Download as PDF, PPTX






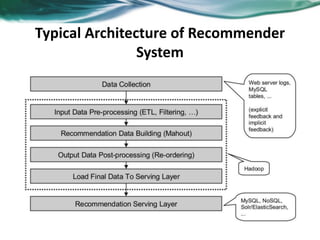

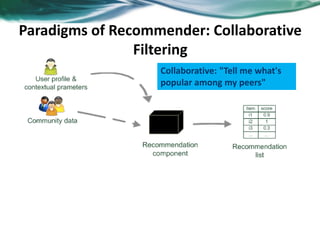
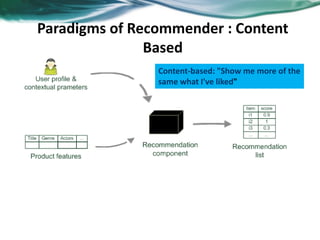
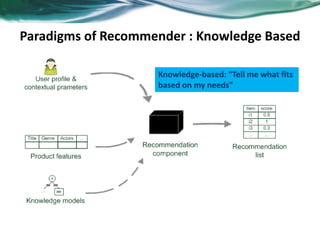
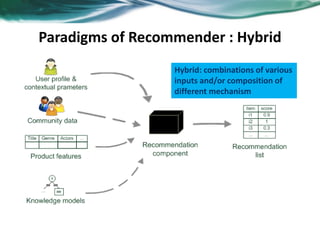
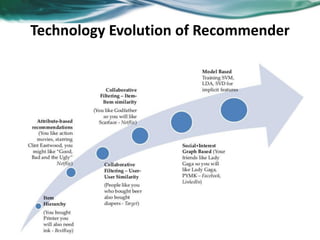
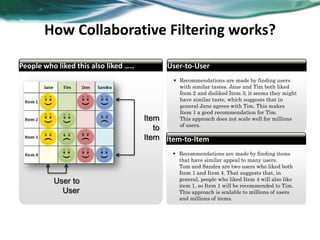












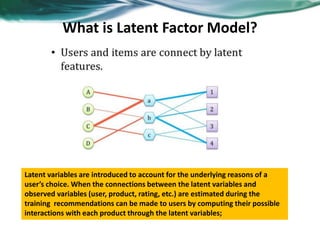


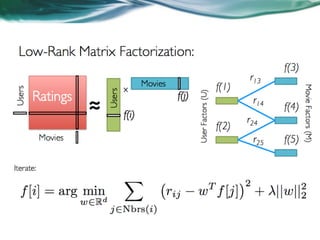


















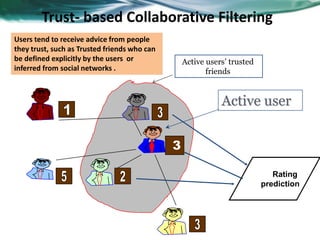



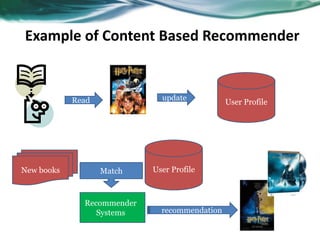

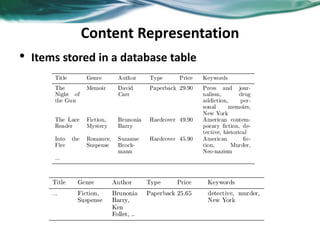






The document provides an overview of recommender systems. It discusses the typical architecture of recommender systems and describes three main types: collaborative filtering systems, content-based systems, and knowledge-based systems. It also covers paradigms like collaborative filtering, content-based, knowledge-based, and hybrid recommender systems. The document then focuses on collaborative filtering techniques like user-based nearest neighbor collaborative filtering and item-based collaborative filtering. It also discusses latent factor models, matrix factorization approaches, and context-based recommender systems.































![[Final]collaborative filtering and recommender systems](https://cdn.slidesharecdn.com/ss_thumbnails/finalcollaborativefilteringandrecommendersystems-141103044224-conversion-gate01-thumbnail.jpg?width=640&height=640&fit=bounds)
























































![Getting Started with Apache Spark: Big Data Made Simple [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/apachesparkgettingstarted-260203175547-8361bcc3-thumbnail.jpg?width=640&height=640&fit=bounds)

