Download to read offline
























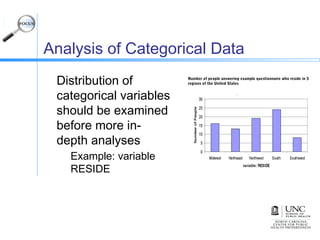





This document discusses the basics of descriptive data analysis, including defining different types of variables, coding principles, and univariate data analysis. It describes continuous variables as always numeric and categorical variables as information sorted into categories, with ordinal variables having intrinsic order, nominal variables lacking order, and dichotomous variables having only two levels. The document outlines steps for coding variables and cleaning data, as well as techniques for univariate analysis of continuous and categorical variables to check data quality.





















































































