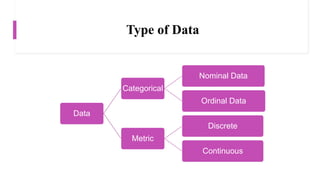
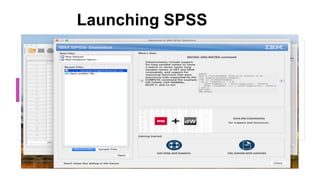
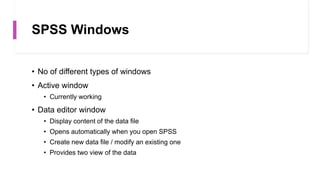
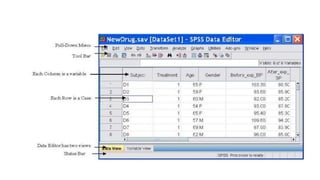
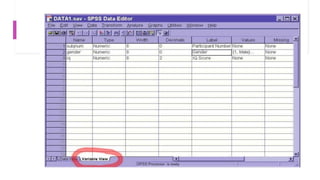
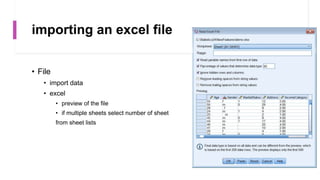
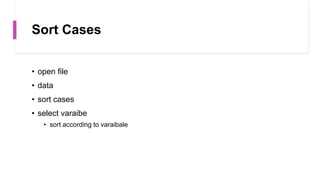
This document provides an overview of a course on data analysis using SPSS. The course objectives are to teach students statistical analysis concepts, grasp psychological research concepts, and learn how to appropriately process, analyze, interpret and report on research data using SPSS. The course will cover introductory topics like launching SPSS and understanding its interface, as well as more advanced topics like conducting different statistical tests and interpreting outputs. Students will apply their learning through a group project involving data collection, analysis and reporting.