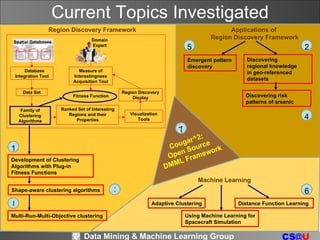
1. The document summarizes ongoing data mining and machine learning research at the University of Houston from 2006-2009.
2. Key areas of research included developing shape-aware clustering algorithms, discovering regional knowledge in geo-referenced datasets, emergent pattern discovery, and various machine learning applications.
3. The researchers were developing techniques for clustering with plug-in fitness functions, discovering spatial risk patterns like arsenic levels, and an open source data mining framework called Cougar2.