2023年4月30日「第58回 コンピュータビジョン勉強会@関東」での発表資料です。"VoxFormer: Sparse Voxel Transformer for Camera-based 3D Semantic Scene Completion"の紹介です。


![© GO Inc.
論文情報
● arXiv初出は2023年2月23日
● CVPR 2023 Highlights(採択論文の10%)
● 著者の所属は多いが、NVIDIAメインの研究と思われる(GitHubリポジトリもNVlabs)
[paper] [code]
3](https://image.slidesharecdn.com/20230430cvvoxformer-230430040121-1232bfb5/75/VoxFormer-Sparse-Voxel-Transformer-for-Camera-based-3D-Semantic-Scene-Completion-3-2048.jpg)
![© GO Inc.
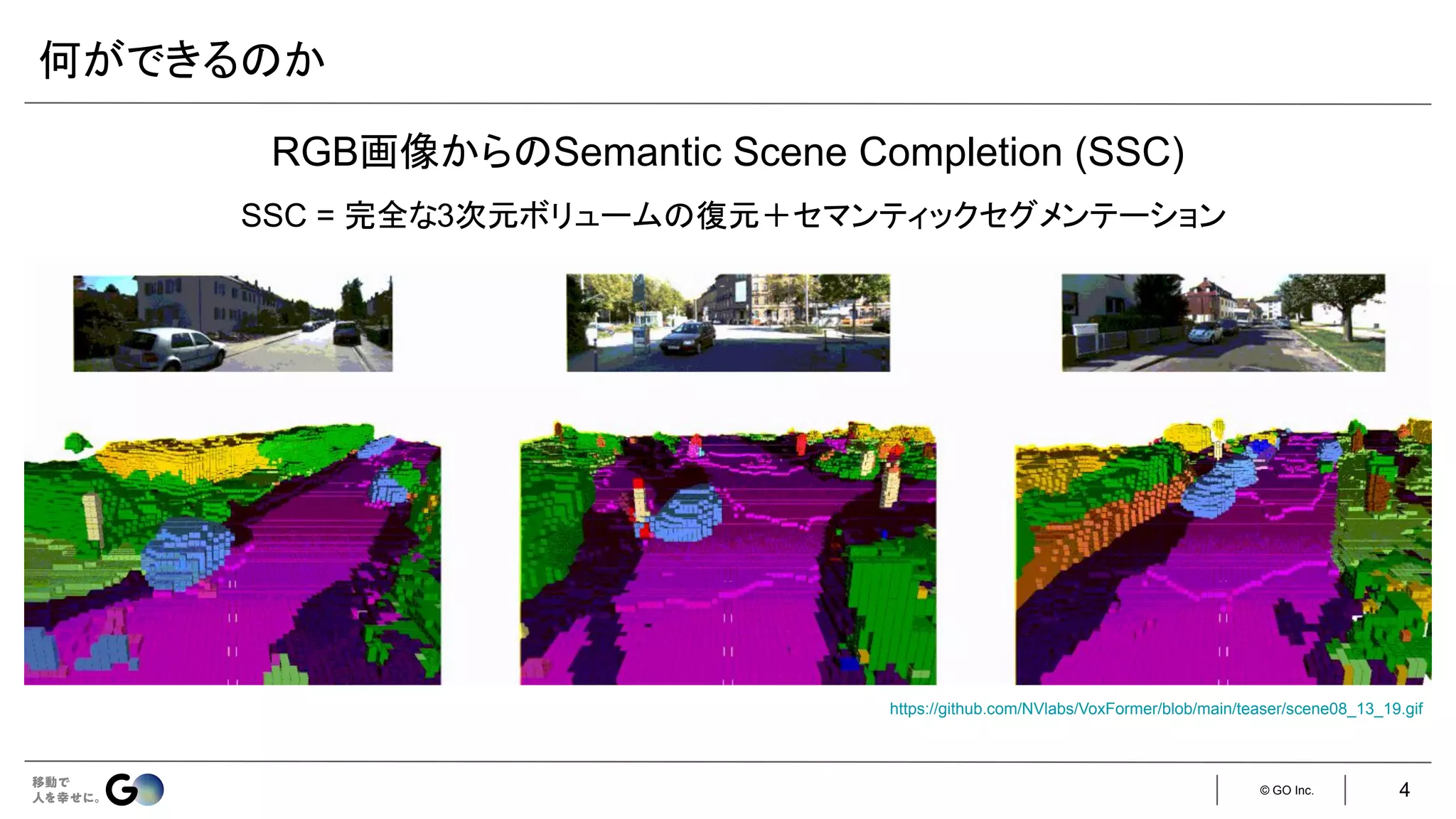
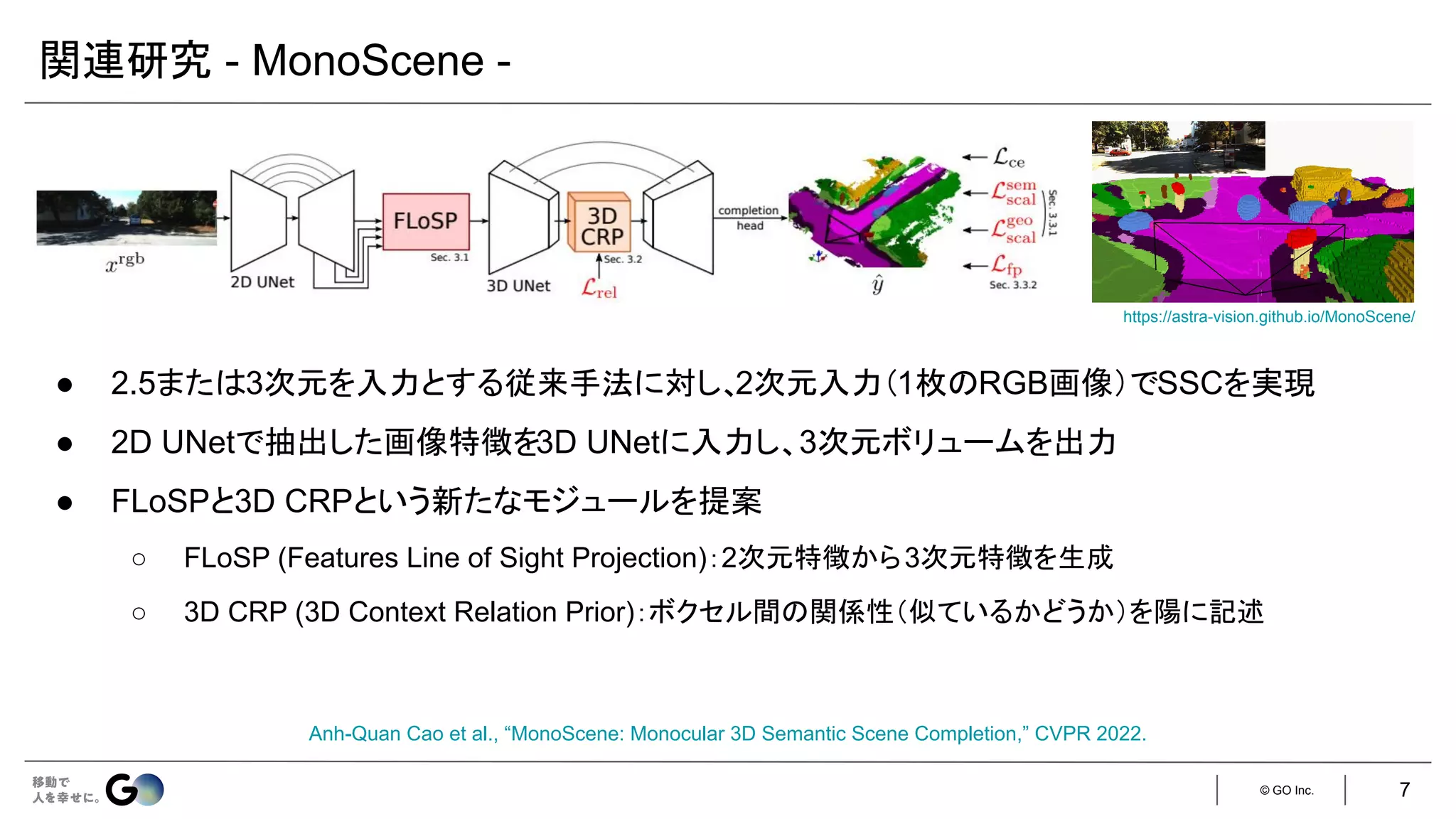
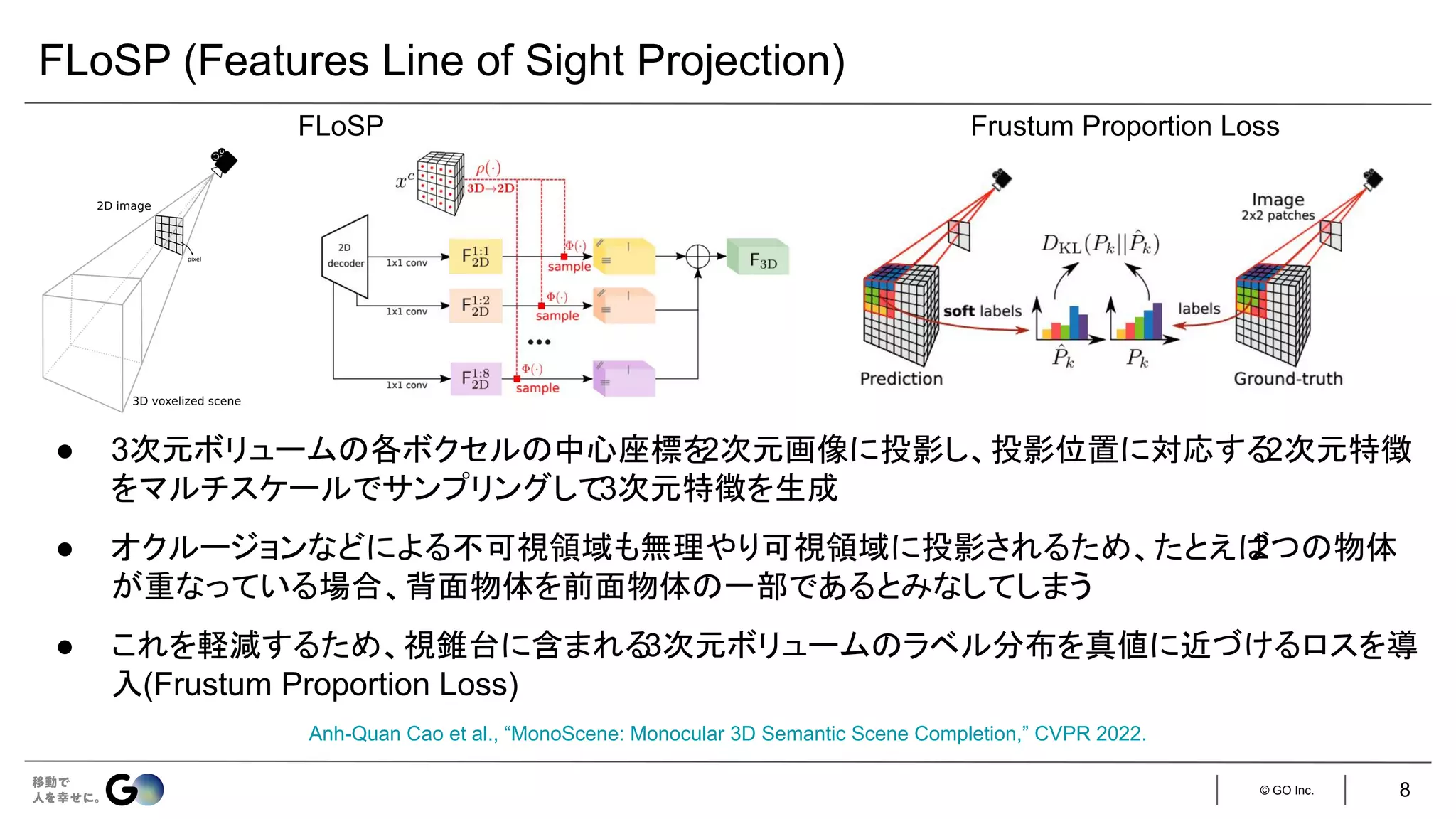
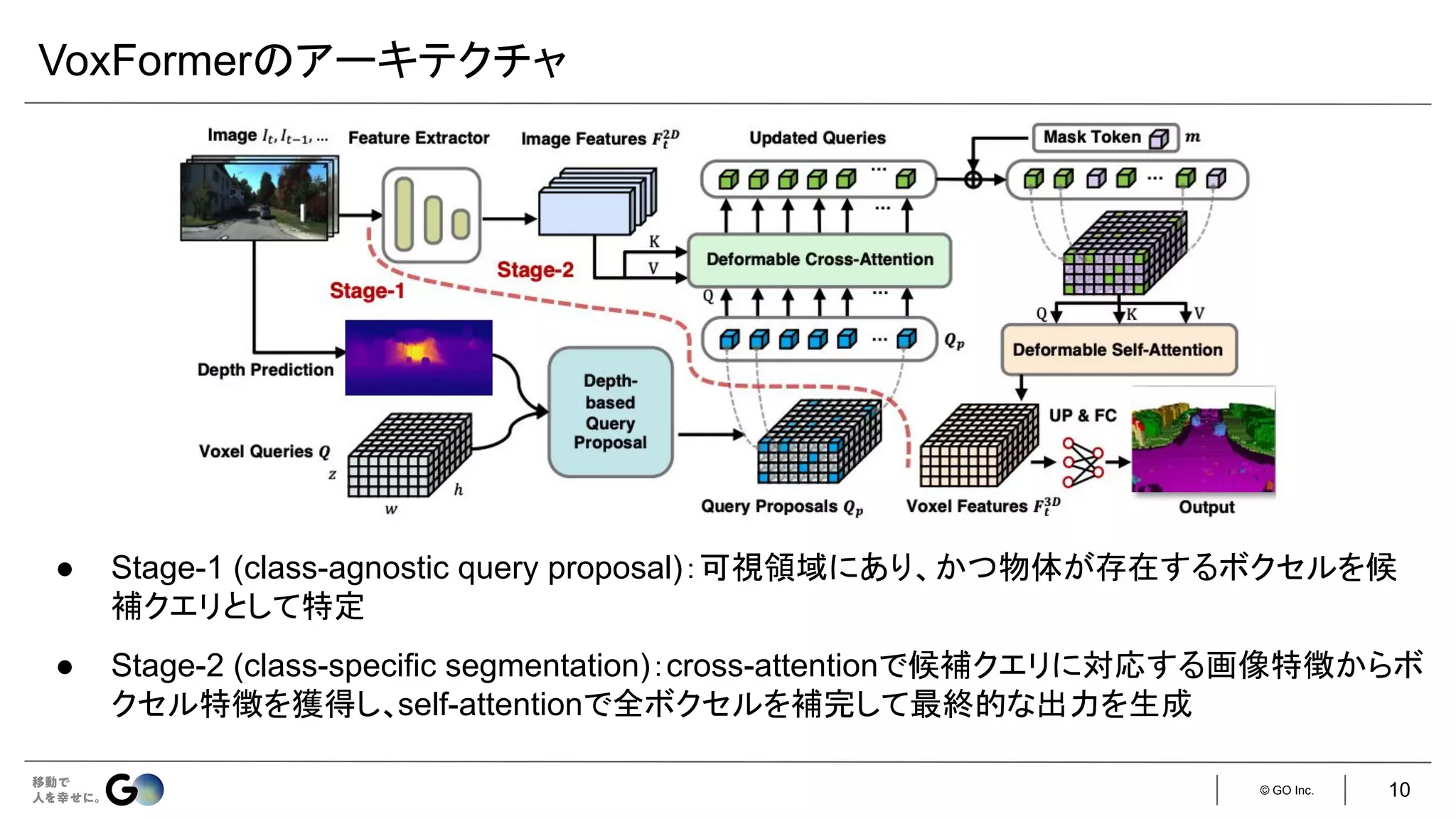
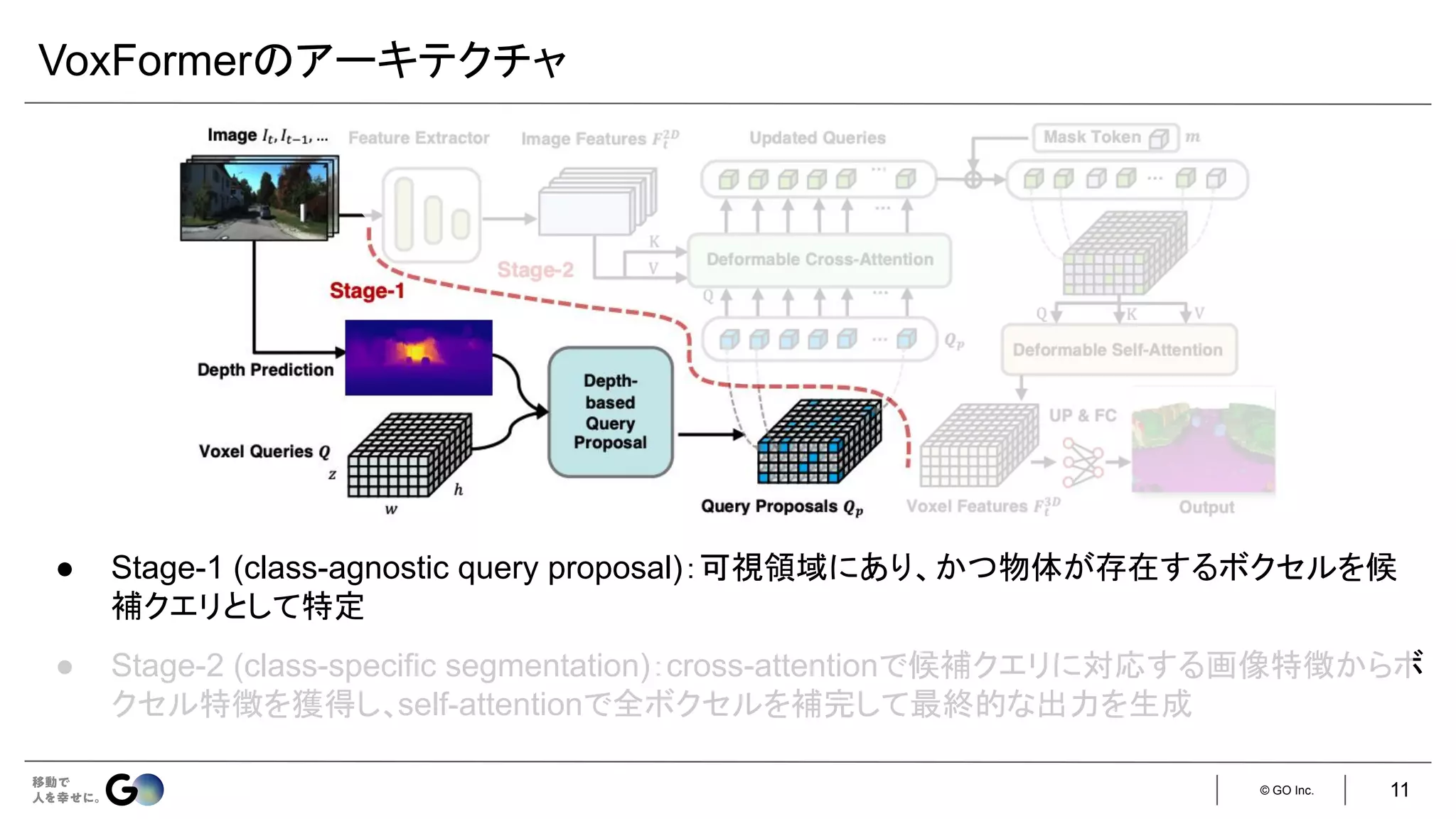
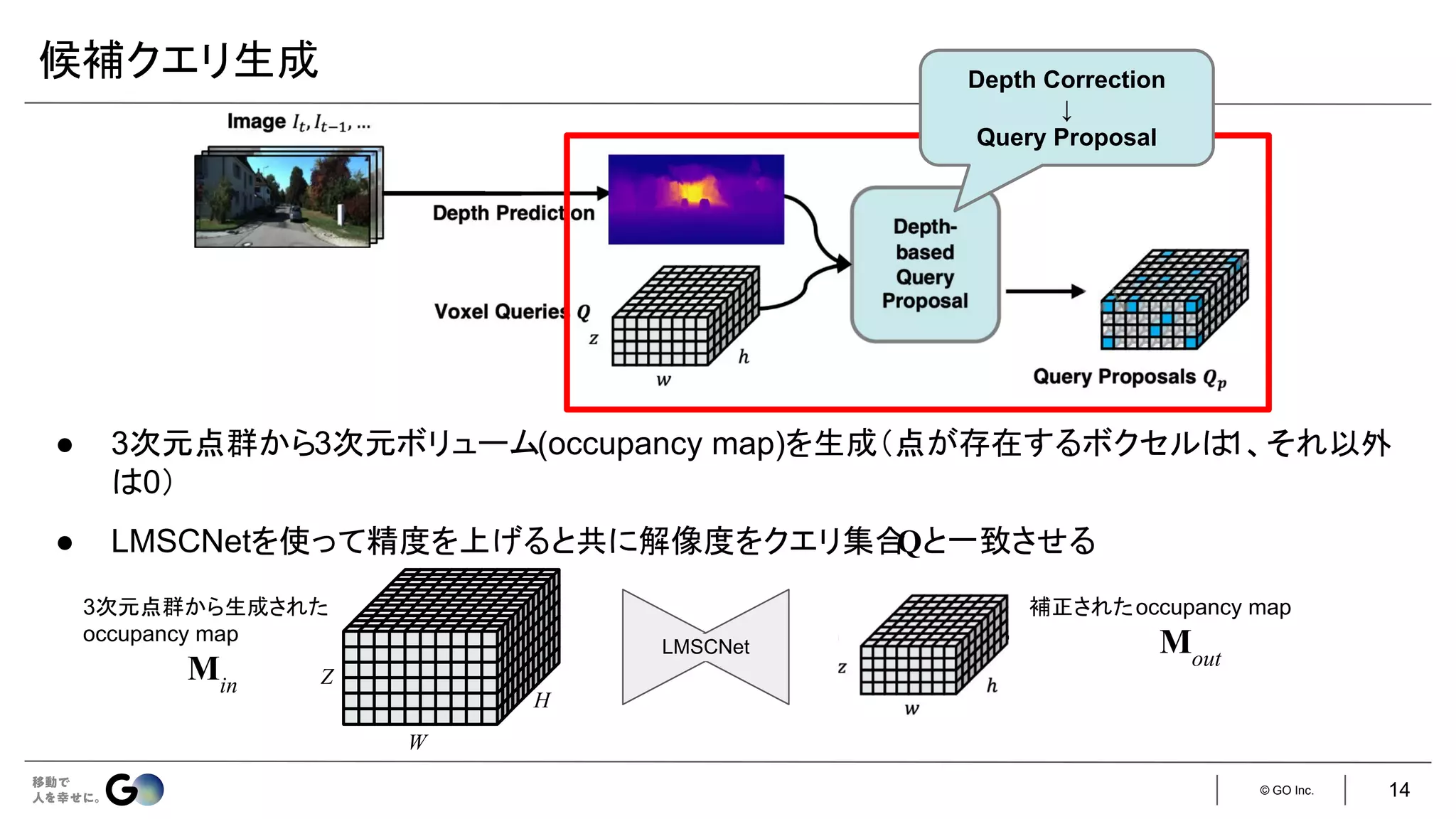
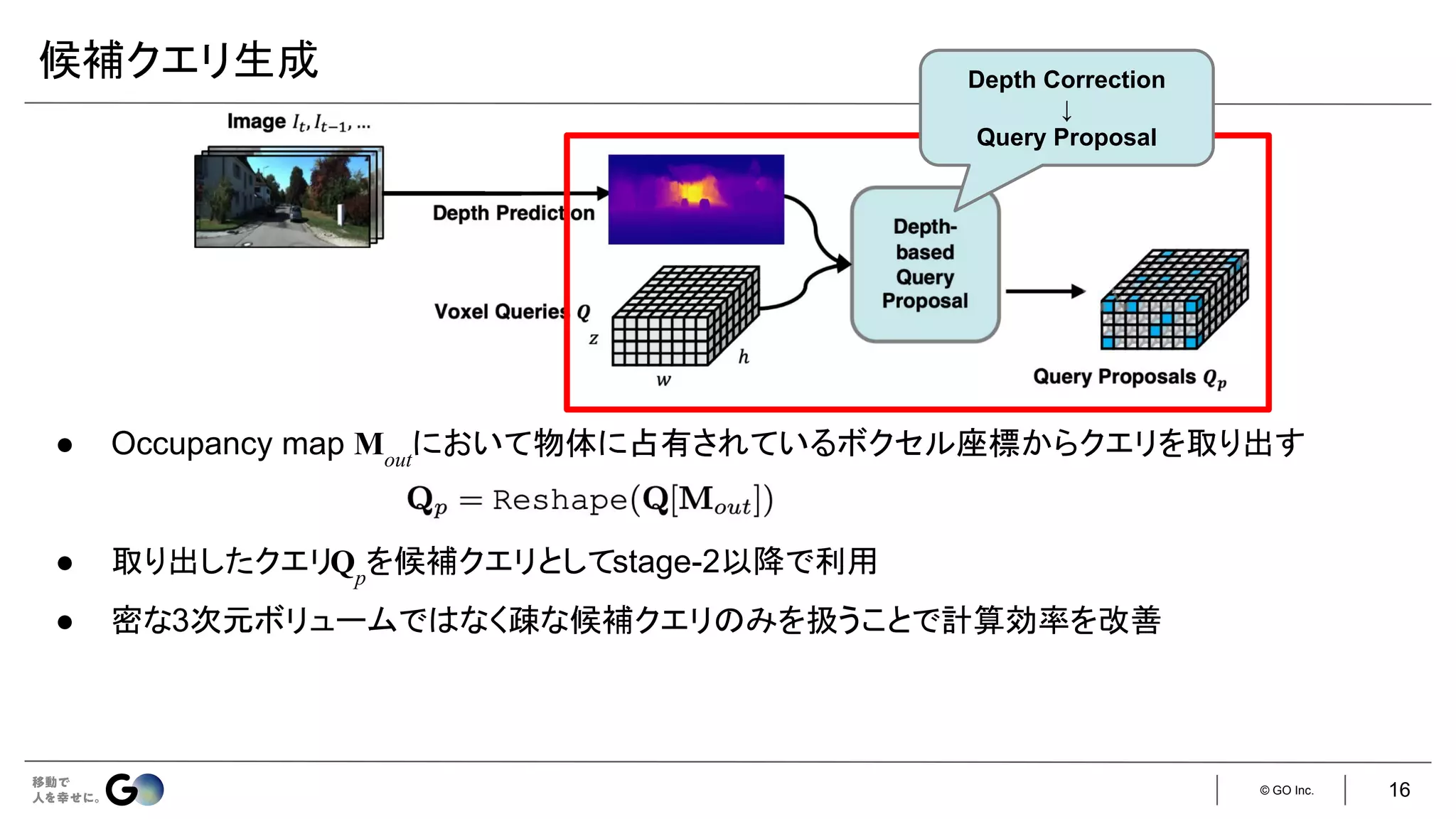
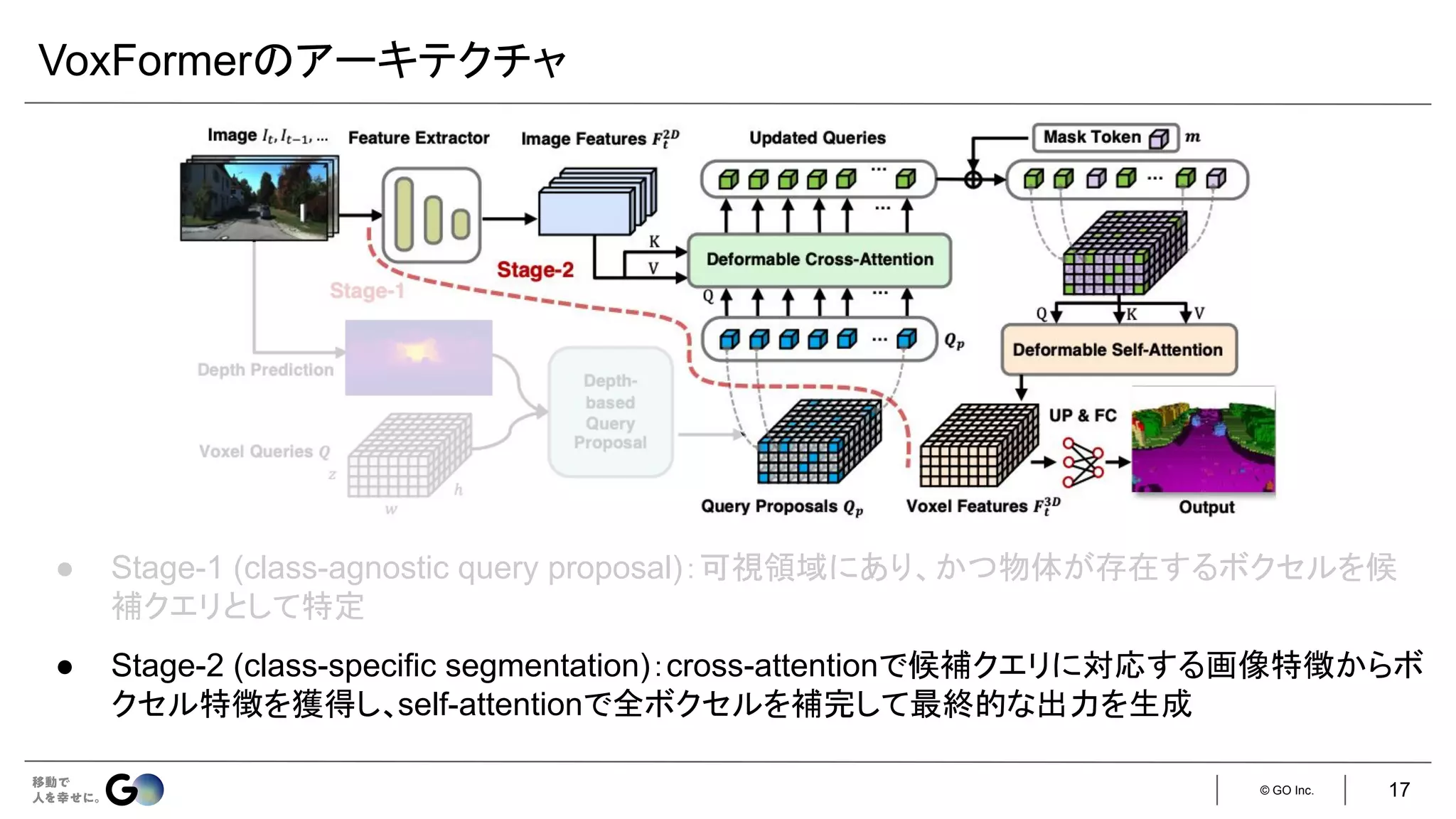
● Semantic Scene Completion (SSC)というタスクを初めて定義
● 入力となるデプス画像を物体表面からの符号付き距離を各ボクセルに格納した
TSDF (Truncated
Signed Distance Function)に変換し、3D CNNに入力
● 広い受容野で3次元空間のコンテキストを取得するため、
dilated convを利用
● 屋内シーンをCGで合成したSUNCGデータセット*を新たに構築し、学習・評価を実施
関連研究 - SSCNet -
Shuran Song et al., “Semantic Scene Completion from a Single Depth Image,” CVPR 2017.
“our goal is to have a model that predicts both volumetric occupancy (i.e., scene completion)
and object category (i.e., scene labeling) from a single depth image of a 3D scene”
* データ盗用で訴えられ、公開を停止(原告側の訴えは却下)
[参考]
5](https://image.slidesharecdn.com/20230430cvvoxformer-230430040121-1232bfb5/75/VoxFormer-Sparse-Voxel-Transformer-for-Camera-based-3D-Semantic-Scene-Completion-5-2048.jpg)

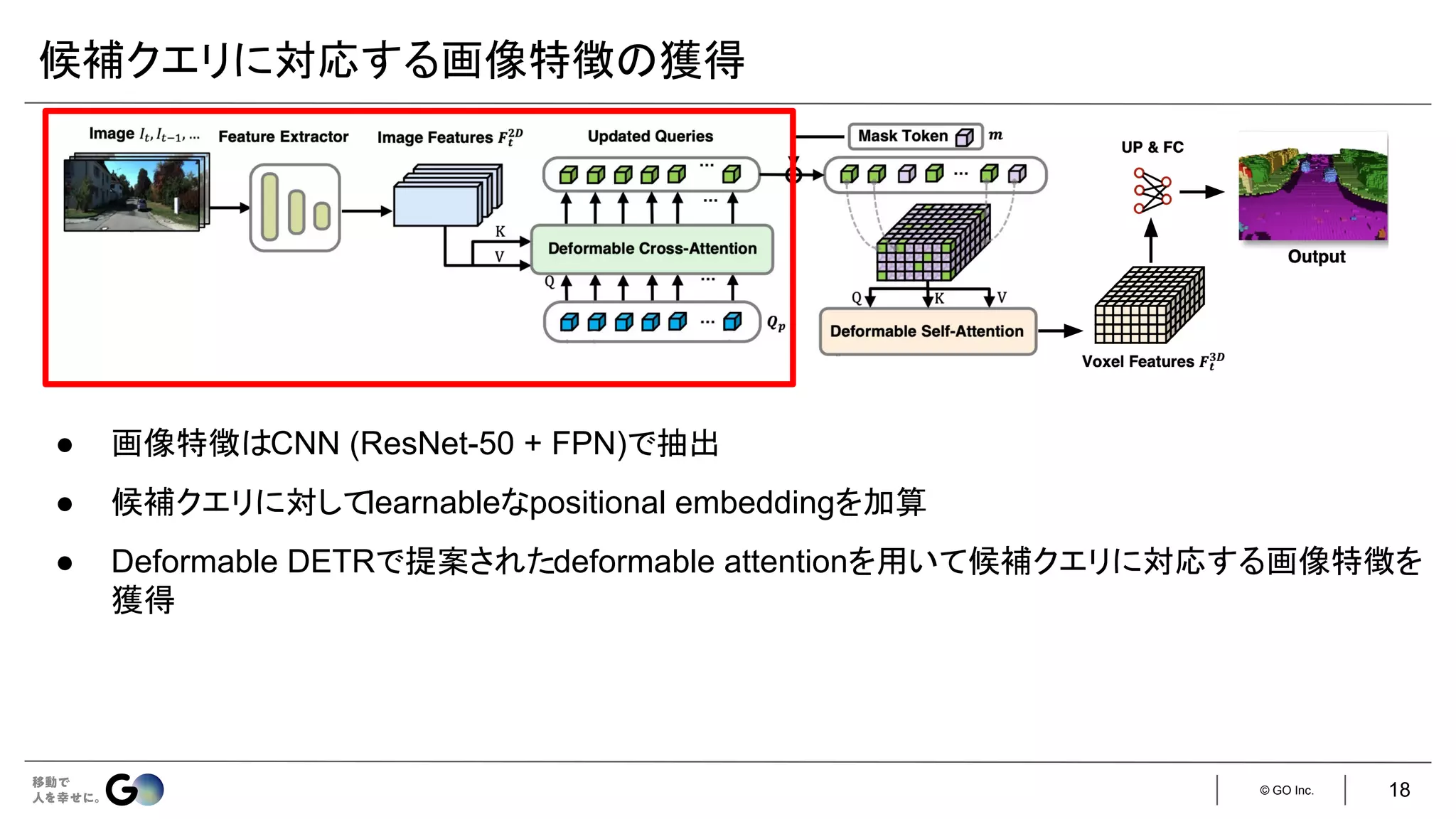
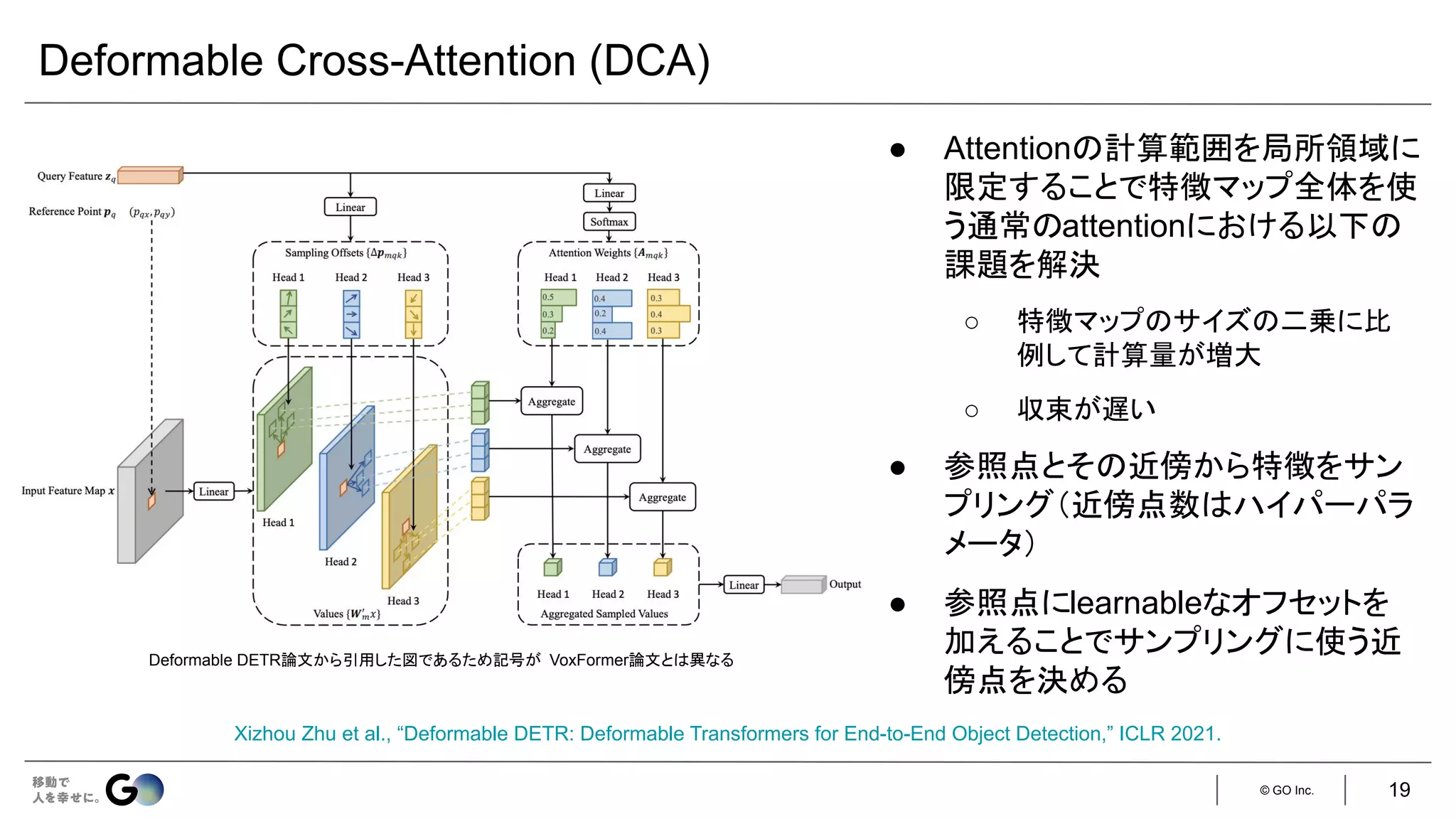
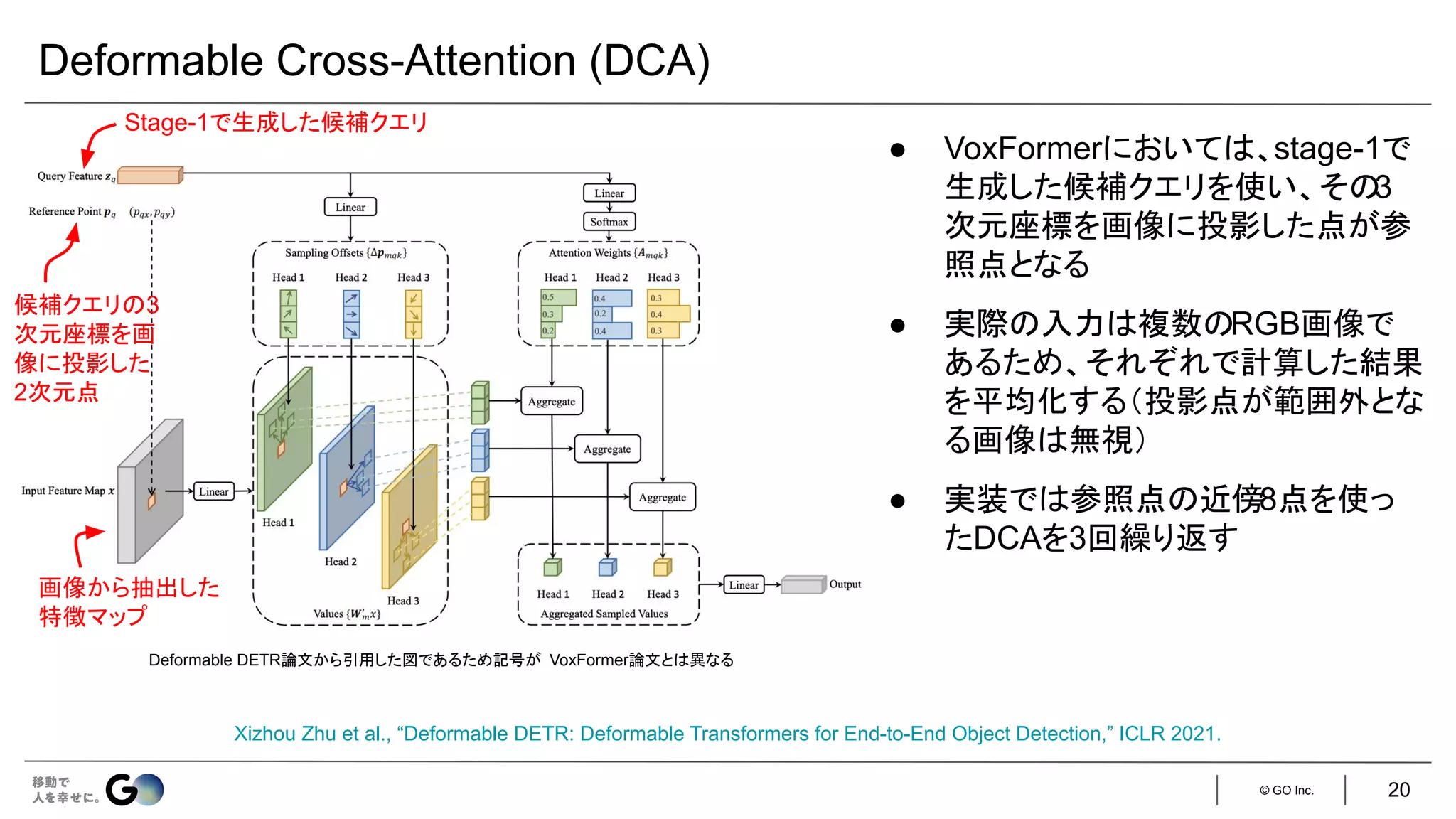
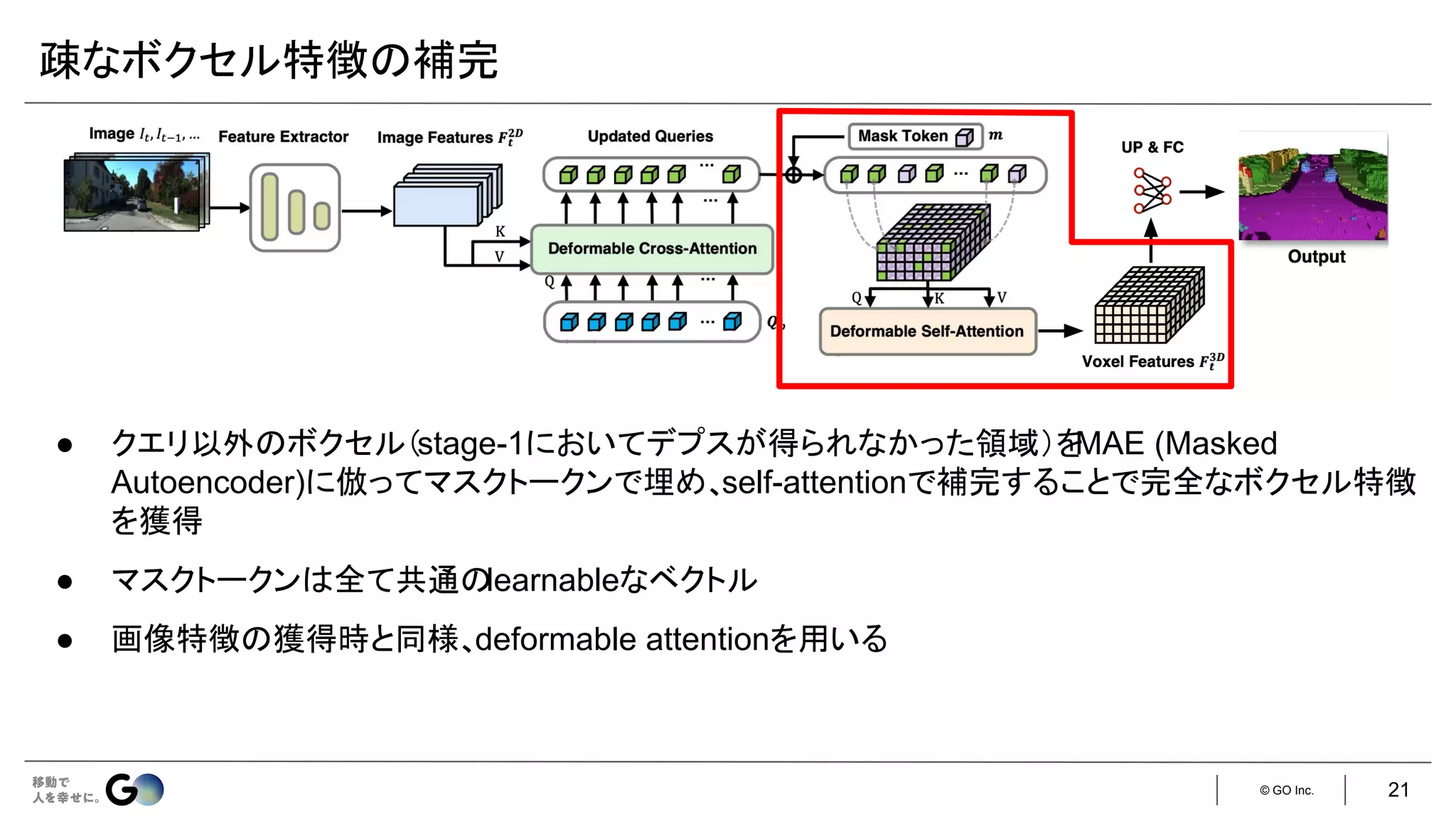

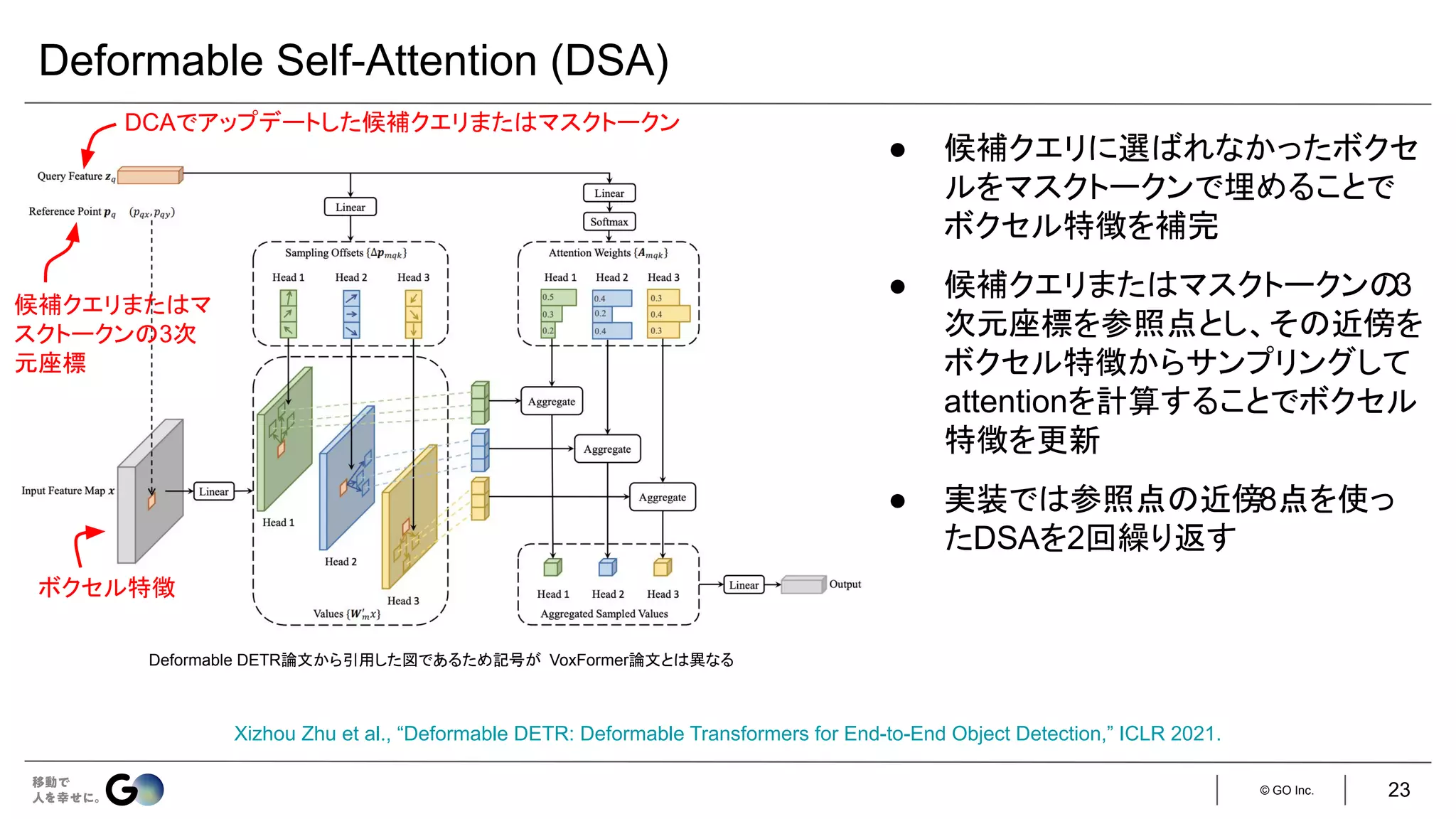
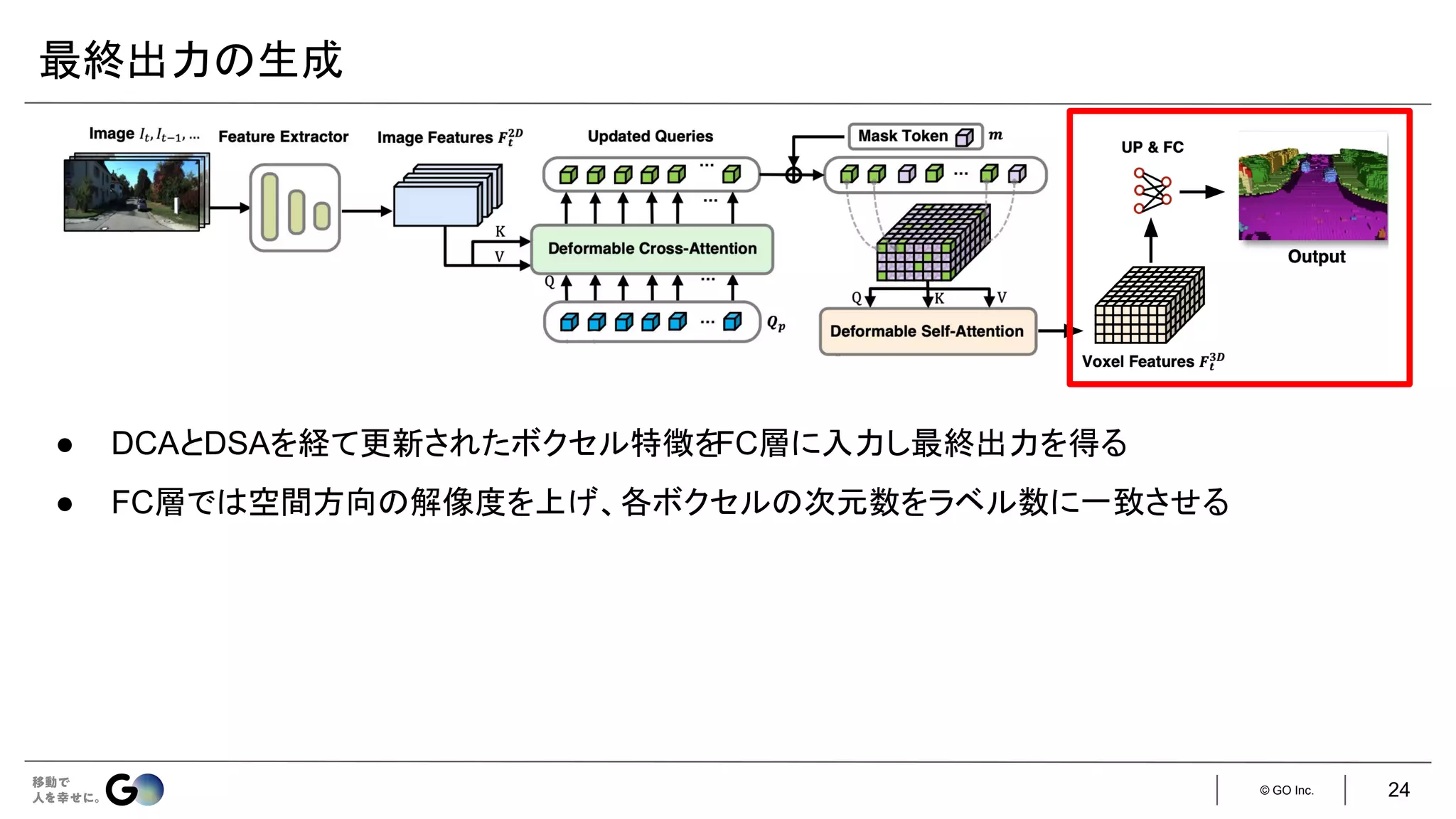
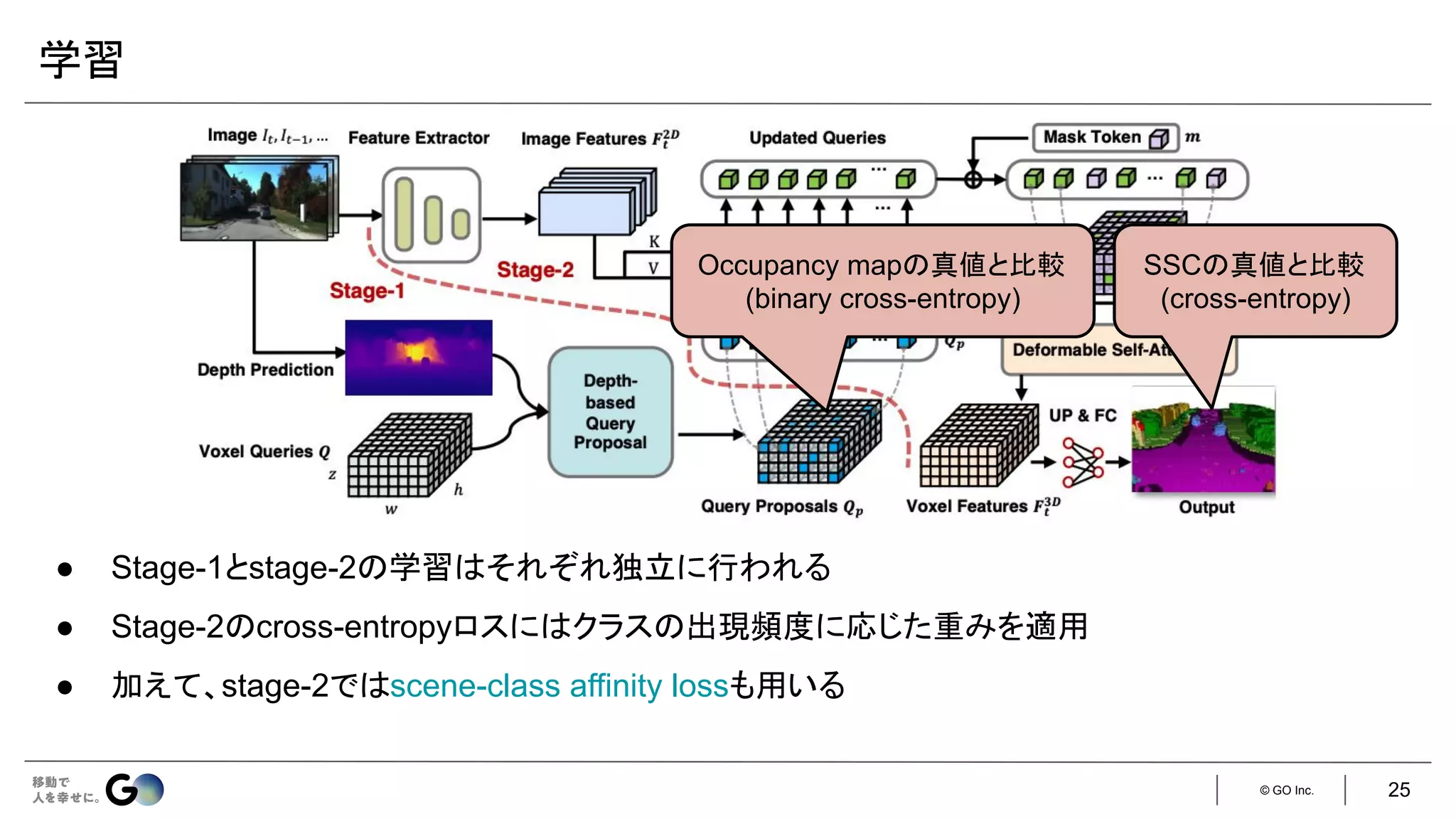
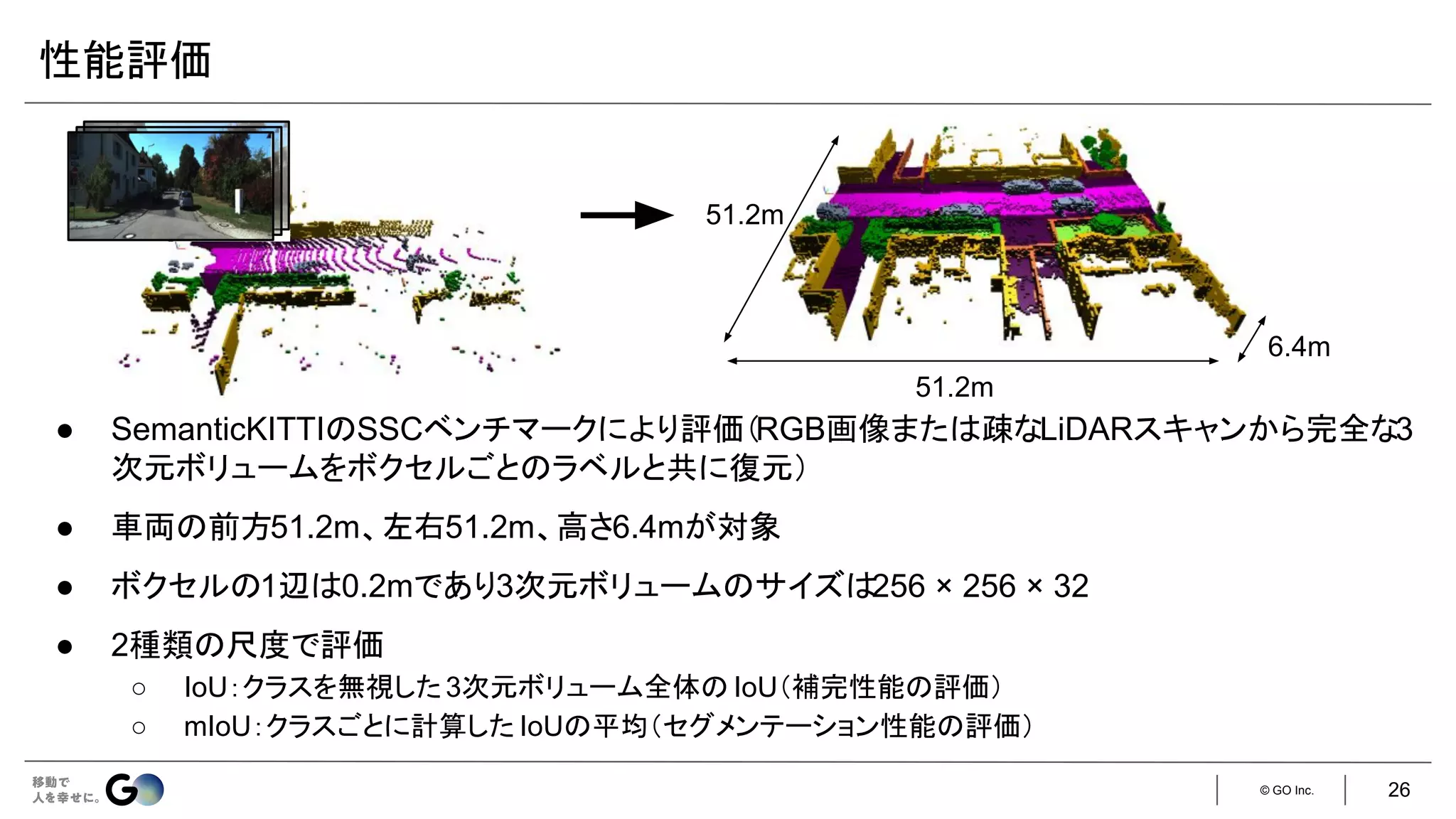
![© GO Inc.
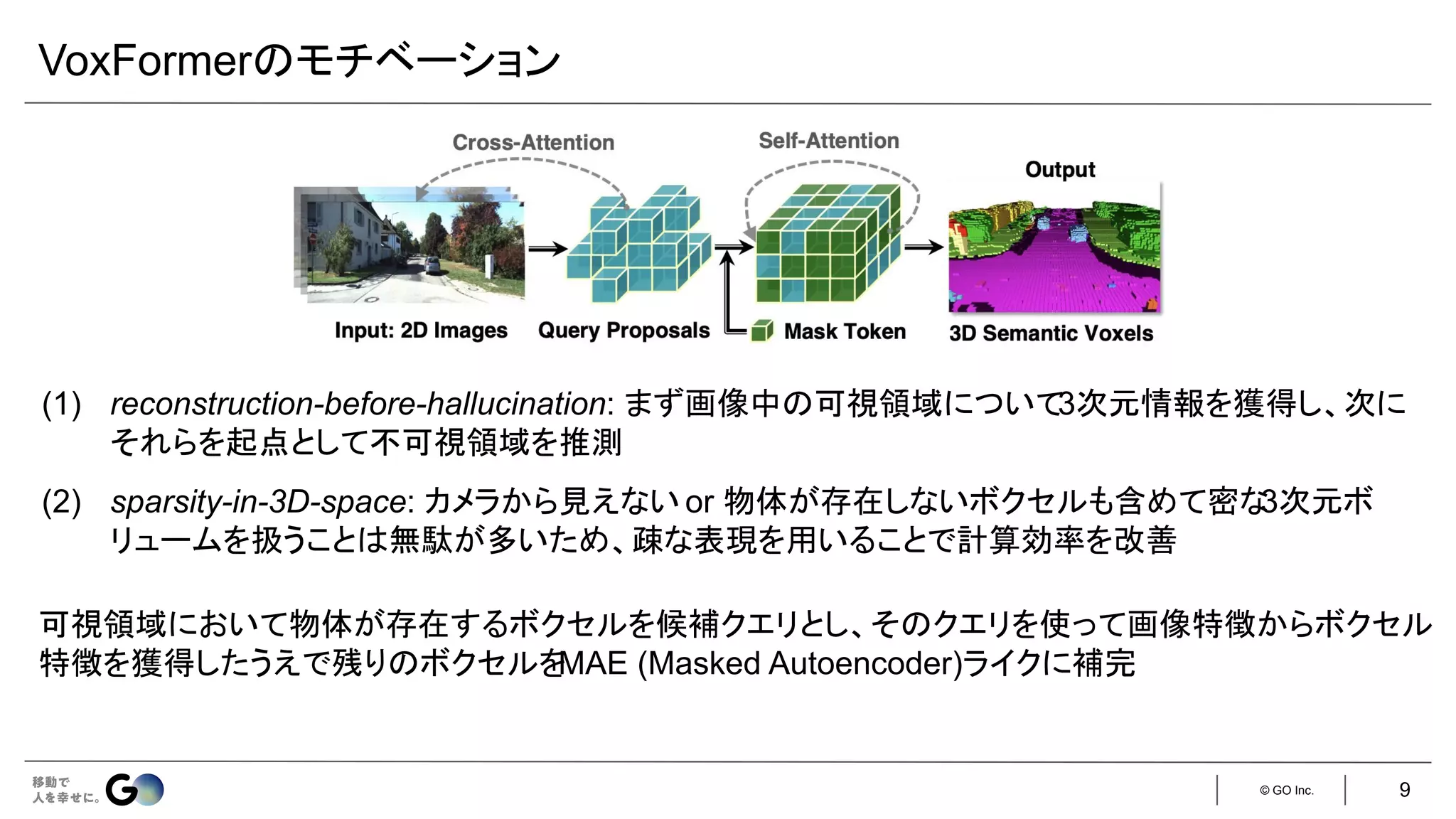
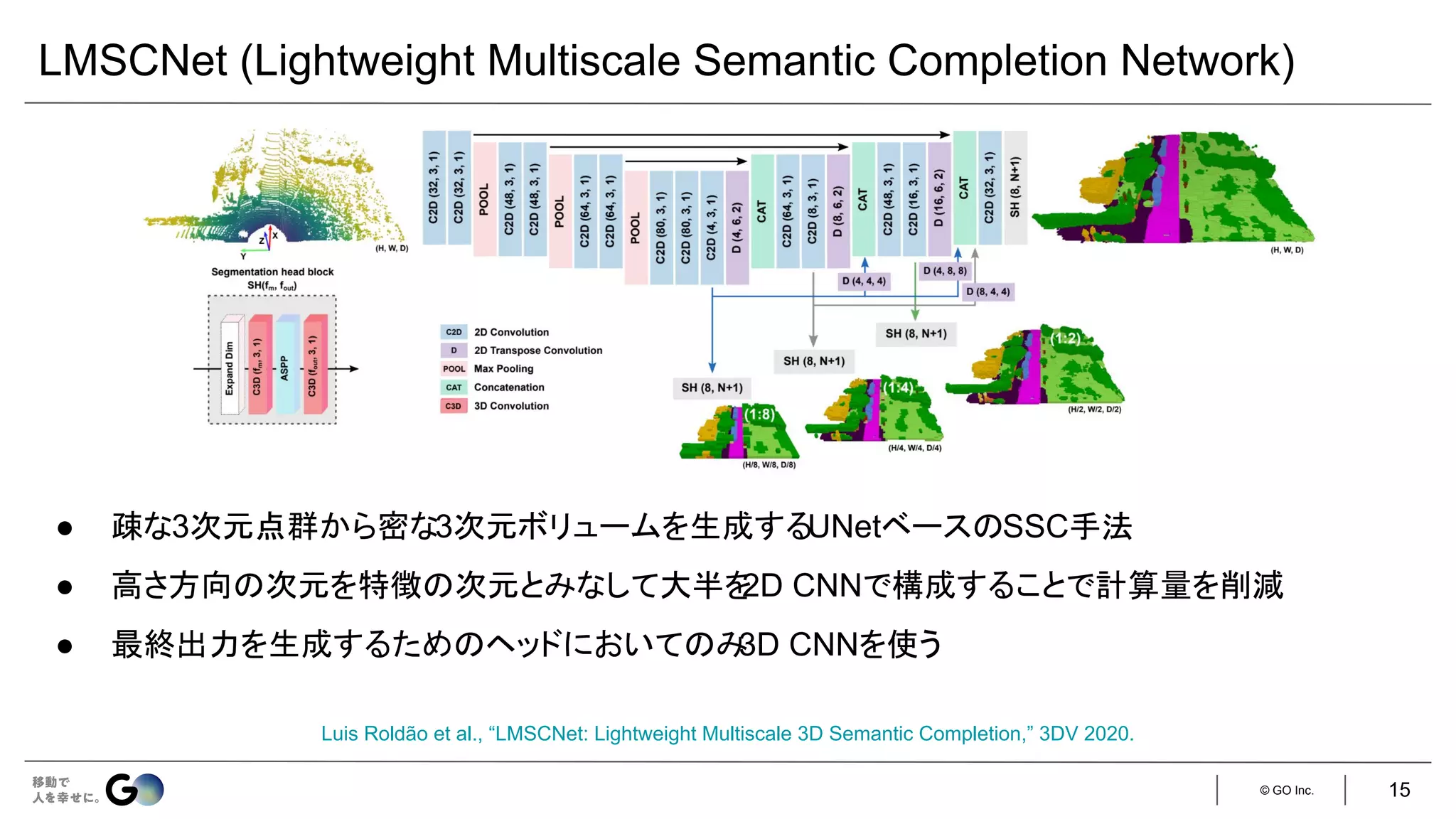
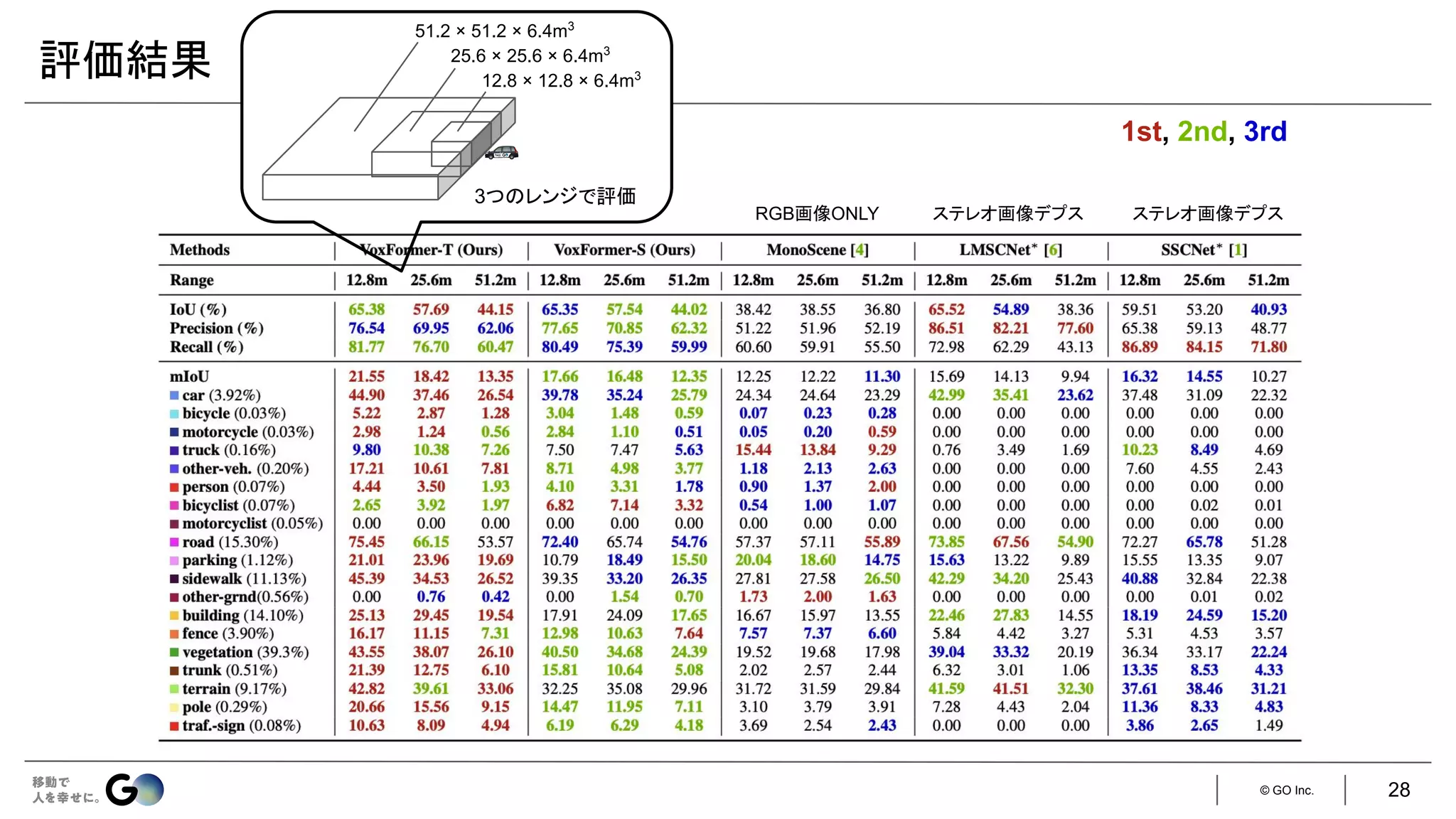
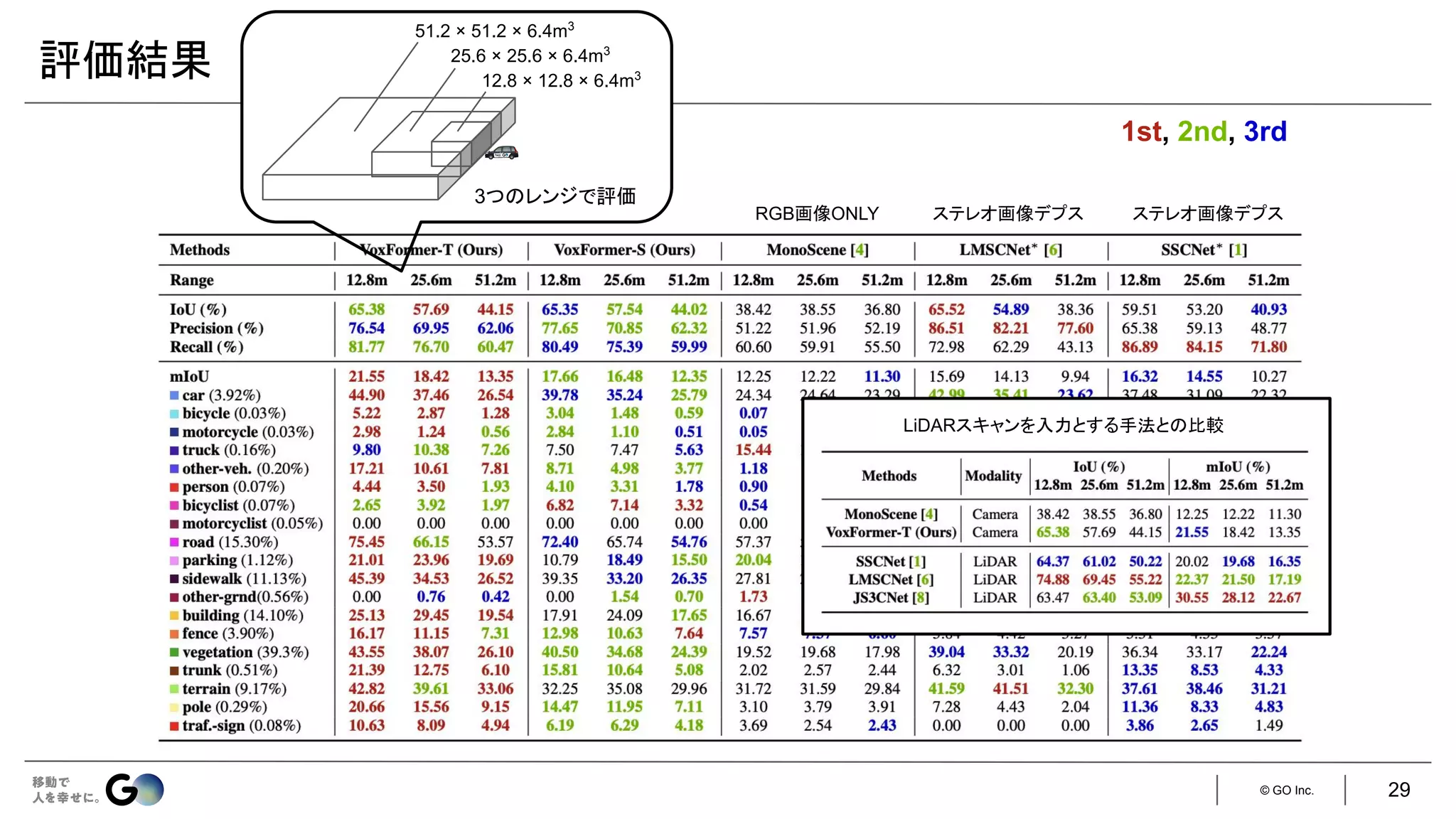
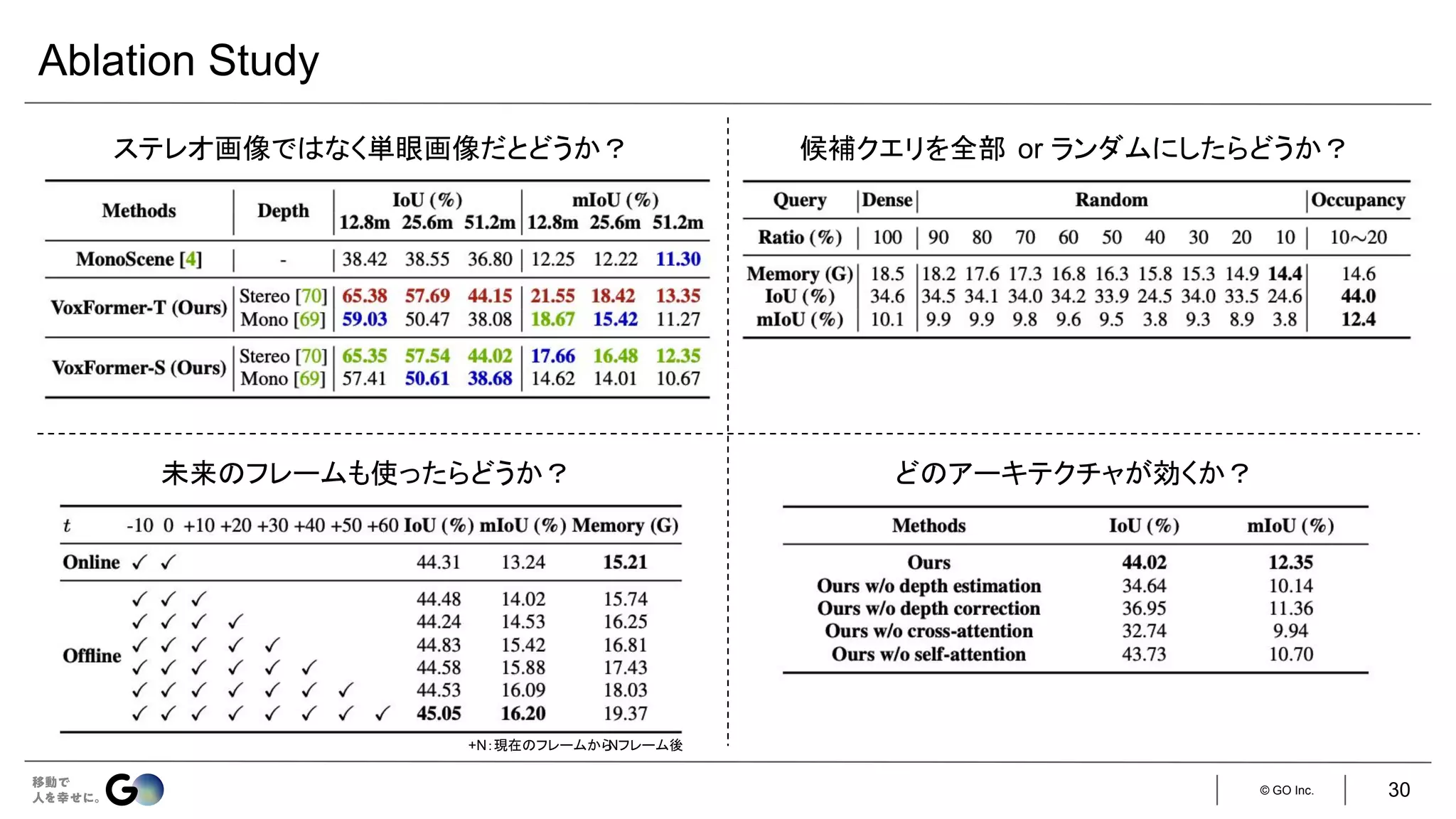
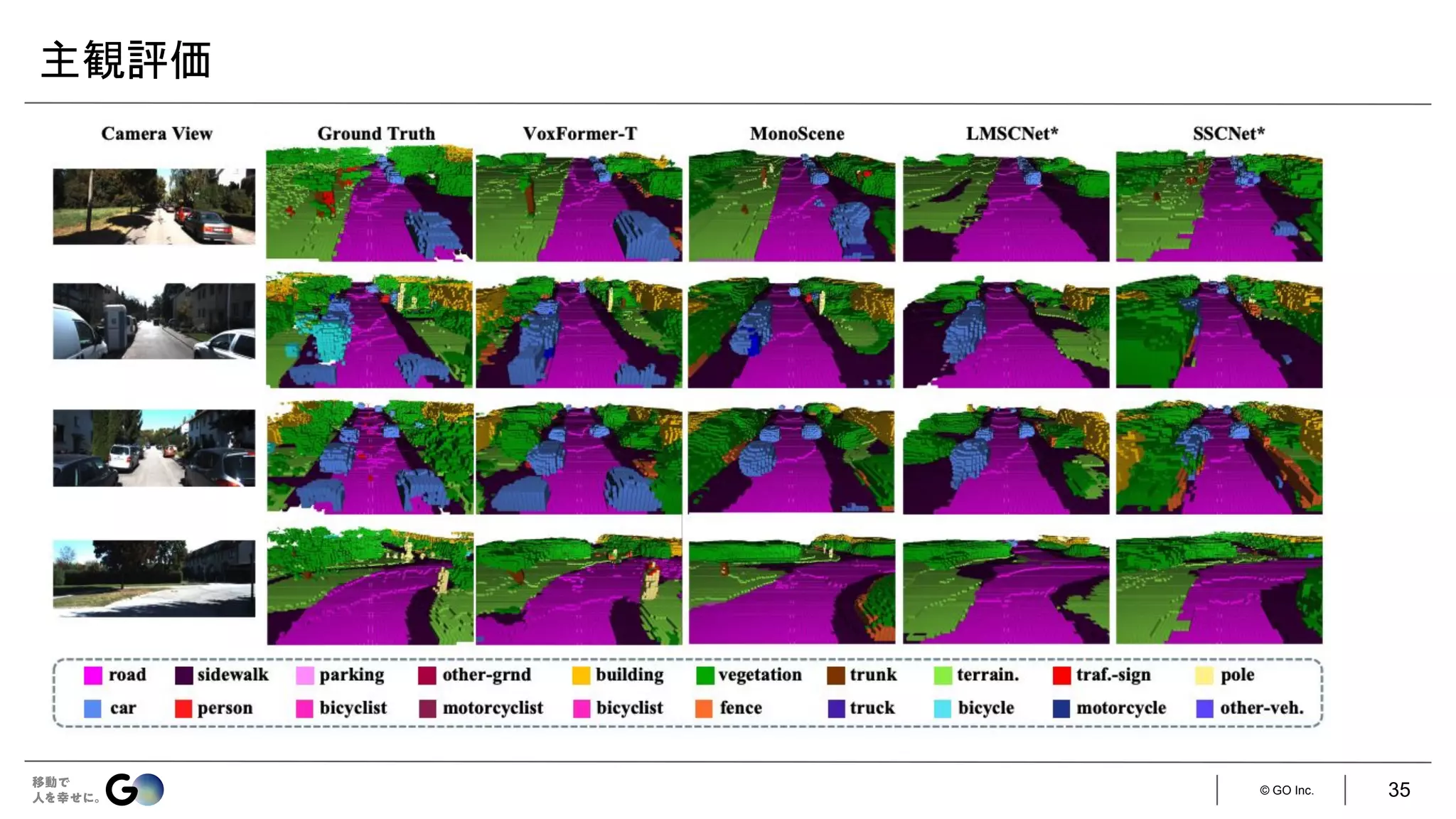
実装
入力はステレオ画像
● 現時刻のフレームのみ:VoxFormer-S
● 現時刻&直前4フレーム:VoxFormer-T
学習済みの
MobileStereoNet [1] で
生成
128 × 128 × 16 256 × 256 × 32
ステレオ画像の片方のみを利用し、
ResNet-50 + FPNで特徴抽出(128次元)
LMSCNet [2]をスクラッチ学習
[1] Faranak Shamsafar et al., “MobileStereoNet: Towards Lightweight Deep Networks for Stereo Matching,” WACV 2022
[2] Luis Roldão et al., “LMSCNet: Lightweight Multiscale 3D Semantic Completion,” 3DV 2020.
x 3
x 2
27](https://image.slidesharecdn.com/20230430cvvoxformer-230430040121-1232bfb5/75/VoxFormer-Sparse-Voxel-Transformer-for-Camera-based-3D-Semantic-Scene-Completion-27-2048.jpg)





![[DL輪読会]data2vec: A General Framework for Self-supervised Learning in Speech,...](https://cdn.slidesharecdn.com/ss_thumbnails/220204nonakadl1-220204025334-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会]Flow-based Deep Generative Models](https://cdn.slidesharecdn.com/ss_thumbnails/20190307-190328024744-thumbnail.jpg?width=640&height=640&fit=bounds)



![SSII2022 [OS3-04] Human-in-the-Loop 機械学習](https://cdn.slidesharecdn.com/ss_thumbnails/ssii2022-os3-04-220607021031-e69700d5-thumbnail.jpg?width=640&height=640&fit=bounds)




![[DL輪読会]Vision Transformer with Deformable Attention (Deformable Attention Tra...](https://cdn.slidesharecdn.com/ss_thumbnails/dl0114-220114032933-thumbnail.jpg?width=640&height=640&fit=bounds)




![SSII2022 [SS1] ニューラル3D表現の最新動向〜 ニューラルネットでなんでも表せる?? 〜](https://cdn.slidesharecdn.com/ss_thumbnails/ss1ssii2022hkatoneural3drepresentationhiroharukato-220607054619-fadc6480-thumbnail.jpg?width=640&height=640&fit=bounds)











![[DL輪読会]An Image is Worth 16x16 Words: Transformers for Image Recognition at S...](https://cdn.slidesharecdn.com/ss_thumbnails/dl10161-201016015214-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]MetaFormer is Actually What You Need for Vision](https://cdn.slidesharecdn.com/ss_thumbnails/20220121metaformer-220121085750-thumbnail.jpg?width=640&height=640&fit=bounds)







![[DL輪読会]End-to-End Object Detection with Transformers](https://cdn.slidesharecdn.com/ss_thumbnails/200529dlseminardetr-200529061512-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]Geometric Unsupervised Domain Adaptation for Semantic Segmentation](https://cdn.slidesharecdn.com/ss_thumbnails/20220121gudalin-220121050547-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DL輪読会]Dense Captioning分野のまとめ](https://cdn.slidesharecdn.com/ss_thumbnails/dlseminar-201202012355-thumbnail.jpg?width=640&height=640&fit=bounds)














![[CVPR2020読み会@CV勉強会] 3D Packing for Self-Supervised Monocular Depth Estimation](https://cdn.slidesharecdn.com/ss_thumbnails/202007043dpackingforself-supervisedmonoculardepthestimation-200704035538-thumbnail.jpg?width=640&height=640&fit=bounds)









