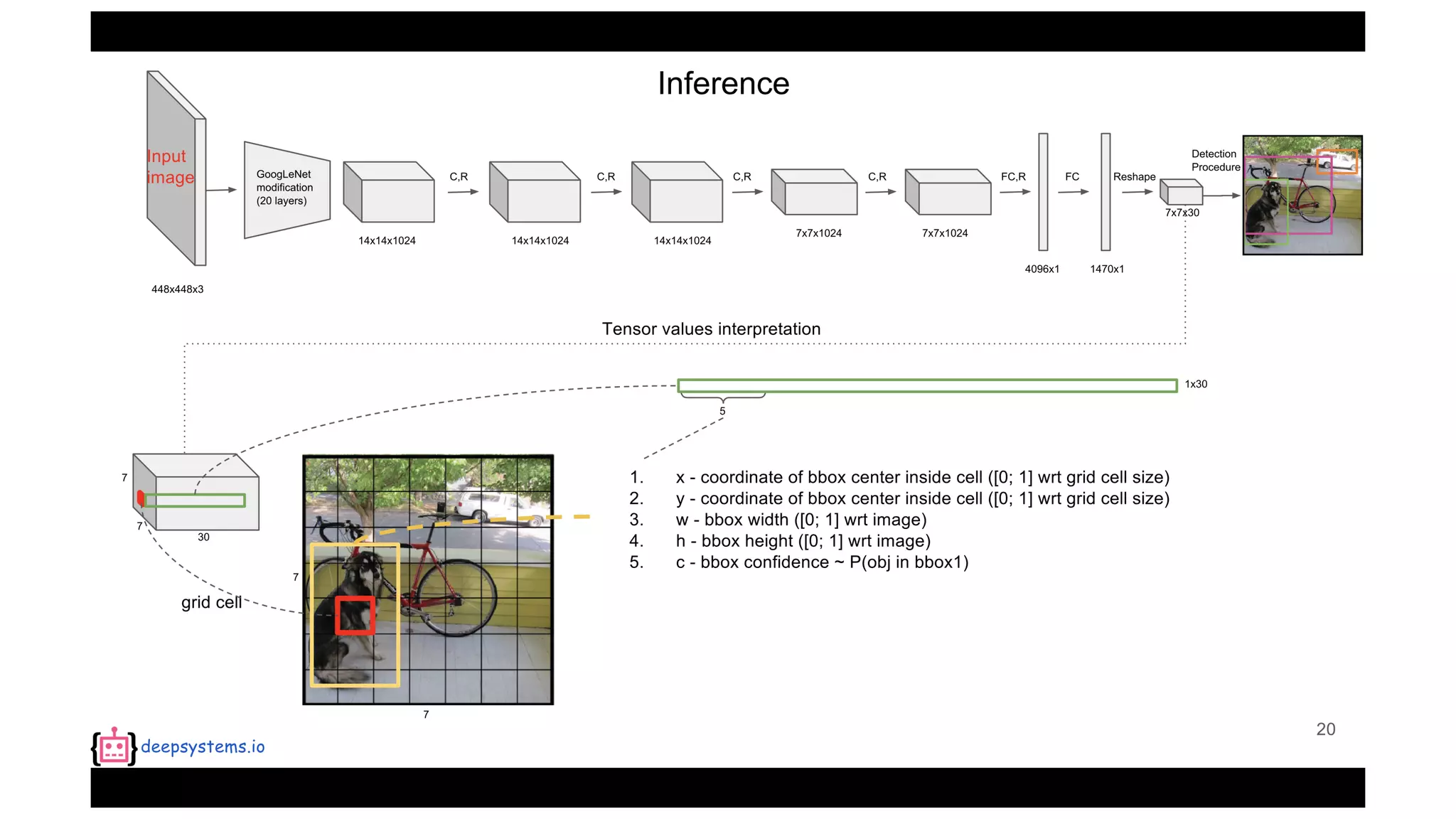
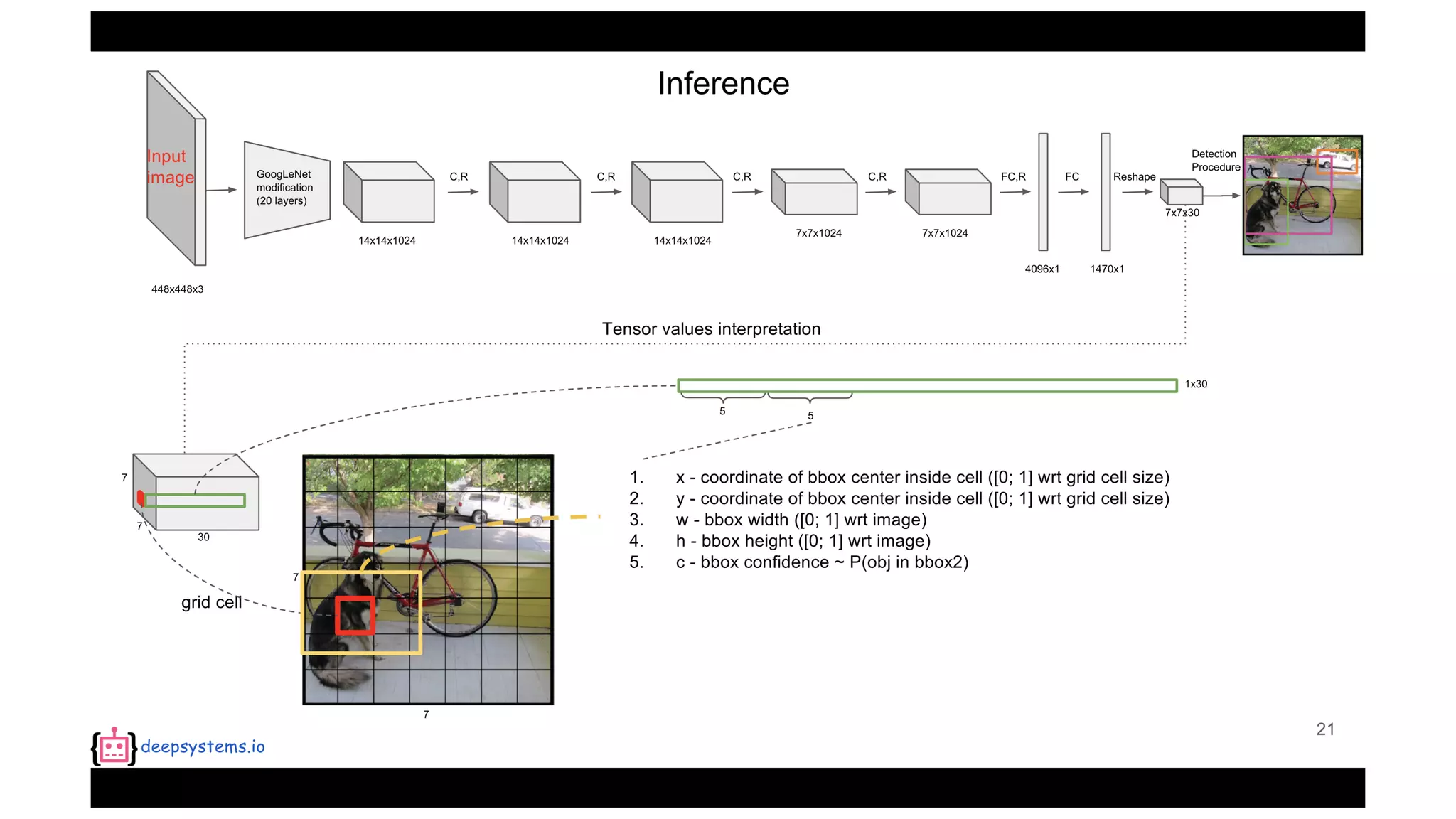
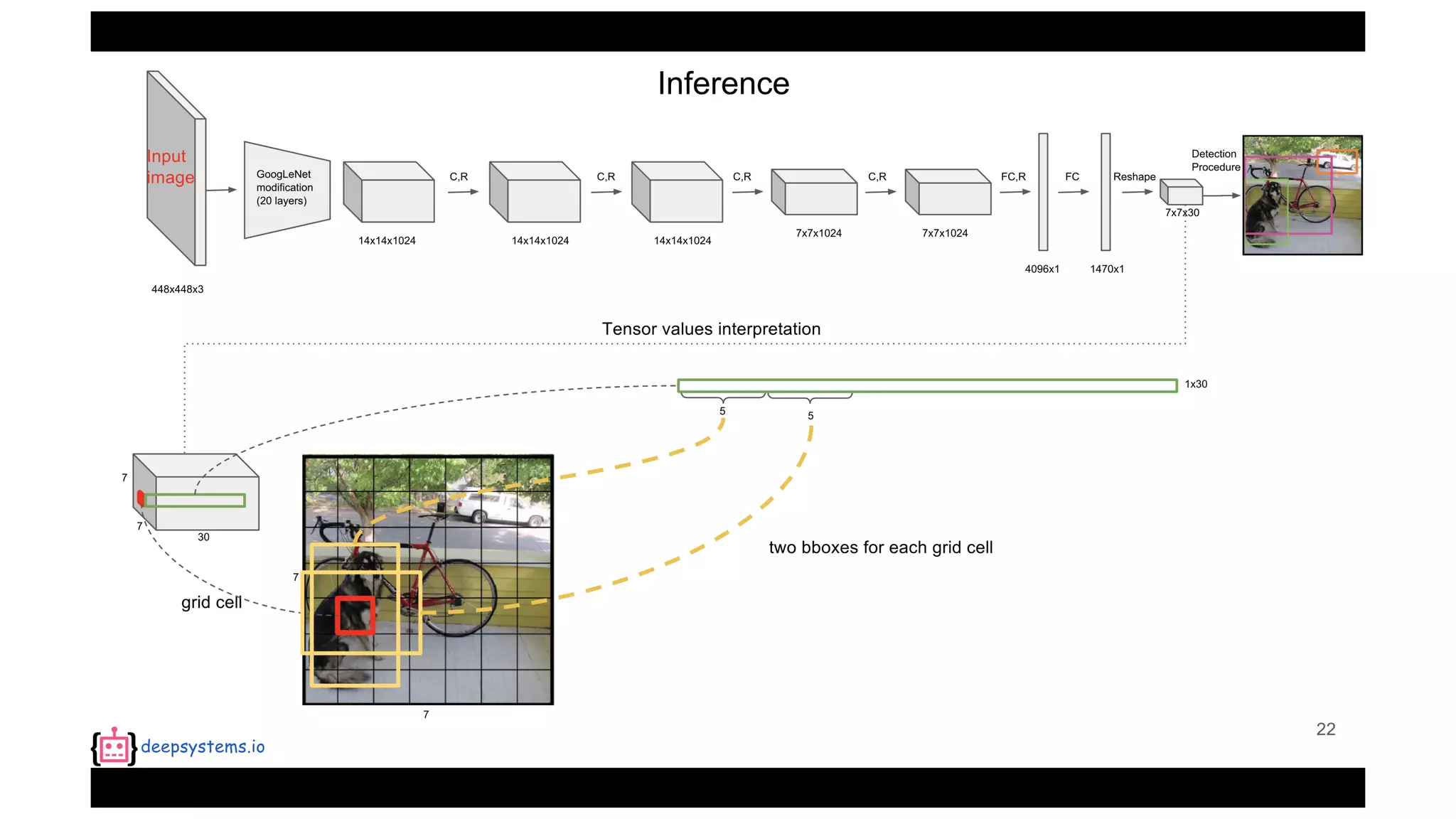
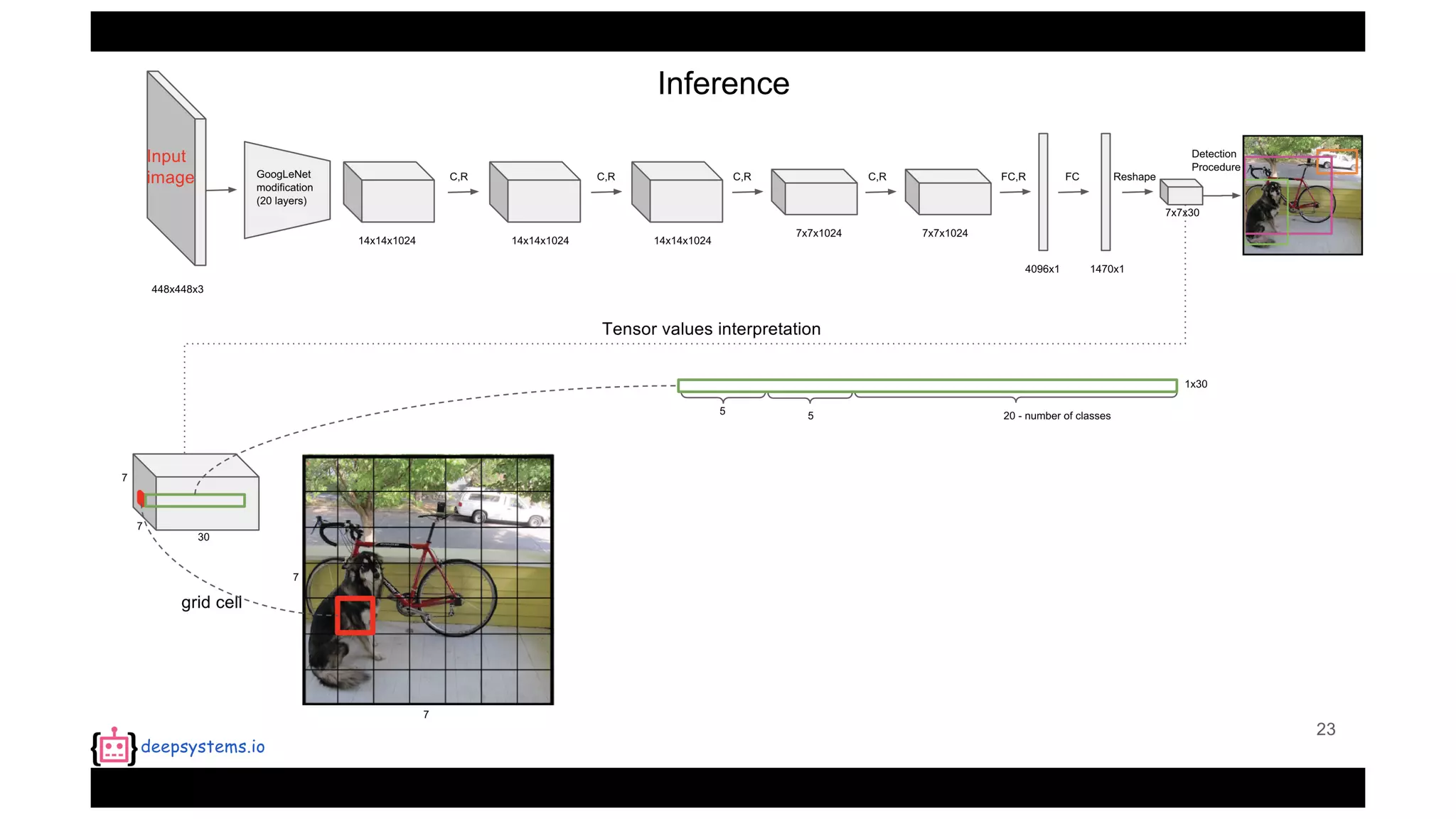
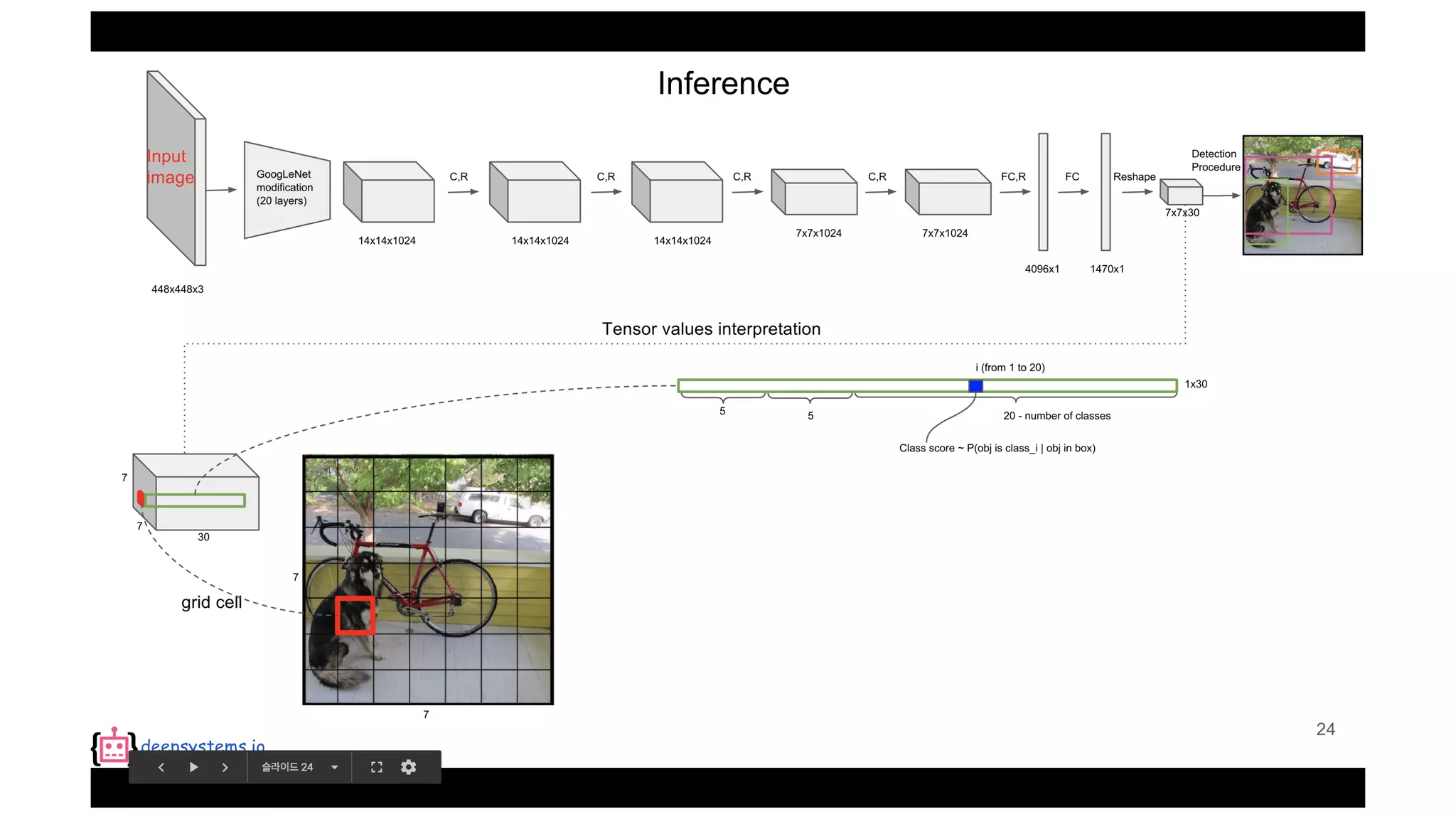
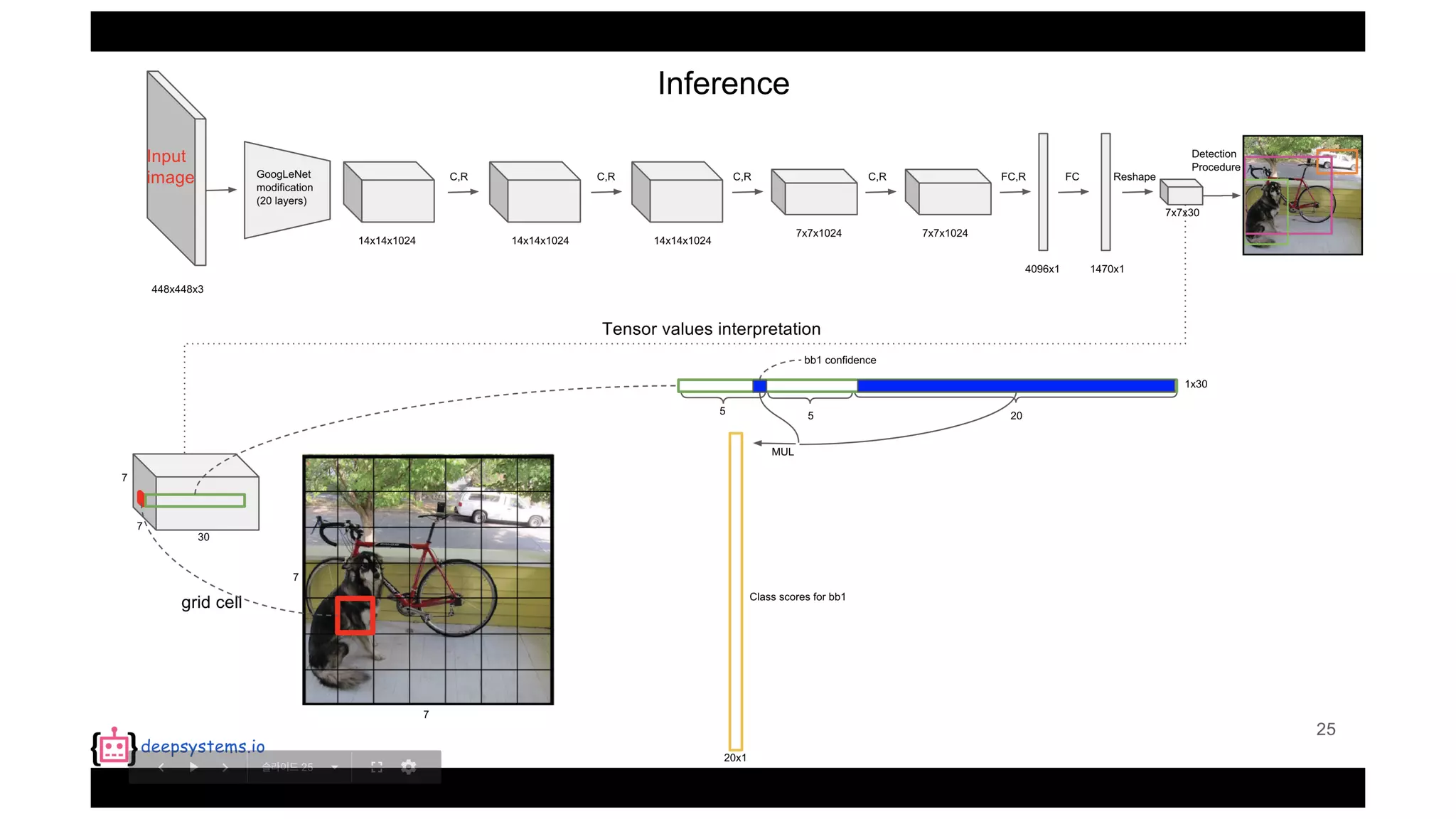
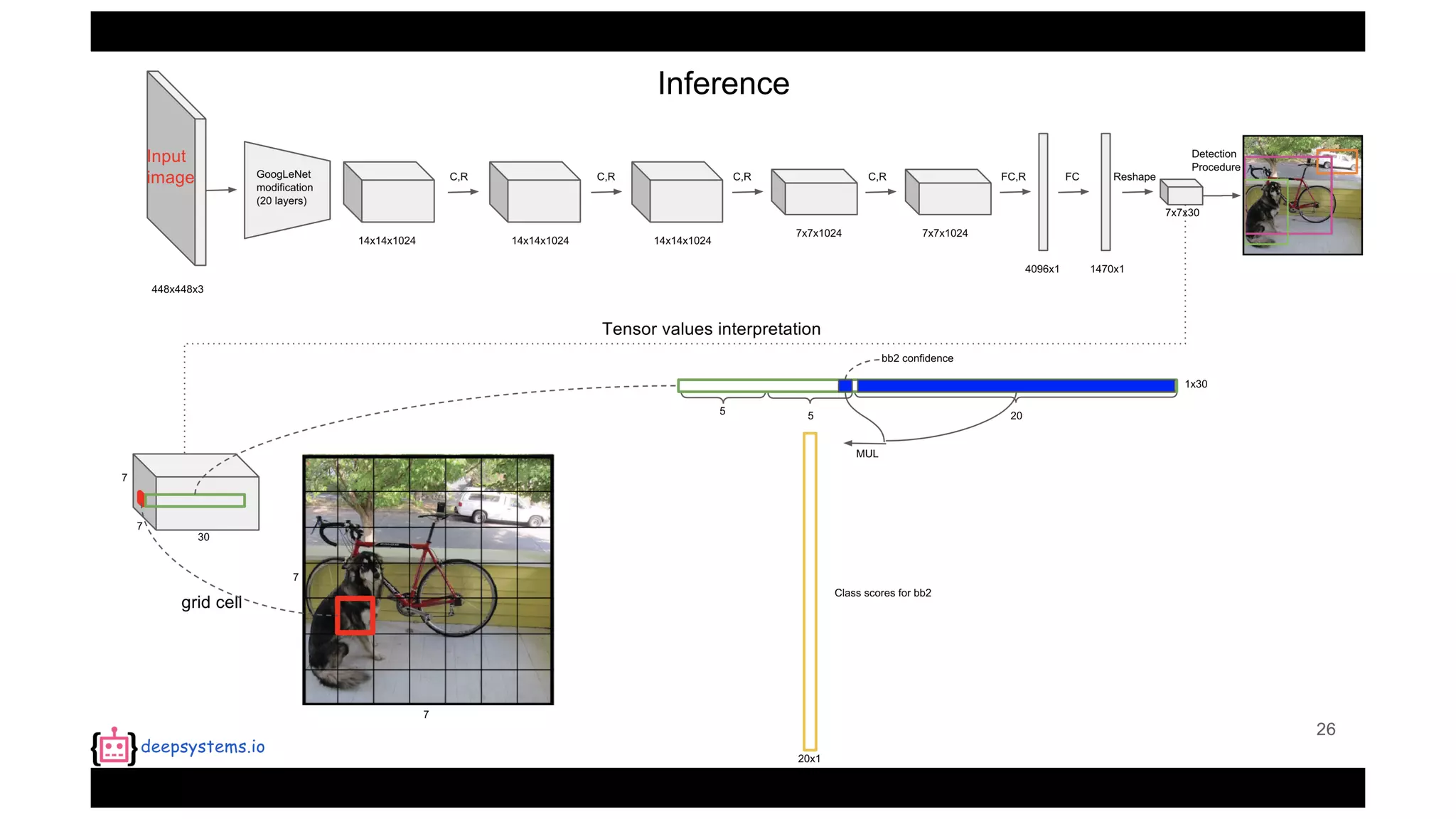
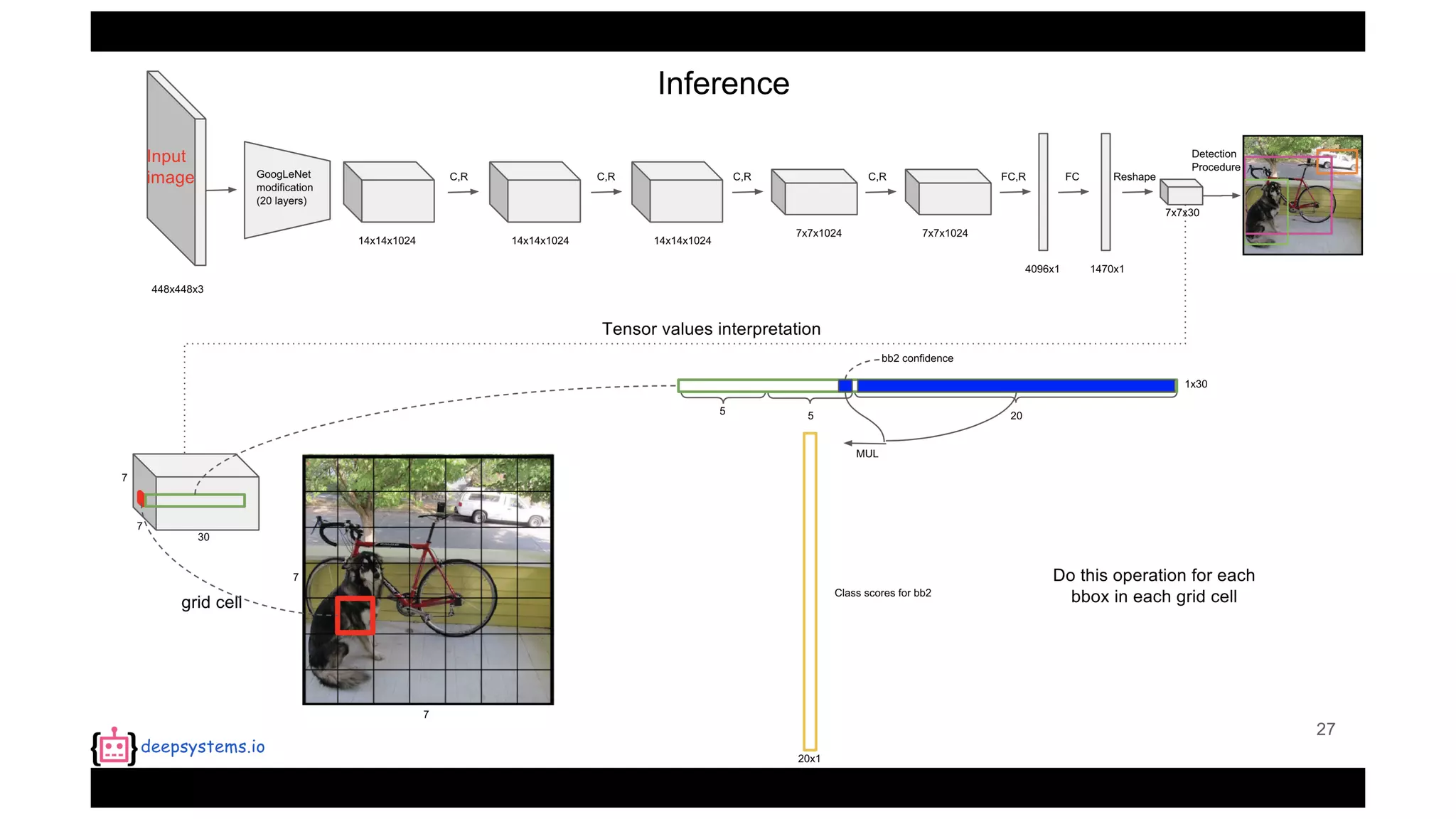
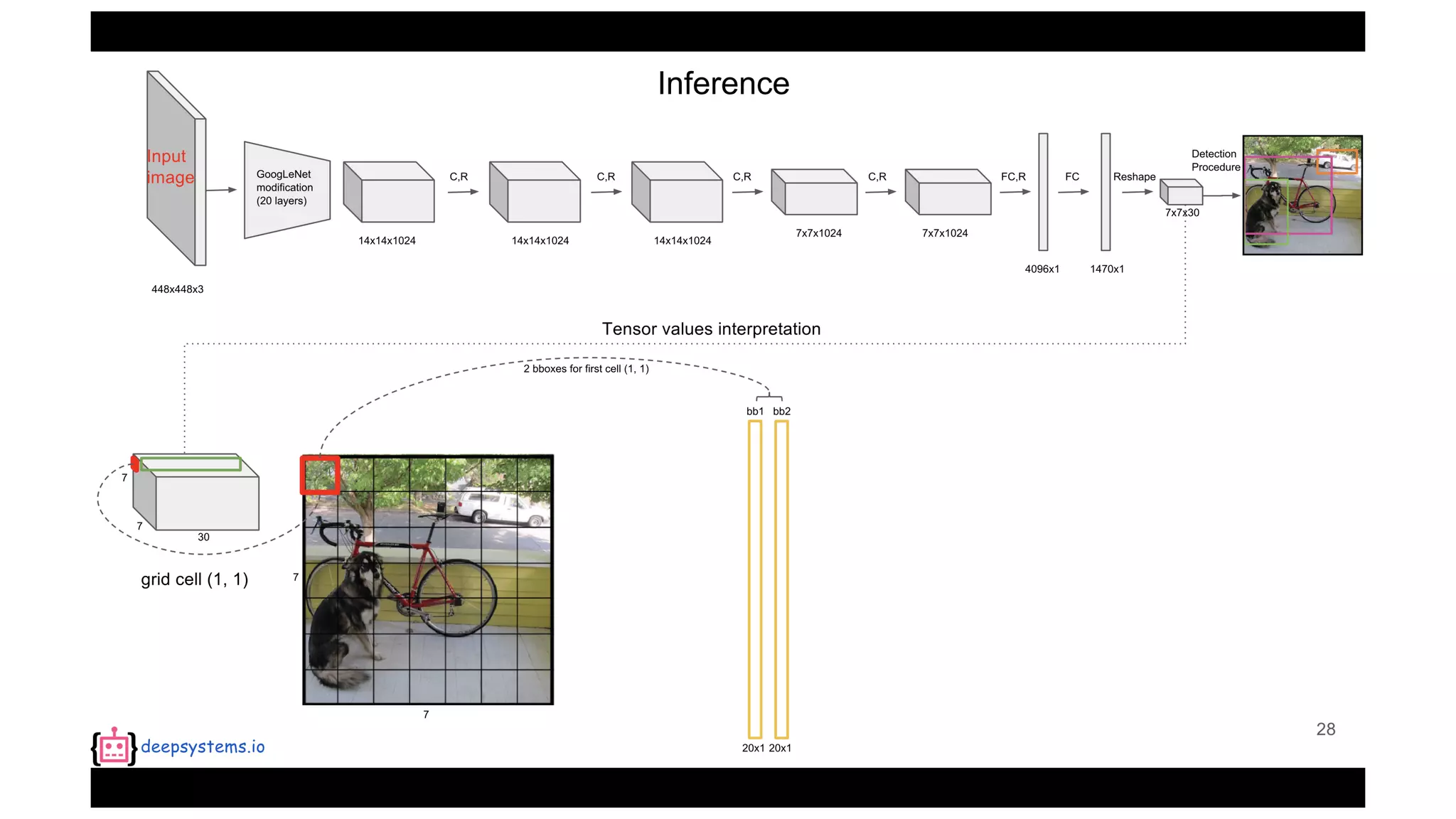
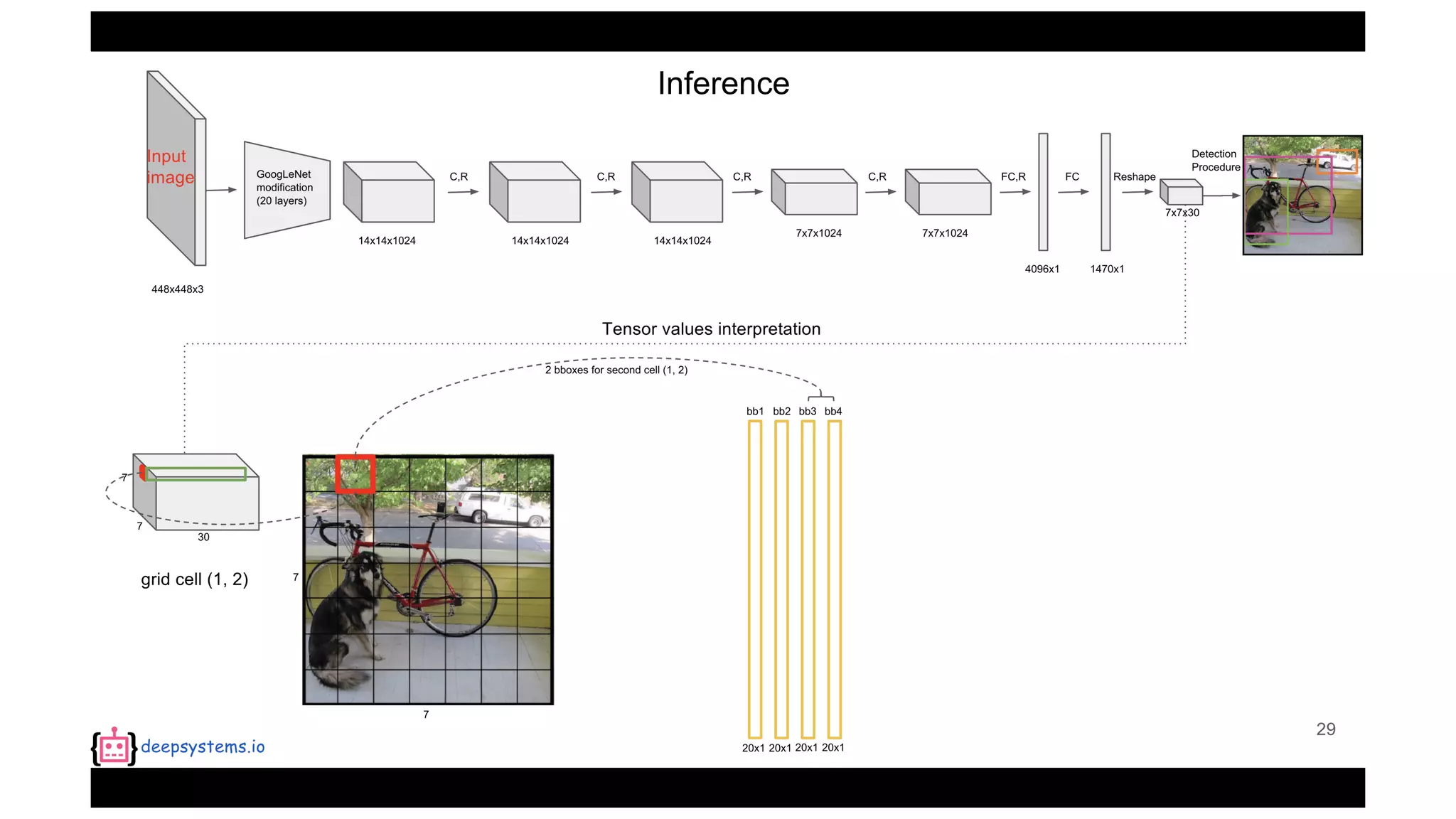
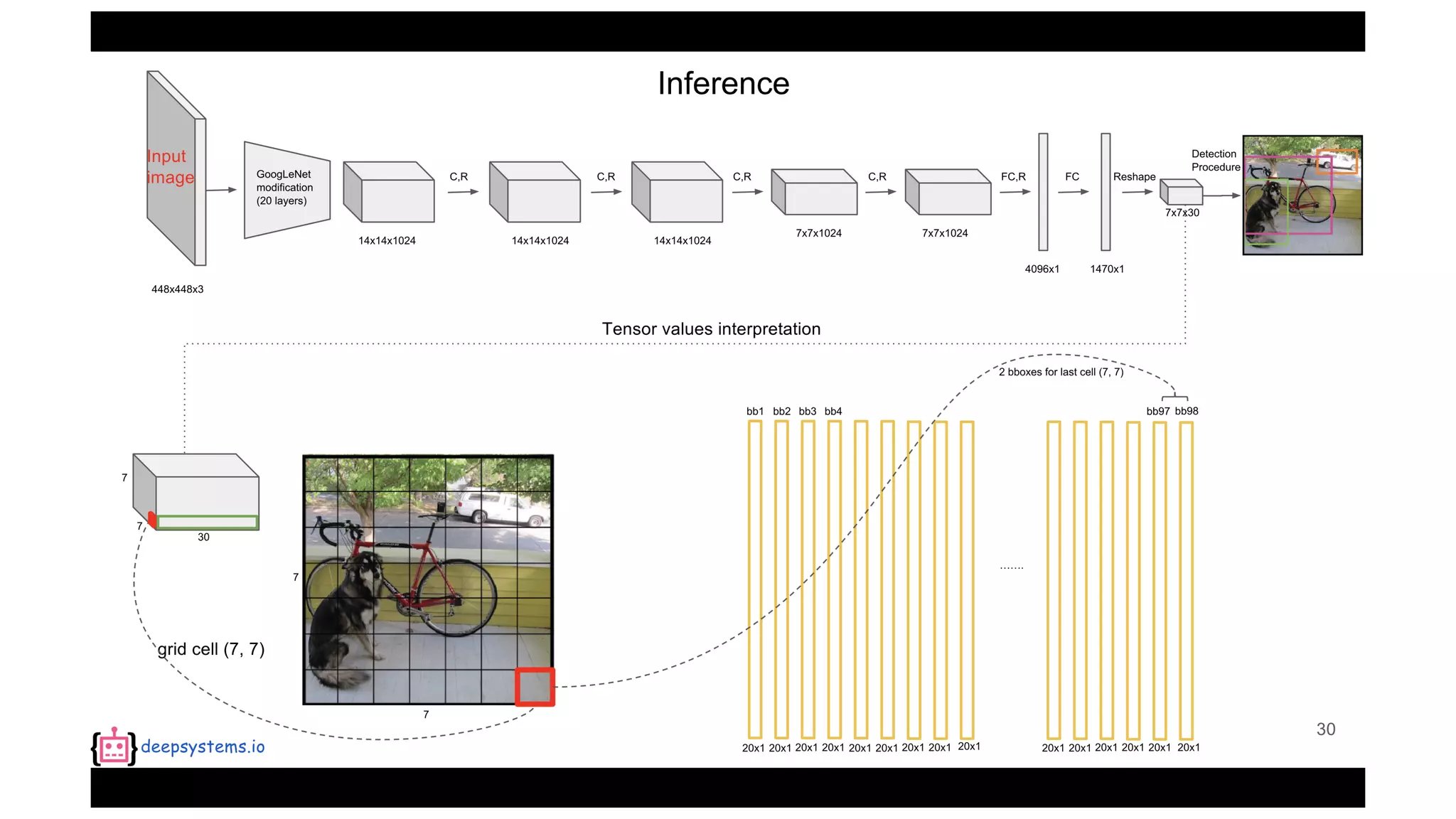
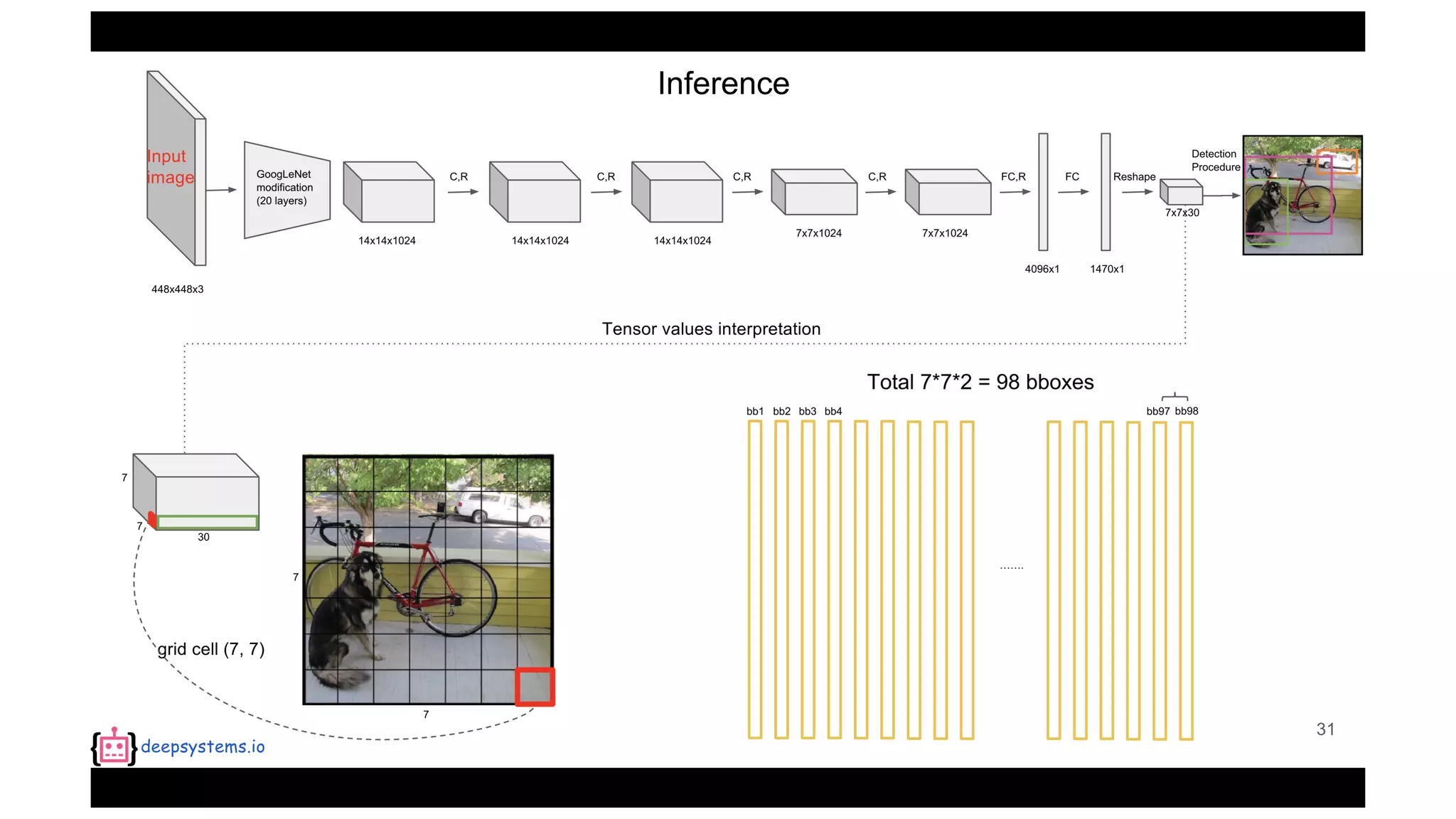
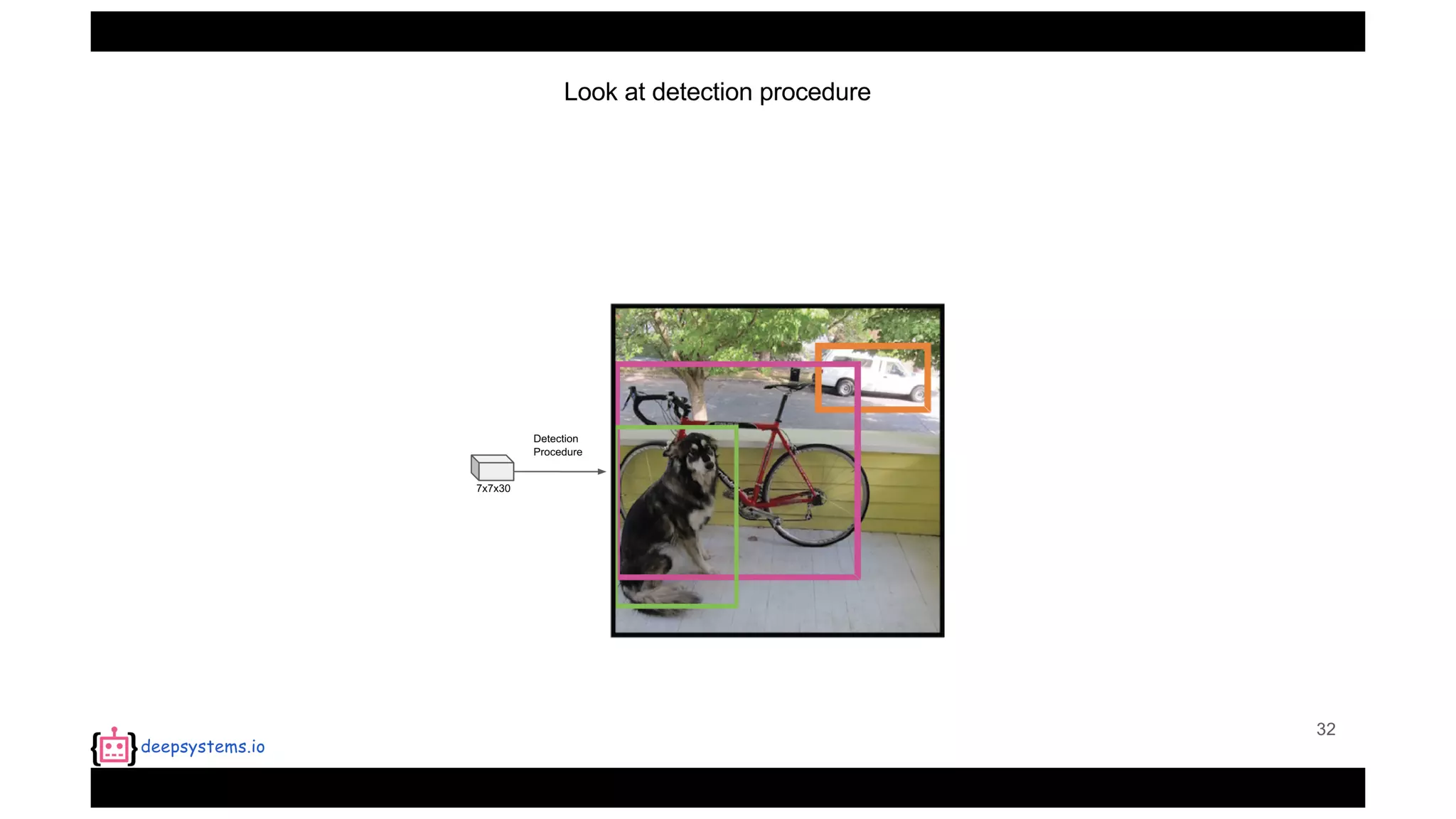
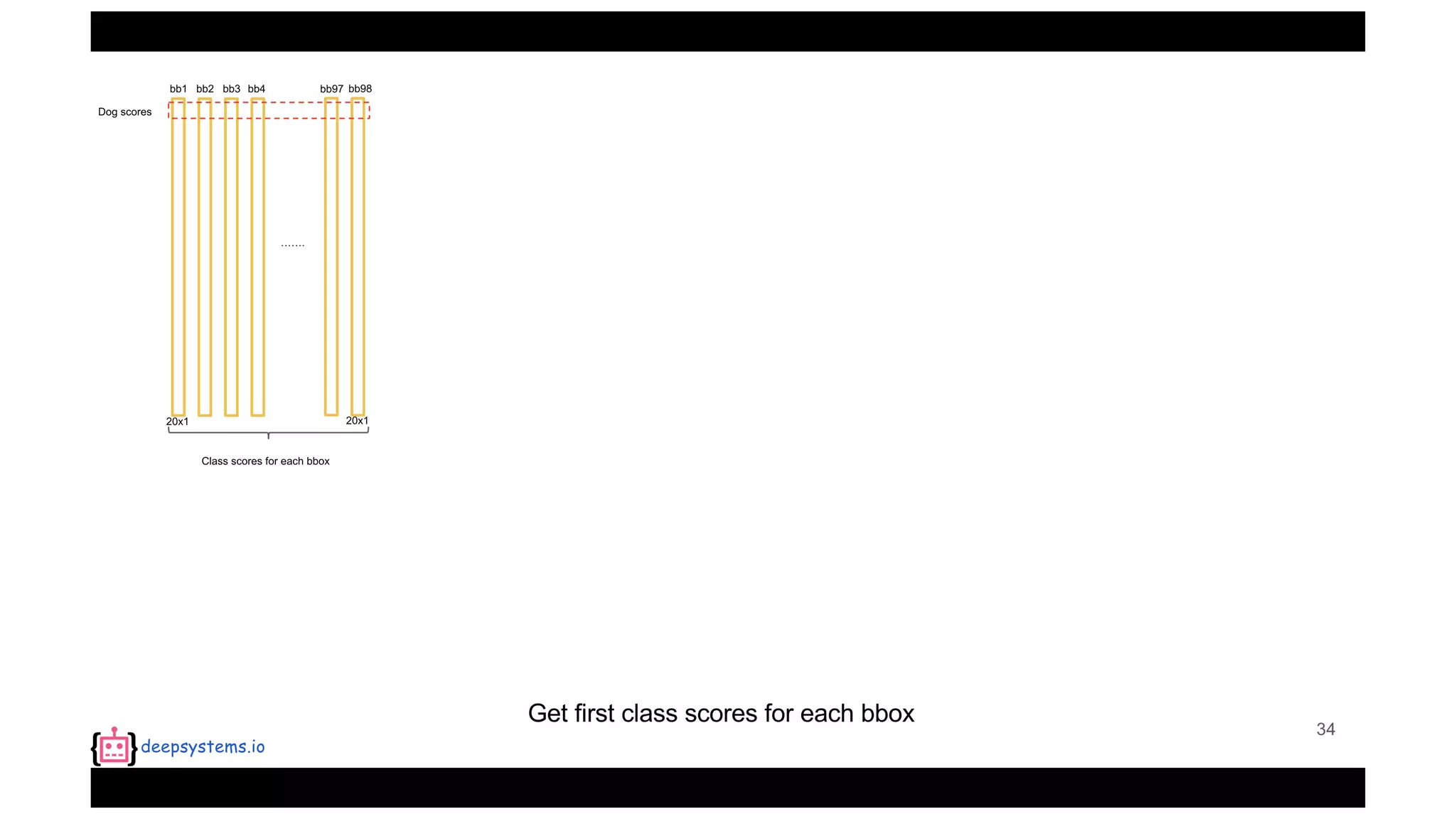
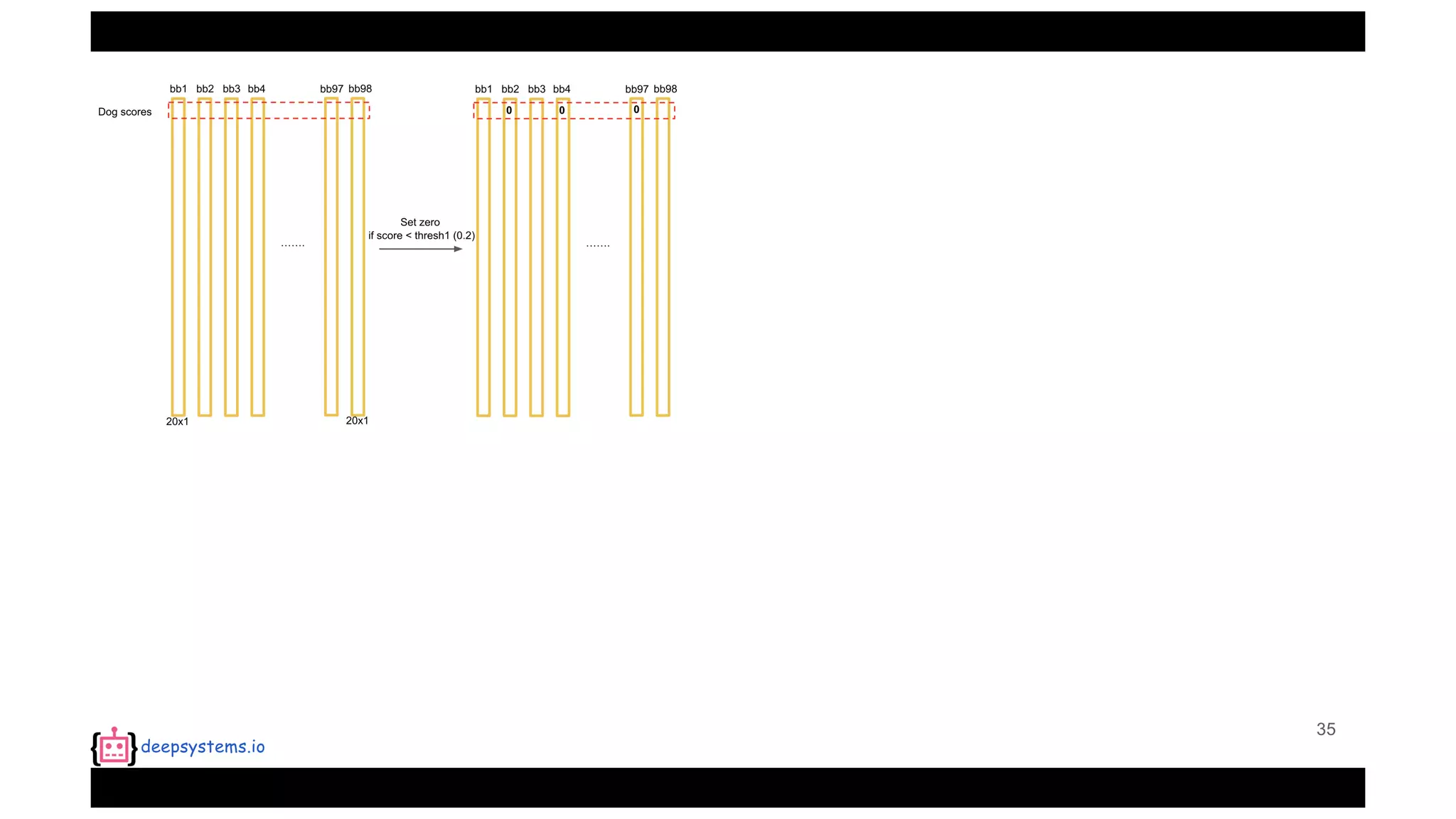
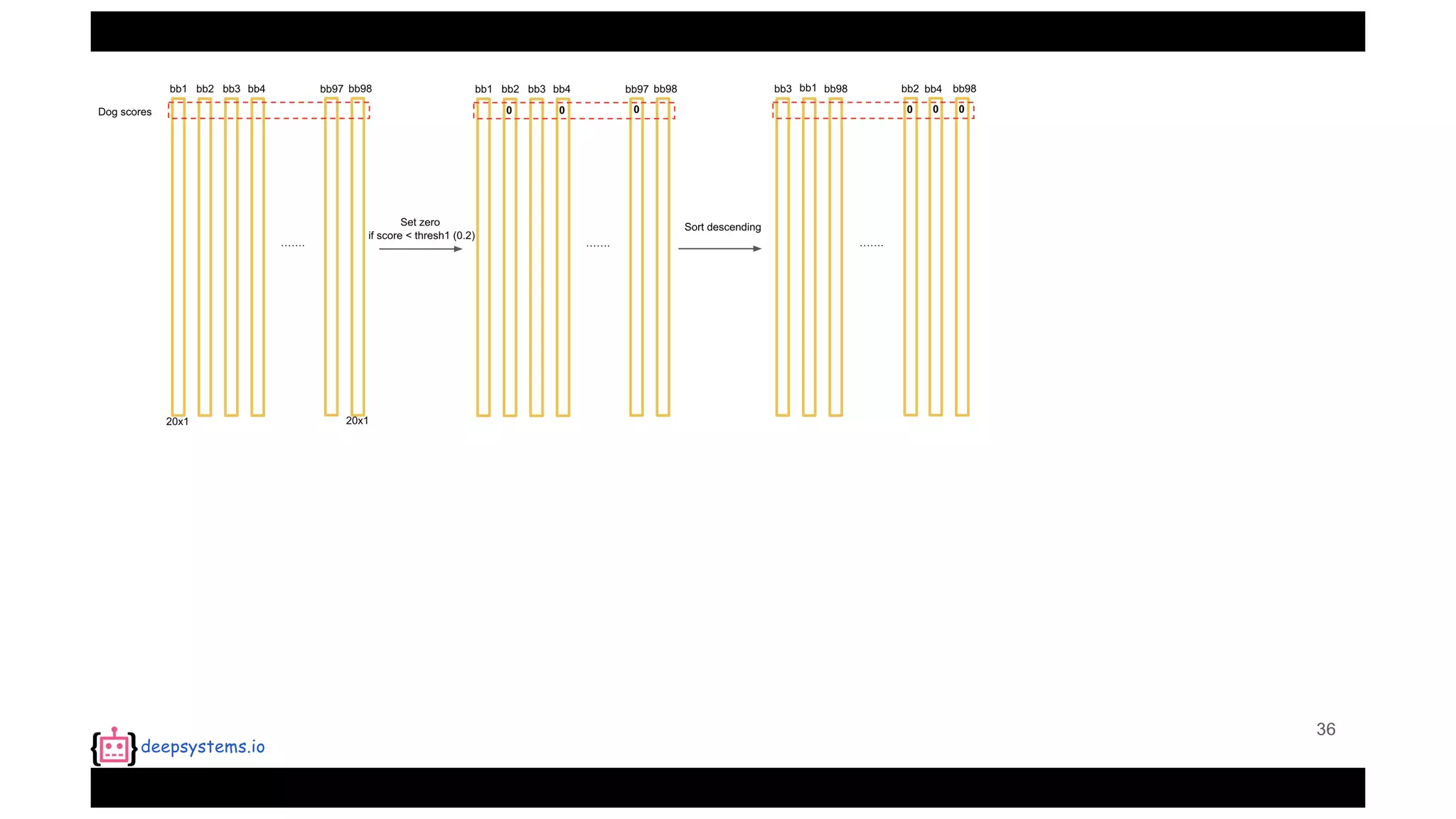
The document summarizes the You Only Look Once (YOLO) object detection method. YOLO frames object detection as a single regression problem to directly predict bounding boxes and class probabilities from full images in one pass. This allows for extremely fast detection speeds of 45 frames per second. YOLO uses a feedforward convolutional neural network to apply a single neural network to the full image. This allows it to leverage contextual information and makes predictions about bounding boxes and class probabilities for all classes with one network.







![Train strategy
epochs=135
batch_size=64
momentum_a = 0.9
decay=0.0005
lr=[10-3, 10-2, 10-3, 10-4]
dropout_rate=0.5
augmentation
=[scaling, translation, exposure, saturation]](https://image.slidesharecdn.com/yolo-170616085751/75/PR12-You-Only-Look-Once-YOLO-Unified-Real-Time-Object-Detection-19-2048.jpg)


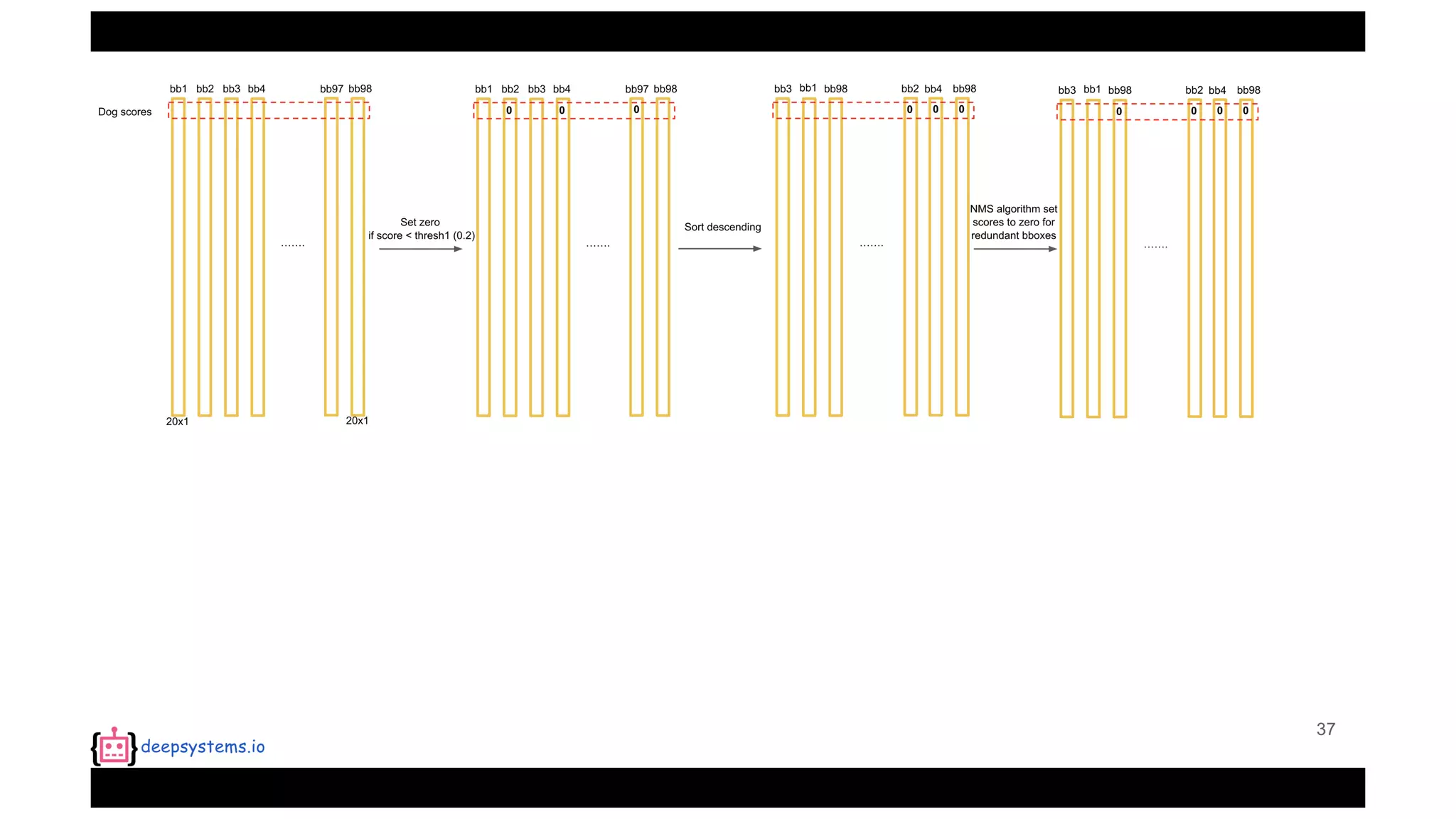
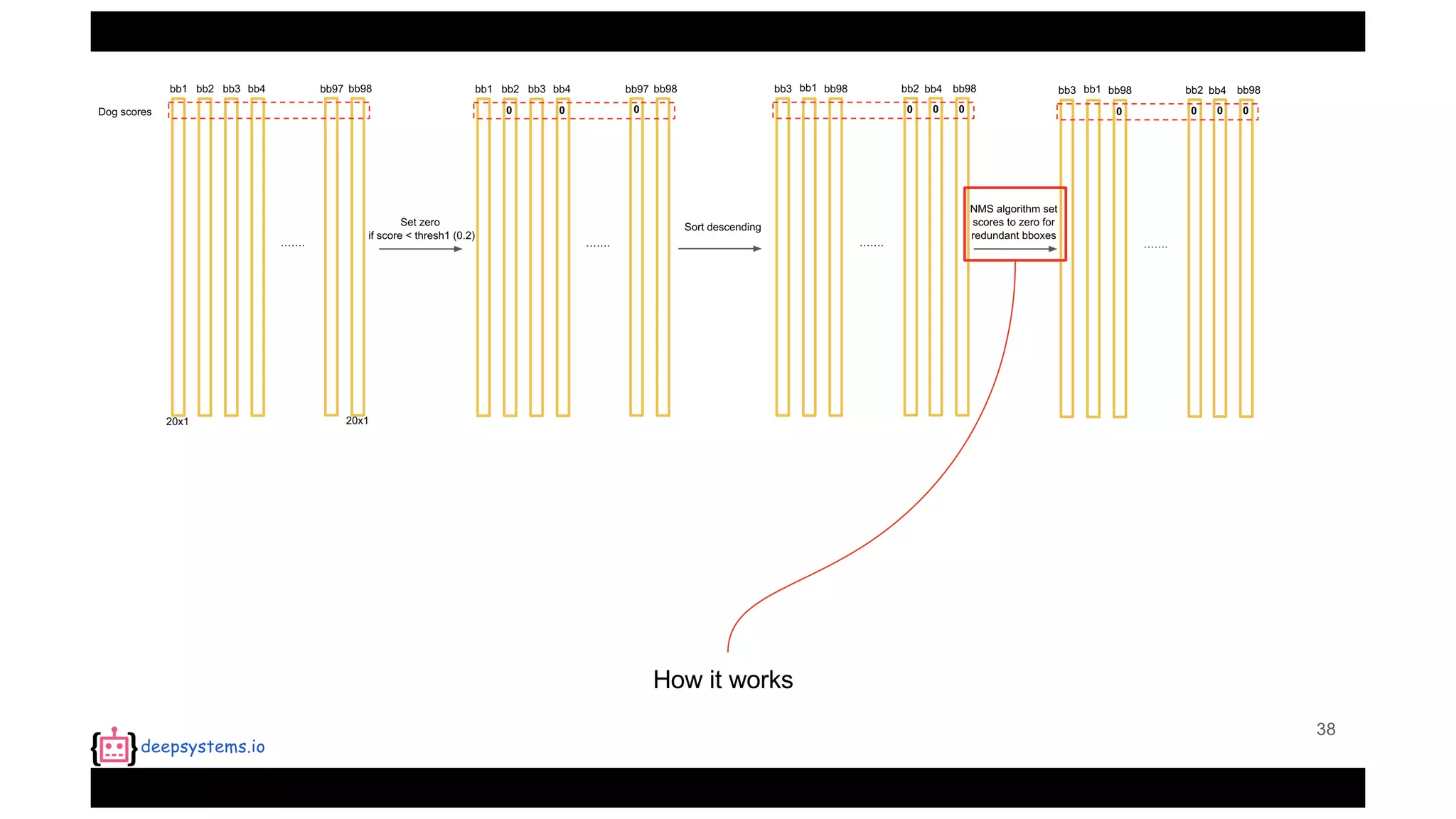


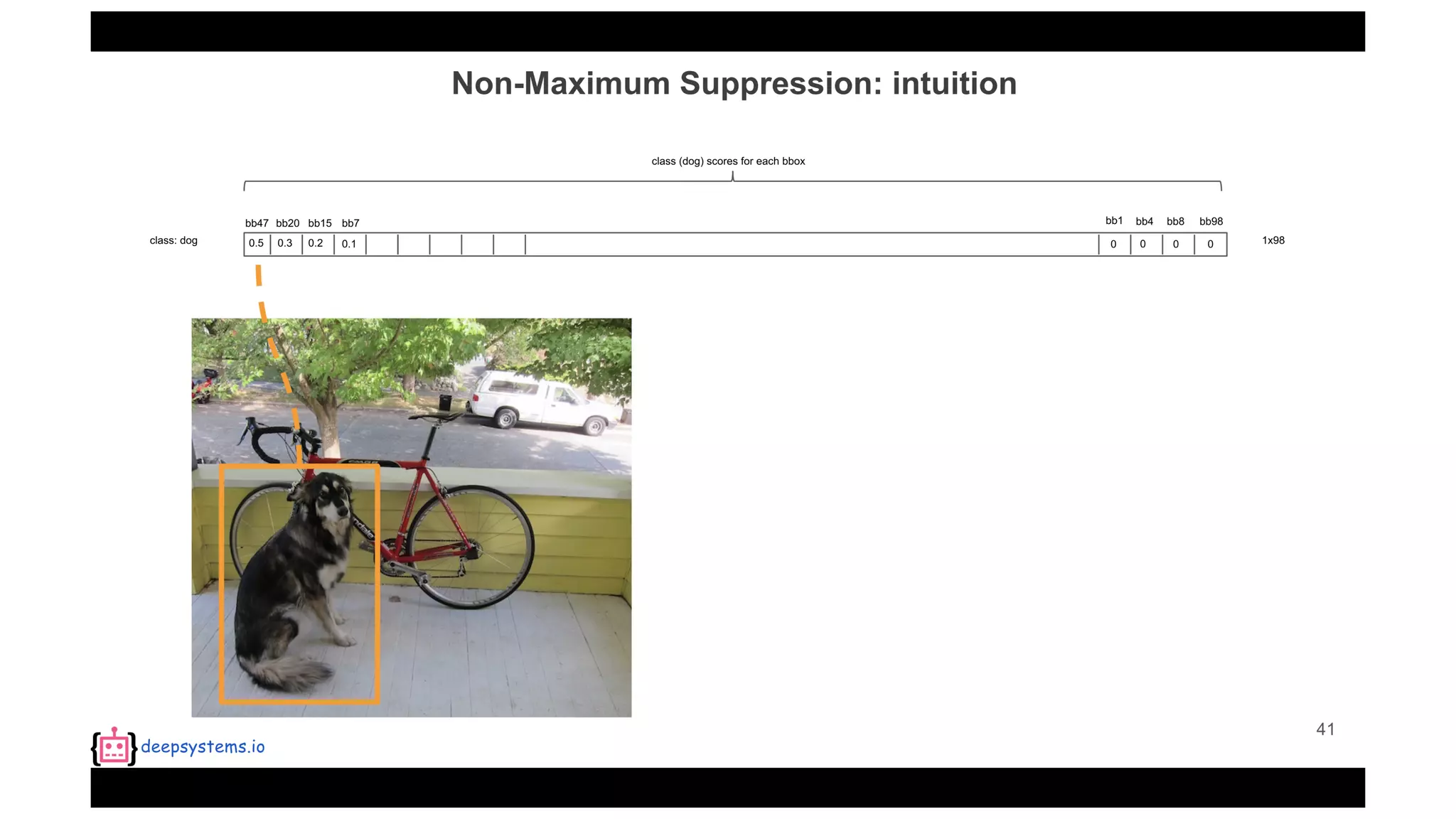
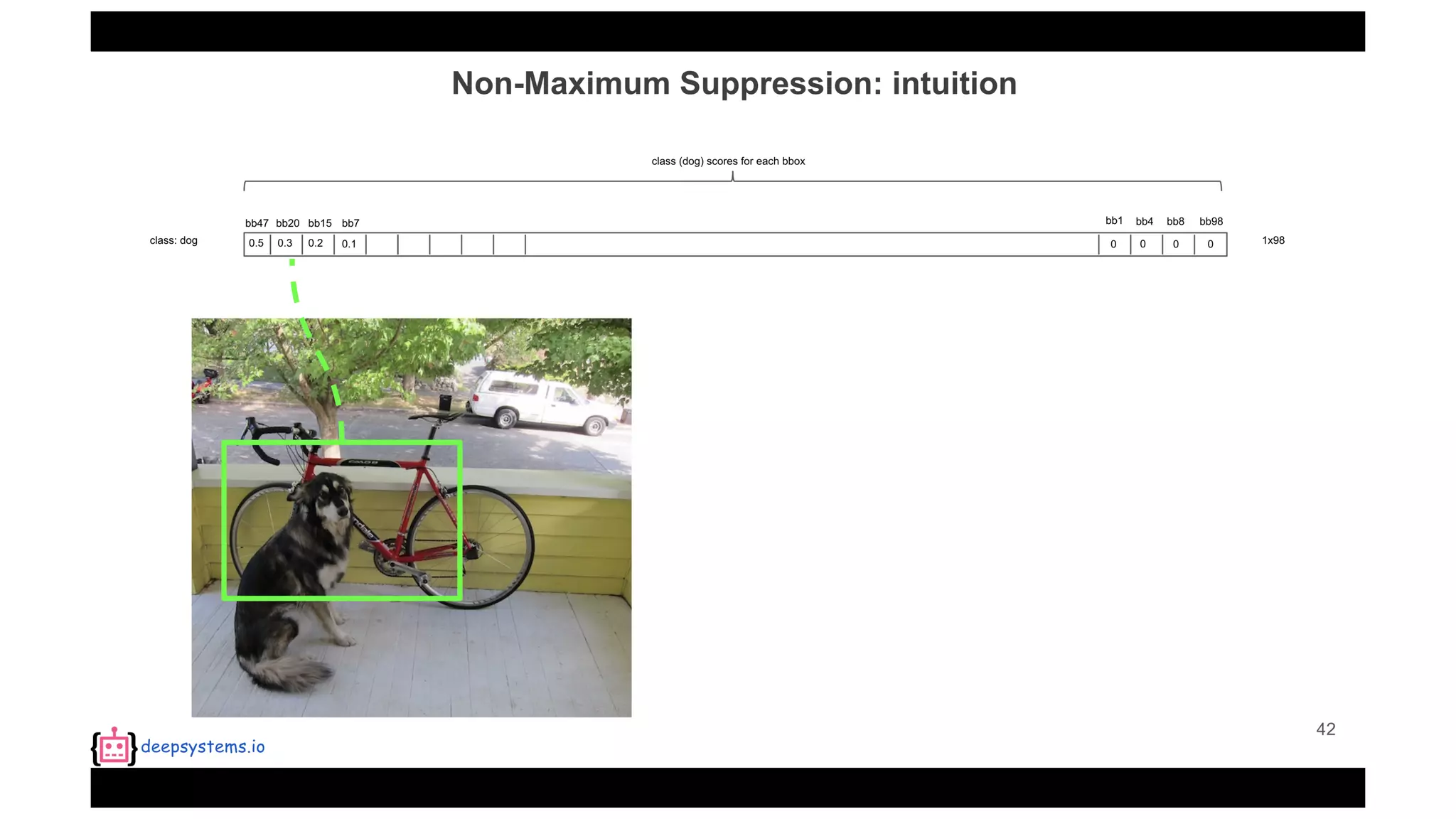

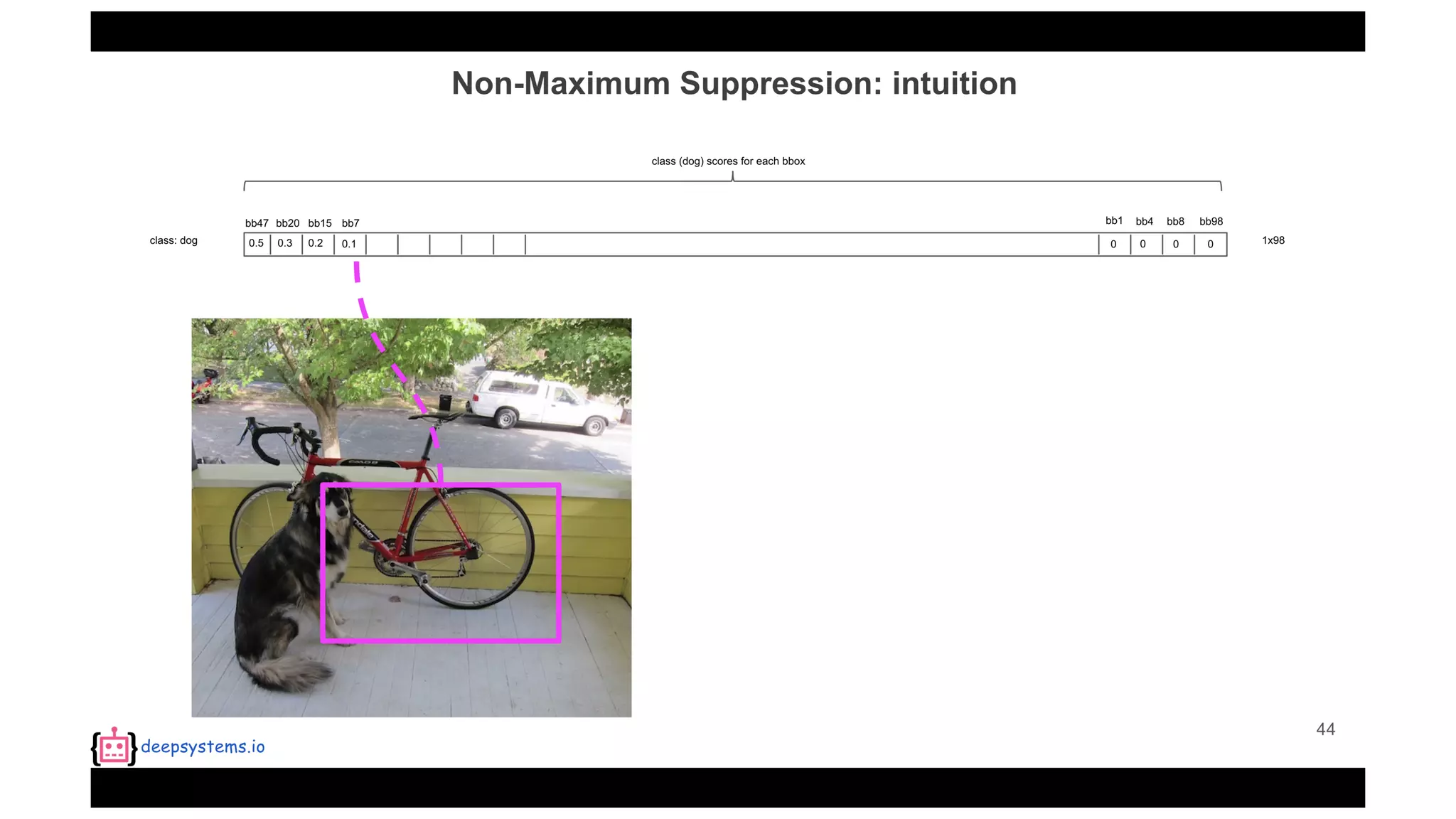

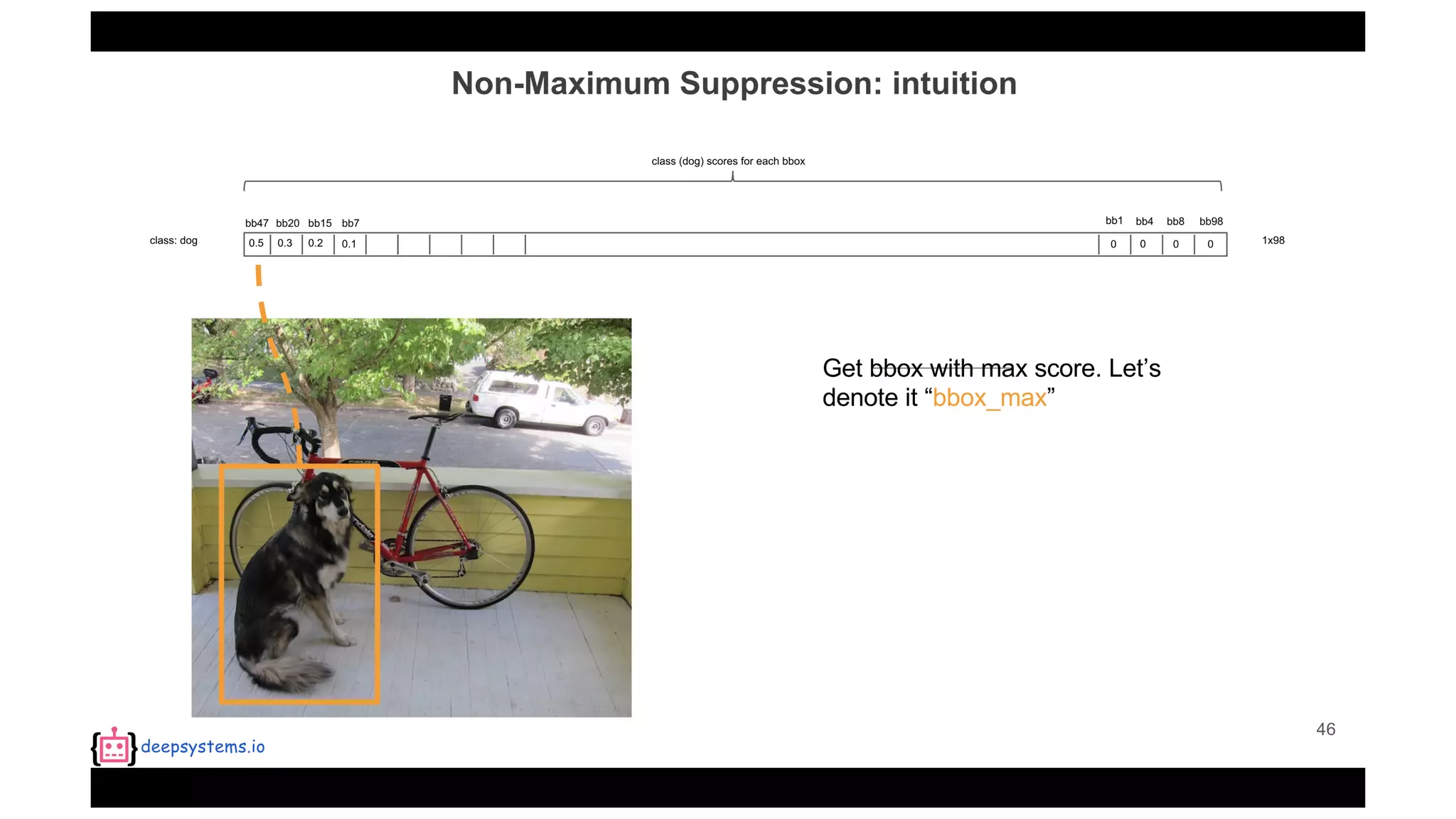



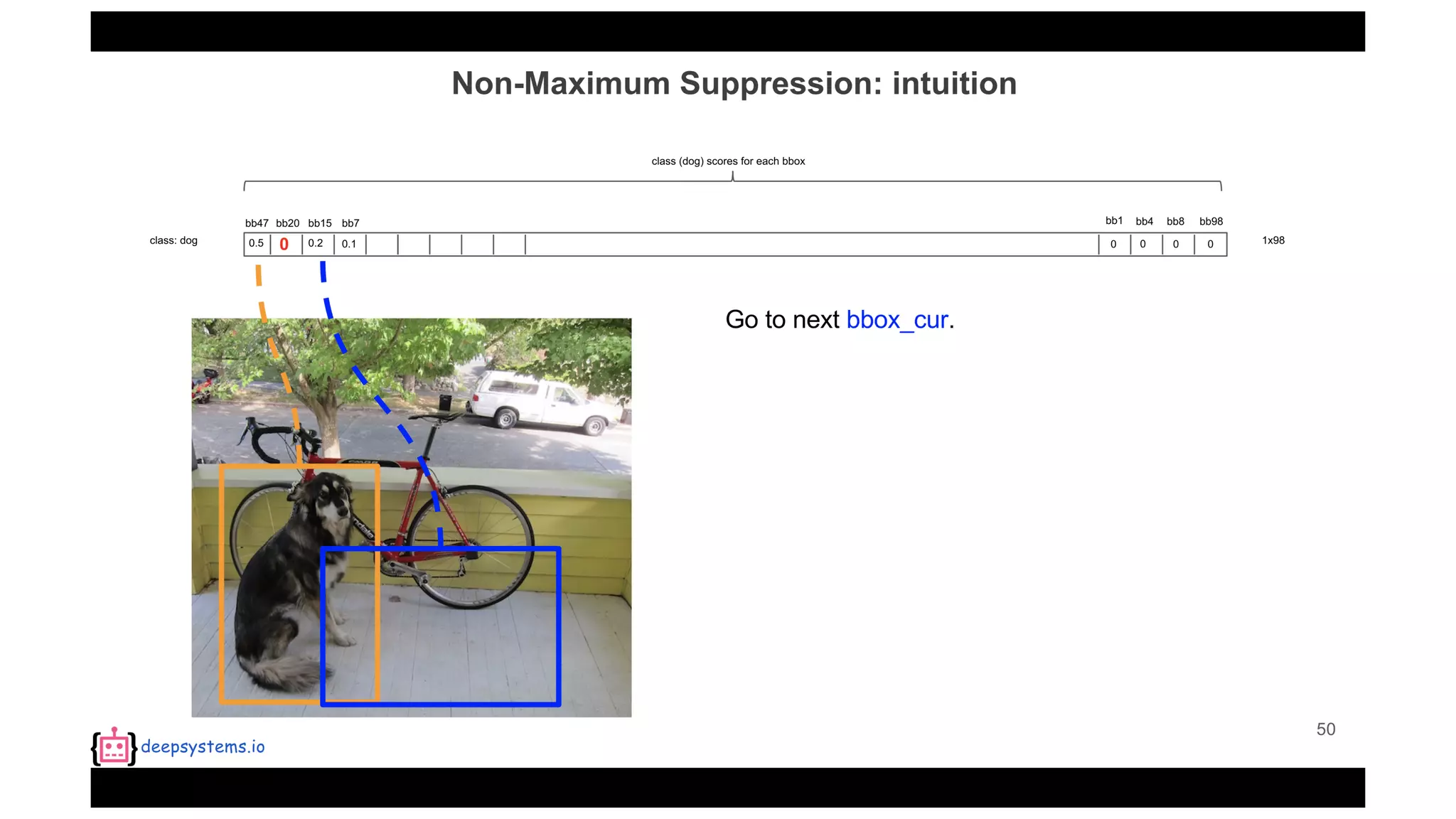

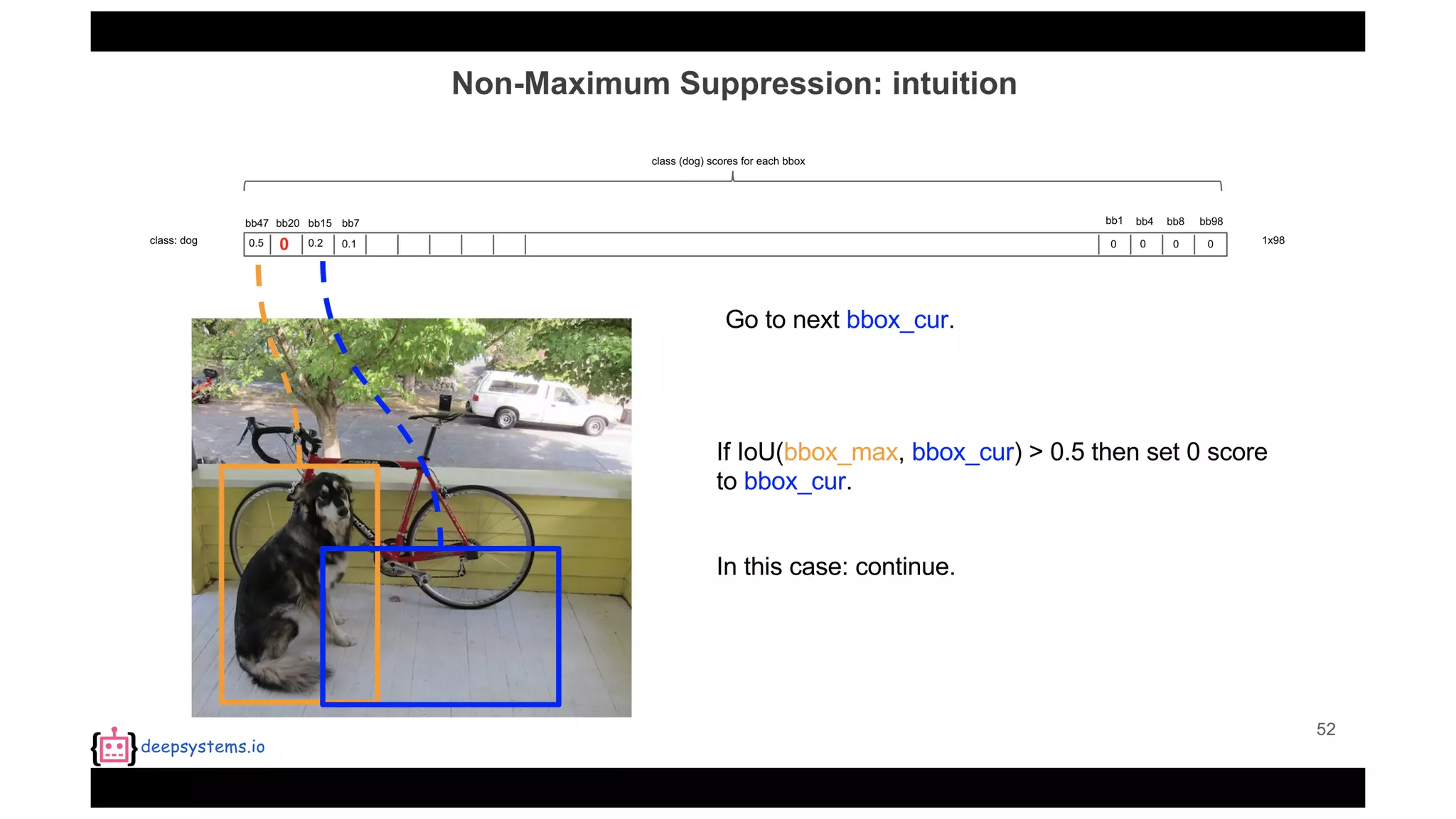
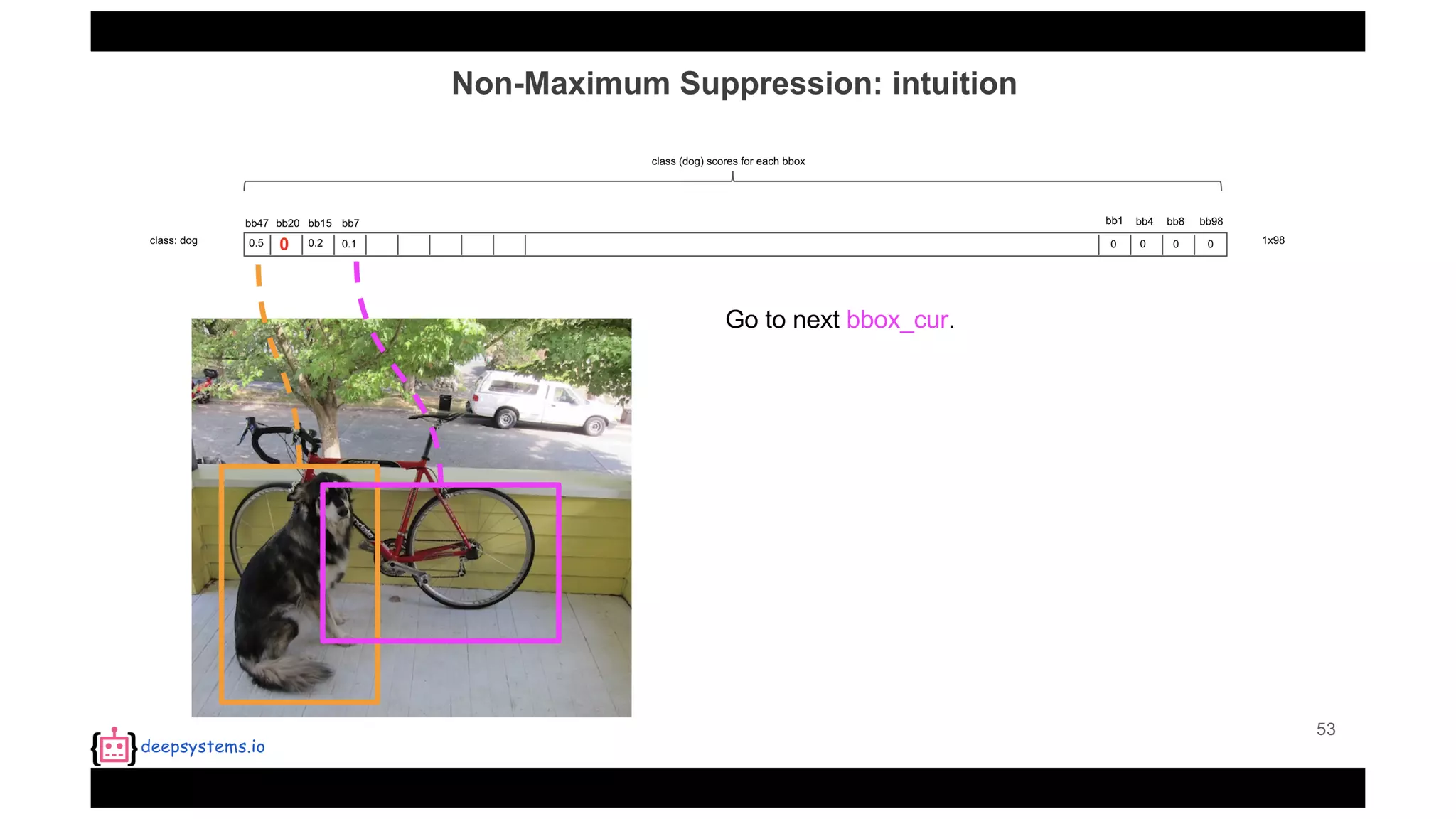




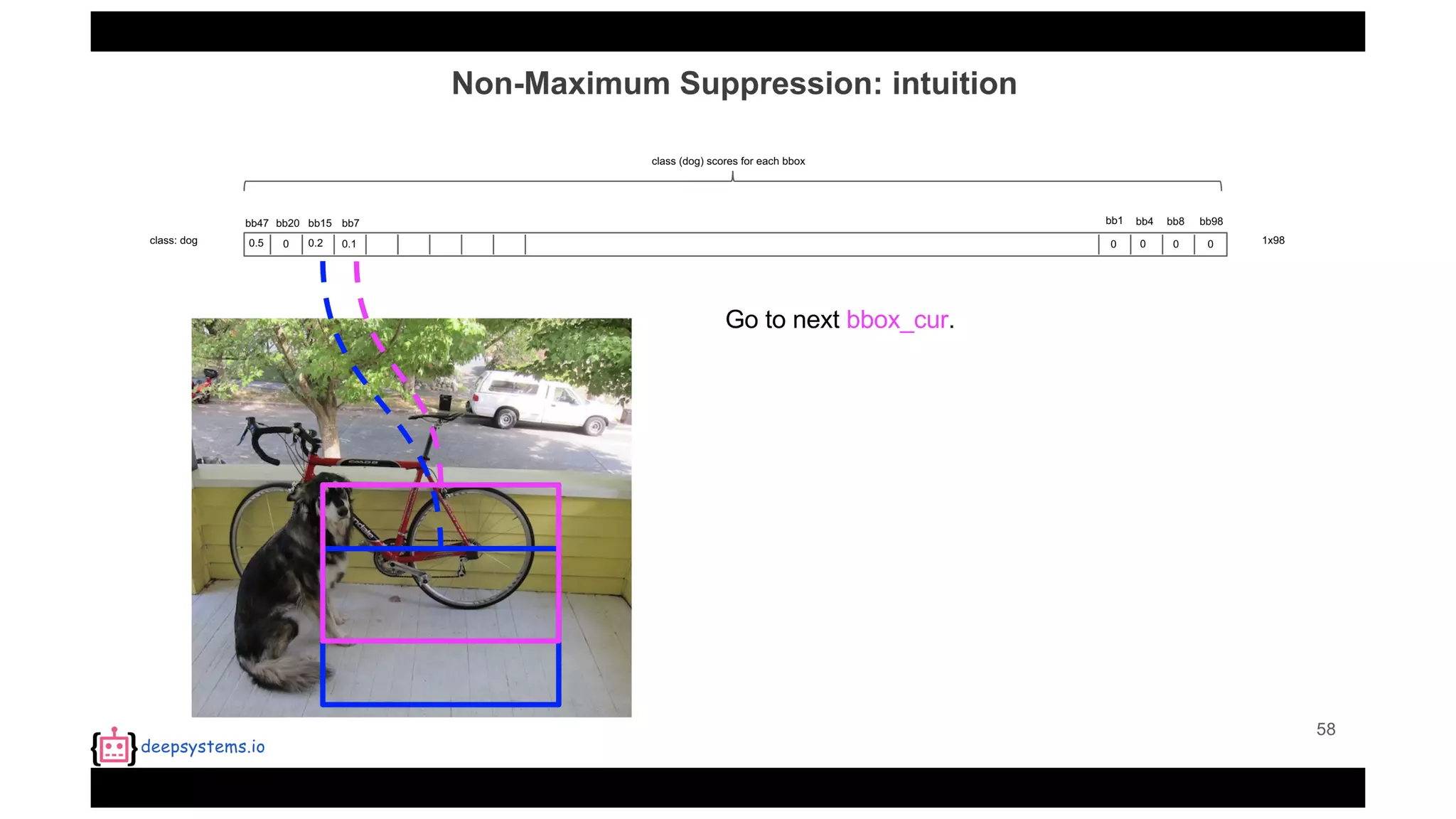



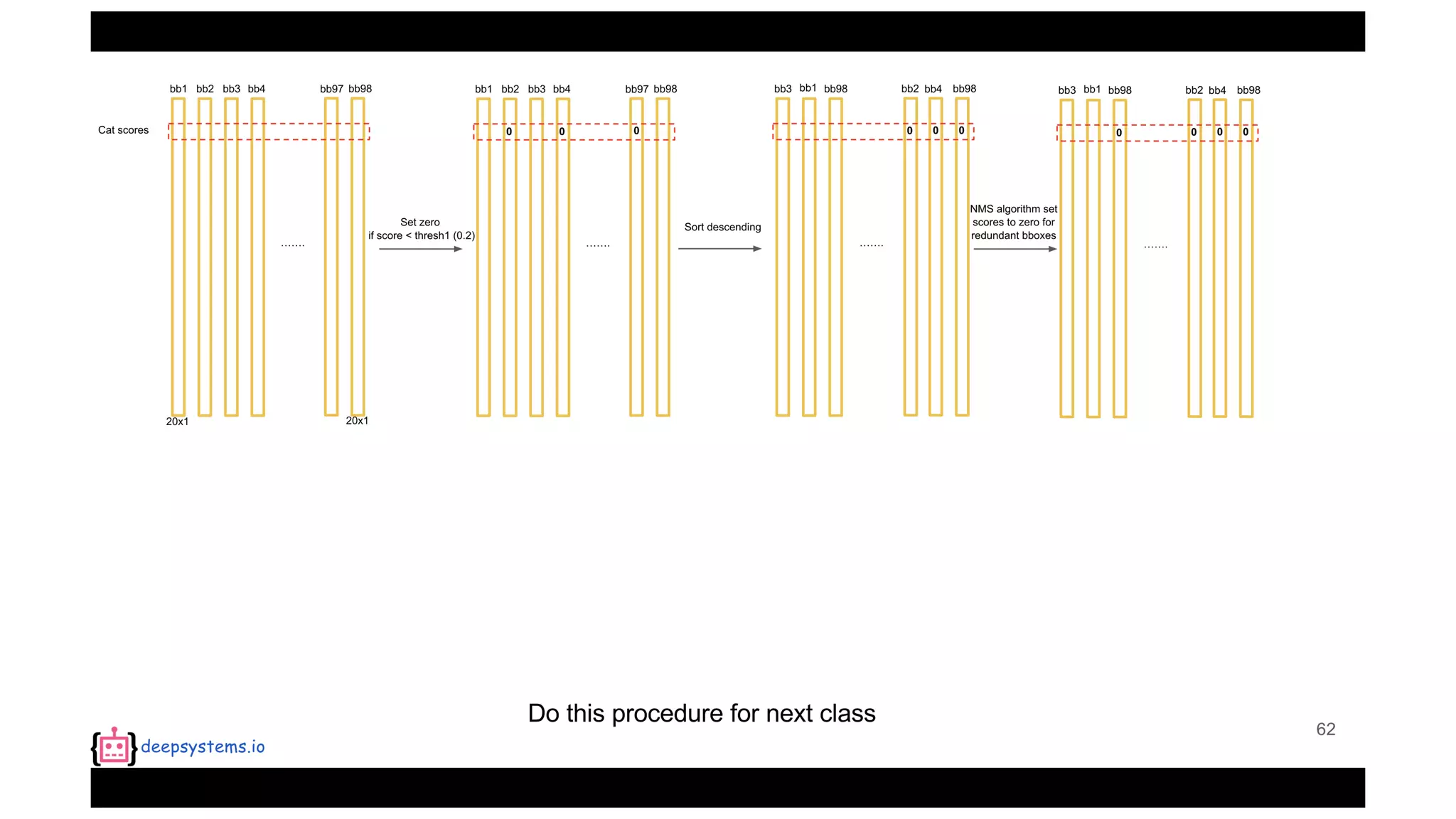
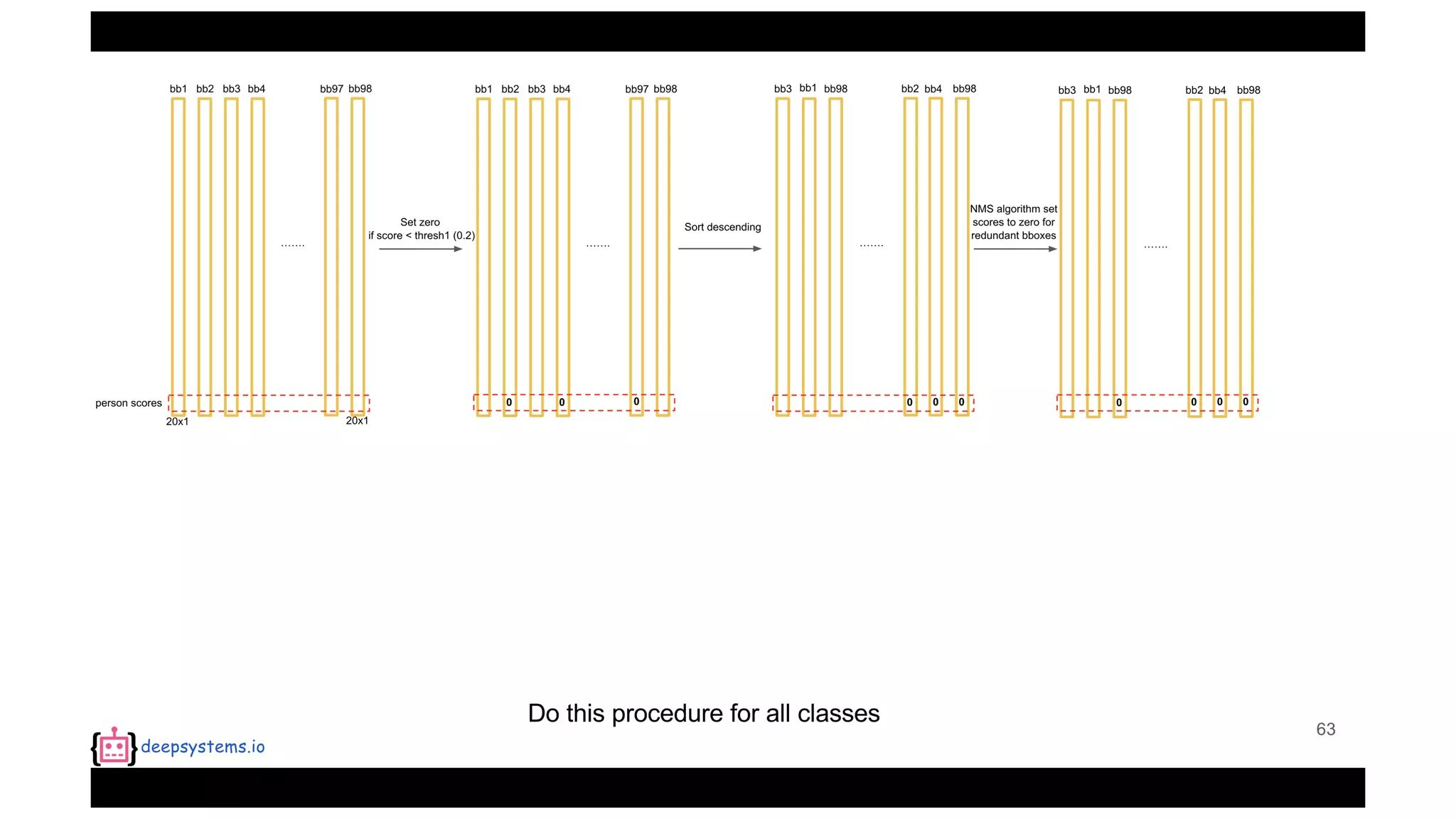
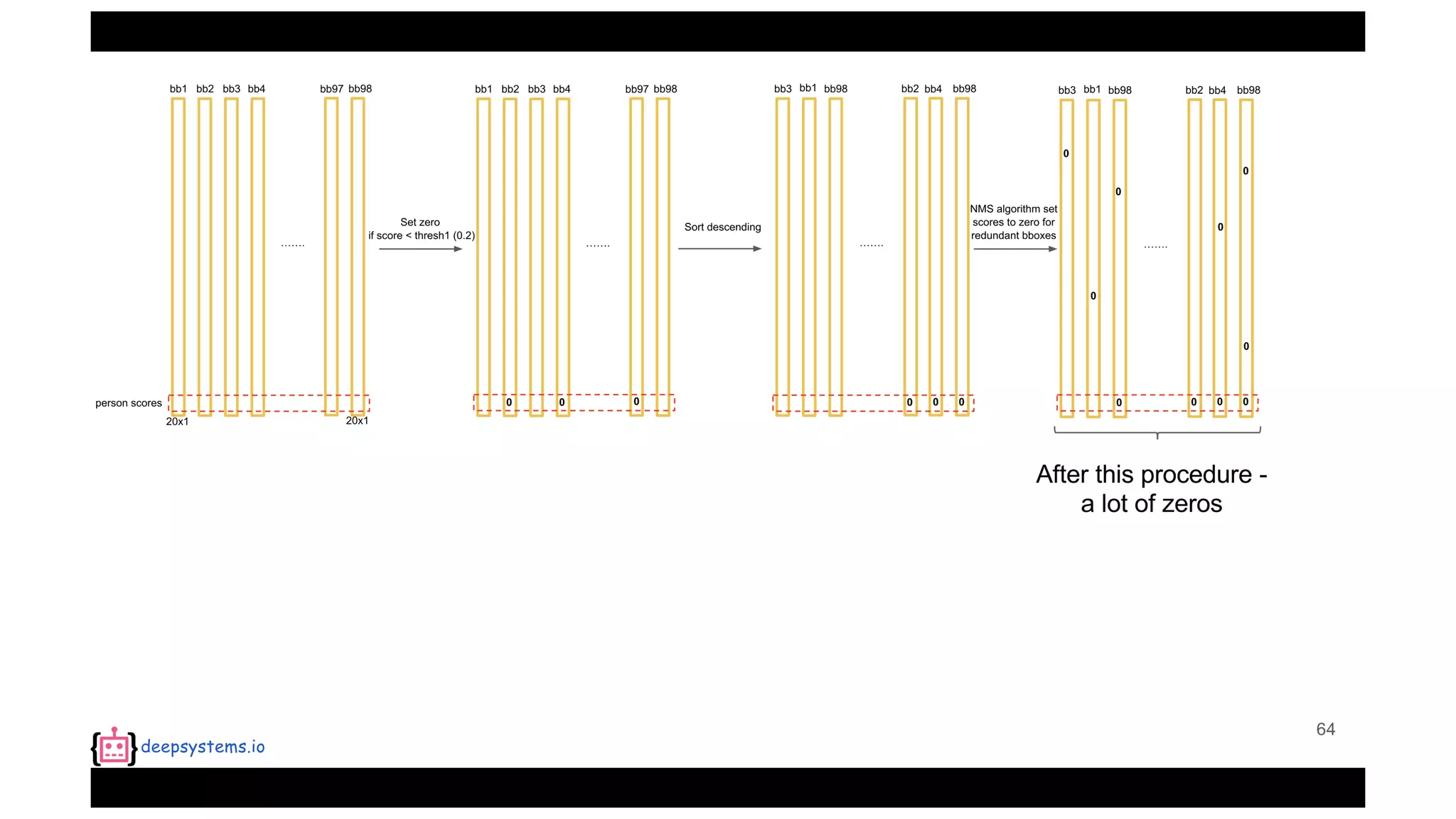
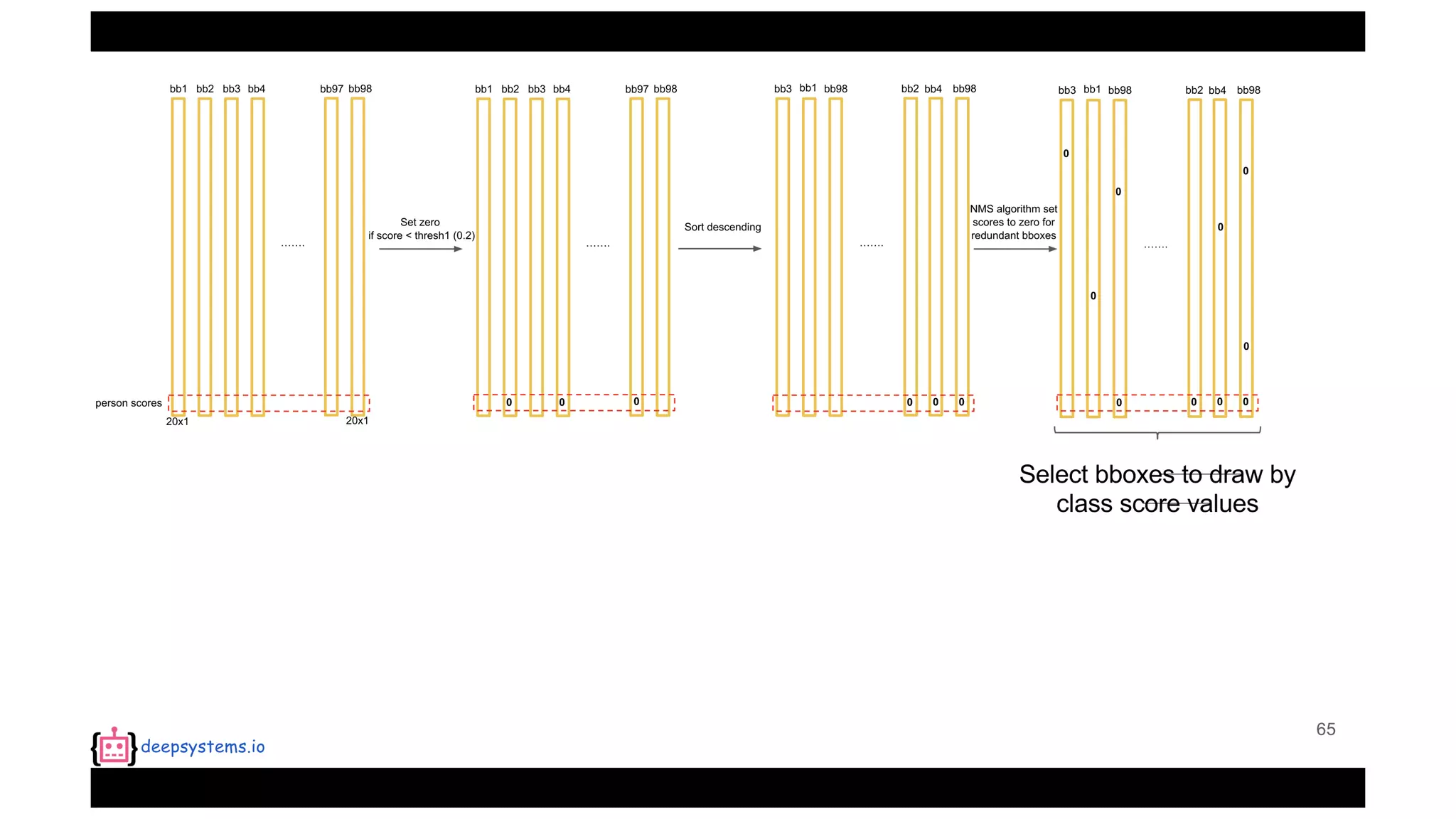
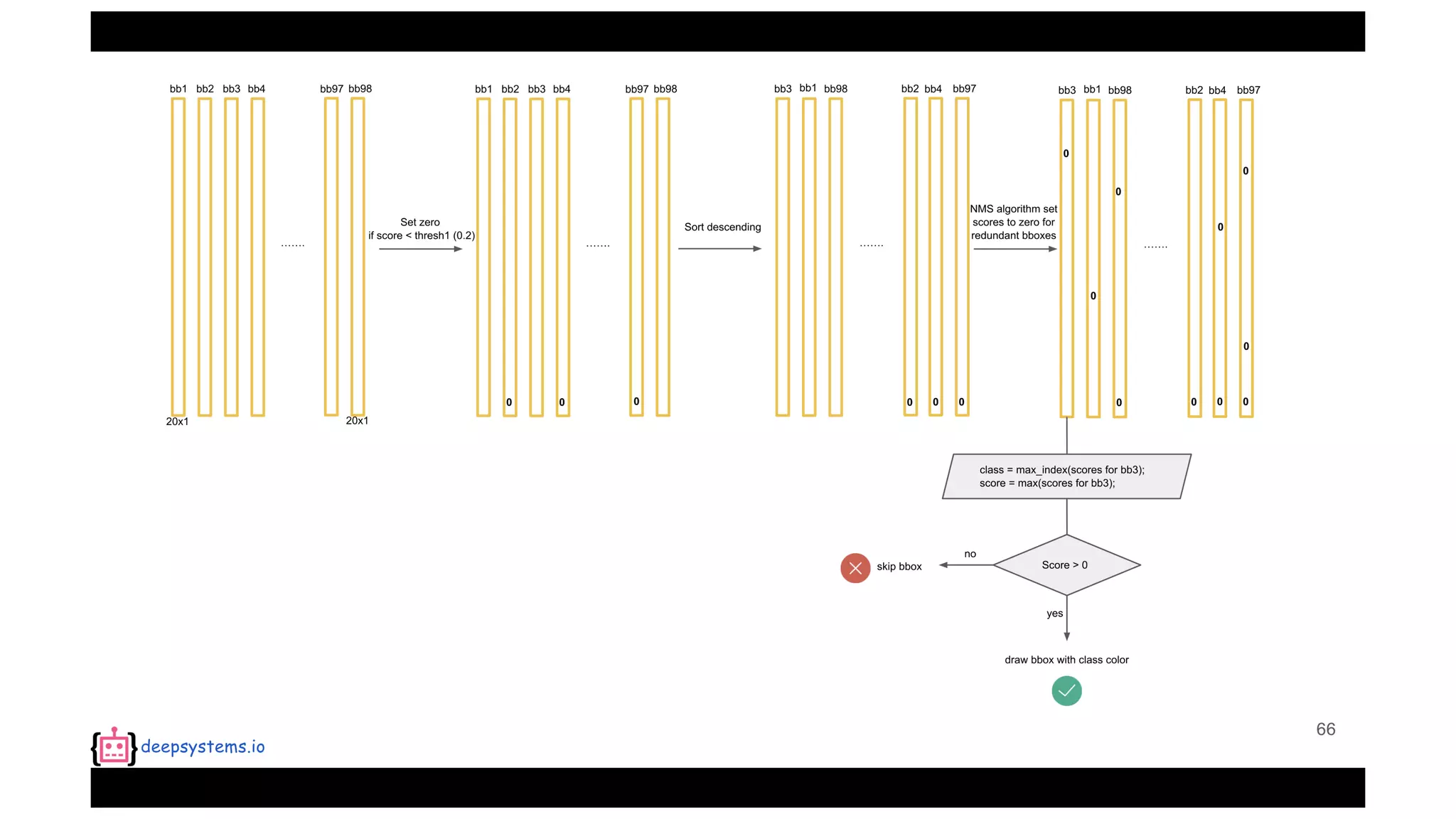
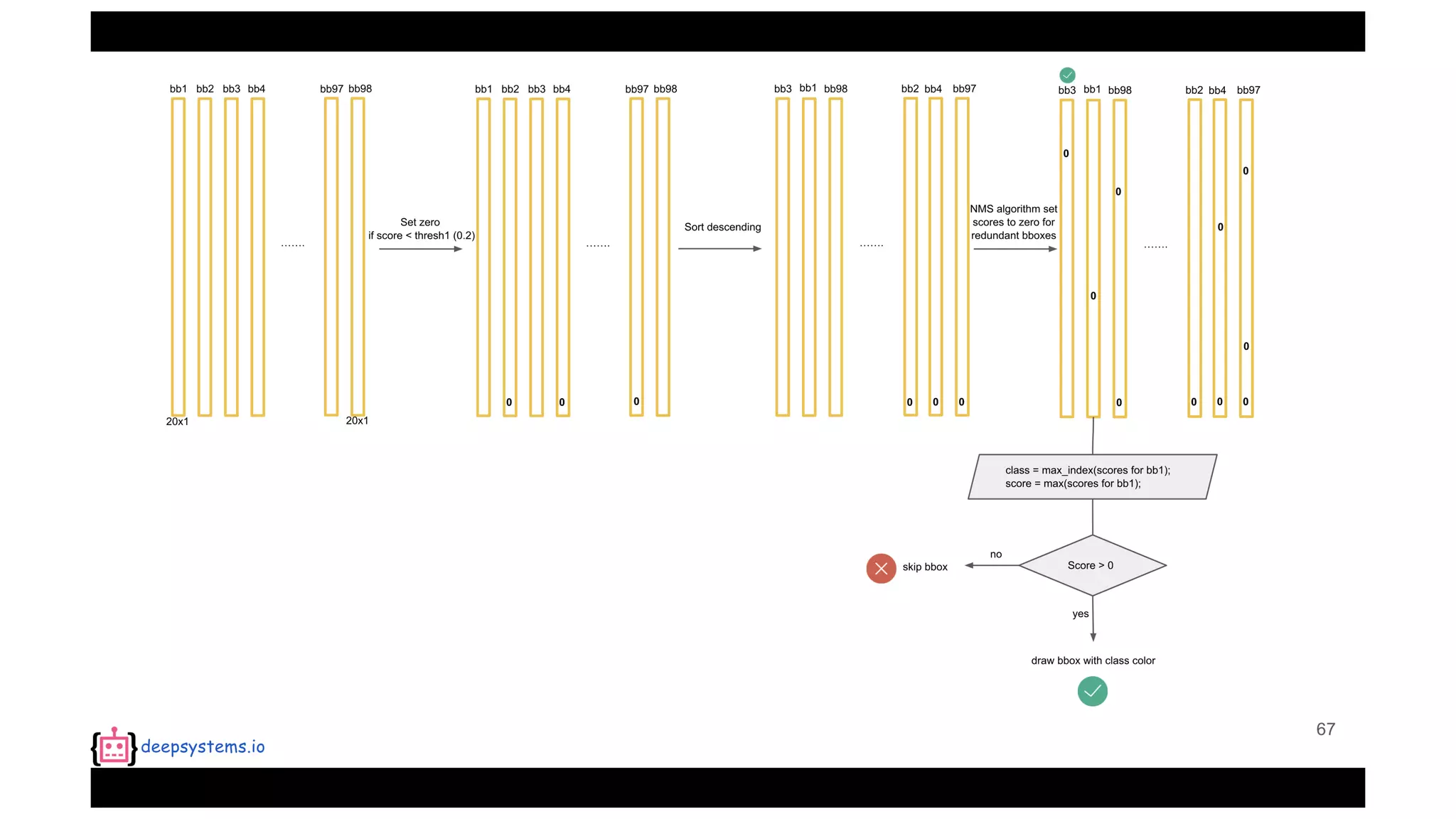








![Appendix | Intersection over Union (IoU)
• IoU(pred, truth)=[0, 1]](https://image.slidesharecdn.com/yolo-170616085751/75/PR12-You-Only-Look-Once-YOLO-Unified-Real-Time-Object-Detection-93-2048.jpg)
























![ViT (Vision Transformer) Review [CDM]](https://cdn.slidesharecdn.com/ss_thumbnails/vitreviewcdm-201012184226-thumbnail.jpg?width=640&height=640&fit=bounds)


























![[OSGeo-KR Tech Workshop] Deep Learning for Single Image Super-Resolution](https://cdn.slidesharecdn.com/ss_thumbnails/osgeo-krdeeplearningforsingleimagesuper-resolution-180223175347-thumbnail.jpg?width=640&height=640&fit=bounds)
![[PR12] PR-063: Peephole predicting network performance before training](https://cdn.slidesharecdn.com/ss_thumbnails/peepholepredictingnetworkperformance-180130162632-thumbnail.jpg?width=640&height=640&fit=bounds)

![[PR12] PR-050: Convolutional LSTM Network: A Machine Learning Approach for Pr...](https://cdn.slidesharecdn.com/ss_thumbnails/pr12-convlstm-171126135417-thumbnail.jpg?width=640&height=640&fit=bounds)

![[PR12] PR-036 Learning to Remember Rare Events](https://cdn.slidesharecdn.com/ss_thumbnails/pr12pr-036learningtoremeberrareevents-170917140144-thumbnail.jpg?width=640&height=640&fit=bounds)
![[대전AI포럼] 위성영상 분석 기술 개발 현황 소개](https://cdn.slidesharecdn.com/ss_thumbnails/08-170822064935-thumbnail.jpg?width=640&height=640&fit=bounds)
![[PR12] PR-026: Notes for CVPR Machine Learning Sessions](https://cdn.slidesharecdn.com/ss_thumbnails/pr-026notesforcvprmachinelearningsessions-170731034245-thumbnail.jpg?width=640&height=640&fit=bounds)
![[PR12] image super resolution using deep convolutional networks](https://cdn.slidesharecdn.com/ss_thumbnails/pr12imagesuper-resolutionusingdeepconvolutionalnetworks-170424004350-thumbnail.jpg?width=640&height=640&fit=bounds)























