







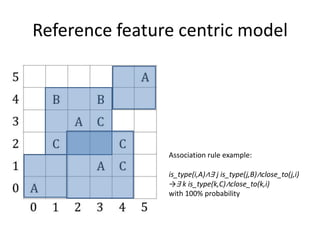
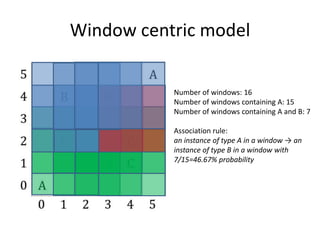
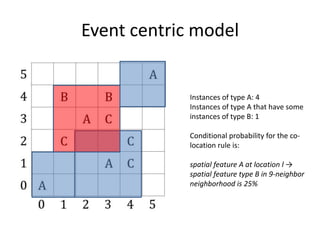


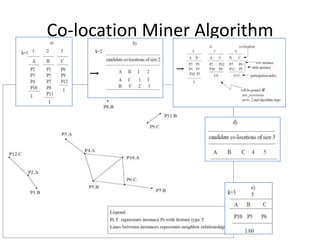




This document summarizes research on discovering spatial co-location patterns from geospatial data. It discusses how spatial data mining differs from classical data mining by considering attribute relationships between neighboring spatial objects. The paper focuses on extracting frequent co-occurrence rules between boolean spatial features from ecological datasets. It presents three approaches for modeling co-location rules problems - reference feature centric, window centric, and event centric. The Co-location Miner algorithm is introduced for mining co-location rules that satisfy minimum prevalence and conditional probability thresholds from the data.



























































































