Download to read offline

















![Adapting Naïve Bayes idea for Book
Recommendation
• Vector of Bags model
– E.g. Books have several
different fields that are all
text
• Authors, description, …
• A word appearing in one
field is different from the
same word appearing in
another
– Want to keep each bag
different—vector of m Bags;
Conditional probabilities for
each word w.r.t each class
and bag
• Can give a profile of a
user in terms of words
that are most predictive
of what they like
– Odds Ratio
P(rel|example)/P(~rel|
example)
An example is positive if the
odds ratio is > 1
– Strengh of a keyword
• Log[P(w|rel)/P(w|~rel)]
– We can summarize a
user’s profile in terms of
the words that have
strength above some
threshold.
∏∏= =
=
S
m
dm
i
mi smcjaP
BookP
cjP
BookcjP
1
||
1
),|(
)(
)(
)|(](https://image.slidesharecdn.com/filteringcontentbbasedcrs-160809113304/85/Filtering-content-bbased-crs-19-320.jpg)




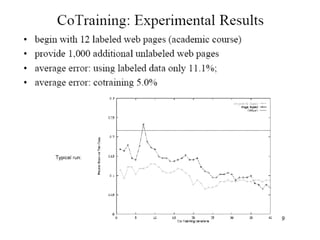
![Co-training
• Suppose each instance has two parts:
x = [x1, x2]
x1, x2 conditionally independent given f(x)
• Suppose each half can be used to classify instance
∃f1, f2 such that f1(x1) = f2(x2) = f(x)
• Suppose f1, f2 are learnable
f1 ∈ H1, f2 ∈ H2, ∃ learning algorithms A1, A2
Unlabeled Instances
[x1, x2]
Labeled Instances
<[x1, x2], f1(x1)>A1 f2
Hypothesis
~
A2
Small labeled data needed
You train me—I train you…](https://image.slidesharecdn.com/filteringcontentbbasedcrs-160809113304/85/Filtering-content-bbased-crs-27-320.jpg)



This document discusses various techniques for filtering and recommender systems, including content-based filtering, collaborative filtering, and hybrid approaches. It provides an overview of key concepts such as using user profiles and feedback to provide personalized recommendations. It also covers common recommendation algorithms like nearest neighbor collaborative filtering and discusses challenges like cold start problems and sparsity issues.


















![[Final]collaborative filtering and recommender systems](https://cdn.slidesharecdn.com/ss_thumbnails/finalcollaborativefilteringandrecommendersystems-141103044224-conversion-gate01-thumbnail.jpg?width=640&height=640&fit=bounds)













































![[系列活動] 人工智慧與機器學習在推薦系統上的應用](https://cdn.slidesharecdn.com/ss_thumbnails/merged-161217165734-thumbnail.jpg?width=640&height=640&fit=bounds)




















