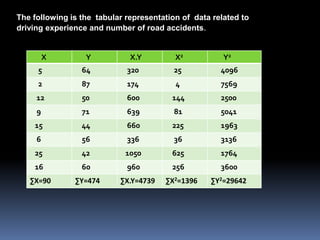
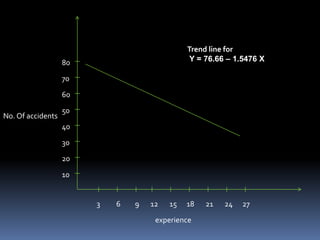
The document presents a regression analysis on the relationship between driving experience (the independent variable X) and the number of road accidents (the dependent variable Y). It finds the regression line to be Y = 76.66 - 1.5476X, indicating a negative relationship between accidents and experience. Using this line, it estimates the number of accidents would be 61.184 for 10 years experience and 30.232 for 30 years experience. It also calculates the coefficient of determination R2 = 0.5894, meaning driving experience explains around 59% of the variance in road accidents.