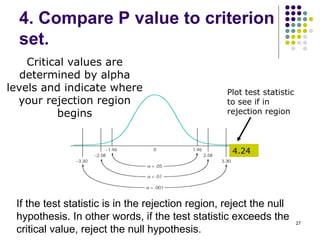
1. The document discusses hypothesis testing using the z-test. It outlines the steps of hypothesis testing including stating hypotheses, setting the criterion, computing test statistics, comparing to the criterion, and making a decision.
2. Examples are provided to demonstrate a non-directional and directional z-test, including stating hypotheses, computing test statistics, comparing to criteria, and interpreting results.
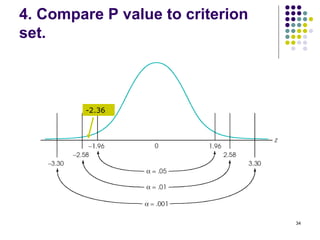
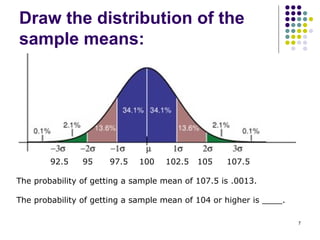
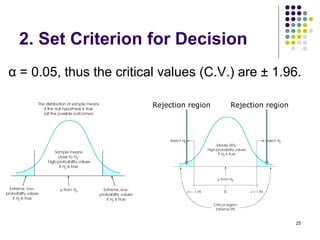
3. Key concepts reviewed are the central limit theorem, type I and II errors, significance levels, rejection regions, p-values, and confidence intervals in hypothesis testing.
























![Compute confidence interval
Alpha set a 0.05. Thus, we build a 95% confidence interval and
the critical values are ± 1.96.
CI95 = μ ± Critical value (σ ) Standard error
√n
CI95% = .75 ± 1.96 (.05 / √50 ) = .75 ± .01 =
[.74, .76]
95% of all possible means for samples of size 50 in the population
will fall between 74% and 76%.
Our sample mean of 78% falls outside of the interval we built.
29](https://image.slidesharecdn.com/week7reviewz-testci-1-090717125923-phpapp01/85/Review-Z-Test-Ci-1-29-320.jpg)