












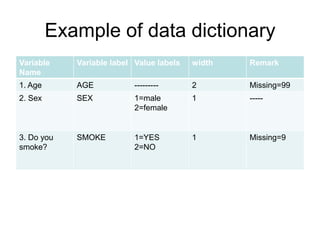
























SPSS can be used for data entry, cleaning, analysis, and presentation. It is important to prepare a data dictionary specifying variable names, codes, ranges, and missing values before entering data. Errors may occur during data collection or entry and can be detected using descriptive statistics, frequency distributions, logical checks, and double data entry. Suspicious values should be investigated rather than automatically changed to avoid correcting valid data.






















































































![PERI-PROSTHETIC FRACTURE NAIL-PLATE CONSTRUCT [NPC].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/drarunkumardrmohamedashrafperiprostheticfrasturenail-plateconstructnpc-260209164459-7e9d15a1-thumbnail.jpg?width=640&height=640&fit=bounds)

